矿物高光谱解混进展研究综述
2020-07-28朱玲李明秦凯潘澄雨
朱玲,李明,秦凯,潘澄雨
(核工业北京地质研究院 遥感信息与图像分析技术国家级重点实验室,北京 100029)
0 引言
由于受影像场景的复杂性和传感器空间分辨率的限制,遥感影像中地物对应的纯净像元一般较少[1]。高光谱影像具有光谱分辨率高、空间分辨率相对较低的特点,混合像元更是普遍存在[2]。为提高光谱遥感应用精度,光谱解混成为研究重点。光谱解混过程包括纯净端元提取和丰度求解,不仅局限于星载、机载的高光谱影像的解混,也包括微观角度的如光谱仪量测的混合光谱解混。
岩石一般是由多种矿物构成的矿物集合体[3],矿物颗粒之间在400~2 500 nm的可见光-近红外波段容易发生多重散射[4],其光谱特征是若干组分矿物光谱的综合反映[5]。矿物的光谱特征与其内在理化特性紧密相关,化学成分和晶体结构特征是矿物端元识别的重要依据,在400~1 300 nm波长范围内主要表现为Fe、Cu等过渡性金属元素的电子跃迁;在1 300~2 500 nm波长内主要表现为矿物水分子、羟基、碳酸根、硫酸根等阴离子基团振动过程[6-7]。20世纪七八十年代学者们开始热衷于岩石样本光谱特征量测,90年代逐渐开展基于完全波形匹配的岩矿识别,目前岩矿光谱解混已经成为新的研究热点[8],它是连接遥感技术与地质的关键,对矿物勘查、矿物含量定量反演和矿物丰度制图等都具有重要的指导意义[9]。
光谱混合模型主要有线性和非线性2类[10]。基于混合模型的光谱解混算法较多,主要分为基于几何、统计和稀疏回归等解混方法,在近20年得到广泛应用。由于岩石的紧致混合特征,基于线性模型解混的精度往往较低[11],Hapke辐射传输模型是非线性解混最常用的模型之一[12],可以把混合矿物的波谱反射率转换为单次散射反照率(single scattering albedo,SSA),将非线性特征转变为线性特征进行研究。除了基于模型的解混方法外,神经网络法、核函数法和流形学习等基于数据驱动的解混方法可以较好地映射矿物光谱的非线性特征,也逐渐获得关注和应用[13]。
解混实验对光谱解混精度和效率要求越来越高,光谱解混算法已逐渐向智能化方向转变。高光谱解混的多种方法已经在实验室模拟光谱数据中得到较好验证[14],在矿区的矿物识别和野外地质填图等方面也得到较好的应用[15-16],除此之外还成功应用于古画颜料解混[17-18]、月表矿物识别监测[19-20]、月球矿物制图评估[21]等众多方面。本文在学者们研究的基础上总结了2种主要的光谱混合模型,系统地介绍了目前存在的多种光谱解混算法和已开展的光谱解混实验,最后对目前矿物光谱解混存在的问题和未来发展趋势进行总结。
1 光谱混合模型
光谱混合模型是光谱解混算法的理论基础。光谱混合方式从本质上可分为线性和非线性混合2种,其主要区别在于光子是否在地物间发生多次散射[2]。
1.1 线性混合模型
线性混合模型(linear mixing model,LMM)即把每一个混合波谱反射率看作为每一个端元光谱反射率和对应组分含量的线性组合。LMM用式(1)表示。
(1)
式中:X表示混合光谱反射率;am表示第m个端元的光谱反射率;em为第m个端元的丰度;A=(a1a2…aM)T为端元光谱矩阵;E=(e1e2…eM)T为端元丰度矩阵;M为端元数;ε为误差项。
1.2 非线性混合模型
由于光子在地物间发生多次散射现象,从微观角度看粒子的混合是非线性的。非线性混合模型的表达式为式(2)。
X=f(A,E)+ε
(2)
式中:f(·)表示端元矩阵A和丰度矩阵E之间的非线性关系。由于模型的不确定性,需要给出确定且合适的非线性模型才能进行光谱混合[2]。Hapke模型[22-23]可以详细描述矿物混合效应,把矿物反射率转化为SSA,把非线性混合光谱转变到线性空间。反射率与SSA的函数表示见式(3)[12]。
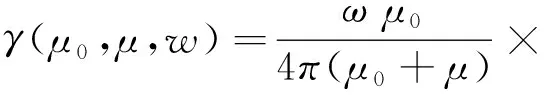
(3)
式中:γ(·)为反射率;μ0=cosi;μ=cose;i为入射角;e为出射角;g为相位角;ω为矿物单次散射反照率;B(g)表示后向散射系数;P(g)为相位函数;H(ω,μ)为各向同性散射函数。由于模型对参数要求较高且求解过程较为复杂,为便于计算,对式(3)进行简化[24],使B(g)=0,P(g)=1,简化后的模型表示为式(4)。
(4)
H函数可近似表示为式(5)。
(5)
ω的表达见式(6)。
(6)
式中:em的含义见式(1);ωm为各组分矿物的SSA;ω表示混合矿物的SSA。简化后的矿物反射率表达式转换为式(7),可以根据已知的矿物反射率求解矿物SSA。
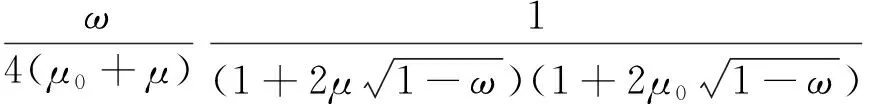
(7)
Hapke模型进行改进后的多混合像元模型(multi-mixture pixel,MMP)是把线性和非线性模型相结合构成的非线性混合模型[25],其物理意义是把非线性混合的端元添加到线性混合模型中。Heylen等[3]在MMP模型基础上把LMM模型和Hapke模型相结合,提出了另外一种紧致混合物的线性混合模型(linear mixture of intimate mixtures,LIM)。LMM模型假设矿物端元在空间上呈棋盘式分布,实际情况中每个棋盘模块由多个端元构成,LIM则描述了非线性混合特征。通过不同参数的设置,LIM模型可以转变为MMP或Hapke模型。除了Hapke模型之外,余先川等[2,15]还提出了一种二次散射模型用于描述矿物的混合效应。
2 解混方法
目前矿物混合光谱解混算法有很多,基本可以分为模型驱动和数据驱动2大类。模型驱动法是基于混合模型理论的,可以分为基于几何、统计和稀疏回归的解混方法。数据驱动主要包括神经网络法、核函数法和流形学习法等方法。
2.1 模型驱动法
1)基于几何方法。在端元提取方面,基于纯像元的端元识别算法常用的有纯端元索引法(pixel purity index,PPI)、顶点成分分析法(vertex component analysis,VCA)和内部体积最大法等。PPI方法将高光谱数据在随机向量方向分别进行投影,把落在两端数据进行标记,标记次数大于某阈值数据作为潜在端元集[26]。内部体积最大法通过选择最大单形体体积来确定端元,对数据降维后,再利用高光谱数据凸面单形体的特征寻找具有最大体积的单形体并将其顶点作为端元[27]。VCA 将像元在所有维度进行投影,把投影值最大的像元作为第一个端元,再把高光谱数据投影到与已确定端元构成的子空间正交方向上,通过迭代法选取其他端元[28]。PPI算法需要获取一定的先验知识,通过人工经验提取端元,人为因素影响较大,而且随机向量选取的不确定性对端元提取影响较大;内部体积最大法利用穷举方法找出端元,计算量较大;VCA和内部体积最大法在端元识别时都需要提前明确端元数目。上述方法均基于纯像元假设,要求高光谱数据中存在纯像元,在对实际高光谱数据解混情况下难以满足要求。
最小体积单形体法(minimum volume simplex analysis,MVSA)[29]和变元切分增量拉格朗日单形体识别法(simplex identification via variable splitting and augmented Lagrangian,SISAL)[30]是基于最小体积变换的端元识别法。2种方法的原理都是通过寻找一个混合矩阵,该矩阵的列所形成的单形体体积是将高光谱数据完全包围的最小体积的单形体;不同之处在于MVSA方法对初始端元矩阵的选择非常重要,SISAL法则是采用一系列增广拉格朗日方法解决最优化问题。基于最小体积的方法不再要求纯像元假设,但容易受噪声的影响,估计端元值与实际端元误差往往较大。
在端元矩阵已知后求解各端元的丰度系数,端元丰度估计依赖于端元光谱的提取。最常用的丰度估计方法有最小二乘法。最小二乘法是基于线性混合模型估计丰度的方法,通过添加不同的约束条件又分为无约束的最小二乘算法(unconstrained least squares,UCLS)、“和为一”约束最小二乘(sum-to-one constrained least squares,SCLS)、“非负”约束最小二乘法(nonnegativity constrained least squares,NCLS)和全约束最小二乘法(fully constrained least squares,FCLS)[31]。
2)基于统计方法。受地物复杂度和高光谱数据空间分辨率影响,像元光谱蕴含多种地物信息。当高光谱数据为高度混合时,基于几何的解混方法效果较差,基于统计的方法可以适用于处理高度混合的像元,同时获得端元矩阵和丰度矩阵。主要的统计方法有独立成分分析法(independent component analysis,ICA)和非负矩阵分解法(nonnegative matrix factorization,NMF)。ICA算法最早由Jutten等提出[32-33],通过估计分离矩阵使输出信号接近于输入信号,但该方法基于LMM约束端元和丰度的相互独立性,容易得到不正确的端元,在高光谱解混应用方面容易受到约束。Lee等[34]正式提出NMF概念。NMF是一种盲源分离算法,把一个非负数据矩阵分解为2个非负矩阵的乘积。该方法不需要纯像元的假设,但求解中存在局部最小值问题,一般需要加入端元和丰度约束。把非负矩阵分解和最小体积约束相结合(minimum volume constrained-NMF,MVC-NMF)进行光谱解混的方法可以不依赖于纯像元假设,且保证得到的端元矩阵和丰度矩阵是非负的[35]。
ICA与NMF算法在端元和丰度信息完全未知的情况下提取混合像元中的隐含信息,属于非监督的解混算法,2种方法都需要先给出一个目标函数,再通过优化算法进行求解。基于统计学方法可以从混合光谱中直接分离得到的端元矩阵和丰度矩阵,但相比于几何解混法计算复杂度相对较高,降低了高光谱解混效率。
3)稀疏解混法。基于光谱库的稀疏解混也是将端元提取和丰度估计联合起来进行求解的。用已知的光谱库作为端元矩阵,光谱库中光谱数量远远大于实际端元数量,混合光谱与端元集向量之间具有稀疏关系,这样就把解混问题转化为组合优化问题,实际是一种稀疏回归的问题[36]。Iordache等[37]首次提出基于光谱库的半监督的稀疏解混法,把光谱库引入到线性模型中代替端元集,利用高光谱数据与l1范数结合提出一种基于l1范数稀疏性约束的快速稀疏解混算法(sparse unmixing via variable splitting augmented Lagrangian,SUnSAL),提高了解混的效率;但由于真实的光谱数据与光谱库中的数据存在一定的差异,解混精度并不理想。后期逐渐对稀疏解混算法进行改进,将协同稀疏约束与稀疏解混算法相结合提出协作稀疏解混算法(collaborative SUnSAL,CLSUnSAL),对混合高光谱数据添加全局行稀疏性[38];利用丰度数据的空间连续性把总变分约束(total variation,TV)与SUnSAL相结合的算法(SUnSAL-TV)考虑数据的空间信息,具有较好的鲁棒性[39-40]。这些改进后的解混算法比l1稀疏性方法具有更高的解混能力。
此外,学者们还把稀疏约束和NMF相结合,求解效率和精度都有较大的提高,优于传统的NMF解混方法[41-42]。Lin等[43]提出了一种基于矿物单次散射反照率光谱库稀疏解混算法,利用简化的Hapke模型把混合矿物反射率转变为单次散射反照率,构建单次散射反照率光谱库,再与稀疏解混算法相结合求解端元丰度。稀疏解混算法不受端元提取准确性的影响,也不依赖于纯像元的假设,但是对光谱库的依赖性较大,光谱库中光谱数量较大,光谱间往往存在较高的相关性,在一定程度上增加了解混的难度。
2.2 数据驱动法
1)神经网络解混。20世纪90年代神经网络开始应用于遥感领域[44],它以神经元数学模型为基础可以学习复杂的非线性特征,具有较强的非线性映射能力[45];相比于传统的手动计算法具有更高的效率,已成功地应用于高光谱混合像元分解。传统神经网络结构较为简单,包括输入层、隐藏层和输出层。隐藏层用于提取特征信息,在不需要先验知识的前提下可以学习数据中的复杂关系。利用传统神经网络解混时容易出现过拟合问题,由于隐层学习不充分,往往导致特征提取能力不足。此外,特征提取和丰度估计一般也需要分别进行训练。
深度学习是一种强大的神经网络学习技术,可以对多层神经网络进行训练,其特点是一次无监督学习只训练一层,把训练结果作为下一层的输入,而且采用“自上而下”的方法对所有层进行微调,克服了传统神经网络的不足。Su等[46]基于深度神经网络的理论,提出了一种堆栈非负稀疏自编码解混方法(stacked nonnegative sparse autoencoders,SNSA),用于处理异常值和降低信噪比;通过一系列自动编码器处理异常值,最后一组编码器通过稀疏编码策略用于矩阵分解。Palsson等[47]基于改进的自编码神经网络方法,同时进行端元识别和丰度计算,测定了不同的激活函数和目标函数在解混方面的性能,并证明该方法对高光谱解混具有较强的鲁棒性。Savas等[48]提出了一种端对端的解混算法,并验证改进后的神经网络模型适用于高光谱解混。
基于深度学习的解混方法不需要预先分析解混的实际情形与学习数据间复杂的非线性关系,求解方便,还具有较强的抗噪性和容错性。进行高光谱数据解混通常也面临何时停止训练和隐层层数设置等问题。目前应用神经网络对高光谱进行解混的研究还处于探索阶段,高光谱解混的案例与传统方法相比应用较少,在混合矿物光谱解混方面的应用更少。
2)核函数法。核函数解混法是利用核函数,把训练样本从低维空间的非线性解混问题转化到高维空间的线性解混问题[49]。采用核函数法可以将高维空间的内积运算转换到低维空间的核函数运算,可以有效地避免较高的特征空间维度。应用该方法需先对数据进行预处理,利用核函数构造核矩阵,再基于相关算法处理核矩阵得到模式函数,然后再进行解混。常用的核函数非线性解混方法有核正交子空间投影算法(kernel orthogonal subspace projection,KOSP)[50]和核化的全约束最小二乘(kernel-FCLS,KFCLS)[51]。二者都是通过定义全局准则选择特征向量表征数据结构,然后将混合像素投影到特征向量上并利用FCLS进行计算。多核支持向量机(multiple kernel support vector machine,MKSVM)[52],在SVM的基础上以线性加权组合核函数代替单核数,采用简单多核学习方法迭代解算权系数实现分类,然后通过S型函数将分类器输出值转化为后验概率,利用后验慨率实现高光谱影像的非线性解混。
当高光谱数据像元包含多种地物信息时,基于核函数解混方法优于传统的解混方法。但目前基于核函数的混合像元分解主要集中于对方法的改进优化方面,在矿物高光谱解混方面应用核函数与线性模型相结合处理非线性的光谱混合研究还相对较少。
3)流形学习方法。流形学习是一种非监督的机器学习算法,可以处理复杂的高维度数据。流形学习的主要思想是假设高维空间给定的样本集处于同一流形,这样就把高光谱图像所在的高维空间映射到低维流形局部邻域中[53]。由于高光谱影像的高维度特征,在保留数据集大部分信息的前提下对输入的训练数据进行降维处理是实验的关键,该方法可以有效地对高维数据进行降维处理,获取数据内部的几何结构和规律。流形学习典型代表方法是局部线性嵌入(local linear embedding,LIE)。Roweis等[54]基于局部线性嵌入的思想首次提出了一种约束最小乘方的局部线性加权回归的建模方法,采用约束最小平方法计算权重系数,通过混合光谱和其端元空间分布进行回归分析。
流形学习方法计算复杂度较高,难以应用于较大的高光谱图像,由于流形学习解混方法是挖掘高维数据内在关系规律,仅适用于学习内部较为平坦的低维流形,计算较复杂且速度较慢。虽然流形学习法在非线性解混方面具有较大潜力,但目前在解混方面相关的算法和应用较少。
3 实验验证与应用
矿物高光谱解混的算法较多,基于模型驱动的方法理论相对成熟,目前应用较多,随着人工智能的发展,基于数据驱动解混方法逐步得到关注。多种解混方法在实验室模拟光谱数据和野外矿区等高光谱影像的岩矿识别、矿区填图方面得到了验证和应用。不过目前众多实验主要围绕Cuprite地区的AVIRIS高光谱数据开展,高光谱影像解混缺乏真实验证数据集。无论是模型驱动法还是数据驱动解混法都需要加强在高光谱影像数据解混方面的应用。
3.1 实测光谱解混实验
实验室实测光谱数据解混是重要的解混对象,也是进行高光谱解混的基础依据。王亚军等[55]采集新疆包古图地区90个样本进行粉碎制样,应用ASD光谱仪在实验室进行光谱测量,基于光谱匹配方法进行端元识别,应用简化的Hapke模型把岩石样品的反射率转换为SSA,并通过分段滤波以及建立区域光谱库的方法提高矿物识别精度。该方法对长石类矿物含量提取精度达到80.5%,对黏土矿物提取精度达到92.36%。赵恒谦等[17]在实验室选取朱砂、石黄颜料粉末按不同体积比例进行混合量测光谱,用FCLS对混合光谱进行全波段解混,利用比值导数法对单波段进行解混计算各自丰度值,全波段解混的均方根误差较大为28%,单波段解混中有20个波段为强线性波段,误差均在10%以内,解混效果较好。李大朋等[18]基于相同方法对石青和石绿2种矿物颜料进行解混,得到相似的结论,全波段解混反演的石青和石绿丰度值的均方根误差较高,为19%,单波段解混误差精度分别有所提高。由于矿物组分的多样性和复杂性,采用实测方法进行矿物识别难度较大,受到数据样本量的限制,难以验证基于数据驱动的多种解混方法的解混效果。
3.2 模拟光谱解混实验
在验证高光谱解混方法时,普遍采用光谱模拟数据。对不同类型的混合矿物波谱模拟有利于解决实际问题,如对典型蚀变矿物混合波谱的模拟,既建立蚀变带矿物波谱模拟理论基础,同时又为矿床蚀变信息提取的研究提供理论依据;对月壤表面混合矿物光谱的模拟有利于反演月表典型的矿物含量,对月球资源利用具有重要的指导意义[20]。余先川等[2,15]利用美国地质调查局矿物光谱库中天然碱、泻利盐和黝帘石3种地物光谱数据,根据光谱线性混合模型和二次散射模型分别生成2组模拟数据;利用VCA提取端元,分别用FCLS和非线性变换后的FCLS进行解混得到丰度系数,2组数据的端元识别光谱与真实光谱相关系数均在0.99以上,但当地物分布复杂情况加重时,基于线性模型的解混效果变差,基于二次散射的非线性解混效果提升,而且非线性模型具有更好的抗噪性。
基于Hapke模型与线性模型相结合进行解混的实验较多。把单斜辉石、斜方辉石、斜长石、橄榄石和钛铁矿5种矿物端元非线性混合的反射光谱转换为SSA,随机生成混合像元,采用FCLS方法进行解混并与真实值进行比较分析,得出单斜辉石、斜方辉石和斜长石3种端元矿物反演含量与真实含量相关系数分别为0.85、0.78和0.66,橄榄石和钛铁矿的反演结果相关系数相对较差为0.54和0.23[20]。把Hapke模型与多种线性解混算法相结合对模拟的火星表面的岩矿样本和在可见光-近红波段内卫星采集的样本进行解混时[56],对于模拟的已知的二元、三元混合光谱解混精度在5%~10%误差以内,但对于未知端元的多端元光谱解混误差达到了25%。林红磊等[4]从美国布朗大学Relab光谱库中选取混合矿物光谱转变为SSA光谱库,以半监督方式基于SSA稀疏解混模型得到矿物的丰度,与真实含量相比反演结果的平均绝对误差为3.12%,线性拟合相关系数的均值为0.997 7,非线性稀疏解混具有较高的精度。对石英和明矾石按照已知的比例进行混合,利用LIM、MMP、LMM和Hapke模型分别进行解混,Hapke模型获取的丰度系数与真实比例最为接近,LIM、MMP具有相似结果,LMM模型获取的结果与真实比例差异最大[3]。
3.3 高光谱影像解混和矿区填图
目前高光谱解混在矿物识别和矿区填图等方面也取得了较好的应用。对不同矿区或月球表面的岩矿样本组分及含量的分析有助于研究岩石成因、地质构造、岩浆演化、历史演变等重要课题[57]。
美国内华达州Cuprite地区的AVIRIS高光谱数据是学者研究的热点,对该地区矿物填图研究已经取得较大进展。余先川等[15]利用VCA方法提取6种矿物端元,并证明基于二次散射的非线性模型的填图结果显著优于LMM模型解混的填图结果,而且每个像元所填矿物种类为3时填图结果更优。在对AVIRIS高光谱数据进行解混时,Heylen等[3]采用重建误差验证解混结果,结果表明LIM和MMP模型获取相对重建误差比LMM模型获取的重建误差好,但Hapke模型对像元的重建误差要高于LMM模型,证明Hapke模型对于AVIRIS数据高光谱解混并不是最理想的解混模型。
林娜等[49]采用核函数方法对AVIRIS高光谱数据解混时,证明基于该方法的解混结果明显优于传统的NCLS和FCLS等解混方法;以明矾石和高岭石为例,核化的正交子空间投影、核化的非约束的最小二乘和核化的全约束最小二乘获取的均方根均值误差分别为0.61%、0.315和0.17%,在未核化情况下误差分别为2.7%、0.92和0.3%,误差明显增大。Heylen等[58]应用等距映射算法,把AVIRIS高光谱数据流映射到低维非线性空间,使用改进的内部体积最大法提取端元,并利用单形体体积的比值来计算端元丰度;该方法与利用传统的内部体积最大法提取端元、FCLS计算的丰度结果进行比较,在端元数量设置为14时,利用传统的内部体积最大法提取的高岭石、蒙脱石和明矾石与USGS光谱库的光谱比较,光谱角误差分别为0.056、0.048和0.043,利用改进的方法在端元数量为16时计算的光谱角分别为0.070、0.049和0.056,2种方法端元提取效果相似,但改进后的方法在高光谱降维处理方面计算效率显著提升。
利用端对端的改进后的自编码网络对AVIRIS的12种矿物解混的平均光谱角误差为0.095[48];利用SNSA方法对AVIRIS数据集进行解混时,SNSA、内部体积最大法、VCA和MVC-NMF的光谱角误差分别为0.088 9、0.105 1、0.098 9和0.090 1[46],实验证明神经网络具有比传统解混方法更高的解混精度。除此之外,张霞等[59]使用协同稀疏解混对火星Eberswalde撞击坑三角洲进行矿物丰度反演,得到斜长石丰度为51%、高钙辉石丰度为29%、低钙辉石丰度为6%和锂蒙脱石丰度为10%,获得了较好的解混结果。
4 结束语
通过对混合模型、解混算法和目前已开展的解混实验分析,概括总结如下。
1)线性模型物理意义简单,易于理解和计算,应用最为广泛;对于矿物粒子而言,Hapke 模型可以详细描述混合特征。基于混合模型的解混方法比较成熟,如VCA等端元识别算法和FCLS丰度求解算法依然是当前较为常用的解混方法,这种线性解混方法对矿物光谱解混精度往往较低,不能满足研究需求。近年来,把Hapke模型与线性解混相结合进行光谱解混的研究和应用逐渐增多,可以明显提高光谱解混精度,但是对参数要求较高,模型计算往往较为复杂。传统解混算法一般是基于模型驱动的非监督算法,解混结果的好坏对混合像元数量、噪声干扰、特征的选取、算法设计这几个因素的依赖性很大,任意一个因素都有可能对最终解混结果产生较大的影响。把线性与非线性混合模型相结合以提高解混精度、降低噪声干扰等是基于模型驱动算法方面需要进一步深入研究的方向。
2)基于数据驱动的解混方法可以降低计算复杂性,提高解混效率,已经逐渐应用于矿物高光谱解混。虽然流形学习和核函数法具有较强的非线性映射能力,但目前在光谱解混方面仍然处于起步阶段,应用于矿物解混的研究较少。神经网络可以学习复杂的非线性关系,具有较强的抗噪性和容错性,近年来基于神经网络解混的研究逐渐增多,由于深度神经网络训练的可监督性、较强的泛化性能、优于传统算法的抗噪能力和提取复杂特征等优点,已经成为学者关注的焦点,在非线性光谱解混方面取得一定的成果,但是目前处于探索阶段。未来提高流形学习的抗噪性、深刻探究内部的数学理论以及对核函数算法进行改进、降低求解复杂度等是进一步深入探究的方向,对混合矿物高光谱解混将会产生重要影响。应用神经网络进行矿物高光谱解混也存在一些需要解决的问题:端元数目的不确定性增加了端元识别的难度;基于数据驱动的解混方法需要大量的标签数据,目前缺乏大量的标签数据;对于深度神经网络的隐层物理意义理解不足,隐藏层层数的设定不明确等。因此,建立大量优质的标签数据库、深入地挖掘神经网络内部的物理含义、在端元数目未知情况下训练深度神经网络等是未来应用深度学习进行矿物解混的重要研究方向。
