一种基于CNN/CTC的端到端普通话语音识别方法
2020-07-27潘粤成刘卓潘文豪蔡典仑韦政松
潘粤成 刘卓 潘文豪 蔡典仑 韦政松

摘 要:为了实现离线状态较高正确率的中文普通话语音识别,提出一种基于深度全卷积神经网络CNN表征的语音识别系统的声学模型,将频谱图作为输入,在模型结构上参考了VGG模型。在输出端,该模型可以与连接时序分类完美结合,从而实现整个模型的端到端训练,将声波信号转换成普通话拼音序列。语言模型则采用最大熵马尔可夫模型,将拼音序列转换为中文文本。实验表明,此算法在测试集上已经获得了80.82%的正确率。
关键词:卷积神经网络;中文语音识别;连接时序分类;端到端系统
中图分类号:TN912.34;TP399 文献标识码:A 文章编号:2096-4706(2020)05-0065-04
An End-to-End Mandarin Speech Recognition Method Based on CNN/CTC
PAN Yuecheng1,LIU Zhuo1,PAN Wenhao1,CAI Dianlun2,WEI Zhengsong1
(1.School of Automation Science and Engineering,South China University of Technology,Guangzhou 510641,China;
2.School of Mechanical and Automotive Engineering,South China University of Technology,Guangzhou 510641,China)
Abstract:In order to achieve Mandarin speech recognition with higher accuracy in offline state,we come up with an acoustic model of a speech recognition system based on deep full convolutional neural network(CNN). We choose the spectrogram of acoustic signals as input. As for the structure of the model,we refer the VGG model. At the output end,the model can be perfectly combined with the connectionist temporal classification (CTC). We realize the end-to-end training of the entire model using this method,and the acoustic signal is directly converted into a Mandarin Pinyin sequence. Our language model uses the Maximum Entropy Markov Model to convert Pinyin sequences into Chinese text. Our experiments show that this algorithm has achieved 80.82% accuracy on our test set.
Keywords:convolutional neural network;Chinese speech recognition;connectionist temporal classification;end-to-end system
0 引 言
近些年,深度學习在人工智能领域取得了无可替代的地位,深度神经网络逐渐替代了传统的GMM-HMM模型。为了实现离线状态正确率较高的中文普通话语音识别,本文提出一种基于CNN表征的语音识别系统的声学模型,采用CNN/CTC的方法,此算法在测试集上已经获得了80.82%的正确率。
1 项目背景
语音识别技术,是让机器通过语音识别把语音信号转化为相应的文本信号或者命令的技术[1]。近些年,深度学习在人工智能领域迅速发展,对语音识别也产生了深远影响,而且已经初步应用于车载系统、手机、搜索引擎、电子商务、机器人等多个领域,深层的神经网络逐渐替代了传统的GMM-HMM模型[2]。传统的语音识别声学模型通常采用梅尔频率倒谱系数特征(MFCC,Mel Frequency Cepstrum Coefficient)对GMM-HMM建模,但是MFCC特征具有短时性,容易受环境中噪声的影响,鲁棒性较差,还容易忽略帧间的相关性[3]。
对语音识别而言,传统的模板匹配方法、统计学习方法已趋成熟甚至出现了瓶颈,而利用神经网络进行语音识别因其巨大优势而方兴未艾[4]。最近人工智能成为热门话题,神经网络的研究得到飞速发展,如何用神经网络进行语音识别的问题得到一定程度上的解决。常用的深度置信神经网络(DBN,Deep Belief Network)在语音识别中得到了广泛的应用[5],在DBN网络后增加一个输出层,则形成一个深度神经网络(DNN,Deep Neural Networks),基于HMM-DNN模型的语音识别系统在识别正确率上较GMM-HMM模型取得了很大的提高[6,7],但基于HMM-DNN模型的语音识别是由声学模型、语言模型和字典三个模块组成的,需要语言学知识,导致对一种新的语言搭建识别系统非常困难。卷积神经网络(CNN,Convolutional Neural Network)提供了一种平移不变性卷积,可以对语音多样性进行良好的改善,提高搭建语音识别系统的效率。
Graves提出连接时序分类技术CTC(Connectionist Temporal Classification)[8]。CTC是一种用于序列建模的工具,训练样本无需对齐,其核心是定义了特殊的目标函数。
文献[5]提出了一种基于CNN的语音识别方法,本文基于华南理工大学国家级创新创业项目“自学习语音交互系统的研究与开发”的研究,在使用CNN的基础上在输出端加入连接时序分类,从而实现整个模型的端到端训练,在很大程度上降低了构建语音识别系统的难度。
2 基于CNN/CTC的端到端普通话语音识别方法
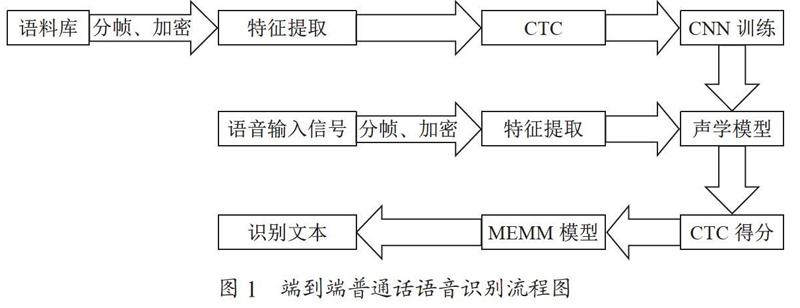
本文的端到端普通话语音识别方法如图1所示,主要有以下几个步骤:
(1)特征提取,将普通的wav语音信号通过分帧、加窗等操作转换为卷积神经网络需要的二维频谱图像信号,即语音频谱图;
(2)声学模型训练,基于Keras和TensorFlow两种网络模型进行训练;
(3)CTC解码,在声学模型输出中,往往包含了大量连续并且重復的符号,为此,我们需要将连续重复的符号合并为同一个符号,然后再除去静音分隔标记符,最终得到实际的拼音符号序列;
(4)语言模型转换,使用MEMM模型,将拼音符号转换成最终的文本并输出。
3 VGG网络结构
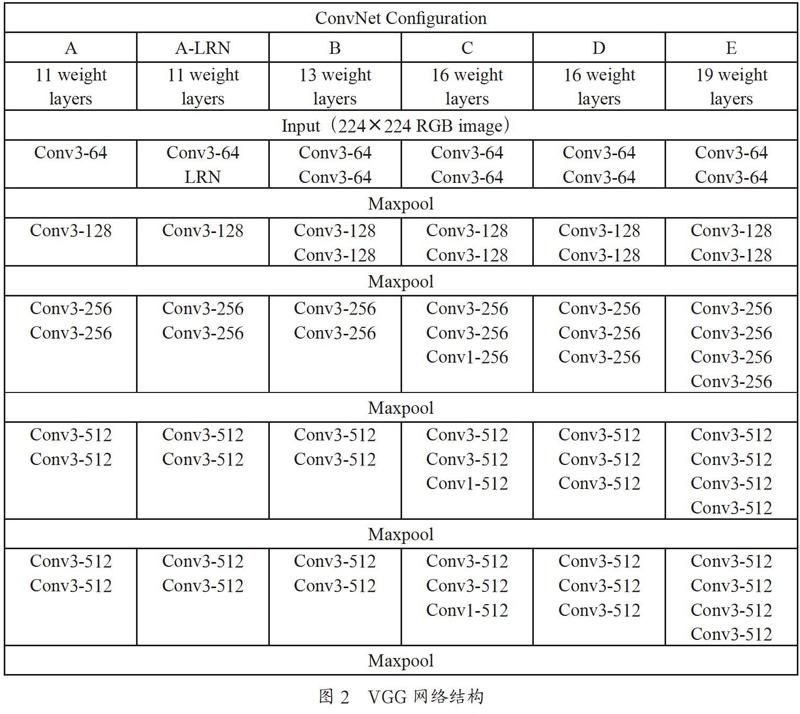
本文在模型结构上参考了VGG模型,VGG网络结构相比之前的RNN有着更强的鲁棒性,并且表达能力非常强,可以看到很长的历史和未来信息。
VGG包括VGG16和VGG19,它们的网络深度不同,如图2所示。
4 连接时序分类
连接时序分类是在自动语音识别技术中计算损失函数的一种方法。与传统的声学模型训练比较,CTC使用的是端到端训练,并不需要输出文字与输入语音在时间上对齐,只需要给定输入端和输出端的序列,CTC输出的就是序列预测的概率,这种方式在很大程度上降低了构建语音识别系统的难度。其结构如图3所示。
4.1 前向算法
前向变量为α(t,u),表示t时刻在节点u的前向概率值,其中u∈[1,2U+1]。
初始化:
α(1,1)=
α(1,2)=
α(1,u)=0,?u>2
递推关系:
α(t,u)=
其中,f(u)=
4.2 后向算法
初始化:
β(T,U′)=1
β(T,U′-1)=1
β(T,u)=0,?u α(1,u)=0,?u>2 递推关系: β(t,u)= 其中,f(u)= 4.3 取对数 ln(a+b)=lna+ln(1+elnb-lna) 4.4 最大似然函数 CTC的损失函数使用最大似然函数: L(S)= L(x,z)=-lnp(z|x) 根据前后向变量,可求得: p(z|x)= 从而得到: L(x,z)= 4.5 BP训练过程 表示t时刻输出k的概率, 表示t时刻对应输出节点k在做softmax转换之前的值: 考虑:t时刻经过k节点的路径。 其中B(z,k)表示节点为k的集合。 考虑:α(t,u)β(t,u)=, 其中X(t,u)表示所有在t时刻经过节点u的路径。 则: 得到损失函数对 的偏导数: 同时可以得到损失函数对 的偏导数: 后续可以使用BPTT算法得到损失函数对神经网络参数的偏导[9]。 5 最大熵马尔可夫模型 最大熵模型是在已经先验分布的前提下求解特征函数f(x,y)的最优概率分布P(y|x)。模型如图4所示。 5.1 HMM模型 HMM模型表达式如下: P(X)= 其中,Y为状态序列,X为观测序列,p(yi|yi-1)为从yi-1到yi的条件概率分布,p(xi|yi)为状态yi的输出观测概率,初始概率为P0(y)。显然,HMM依赖已知的概率分布和历史经验来实现决策,但实际上能提供的训练数据是少量且稀疏的,我们不可能知道所有的数据分布情况。所以需要接下来介绍的MEMM来解决在数据稀疏的条件下估计未知x,y的条件概率这个问题。 5.2 MEMM模型 MEMM模型表达式如下: i=1,2,…,T MEMM用p(yi|yi-1,xi)来代替HMM中的p(yi|yi-1)和p(xi|yi),根据先前状态和当前观测预测当前状态。每个分布函数pyi-1(yi|xi)都是一个服从最大熵分布的指数模型。MEMM在限定条件下求解最优条件概率,在训练过程中使特征多项式fi(x,y)收敛于λi,并求解此时的xi与yi-1的正则化因子,在此解码过程中直接求得条件概率p(yi|yi-1,xi)。[10]
6 结果及分析
为了检验基于CNN/CTC的端到端普通话语音识别方法的有效性,我们使用此方法训练出声学模型,实验中使用了清华大学THCHS-30中文语音数据集、Free ST Chinese Mandarin Corpus数据集、AISHELL-1开源版数据集、Primewords Chinese Corpus Set 1数据集、aidatatang_200zh数据集、MagicData数据集。其中训练语音625 000句,验证集语音2 000句。由于连续语音识别结果为一连串的词语,所以我们可以使用词错误率(Word error rate,WER)作为一个评测标准,词错误率与系统性能成反比。
本实验使用的CNN网络输入层为200维的特征值序列,一条语音数据最大长度为1 600,约为16 s;隐藏层包括10个卷积层、5个池化层、1个Reshape层、2个全连接层,卷积核大小为3×3,池化窗口大小为2;输出层维度为神经网络最终输出的每一個字符向量维度的大小,激活函数使用softmax;CTC层使用loss作为损失函数,实现连接性时序多输出。
从表1中数据可以得出,文中基于CNN/CTC的端到端普通话语音识别方法在验证集上词错率为19.18%。文献[11]中给出的基于卷积神经网络算法的语音识别算法在THCHS30数据库上测试错率在22.19%~23.68%之间,相比之下,本文加入CTC层后词错误率下降3.01%~4.50%左右。
下面来看基于CNN/CTC的端到端普通话语音识别方法的训练过程。本实验设置迭代轮数epoch为50,每500步保存一次模型,每次训练16个数据。图5为此方法的训练收敛曲线。
可见,训练loss最终收敛在20%左右。
验证数据的收敛曲线
7 结 论
通过在CNN的基础上加入CTC层,大大减少了构建语音识别系统的难度,为实现离线语音识别提供了一种方法,其语音识别正确率达到80.82%。在今后的工作中,拟尝试加入针对说话人进行识别的功能,做一个说话人识别系统,以解决语音识别系统应用在很多场景时的问题。
参考文献:
[1] 张德良.深度神经网络在中文语音识别系统中的实现 [D].北京:北京交通大学,2015.
[2] 林俊潜.基于神经网络和小波变换的语音识别系统研究 [D].广州:广东工业大学,2013.
[3] 郑文秀,赵峻毅,文心怡,等.一种基于瓶颈复合特征的声学模型建立方法 [J/OL].计算机工程:1-6(2019-12-16).https://doi.org/10.19678/j.issn.1000-3428.0056278.
[4] 唐美丽,胡琼,马廷淮.基于循环神经网络的语音识别研究 [J].现代电子技术,2019,42(14):152-156.
[5] 王嘉伟.基于卷积神经网络的语音识别研究 [J].科学技术创新,2019(31):71-73.
[6] DAHL G E,YU D,DENG L,et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition [J].IEEE Transactions on Audio,Speech and Language Processing,2012,20(1):30-42.
[7] SEIDE F,LI G,YU D. Conversational speech transcription using context-dependent deep neural networks [C]//12th Annual Conference of the International Speech Communication Association,2011.
[8] GRAVES A,FERN?NDEZ S,GOMEZ F. Connectionist temporal classification:Labelling unsegmented sequence data with recurrent neural networks [C]// Machine Learning,Proceedings of the Twenty-Third International Conference (ICML 2006),2006:369-376.
[9] GRAVES A. Supervised Sequence Labelling with Recurrent Neural Networks [M]. Berlin,Heidelberg:Springer Berlin Heidelberg,2012:52-81.
[10] KLINGER R,TOMANEK K. Classical Probabilistic Models and Conditional Random Fields [J].Algorithm Engineering Report,2007,2(13):5-6
[11] 杨洋,汪毓铎.基于改进卷积神经网络算法的语音识别 [J].应用声学,2018,37(6):940-946.
作者简介:潘粤成(1998-),男,汉族,广西融水人,就读于自动化专业,本科在读,研究方向:自动语音识别。
