基于边缘计算的道路行程时间预测
2020-07-27黄相铭祝嘉辉祝富锴高岩
黄相铭 祝嘉辉 祝富锴 高岩

摘 要:为了解决目前市面上的导航软件无法针对用户个性化预测的问题,本文提出了基于边缘计算的道路行程时间预测的预测思想,并在之后就系统架构和预测过程进行了详细论述。为了实现个性化预测,本文根据速度变化特征将用户的行为模式分成了三类,并对每一类行为模式构建了对应的数据集。在基于用户行为模式的预测算法方面,本文对每一类数据集分别应用了ELM模型和LSTM模型,通过对模型的预测表现进行对比确定了最优模型,并将模型及其参数装载到边缘端。
最终,本文通过大量的实验,将该研究所提供的时间预测和百度地图提供的时间预测进行对比,验证了本文研究内容的可行性和准确性;以实例证明了本文设计并实现的道路行程时间预测原型系统的实用性和有效性。
关键词:道路行程时间预测方法;边缘计算;行为模式分类
中图分类号:TP391 文献标识码:A
Abstract: This paper first proposes a framework of road travel time prediction based on edge computation, and then elaborates its system architecture and prediction process. The navigation software in current market does not make personalized prediction for users. In order to achieve personalized prediction, users' behavior patterns will be classified into three categories based on characteristics of driving speed changes. For each of these three categories, the corresponding data sets are collected. With regard to prediction algorithm based on users' behavior patterns, the optimal model is determined by comparing the prediction performance of ELM and LSTM models, which are trained with data sets separately. And then, the optimal model and its parameters are loaded to the ends of edge computing. Finally, a large number of experiments are conducted by comparing the time prediction presented in this research with that of Baidu Map so to verify the feasibility and accuracy of this framework. The prototype system of road travel time prediction designed and implemented in this paper is proved to be practical and effective with real cases.
Keywords: road travel time prediction method; edge computing; classification of behavior patterns
1 引言(Introduction)
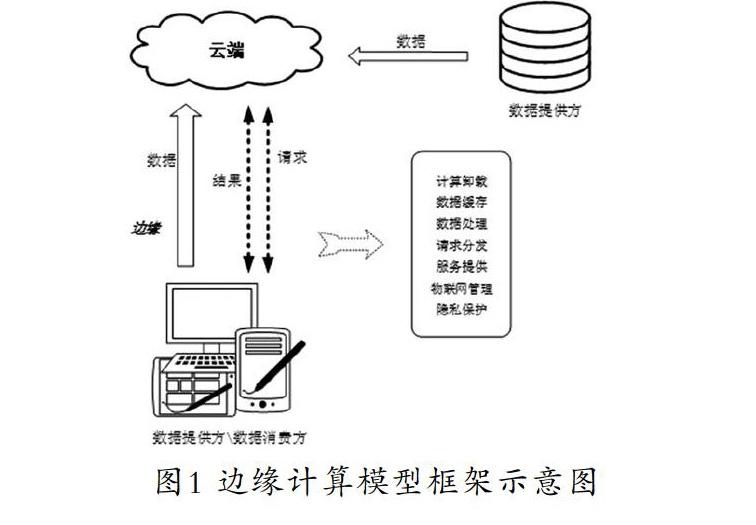
一直以来,城市道路交通所追求的是人、车、路的密切配合与和谐统一,因此尽可能地提高道路交通运行的效率、确保交通运行的安全度、提高能源的利用率并且改善环境成为人类的共同目标。一种能够实现准确、实时、高效率地对城市道路交通信息进行大范围处理的智能交通系统便成了时代发展所需。边缘计算指的是在网络的边缘来处理数据,这样能够减少请求响应时间、提升电池续航能力、减少网络带宽同时保证数据的安全性和私密性[1-4]。边缘计算模型框架示意图如图1所示。
相关研究表明,与云计算模型相比,边缘计算的优势主要体现在几个方面。
在文献[5]的实验中,研究人员将人脸识别的计算过程从云端移动到边缘端,响应时间由900毫秒缩减到169毫秒。
在文献[6]中,实验人员在研究可穿戴的认知辅助设备时,将部分计算任务从云端卸载到边缘端,整个系统对资源的消耗减少了30%—40%。
文献[7]提出的Clone Cloud模型,将部分处理任务从云端转移到边缘端,使得数据在分区、迁移与合并等方面减少了20倍的时间。
综上所述,边缘计算模型更适合在移动边缘端处理用户所产生的数据,低延迟和高效率更加契合了当今人们在快节奏时代的日常所需。对于本就强调实时性的“智慧交通”的分支——道路行程时间预测,边缘计算无疑是一个与之最为匹配的计算模型。
2 基于边缘计算的道路行程时间预测框架(Framework of road travel time prediction based on edge computing)
2.1 預测过程及研究架构
预测过程主要分为两大部分,即云端处理部分和边缘端预测部分。本小节将分别阐述两部分的运作过程。研究架构如图2所示。
云端:我们将搜集到的不同行人的步行GPS数据在云端进行数据预处理,将经纬度坐标值序列根据前述方法转换为速度序列,去掉了无效数据;其次基于用户的速度变化情况,对不同行为模式进行了分析和分类,基于不同的速度变化方式来构建数据集;之后主要采用ELM模型和LSTM模型对不同的行为模式所对应的数据集进行训练,通过调参和模型评判,得到了每种模式所对应的最优速度预测模型,并保存下来,装载到边缘端。
边缘端:用户首先需要选定出发点和终点,一旦选定,路径规划将自动完成。用户的初始道路总剩余时间将由冷启动机制下的初始速度和路径总长度计算得来。冷启动过程中,边缘端将实时接收用户的GPS轨迹点,并根据前述方法计算用户的实时速度。冷启动结束后,边缘端将基于之前搜集到的速度,判断用户的行为模式,调用预先训练好的模型来预测下一阶段的速度,再结合剩余路径距离预测出剩余行程时间,从而实现基于边缘计算的道路行程时间预测的实时周期更新。当发现用户行为模式改变,边缘端将调用与新模式对应的预测模型;当预测值和真实值有较大偏差时,边缘端将做适当调整。
2.2 基于行为模式的速度预测方法
2.2.1 基于ELM模型的速度预测建模和预测过程
ELM预测模型整体需要输入的数据为,
如果分段表示的话即为,其中表示整个训练数据集的长度,表示步长。基于ELM模型的速度预测方法网络图如图3所示,其中为输入数据,是输入权重,为偏置,为输出偏重,为要预测的速度,通过训练得出输入和输出之间的关系,其中和可以随机输入。
根据图3可知,基于ELM的速度预测方法的训练过程包括以下几个步骤:
输入训练集数据、选定激活函数和隐藏层节点个数。不同的激活函数可能会造成不同的预测结果,所以要选定激活函数。ELM模型中隐含层神经元个数和预测步长均会影响ELM的预测效果,本文会通过大量的实验来找到最优的神经元个数和预测步长。
随机设置输入权值和隐藏层节点偏置。在ELM模型的学习过程中,输入权值矩阵和隐含层偏置矩阵是随机生成的,这样学习训练的结果很快。
当ELM模型中所需要的预测步长、参数节点个数、输入权值和均确定后即可根据训练集進行训练,首先计算出输入矩阵的广义逆矩阵。
计算ELM预测模型中隐含层到输出层的输出权值。将确定后,整个模型最终确定。因为输入权值矩阵和隐含层偏置矩阵是随机生成的,多试验几次,并且用测试集对其进行测试,计算预测误差,选取最优的预测模型。
将训练模型用的输入权值,隐藏节点偏置,隐藏层节点个数,预测步长和隐藏层到输出层的权值保存下来,以便以后进行预测使用。
2.2.2 基于LSTM模型的速度预测建模和预测过程
LSTM预测模型整体需要输入的数据为,如果分段表示的话即为
,其中表示整个训练数据集的长度,表示单词输入的数据维度。基于LSTM模型的速度预测方法网络图如图4所示,其中为输入数据,为输出结果,表示时序,代表输入权重,代表输出权重,代表上一个时刻的输出值在下一次输入之中的权重,是LSTM层与全连接层之间的权重。
根据图4可知,基于LSTM的速度预测方法的训练过程包括以下几个步骤:
输入训练集数据、选定激活函数和隐藏层节点个数。不同的激活函数可能会造成不同的预测结果,LSTM模型中默认的激活函数是tanh函数。
LSTM模型中预测步长、层数、神经元个数均会影响预测效果,本文会通过大量的实验来找到最优的参数选择。
随机设置权重值、、。在LSTM模型的学习过程中,权值矩阵、、的值均是随机生成的,隐藏层神经元的个数决定了初始化多少组参数矩阵,因此参数的设置至关重要。
当LSTM模型中所需要的预测步长,层数,隐藏层神经元个数,输入权重、、均确定后即可根据训练集进行训练,首先计算出输入矩阵的广义逆矩阵。
计算LSTM预测模型中全连接层到输出层的输出权值。将确定后,整个模型最终确定。因为权重值、、是随机生成的,需进行多次实验,选取最优的预测模型。
将整个训练模型及其权重参数以.h5的格式保存下来,以便将来进行预测和调整。
2.3 用户行为模式的分类
我们的预测希望能够为不同行人的不同行为模式提供更精确的个性化服务。因此,对行人的用户行为模式规律性的挖掘具有必要性。本节将结合生活实际的经验,对用户行为模式进行分类。由于在道路行程时间预测的问题中,对速度的预测是至关重要的一个环节,因此我们对步行者的行为模式进行分类是基于用户的速度特征。
根据我们收集到的用户步行数据信息,我们发现均可以用三种基于速度变化特征的行为模式来描述用户的整个步行过程。
2.3.1 用户行为模式的分类
模式一:速度平稳模式。
该步行模式下,行人的速度较为稳定,其速度值并非完全与X轴水平,只是其Y轴上的波动较小。该种模式多出现在行人在某段路程的步行过程中途,因为行人已经达到了由起步到加速,且对路况和目的地都有了一定的了解,因此会保持自己的一种最舒适的状态,不会轻易过分改变现有的速度。这一点与日常生活经验也是相吻合的。
模式二:速度匀变模式。
该步行模式下,行人的速度会改变,但是改变方式呈匀速变化,即其加速度稳定在一定的区间内。当时,步行者的速度呈匀速上升趋势;当时,步行者的速度呈匀速下降趋势,此两种情况均可视为匀速变化模式。此种步行模式可能出现在行人跑步健身过程中,其速度在开始时由慢速逐渐加快,在临近结束时又由快速匀速减慢;或者是行人在行走过程中心里想到了其他事务,速度会不自觉逐渐下降。这与日常生活经验也是相吻合的。
模式三:速度突变模式。
该步行模式下,行人的速度也会改变,但是改变方式并非呈匀速状态,而是剧烈突变,即其加速度并非稳定在一定的区间内。当时,步行者的速度会突然加快;当时,步行者的速度会突然减慢,此两种情况均可视为速度突变模式。在生活中,这样的速度变化方式是常见的,比如当一个行人在行进过程中突然发现前方有一位熟人,于是快速提速并赶上,之后和熟人谈论,并一同慢速前行。在上述所描述的情境中,分别发生了速度突然变快和速度突然变慢的情况。这与生活实际经验相符,也同时印证了上一节所论述的行人步行过程的非均质性和弱规则性。
上述的基于用户速度变化的分类方式具有可行性和合理性,与实际生活经验相符,能够合理刻画出用户的步行过程。
2.3.2 用户行为模式的判别
在实际预测过程中,当用户行为模式发生改变时,边缘端需要更换对应的装载好的模型去做预测。这就为我们判断用户行为模式的改变提出了要求。本文拟采用最小二乘法直线拟合方式来判断用户的行为模式。
在每次判断用户的行为模式是否发生改变之前,边缘端会收集行人的个GPS轨迹数据,并计算出速度值序列。简便起见,不妨设此时得到个速度值分别为:,为了应用最小二乘法,我们将其转换成坐标格式,即为:。
假设我们需要拟合的直线方程为,根据最小二乘法的原理,我们需要让总的最小平方误差尽可能小,的计算方法如公式(1)所示。
我们最终可以推导出直线方程的斜率的值如公式(2)所示。
在确定了直线公式后,我们再将带入公式(1)计算出对应的,然后我们对和分别设置阈值和,并据此得出三类行为模式的判别方式。行为模式判别的流程图如图5所示。
在实际预测过程中,阈值和通过大量的实验数据得来。本文研究中分别将上述两个阈值设置为,。于是每当边缘端收集到个GPS轨迹点计算出速度值序列之后,便依据上述方法判断用户所处的行为模式,之后调用对应的已装载的模型对用户接下来的速度做预测。
3 实验与分析(Experiment and analysis)
3.1 实验环境与数据
本文的实验环境是安装Windows 10操作系统的工作站,具体软硬件配置如表1所示。
实验数据是准确地验证道路行程时间预测模型的关键,实验数据对于实验结果的客观性、准确性、真实性的影响尤为重要。本文所使用的数据主要是通过发动周围同学而得来,通过让他们下载我们的APP,我们能够收集到他们在校园内步行时的GPS数据。当数据量不足时,我们使用数据扰动的方式围绕已有数据上下波动生成足量数据,以便后续实验所需。单次的数据量大小约为8kB—38kB不等。GPS数据采集频率,也即定位时间间隔为1秒。
在这些原始数据的基础上,为了更好地实现用户模式的个性化预测,本文根据用户行为模式分类重新构建了新的数据集,用于对预测方法进行验证。
3.2 评价标准
本文选取的评价指标有以下三种,这些客观的统计学评价指标能够较为准确地评价本文实验的结果。
如表2所示,就速度平稳模式而言,LSTM模型的预测MAPE误差指标更小,表明其预测更为精确,但是其每次的迭代时间较长。虽然ELM模型的预测误差MAPE较LSTM稍大,但仍在较好的可接受范围内,因此对于速度平稳模式,我们最终确定选用ELM模型。
就速度匀变模式而言,ELM模型无论是在MAPE误差还是在用时方面都较LSTM模型更优,因此在该种模式下,我们选用ELM模型。
就速度变模式而言,虽然LSTM模型每迭代一次的时间较长,但是其MAPE误差指标较ELM模型显著更小,表明其预测值显著更优。因此在该种模式下,我们拟采用LSTM模型来做预测。
3.4.6 实验方案六
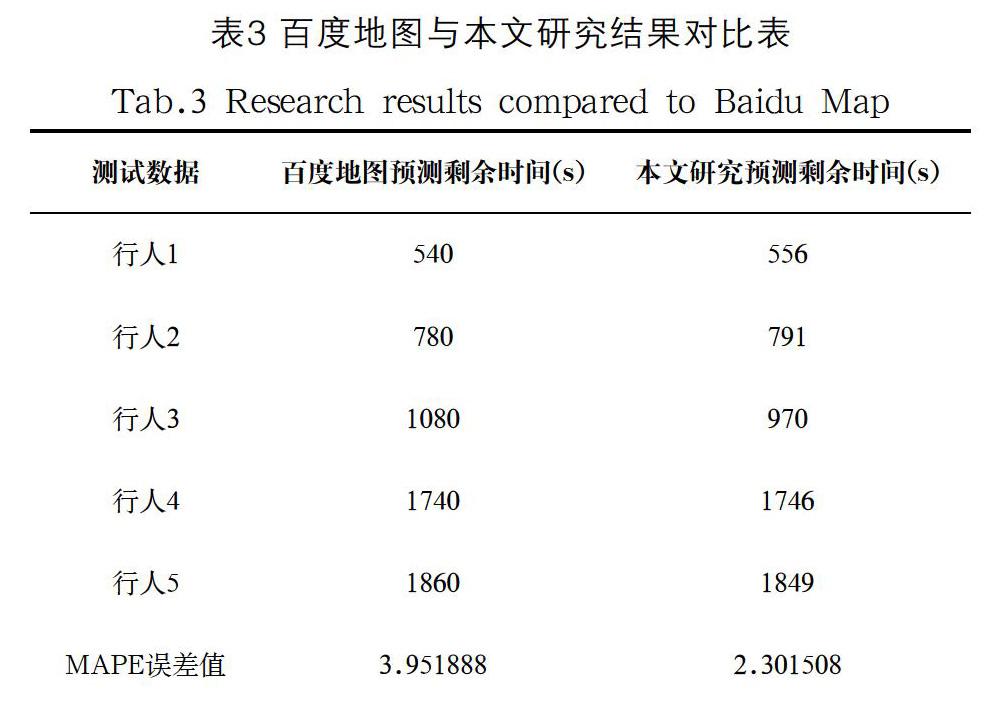
为了将本文研究模型与百度地图预测模型进行对比,我们随机选取了五位行人,记录他们在行程的中间一半处时,百度地图提供的道路剩余时间和本文模型预测的道路剩余时间;同时用秒表记录下了他们实际行走后半程的用时。由于五位行人在行程中的行为模式不固定,因此作出的时间预测并不十分稳定;此外,百度地图的预测时间精度只能精确到分钟,而本文研究内容所提供的时间预测能够精确到秒,这可能也是本文的预测结果更加精确的原因之一。具体的统计和对比结果如表3所示。
由表3可以看出,本文提出的基于边缘计算的道路行程时间预测方法与百度地图内嵌的导航时间预测相比,本文提出的预测模型在实际行人道路行程中预测误差更小,证明了该方法的可行性和准确性。
针对边缘端APP的测试,首先对参数进行设置,然后对原始GPS轨迹数据进行处理,按照前文所述三种用户行为模式类别分别构建数据集,处理结果保存在对应路径下的文件内。之后针对不同行为模式在云端对模型进行训练,将选出的最优模型利用tensorflow lite等工具转换格式并装载到边缘端APP。
完成云端的数据和模型处理后,针对边缘端Android APP进行测试,初始定位在东北大学浑南校区五舍,如图14(a)所示;之后可以键盘输入出发地点和目的地,也可在界面上触屏点击,如图14(b)所示;系统以红色标注提示目的地所在位置,如图14(c)所示;路径生成并显示在APP上,然后界面下方会显示当前路程剩余距离、当前路程剩余時间、当前速度和下一阶段预测速度,如图14(d)所示。
5 结论(Conclusion)
为了解决目前百度地图的道路行程时间预测无法很好地针对步行用户个性化的速度模式进行预测的问题,本文提出了一种基于边缘计算的道路行程时间预测的框架,旨在根据用户前一阶段的速度值序列来预测该用户在下一阶段的速度,从而实现对于不同用户的个性化预测。
在云端处理方面,明确了研究思路之后,本文首先对用户的行为模式基于速度变化特征分成了三类,分别是:速度平稳模式、速度匀变模式和速度突变模式;之后通过对GPS轨迹数据进行预处理,就每一类行为模式构建了对应的数据集。在具体的模型方面,本文对每一类数据集分别应用了ELM模型和LSTM模型,通过对模型的预测表现进行对比确定了最优模型及其参数选择。之后通过随机选取的行人数据,将本文研究所提供的时间预测和百度地图所提供的时间预测进行对比,验证了本文研究内容的可行性和准确性。
在边缘端部分,本文设计并实现了一个Android APP,在将云端预训练好的模型装载到APP中之后,系统会在判别用户行为模式之后调用对应的模型对用户速度进行预测。
此外,本文就用户行为模式的判别和系统冷启动处理等关键问题做了阐述,并给出了可行的解决方案。
参考文献(References)
[1] Shi W, Fellow, IEEE, et al. Edge Computing: Vision and Challenges[J]. IEEE Internet of Things Journal, 2016, 3(5): 637-646.
[2] 施巍松,孫辉,曹杰,等.边缘计算:万物互联时代新型计算模型[J].计算机研究与发展,2017,54(05):907-924.
[3] 李子姝,谢人超,孙礼,等.移动边缘计算综述[J].电信科学,2018,34(01):87-101.
[4] 施巍松,张星洲,王一帆,等.边缘计算:现状与展望[J].计算机研究与发展,2019,56(01):69-89.
[5] Yi S, Hao Z, Qin Z , et al. Fog computing: Platform and applications[C]. 2015 Third IEEE Workshop on Hot Topics in Web Systems and Technologies, 2015: 73-78.
[6] Ha K, Chen Z, Hu W, et al. Towards wearable cognitive assistance[C]. Proceedings of the 12th annual international conference on Mobile systems, applications, and services, 2014: 68-81.
[7] Chun B G, Ihm S, Maniatis P, et al. Clonecloud:elastic execution between mobile device and cloud[C]. Proceedings of the sixth conference on Computer systems, 2011: 301-314.