一种基于Inception结构的神经网络协同过滤推荐算法
2020-07-26金铭李俊
金铭 李俊

摘 要:在商品推荐领域,商品评论信息往往难以得到有效利用。为了充分利用商品评论信息,提高商品推荐系统精度,对NCF神经网络协同过滤模型进行改进,将NCF模型与Inception结构的卷积神经网络相结合,提出基于Inception结构的神经网络协同过滤方法(NCF-i模型),将商品评论信息融入模型进行预测和推荐。首先基于Inception结构的卷积神经网络对商品评论信息进行分析并提取多元特征模型,然后将多元特征模型添加到NCF模型中,通过多层全连接层获取用户、商品及商品评论之间的非线性关系,最后基于此非线性关系对商品进行预测和推荐。通过基于真实数据集的实验证明,应用NCF-i模型的推荐算法,推荐系统的预测精度和稳定性均优于当前常用的推荐模型。
关键词:协同过滤模型;商品评论;商品推荐;Inception结构;神经网络
DOI:10. 11907/rjdk. 192226 开放科学(资源服务)标识码(OSID):
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2020)007-0050-06
An Neural Collaborative Filtering Recommendation Algorithm
Based on Inception Structure
JIN Ming, LI Jun
(School of Computer and Artificial Intelligence, Wenzhou University, Wenzhou 325035, China)
Abstract: In the field of product recommendation, product review information is often difficult to be used effectively. In order to make full use of commodity review information and improve the accuracy of commodity recommendation system, this paper improves the neural network collaborative filtering model of neural collaborative filtering(NCF), combines the NCF model with the convolutional neural network of Inception structure, and proposes a neural network based on Inception structure. The collaborative filtering method (NCF-i model) integrates product review information into the model for prediction and recommendation. The method firstly analyzes the commodity review information based on the convolutional neural network of Inception structure and extracts its multi-feature model. Then, the multi-feature model is added to the NCF model to obtain users, commodities and commodity reviews through multiple layers of all-connected layers. The nonlinear correlation between the two is based on this nonlinear relationship to predict and recommend commodities. Through the experiment based on the real data set, the recommended algorithm of the NCF-i model is applied, and the prediction accuracy and stability of the recommendation system are better than the currently recommended models.
Key Words: collaborative filtering model; commodity review; product recommendation;inception structure; neural network
0 引言
全球每时每刻都产生着海量信息。如何从浩如烟海的信息中获取满足用户需求的信息是计算机领域的研究热点。为解决信息获取问题,计算机領域提出了两种方案,即门户网站和搜索引擎。前者的代表是雅虎公司,雅虎凭借门户网站迅速在计算机领域占据一席之地,而像hao123等门户网站也曾风靡一时,成为中国早期网民的不二之选。但是由于门户网站只能包含有限个目录,而互联网上的信息斑驳复杂,使得门户网站无法满足用户需求,这促使了搜索引擎的崛起。搜索引擎的代表是谷歌和百度,用户可以自己描述需求,使用搜索引擎服务查找到所需要的信息。但是当用户无法准确描述需求的时候,搜索引擎便无法有效地提供服务。因此,能根据用户行为推荐满足用户个性化需求的推荐系统应运而生,在电商网站、新闻网站、视频网站等领域都可以看到推荐系统的影子[1]。
传统的推荐方法主要有3种:基于内容推荐的方法、基于协同过滤的方法和基于混合推荐的方法。基于内容的推荐方法,是根据用户的行为历史,比如用户已经收藏或购买的项目推荐相似的项目。该方法缺点在于,项目的特征需要人工提取,花费大量成本效果却不理想;基于协同过滤方法,是基于相似的用户有相似的兴趣假设,根据与该用户相似的用户所购买或收藏的项目给用户推荐项目。该方法缺点是容易产生冷启动(系统使用初期缺乏数据,无法进行推荐)、数据稀疏(一个用户所评分过的项目占所有项目的比重很小)和无法学习到深层特征问题。基于混合推荐的方法融合了协同过滤和基于内容推荐两种方法的结果,提高了推荐精度[2]。
进入21世纪以来,由于算法水平和硬件水平的大幅度提高,深度学习技术得到了里程碑式的发展。由于深度学习具有非线性结构,有强大的特征提取能力,可以很好地克服传统推荐算法中的冷启动、数据稀疏和提取特征困难等问题。因此,以深度学习为基础的推荐系统是未来推荐系统发展方向。
1 相关工作
目前,国内外许多学者已经在该领域做了大量的工作。Ricci[3-4]建议将评论意见用于产品描述和用户行为研究,他相信商品评论可广泛应用于推荐系统,并可提供更佳的建议;Aciar S、 Zhang D、Simoff S等[5]在Ricci工作的基础上,提出了一种排序机制将商品评论应用于推荐系统。Chen L等[6]對于基于评论的推荐系统两个方面:基于评论的用户配置文件构建以及基于评论的产品概要构建做了详细描述,探讨了基于评论的推荐系统发展趋势;Zhang Z等[7]提出一种新的基于内存协同过滤方法,称为urCF(用户评论增强协同过滤),可以从网络评论中提取用户对单项特征的评价,有效提高了协同过滤效果;Xu J等[8]提出了一种新的个性化推荐模型,即基于主题模型的协同过滤(TMCF),利用扩展的文档主题模型为每个评审生成主题分配,然后获得每个用户的偏好,在很大程度上缓解了稀疏性问题,获得了良好效果;S Raghavan等[9]探讨了在评价中附加权重或质量分数的同时进行协同过滤的可能性。在进行协同过滤时,利用相应的评论数据确定质量分数,对个体评分的重要性进行增权或减权,从而提高预测的准确性。
尽管上述方法取得了一定的成功,但它们都基于传统的因子分解模型对未知项目(item)的评分进行预测,因此无法捕获用户与商品之间复杂的非线性相关信息。 针对这一问题,He等[10]提出了一种神经网络协同过滤模型(Neural Collaborative Filtering,NCF),该模型使用神经网络表示用户和项目之间的非线性关系,提供一种将深度学习应用于推荐系统的新思路。与FM(factorization machine)因子分解机模型相比,NCF模型具有更好的表现能力,能更好地获取用户与项目之间隐含的关系。但是,NCF只利用用户对项目的评分信息,却没有考虑对项目评论等文本信息进行处理和利用,而文本评价往往比简单评分拥有更多的潜在信息,并且更能体现用户的个性化偏好。本文在NCF基础上,提出一种基于Inception结构的神经网络协同过滤方法(NCF-i模型)。该方法首先基于Inception结构的卷积神经网络对商品评论信息进行分析并提取多元特征模型,然后将该多元特征模型添加到NCF神经网络协同过滤模型中,通过多层全连接层获取用户、商品和商品评论之间的非线性关系,最终基于此非线性关系对商品进行预测和推荐。
2 NCF-i模型
常用的NCF模型需要首先将user的id和item的id进行词嵌入,之后将user的id嵌入层与item的id嵌入层进行拼接组成特征层,然后再经过多层全连接层让user的特征和item的特征充分组合,最后输出评分。由于在全连接层输出时会使用非线性的激活函数进行激活,因此NCF模型具有更好的表现能力[11]。
本文针对商品评论的文本中包含用户对于商品的喜好特点,在NCF模型的基础上构建了添加商品评论的NCF -i模型,NCF -i模型结构如图1所示。
下面对Inception结构的卷积神经网络处理商品评论的方法和原理作详细说明,对NCF -i模型的算法实现细节进行详细介绍。
2.1 词嵌入
当对商品评论文本进行处理时,首先应该选择合适的模型对文本进行表达。传统的机器学习方法在处理文本数据时,通常使用词袋模型[12]进行文本表达,但词袋模型往往具有维度高、数据稀疏等特点,无法作为卷积神经网络的输入,因此使用词嵌入[13]的方法进行文本表达。词嵌入就是通过将词语映射到固定的维度获得一个维度低、数据稠密的词向量模型。因此,可以通过词嵌入的方法对文本进行处理,将其转化为维度大小为句子长度与词嵌入维度乘积的二维矩阵。例如可以将文本“canned dog food products”(罐装狗粮商品)进行词嵌入后转化为如下矩阵,如图2所示。
2.2 卷积与池化
有了词嵌入模型便可以应用卷积神经网络对商品评论进行文本处理。卷积神经网络最关键的操作就是卷积和池化。卷积操作就是卷积核依次滑过输入层,与输入层对应的矩阵做内积,最终将结果映射到输出层的过程。卷积神经网络由于卷积核的参数共享,有效减少了需要训练的参数个数。在进行卷积操作时,设定卷积核的深度等于输入层的深度,输出层的深度与卷积核的个数相等。
在使用卷积神经网络对文本进行分析时,由于每个词语都由词嵌入层的一整行数据表示,因此需要让卷积核的宽度和词嵌入的维度相等,否则就无法提取到每个单词的全部信息[15],如图3所示。
在图3中使用的卷积核宽度为2,步长为1,卷积操作后映射成一个一维向量。由于进行文本预处理时会将长文本进行截短,对短文本用占位符进行填充,因此在使用卷积神经网络时无需对输入矩阵进行0填充。
文本向量在使用卷积核进行卷积操作后得到的文本向量维度为:
文本向量维度 = 句子长度 - 卷积核大小 + 1
为了充分提取到商品文本特征,本文使用Inception结构的卷积神经网络[16]。Inception结构使用多个大小不同的滤波器对输入层做卷积和池化操作,之后将得到的映射在深度维度进行拼接。经过这样并行的卷积和池化操作可以提取到卷积层的不同特征。简单的卷积神经网络Inception结构如图4所示。
在图4中,分别使用1*1的卷积核、3*3的卷积核和5*5的卷积核对输入层做卷积,使用3*3的空间窗口对输入层做池化,将并行操作得到的输出层在深度维度上进行拼接,作为最终提取到的特征。测试表明,使用了Inception结构的卷积神经网络在提取特征方面拥有更高的计算效率,效果更好。
具体到将卷积神经网络的Inception结构应用到文本处理时,卷积神经网络可以同时提取到语言模型中多种N元模型特征。相比传统方法,即直接计算文本中的N元模型方法,只能提取到固定的一种N元模型特征[17]。为了获取到文本的多元模型特征,以期望达到更好的效果,在对评论文本做分析时使用Inception结构的卷积神经网络。
此处的语言模型指,如果某一词语出现的概率与前面N个词相关,则称其为N元模型。根据条件概率公式可以得到一元模型的公式(2),其中m为句子中单詞的个数,P(wi)为第i个词语出现的概率:
同理可得二元模型公式为:
三元模型公式为:
本文在文本卷积神经网络中提取了二元模型、三元模型、四元模型和五元模型特征,即所使用的卷积核宽度分别为{2,3,4,5},而传统的机器学习方法只能使用一种语言模型[18]。
卷积神经网络进行文本分析时通常使用最大池化,本文也同样使用最大池化。
2.3 NCF -i模型算法实现
搭建好模型后对NCF -i模型进行训练,训练算法如下:
NCF -i模型训练代码
输入:[Duser,Ditem,Dreview,Nwindows,Nnerual,Nepochs]
输出:[Mncfr]
1. For k to [Nepochs]:
2. 初始化 [Fuser,Fitem,Freview,Frev_layer,Fcov_layer,Fcombine_layer]特征矩阵,[Mncfi]模型权重
3. [Fuser,Fitem,Freview=Embedding(Duser,Ditem,Dreview)]
4. For w to [Nwindows]:
5. [Fwcov_layer=Conv(Freview,w)]
6. [Frev_layer=Frev_layer+Fwcov_layer]
7. [Fcombine_layer=Fuser+Fitem+Frev_layer]
8. For i to [Nnerual]:
9. [Mi+1ncfr=FullConnect(Fcombine_layer,Mincfr)]
10. [Loss=CrossEntropy(M-1ncfr)]
11. [M'ncfr=Min_AdamOptimizer(Loss,Mncfr)]
12. 返回[Mncfi]
算法输入包括[Duser,Ditem,Dreview,Nwindows,Nnerual,Nepochs]分别为用户数据向量、物品向量、评价词向量、卷积核大小向量、全连接层大小向量以及算法运行次数。其中包括Embedding,Conv,FullConnect,CrossEntropy,AdamOptimizer,它们分别是Embedding 为词嵌入映射函数,把来自数据集的数据D映射到特性空间中F.Conv 为卷积函数,根据卷积核w把数据[Freview]映射到卷积层[Fwcov_layer];FullConnect 为全连接层,把上一层特征[Mincfr]权重输出到下一层[Mi+1ncfr];CrossEntropy 为交叉熵损失函数,通过[M-1ncfr]神经网络最后一层的输出计算交叉熵;Min_AdamOptimizer 为优化函数,通过最小化交叉熵获取合适的模型权重。最后NCF -i算法返回模型权重矩阵[Mncfi]。
实验中,为了与提出的NCF -i模型进行比较分析,使用应用了商品评论的推荐模型、FM模型以及一般的NCF模型进行对比。使用的一般NCF模型如图5所示。
使用已有的应用了商品评论的推荐模型是基于物品的协同过滤方法,根据评论对商品进行聚类,之后根据聚类结果,计算商品最近邻居的平均得分预测商品得分
3 NCF -i模型实验设计与结果分析
3.1 NCF -i模型实验数据
亚马逊是一家电子商务公司,其对于推荐系统的研究与发展发挥了巨大的推动作用。据亚马逊前科学家Andreas Weigend在斯坦福讲课时提到的数据,亚马逊有20%-30%的销售额应该归功于推荐系统。本文使用亚马逊的食品评论数据集和亚马逊婴幼儿商品数据集对模型进行训练和测试。两个数据集格式类似,包括的字段主要内容有:ProductId(产品id)、UserId(用户Id)、helpfulnessNumberator(觉得该评论有所帮助的用户数量)、HelpfulnessDenominator(认为该评论有无帮助的用户数目)、Score(用户对商品的评分)、Time(评论时间)、Summary(评论摘要)、Text(评论文本)等。
3.2 NCF-i模型训练与测试
选取数据集中的UserId(用户Id)作为用户特征进行处理,选取ProductId(商品Id)作为商品特征进行处理,同时考虑模型在不同数据集下的泛化能力,而不仅仅是在该数据集上的表现。选用Text(评论文本)作为商品评论特征,放弃比如helpfulnessNumberator(觉得该评论有所帮助的用户数量)这种会有较大帮助却在其它数据集上很少见的字段。将UserId、ProductId和Text進行数据处理后作为输入,将Score(用户对商品的评分)作为标签,将数据划分为训练集和测试集,使用训练集对NCF –i模型进行训练,使用测试集对训练好的模型效果进行测试。
3.3 NCF-i模型测试结果
为了验证添加了商品评论的NCF模型效果,同时使用一般的NCF模型、传统的推荐算法FM模型以及应用商品评论的协同过滤模型作为NCF -i模型进行对比,使用精度对模型效果进行衡量(精度为机器学习模型预测的用户对商品的评分与用户对商品实际评分相等的数据占总数据的比例)。精度定义为:
其中,I(*)为指示函数,当*为真时,I取1;当*为假时,I取0[19]。
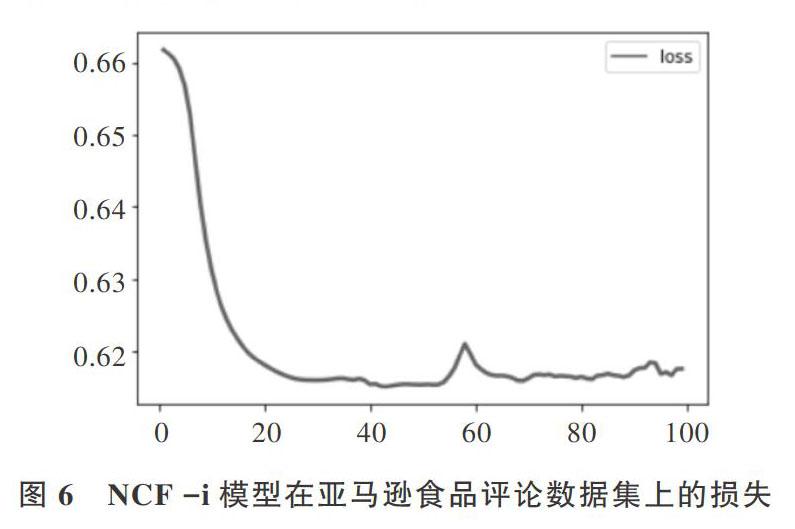
首先对亚马逊食品评论数据集进行清洗,选取40000条数据,用该数据集对3个模型进行训练和测试,包括NCF模型、NCF -i模型以及FM模型,观察NCF -i模型在测试集上的损失率,如图6所示。横轴为训练的轮次,纵横为损失率。结果发现,损失率在前20轮训练过程中有大幅度下降,之后损失率趋于平缓。
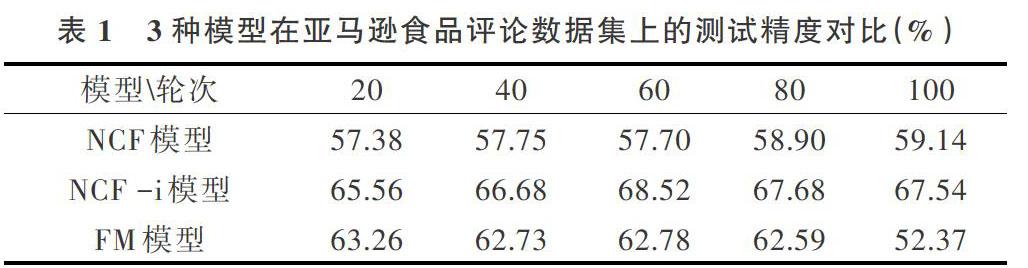
之后查看3种模型经过不同轮次的训练后在测试集上的精度对比,测试结果如表1所示。
可以观察到NCF -i模型效果好于FM模型,更好于NCF模型。但是同时也发现FM模型的效果似乎更好于NCF模型,为了更好地对3个模型的精度进行对比,通过折线图观察不同模型在测试集上的精度,模型的横轴为训练轮次,纵轴为精度,折线图如图7所示。
观察图7可以发现,虽然FM模型的精度有时优于NCF模型,但FM模型的精度十分不稳定,波动极大。分析出现该现象的原因,是由于FM模型只能获取user和item之间的线性相关关系,无法获取非线性关系。同时由于数据集数据比较稀疏,在验证集测试过程中出现了冷启动现象,导致FM模型测试的精度波动极大[20]。
将NCF模型与FM模型比较可以看出,NCF模型精度虽然不如FM模型最优预测结果表现好,但是其预测精度波动小,预测精度十分稳定。分析出现该现象的原因,是由于NCF使用神经网络的方式获取user和item之间的相互关系,而神经网络使用激活函数对网络的隐藏层输出进行激活,让NCF模型具有获取user和item之间非线性关系的能力,从而使其在测试集上的精度十分稳定。
之后对应用商品评论的协同过滤模型在该数据集上进行训练和测试,模型精度和商品评论数目有关。因此在限制商品拥有的最少评论数目条件下,观察该模型符合要求的商品数目和模型在测试集上的精度,如表2所示。
从表2可以看到,应用商品评论的协同过滤模型在考虑全部商品时,模型精度很低,而当限制商品拥有的最少评论数时,模型精度有了明显提高,但是符合要求的商品数目急剧减少。当模型精度达到70%,超过NCF -i模型的稳定精度67%~68%时,符合要求的商品数目仅为91个,为商品总数的22.09%。由此得到结论,应用商品评论的协同过滤模型只对热门商品的推荐结果优秀,冷启动问题严重。而NCF -i模型对于全部商品推荐的精度高于应用商品评论的协同过滤模型精度,同时NCF -i模型预测精度更稳定。
为了进一步验证结论,对亚马逊婴幼儿商品评论数据集进行同样操作,用该数据集对3个模型进行训练和测试,观察NCF -i模型在测试集上的损失率,如图8所示,横轴为训练轮次,纵横为损失率。发现损失率在前20轮训练过程中有大幅度下降,之后损失率虽有波动,但逐步趋于平缓。
之后查看3种模型经过不同轮次的训练后,在测试集上的精度对比,测试结果如表3所示。
为了进一步观察结果,通过折线图来观察不同模型在测试集上的精度,模型横轴为训练轮次,纵轴为精度,折线图如图9所示。
通过观察图4可以发现,NCF-i模型的精度远高于NCF模型和FM模型,并且其稳定性也能保持较好水平。分析出现该现象的原因,是由于NCF-i模型既使用神经网络的方式获取user和item之间的非线性关系,避免了冷启动问题,保持精度的稳定性;同时使用Inception结构卷积神经网络将商品评论信息添加到模型中,进一步提高了预测精度。而FM模型只能获取user和item的线性相关关系,冷启动问题严重。并且FM模型和NCF模型都未利用商品评论信息,因此精度低于NCF-i模型。
之后对应用商品评论的协同过滤模型在亚马逊婴幼儿商品评论集上进行训练和测试,观察在限制商品拥有的最少评论数目条件下,该模型符合要求的商品数目和在测试集上的精度,如表4所示。
可以观察到,即使通过限制商品最少的评论数目,有效提高应用商品评论的协同过滤模型精度,但其精度在不牺牲符合要求的商品数目前提下都低于NCF -i模型。分析出现该现象的原因,是由于协同过滤模型受冷启动问题困扰,导致其只对热门商品的推荐有较好效果,而NCF-i模型可以有效克服冷启动问题。
3.4 NCF-i模型实验结论
通过将NCF模型、FM模型、应用商品评论的协同过滤模型和NCF-i模型在亚马逊食品评论数据集和亚马逊婴幼儿商品数据集上训练和测试,可以发现与FM模型和NCF模型相比,NCF-i模型不仅在测试集上的预测精度十分稳定,而且精度高出FM模型和NCF模型。与应用商品评论的协同过滤模型相比,在考虑全部商品的情况下,NCF-i模型精度远远高于协同过滤模型,协同过滤模型只对热门商品的推荐效果良好,但冷启动问题严重。这是因为NCF-i模型既使用神经网络获取user和item之间的非线性相关关系,避免了冷启动问题,提高了预测精度的稳定性,而且将使用Inception结构的卷积神经网络获取的商品评论信息添加到模型中,让模型能够获取user、item和商品评论之间非线性相关关系。可以发现,user对item的评论的确包含重要信息,对于推荐算法能起到重要作用[21]。
4 結语
由于商品评论中包含有关用户对商品喜好程度的重要信息,而传统的推荐算法很难对商品评论这类文本有效利用,因此本文基于NCF模型,设计了一种能将商品评论充分利用的NCF-i模型。该模型通过使用Inception结构的卷积神经网络,对商品评论的文本进行分析,提取出文本的二元模型、三元模型、四元模型和五元模型特征,经过最大池化后将这些文本特征与user id的嵌入层、item id的嵌入层进行拼接得到特征层,之后使用全连接层获取模型中的非线性相关关系,最后输出模型预测的商品评分。
通过观察NCF模型、FM模型、应用商品评论的协同过滤模型和NCF-i模型在亚马逊食品数据集和亚马逊婴幼儿商品评论数据集上训练和测试的结果,得到结论:NCF-i模型精度远高于NCF模型、FM模型和应用商品评论的协同过滤模型,且能保持良好的稳定性。推荐系统使用NCF-i模型进行离线训练会得到更优秀的推荐结果。但由于使用神经网络的计算比较复杂,当用户和商品规模巨大时,会消耗大量的资源以及时间,因此无法将模型应用于实时在线推荐。所以NCF-i模型的下一步发展方向是减少资源消耗以及减少耗费的时间,将其应用到大规模数据的实时推荐系统中。
参考文献:
[1] 项亮. 推荐系统实战[M]. 北京:人民邮电出版社,2012.
[2] RICCI F,ROKACH L,SHAPIRA B. Introduction to recommender systems handbook[M]. Boston:Springer,2011.
[3] WIETSMA R T A,RICCI F. Product reviews in mobile decision aid systems[C]. PERMID,2005: 15-18.
[4] RICCI F, WIETSMA R T A. Product reviews in travel decision making[M]. Information and communication technologies in tourism 2006. Vienna:Springer,2006.
[5] ACIAR S,ZHANG D,SIMOFF S,et al. Recommender system based on consumer product reviews[C]. Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence,2006:719-723.
[6] CHEN L, CHEN G, WANG F. Recommender systems based on user reviews: the state of the art[J]. User Modeling and User-Adapted Interaction, 2015, 25(2): 99-154.
[7] ZHANG Z,ZHANG D,LAI J. urCF: user review enhanced collaborative filtering[EB/OL]. https://onlinelibrary.wiley.com/doi/abs/10.1002/int.20495, 2014.
[8] XU J,ZHENG X,DING W. Personalized recommendation based on reviews and ratings alleviating the sparsity problem of collaborative filtering[C]. 2012 IEEE Ninth International Conference on e-Business Engineering. IEEE, 2012: 9-16.
[9] RAGHAVAN S, GUNASEKAR S, GHOSH J. Review quality aware collaborative filtering[C]. Proceedings of the sixth ACM conference on Recommender systems. ACM, 2012: 123-130.
[10] HE X, LIAO L, ZHANG H, et al. Neural collaborative filtering[C]. Proceedings of the 26th International Conference on World Wide Web,2017:173-182.
[11] LEE M,CHOI P,WOO Y. A hybrid recommender system combining collaborative filtering with neural network[C]. International conference on adaptive hypermedia and adaptive web-based systems,2002:531-534.
[12] ZHANG Y, JIN R, ZHOU Z H. Understanding bag-of-words model: a statistical framework[J]. International Journal of Machine Learning and Cybernetics, 2010, 1(1-4): 43-52.
[13] LEVY O, GOLDBERG Y. Neural word embedding as implicit matrix factorization[C]. Advances in neural information processing systems,2014: 2177-2185.
[14] RONG X. Word2vec parameter learning explained[J]. arXiv preprint arXiv,2014(1411): 2738-2751.
[15] KIM Y. Convolutional neural networks for sentence classification[J]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 2014(1):1746-1751.
[16] TANG P,WANG H,KWONG S. G-MS2F: Googlenet based multi-stage feature fusion of deep CNN for scene recognition[J]. Neurocomputing,2017(225): 188-197.
[17] ZHANG Y,WALLACE B. A sensitivity analysis of (and practitioners guide to) convolutional neural networks for sentence classification[EB/OL]. http://xueshu.baidu.com/usercenter/paper/show?paperid=b901e951b6b7d7cdf13750b008dd66ad&site=xueshu_seResearchGate
[18] CAVNAR W B,TRENKLE J M. N-gram-based text categorization[C]. The 3rd annual symposium on document analysis and information retrieval,1994:161-175.
[19] 周志華. 机器学习[M]. 北京:清华大学出版社,2016.
[20] HERLOCKER J L,KONSTAN J A,TERVEEN L G,et al. Evaluating collaborative filtering recommender systems[J]. ACM Transactions on Information Systems (TOIS),2004,22(1):5-53.
[21] FENG Z,HUIYOU C. Employing bp neural networks to alleviate the sparsity issue in collaborative filtering recommendation algorithms [J]. Journal of Computer Research and Development,2006(4): 14-21.
(责任编辑:杜能钢)
