基于大数据的农业用药推荐
2020-07-24吴迪吴方华
吴迪 吴方华
摘要:我国是农业生产大国,农业生产中极易受到病虫害的侵袭导致减产,因此越来越多的养殖户开始大量使用农药来防治病虫害,但是农业生产者在实际的用药过程中经常会因为自身专业知识掌握不足导致无法进行精准用药,而且在实体店咨询用药的方式也极易会错过用药时间,因此基于大数据的农业用药推荐可以节省很多线下咨询的时间,而且用的药也可以在很大概率上保证是最好的。基于此,本文基于大数据进行了农药用药推荐模型的构建,以此实现农业生产中的配方施药、精准施药,从而提高现代农业的生产质量。
关键词:大数据;农业用药;推荐系统;机器学习
1 大数据与农业用药推荐概述
1.1 大数据
现在的社会高速发展,信息流通比以往更加便捷,人们的交流沟通也越来越密切,在这个时代背景下,大数据就产生了。
我们正处于大数据时代,但是很少有人深入了解过大数据的内涵,对大数据的定义尚不清晰明确。因此有必要对其定义进行阐述。
大数据的特征可以归纳为体量浩大,超出常规数据处理工具的运算能力;数据形式多样,大数据中包含了大量的非结构化数据;产生速度快,互联网、物联网、智能设备每时每刻都在产生大量数据,数据增长速度较快;以及数据价值密度低四个特征[1]。
大数据可以用于解决生产生活的方方面面问题,如电商推荐系统、人脸识别、语音处理及智能控制、天气预测等。随着信息化的发展,未来社会将逐步走入人工智能时代,而大数据就是人工智能研究和实践的基础。
1.2 大数据与农业用药推荐
农业用药大数据即通过大数据的相关技术和方法在农业用药推荐上的实践。以往农民们用药时,都需要去农药店咨询用药,在用药淡季还是很方便,但是一旦到了病虫害的高峰期,到实体店咨询农药的人就会特别多,一来会浪费黄金用药时间,二来人多了之后很难保证商家对每个人用药推荐都是最好的。
如果将大数据应用到用药推荐上面,就可以节省很多线下咨询的时间,而且用的药也可以在很大概率上保证是最好的,只要大数据包含的历史用药信息足够大,那么几乎可以说是很少失误的。
在农业大数据这方面,美国实施得比较好,他们推行了精准农业,对于拥有大片土地的美国农场主来说,利用大数据技术来操控农业的方方面面,提高了他们的生产效率以及收益。目前也有许多大公司看到了这一行业的前景,孟山都、杜邦先锋等种业巨头都先后投入大批资金在这一领域。
目前国内这一块发展得比较缓慢,作为传统农业大国,全国范围内分散的小农生产方式让大数据的应用进程缓慢,不过像东北,新疆这几个大面积种植农产品的地区,大数据的应用前景还是可以期待的。
2 农业数据获取
我国是农业大国,农业发展历史悠久,由于农业科技进步发展滞后,加之农业信息化程度不高,农业数据呈现以下特点:数据历史长、数据量大、类型多。但存在数据缺失严重、数据质量不高、开发利用不够、数据采集基础建设不完善、家底不清等问题[2]。
但值得期待的是,国家对农业大数据这一块逐渐加大了重视,许多高校研究院都相继开办了相关专业,比如山东农业大学就开办了农业大数据研究中心。在此基础上,我们也可以对农业大数据的获取有一些展望。建立农业数据的标准体系,比如土地的相关参数,天气以及气温变化的统一化规定,农产品质量的指标等。利用先进技术进行大数据采集,比如利用物联网、云计算、微信遥感与通信等来进行农业大数据的采集,使得获取的大数据更加准确和统一。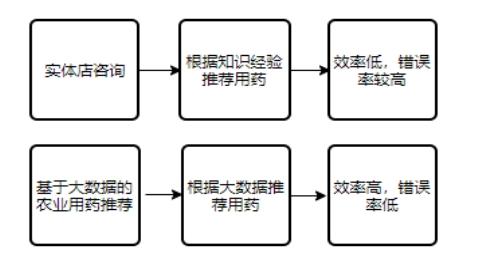
3 農业数据预处理
在基于大数据的人工智能中,数据预处理是最重要的一环。预处理主要包括数据缺失值的填充和异常值的修正,还有就是特征工程。现实的数据都是“肮脏”的,也就是不能直接拿来做分析推荐的,我们称之为有噪声。缺失值是最常见的,比如某一块农田的某一天的气温缺失了,我们就可以用最近几天的平均值来填充这一缺失值,当然用来填充的方法很多,在检验最后用药推荐的准确率的时候,可以相应的通过修改数据处理的方法来不断地逼近一个比较高的正确率。比如我们收集到了某个地区某块地几年的数据,有气温,降雨量等,甚至可以用往年当天的数据来作为当天的缺失值的填充量。另外一种方法就是预测,将不存在缺失值的数据放入到机器学习模型中训练,得到一个较好的模型,然后对于有缺失数据的那块地,我们把那块地不缺失的数据作为训练特征,然后预测出这块地缺失的数据。
更加深入的处理缺失值的方法有插值法,在数值分析中,牛顿给出了用插值的方法求得一组数中缺失的值,只要把缺失值前后对应的数据提取出来,建立插值多项式,就可以求得缺失值。异常值也是经常遇见的,可以用人工智能机器学习中常用的“滑窗”方法来给数据建立一个散点图,当发现有偏离正常曲线的点时,就基本可以认定这个点是异常值,修正值可以用曲线来预测。
在统计学中,我们也可以用z-score的方法来判断是否有异常值。将农业数据进行标准化,也就是将每个数据减去这组数的平均数,再除以这组数方差。经过这番处理后,这组数据就变成了平均值为0,方差为1的标准数。利用3σ原则,把绝对值大于3的数列为不恰当值,也就是异常值。之后就可以把这些异常值视为缺失值,再对这些值进行替换处理,用更准确的数代替它们。
最后就是特征工程,在机器学习中,有这么一句话:“特征工程决定上限,而模型只是在不断逼近这个上限”。所以得到好的特征工程可以说是关键一环。对于一块特定的农田,可以选取当地的气温变化,施药的时间,历年灾害等众多特征,把特定时间的用药作为标签,当然,特征的调整也会影响正确率。不过,对于具体特征的选择需要采取相应的办法。
第一种方法就是卡方检验,经典的卡方检验是检验定性自变量对定性因变量的相关性。可以利用它选出与农业用药相关性最强的特征集合。
其次就是RFE,即递归消除特征法,将所有的特征投入到一个模型进行训练,然后逐步淘汰掉不太重要的特征,比如在农业大数据特征里,可能就会淘汰掉田的形状等不太相关的特征,然后递归调用这种方法,直到特征数满足我们的需求。
第三种方法是利用模型选取特征,可以选取RandomForest来作为特征选择的学习器,投入农业大数据到学习器中后,它会输出每个特征的重要性,就可以选取重要的特征。
4 模型建立
支持向量机、随机森林、朴素贝叶斯、线性回归、神经网络等都是比较常用的机器学习模型,当然随着深度学习的发展,也可尝试一些深度网络等方法。将处理好的农业大数据划分为训练集和测试集,把训练集投入到这个模型中,经过训练得到一个标准模型,然后利用测试集检验模型的准确率,不断改变数据预处理的方法来获得一个比较理想的正确率。这样,一个简易的农业用药推荐系统就应运而生。
当然,我们也得注意模型的泛化能力,也就是模型的普适度。可能存在的情况就是,模型在用作训练集的农业大数据里错误率比较低,表现很好,但是当农户投入他自己的农业数据时,就可能得不到很精确的用药推荐,这就是因为模型的泛化能力太低了。造成这种现象的原因可能是过拟合,也可能是欠拟合。过拟合就是模型太依赖于训练集的数据,而缺失“举一反三”的能力,欠拟合就是模型没有很好地拟合数据,也就是说“课堂内容”都没消化好,就想着去做“模拟试卷”了。
解决这两种现象的方法有很多。
第一,特征数和样本数的平衡。当样本数很少的时候,特征数也要跟着稍微少一点,防止过拟合。当样本数比较多时,也要适当增加特征数,防止欠拟合。
第二,利用交叉验证的方法,也就是将获取的农业大数据分为两部分,一个训练集,一个是测试集。也就是说一个是“课堂内容”,用于自己巩固提高,另一个是“模拟试卷”,检查自己学习的效果。然后再不断重新划分训练集和测试集,基本保证农业大数据的每个部分都曾作为训练集和测试集。
5 用药推荐
把简易的推荐系统进行包装,就可以得到一个人机交互的推荐系统,例如触屏式机器人,或者app。农民按照条件,把作物状况、土地的相关参数、天气、气温等特征填入,就可以得到用药推荐。
6 结束语
我国是农业大国,将近14亿人口对粮食的消耗量是不言而喻的,而农药的使用对粮食的产量起到了关键性的作用,农业用药不能只凭已有的经验,随着大数据技术的逐步深入,利用农业大数据进行用药推荐是配方施药、精准施药,是大势所趋,不仅可以提高生产力,还可以实现农药减量,确保农产品质量安全和农业环境友好。
参考文献
[1] 罗成飞.基于大数据的制造企业服务化研究[J].现代营销(下旬刊),2019(9):73-74.
[2] 宋长青,温孚江,李俊清,等.农业大数據研究应用进展与展望[J].农业与技术,2018,38(22):153-156.
