仿真假体视觉下神经网络算法的应用研究
2020-07-23赵瑛李琦王冬晖于爱萍谷宇
赵瑛 李琦 王冬晖 于爱萍 谷宇

摘 要: 尽管已有多种图像处理策略被应用到视觉假体的仿真研究中并提高了被试的识别表现,但在植入电极数量有限的情况下,如何保证盲人获得足够的拓扑信息是视觉假体仍需解决的问题。在此背景下,本文将两种神经网络算法应用到仿真假体视觉中对图像进行前景目标提取和像素化处理,首先利用图像分割数据集训练一个U?net网络得到前景提取后的结果,将其像素化之后与提取前的原图配对,再利用配对后的数据集训练一个Pix2Pix网络从而实现了将彩色图像“翻译”为像素化图像的目标。实验结果表明,与传统图像处理算法相比U?net网络具有更准确的目标提取效果,且经Pix2pix网络“翻译”后的图像也与标签图像更相似,有助于提高假体佩戴者的识别准确率。
关键词: 仿真假体视觉; 神经网络算法; 前景目标提取; 像素化处理; 数据集训练; 图像配对
中图分类号: TN911.34?34; TP391.4 文献标识码: A 文章编号: 1004?373X(2020)04?0164?03
Application of neural networks algorithm in artificial prosthesis vision
ZHAO Ying1, LI Qi1, WANG Donghui1, YU Aiping1, GU Yu1,2
(1. Inner Mongolia Key Laboratory of Pattern Recognition and Intelligent Image Processing, School of Information Engineering, Inner Mongolia University of Science and Technology, Baotou 014010, China; 2. School of Computer Engineering and Science, Shanghai University, Shanghai 200444, China)
Abstract: A variety of image processing strategies have been applied to the simulation study of visual prosthesis and improved the recognition performance of the subjects, but how to ensure that blind people get enough topological information with limited electrodes is still a problem to be solved in visual prosthesis. On this background, two kinds of neural network algorithm are applied to the artificial prosthesis vision to perform foreground object extraction and pixel processing for images. A U?net network is trained with the image segmentation dataset to acquire the extracted results of foreground, which are matched with the original image after its pixel processing. A Pix2pix network was trained with the matched datasets to achieve the goal of “translating” color images into pixelated images. The experimental results showed that in comparison with the traditional image processing algorithm, the U?net network has more accurate object extraction effect, and the image translated by the Pix2Pix network is more similar to the ground truth. It is helpful to improve the recognition accuracy of prosthesis wearers.
Keywords: artificial prosthesis vision; neural networks algorithm; foreground object extraction; pixel processing; dataset training; image matching
人类对外界信息的获取约有80%来自于视觉,视力残疾或失明对人的正常生命活动造成的影响是灾难性的。对于由视网膜色素变性(Retinal Pigmentosa)和老年性黄斑变性(Age?related Macular Degeneration)造成視力残疾或失明的患者[1],他们病变的视网膜组织中仍然有近80%的内层神经细胞和近30%的神经节细胞的形态和功能处于正常状态,并保持一定的功能性连接,视觉假体可应用于这类患者的视觉恢复和重建过程中[2]。通过在他们的视网膜、视觉皮层或视神经等位置植入微电极并对其施加合适的电刺激,可使患者感知到光幻视点。而进一步传递有用的外界信息,还需要利用图像处理策略对电刺激的拓扑位置加以控制。目前,得益于视网膜假体技术快速发展,已经有盲人能够借助视觉假体在日常生活中完成一些字母阅读、物体识别、寻路等任基本任务[3]。
然而在临床实验中,测量所得即使是最好的视觉敏锐度也仍然很低,Argus Ⅱ和Alpha?IMS视网膜假体系统可提供的视觉敏锐度[3]分别只有20/1260和20/546。针对这种情况,许多研究者企图通过更有效的图像处理策略来改善视觉假体的表现,从而为盲人提供更好的重建视力。Sheng Li等人将小波分析方法与k?means聚类结合并应用于图像中目标的轮廓提取与像素化重构过程中,并通过仿真假体视觉下的心理物理学实验讨论了正确识别简单物体的最小信息需求[4]。Li Heng等人基于图的生物显著性运用GrabCut的自适应分割算法提取前景目标后进行再像素化[5],相较于直接像素化得到了更高的目标识别准确率和识别效率。此外还有多种显著性提取算法被证明在提高假体视觉下的识别准确率是有效的。
本文提出将U?net卷积神经网络与Pix2Pix生成对抗网络这两种深度学习图像处理技术应用于仿真假体视觉下的前景目标提取与图像像素化过程中。经过在分割训练集和像素化训练集上的参数调整,可以得到最优的两种模型。之后,在图像分割测试集上对比U?net网络模型与传统显著性目标提取方法的效果差异,同时在像素化测试集中对Pix2Pix模型生成的测试结果进行对比。
1 数据集与方法
1.1 数据集
使用ETH?80数据集[6]作为训练与测试神经网络模型的图像集,其中包含苹果,汽车,牛,杯子,狗,马,梨,和番茄8种常见的自然或人造物体,每种物体包含410张RGB图像和对应的经过分割后的标签(Ground Truth),对于每种物体从中随机选取307张图像作为训练图像,剩下的103张图像作为测试图像,最终的数据集包含2 456张训练图像和824张测试图像。
1.2 前景目标提取
传统的卷积神经网络(Convolutional Neural Networks)借鉴了人体视觉系统的特点,网络的前几层在输入图像上重复使用卷积的方式来提取小的、局部化的边缘特征,然后通过激活函数和池化操作即下采样将这些边缘特征组合成更复杂的表示[7]。池化操作会导致经过整个网络的信息流缩减,这使得传统卷积神经网络不能很好地应用于图像分割任务中。U?net[8]是全卷积网络(Fully?Convolutional Networks)概念的扩展,适合在训练图像较少时对模型进行训练并可以产生精确的分割结果。如图1所示,U?net的体系结构由下采样和上采样两条路径组成。下采样路径是一种典型的层叠状卷积结构,每个层叠结构包含两个连续的卷积层(使用3×3卷积核)和一个池化层(使用2×2最大池化),激活函数为线性整流单元(ReLU)。上采样路径对称地将卷积层改为反卷积层并去掉池化层,每一个反卷积层得到的特征图与下采样路径中对应卷积层得到的特征图会进行拼接,再对拼接后的特征图进行反卷积,经过两个反卷积层叠结构后,到达最后一层对特征图进行1×1反卷积得到二值分割结果。
1.3 图像翻译
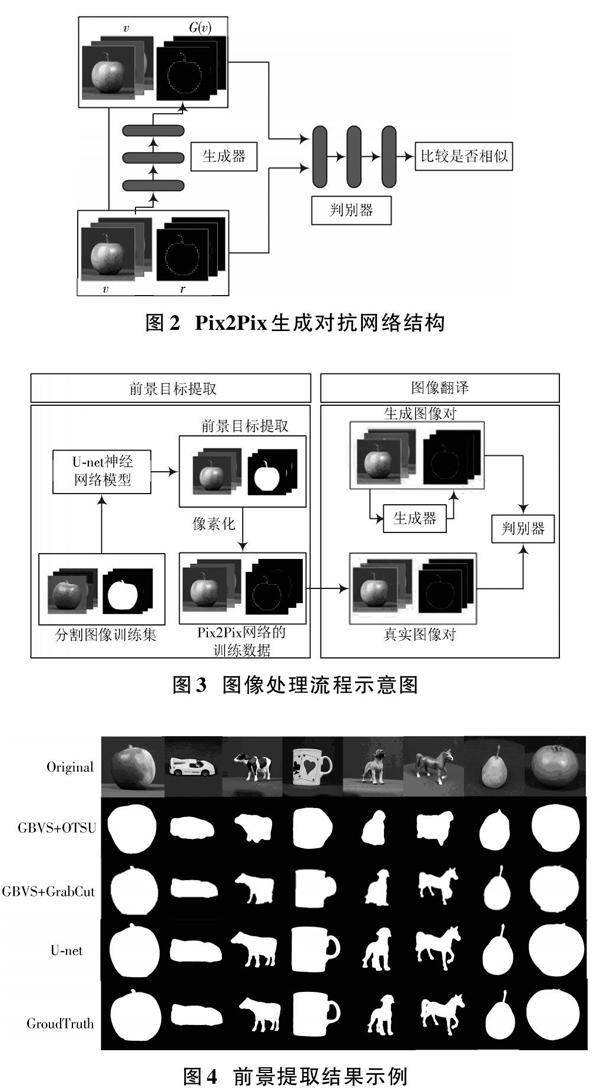
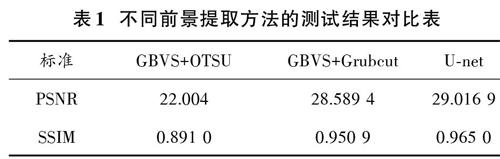
图像翻译是一种相对较新的计算机视觉处理任务,其目标是在图像X转化为另一种表示Y的过程中得到一种映射关系。这种关系可以通过具有半监督学习能力的生成对抗网络中的生成器来表示和实现。经过训练后的神经网络模型能够利用一张从未见过的图像[Xnew]预测并生成一张新的图像[G(Xnew)],即最有可能表示训练数据中的映射关系。Pix2Pix[9]生成对抗网络是在生成对抗网络的基础上为了实现图像翻译任务而加入了半监督学习能力的一种条件生成对抗网络。当需要处理彩色图像直接得到像素化图像时,输入生成器的训练数据应是带有标签的样本{([v1],[r1]),([v2],[r2]),…,([vn],[rn])},因此生成器需要完成的任务是从配对的训练数据中学习到可以使生成的图像[G(vi)]与真实图像[ri]最相似的映射,而判断生成图像与真实图像是否相似的任务需要判别器来完成。这样在学习和优化的过程中,不仅生成器试图生成与真实图像越来越相似的[G(vi)]表示来欺骗判别器,判别器也能更好地分辨[G(vi)]是否是真实图像,最终在对抗学习的过程中提高了生成器的“翻译”能力,这一过程如图2所示。U?net模型经过调参后可以精确地输出包含前景目标的二值图像,然后对这些图像进行轮廓提取后匹配32×32大小的像素化模板,再将这些经过像素化之后的图像与原RGB图配对形成新训练集来训练Pix2Pix生成对抗网络模型,从图3中可以看到这一过程的整个流程。由图割方法(GrabCut)可以得到前景目标的提取结果[13]。
在TensorFlow深度学习框架中训练了一个对称型U?net网络结构,利用NVIDIA GTX1080Ti GPU在分辨率为256×256像素的训练图像集上训练200次迭代,得到了损失函数达到最小,并保持稳定的模型。图4中展示了不同前景目标提取方法的结果。
同时利用峰值信噪比(PSNR)和结构相似性(SSIM)两种评价标准对三种方法进行了量化比较,在测试图像集中计算了每种方法得到的结果,如表1所示。相较于传统方法,U?net神经网络的前景提取结果相对于标签图像有更高的PSNR值,且SSIM值也更接近1,因此具有更好的表现。
1.4 像素化结果评估
在利用传统方法提取前景目标后的测试结果中,对其进行轮廓提取并匹配32×32分辨率的像素化模板,得到了经过传统像素化方法处理后的结果。随后通过PyTorch深度學习框架构建了一个的Pix2Pix神经网络,输入由原图与像素化图像的配对训练集并调试参数,在训练400次迭代后得到一个最优的生成器,利用该生成器可以在测试图像集中直接由RGB原图得到像素化后的结果,各方法得到的像素化结果示例如图5所示。
同时利用峰值信噪比(PSNR)和结构相似性(SSIM)两种评价标准对三种像素化方法进行了量化比较,在测试图像集中计算了每种方法得到的结果,并展示在表2中。相较于传统方法,Pix2Pix生成对抗网络的像素化结果相对于标签图像有更高的PSNR值,且SSIM值也更接近1,因此具有更好的表现。
