基于WiFi数据的实时高效定位分析系统设计
2020-07-23韩萍王浩方澄牛勇钢贾云飞
韩萍 王浩 方澄 牛勇钢 贾云飞


摘 要: 近年来很多室内定位技术被提出,但是大多数技术都是重点研究怎样提高定位精准度,却忽略了系统处理海量数据的稳定性、实时性和高效性。特别是在机场高峰时段和大面积航班延误情况下,大量旅客聚集在航站楼产生了海量WiFi数据,导致传统的数据处理架构出现处理数据不及时、统计实时性差、稳定性差的问题。针对该问题设计一种高吞吐、低延迟的分布式实时数据处理架构。该架构使用消息中间件、实时流数据处理、内存并行计算和分布式数据库读写技术,实现了大客流环境下处理海量实时WiFi数据的分布式定位分析系统。通过使用模拟数据和实时数据进行多组实验测试,验证了系统在保持定位算法准确性的情况下,仍然具有稳定、实时、高效的定位分析能力。
关键词: 定位分析; WiFi数据; 架构构建; 分布式处理; 系统测试; 性能比较
中图分类号: TN919?34 文献标识码: A 文章编号: 1004?373X(2020)04?0043?05
Design of real?time and efficient location analysis system based on WiFi data
HAN Ping1, WANG Hao[2], FANG Cheng[1], NIU Yonggang[1], JIA Yunfei[1]
(1. School of Electronic Information and Automation, Civil Aviation University of China, Tianjin 300300, China;
2. School of Computer Science and Technology, Civil Aviation University of China, Tianjin 300300, China)
Abstract: In recent years, many indoor positioning technologies have been proposed, but most of them focus on how to improve positioning accuracy, while ignoring the stability, real?time performance and high efficiency of the system in processing massive data. Especially in the case of airport peak hours and large?scale flight delays, while a large number of passengers gather in the terminal, which makes a large amount of WiFi data generated, the traditional data processing architecture shall produce the problems of unresponsive data processing, poor statistical real?time performance and poor stability. Therefore, the distributed real?time data processing architecture with high throughput and low latency is designed to solve above problems. In the architecture, the message middleware, real?time streaming data processing, memory parallel computing and distributed database write?read technology are adopted to realize the distributed positioning analysis system for processing massive real?time WiFi data in the large passenger flow environment. The multi?group experimental test using simulation data and real?time data proves that the system has stable, real?time and efficient positioning analysis ability while still maintaining the accuracy of the positioning algorithm.
Keywords: positioning analysis; WiFi data; architecture building; distributed processing; system testing; performance comparison
0 引 言
我国民航事业正处于高速发展期,航空已然成为人们出行的重要选择方式。随着民航客流量的逐渐增加,不仅对机场的服务提出了新的要求,并且对机场的安全保障工作带来了新的挑战。在机场候机楼内免费WiFi是旅客使用率较高的一种通信方式,因此可以利用航站楼现有的免费WiFi网络开展定位业务和旅客密度分析等业务,为机场运行与资源调度提供支持[1]。目前在室内定位技术研究领域大多数研究都在提高定位算法的准确性,却忽略了系统处理数据的性能问题。例如在文献[2]中,江聪世等人提出了一种客户端?服务器端架构的定位系统,通过手机采集定位数据后传输到系统服务器端进行数据处理,将定位结果返回到手机端显示。文献[3]中,乐燕芬等人设计了基于Android平台的室内移动目标的实时定位系统,服务器端获取无线传感器网络采集的定位数据发送给Android智能终端,智能终端利用位置指纹算法进行处理,实时动态显示移动目标。在文献[4]中,罗健宇等人设计了基于RSSI优化模型的室内定位系统,使用无线传感器网络采集定位数据后上传到服务器,在服务器端使用滤波器进行数据处理,最后使用加权质心定位算法进行定位计算。在机场航班大面积延误和高峰时段航站楼高密度人流的环境下,由于数据产生快、实时性强、数据量大等特点,导致传统的数据处理架构无法满足需求。因此,实现一个具有对实时数据进行快速处理、高效存储和及时服务能力的高性能系统尤为重要。
Hadoop作为一个分布式系统基础架构,在架构之上的生态系统给大数据的存储、处理和分析做出了重要贡献。但是随着实时大数据应用越来越多,Hadoop的MapReduce作为离线的高吞吐、低响应框架已不能满足数据实时处理的需求。因此为了满足在高密度客流环境下对系统高吞吐和实时性的需求,本文给出一种基于WiFi数据的实时高效定位分析系统。在系统中将海量实时流数据处理和定位算法实现并行化,结合具有高密度读写能力的NoSQL数据库,实现了一个具有稳定性、实时性和高效性的分布式系统。
1 系统体系架构
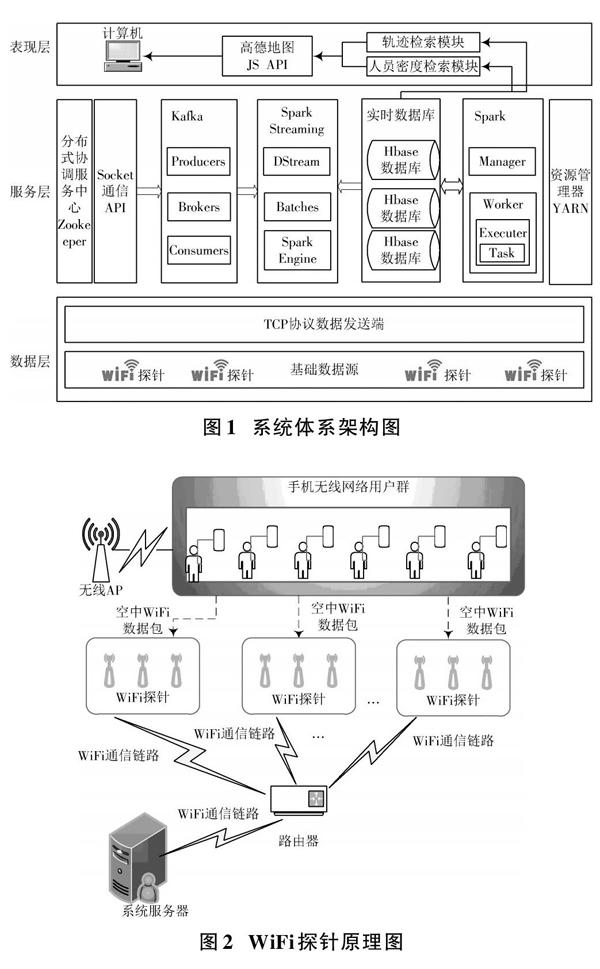
基于海量WiFi数据的分布式定位分析系统架构如图1所示,主要包括3个层次:数据层、服务层和表现层。数据层通过部署WiFi探针设备,使用探针对WiFi数据进行采集并且通过WiFi网络将数据上传到系统后端服务器。服务层运行在分布式架构之上,主要包括Kafka作为消息中间件接收和整理WiFi探针上传的WiFi数据,Spark Streaming将Kafka的实时流数据进行数据解析后存储到HBase数据库以及Spark进行并行定位计算。表现层即用户层,用户通过轨迹检索模块和人员密度检索模块与高德地图JS API结合实现系统的可视化呈现。
2 系统设计与实现
2.1 WiFi定位数据采集与上传
WiFi定位数据的采集功能通过部署WiFi探针实现。WiFi探针是基于WiFi探测技术,自动识别已开启WiFi的移动设备(手机、平板、手提电脑等)并且获取移动设备的MAC(Medium/Media Access Control)层数据的一种硬件设备。
如图2所示,在公共WiFi环境下,移动设备的WiFi功能在开启的状态下会周期性地向四周发射扫描信号,因此WiFi探针就可以监听移动设备发射的探测信号。WiFi探针探测到移动设备的MAC层的信息,主要包括设备MAC地址、数据传输信道、数据帧类型、信号强度以及移动设备所连接的热点名称。每个移动上网设备的MAC地址都是全球唯一的,所以利用MAC的唯一性可以有效地作为旅客的唯一标识。WiFi探针将探测到的数据按照数据上传协议进行数据包封装,封装后的数据包采用TCP的Socket方式上传到后台服务器。
2.2 消息队列中间件
消息中间件是分布式系统中必不可少的组件,面对流量高峰问题可以帮助系统进行削峰降流和异步处理,并且可以降低系统架构各层的耦合度来提高系统的健壮性。因此,消息中间件广泛应用于分布式系统中,目前主流的消息队列中间件主要有:KafKa,RabbitMQ,RockertMQ。文献[5?8]将Kafka分别应用于航空维修大数据系统、电量采集系统、联通实时账单短信系统中,验证了Kafka作为消息中间件的可靠性。本文使用WiFi定位数据对三个中间件系统进行性能实验对比,在测试过程中不断增加数据发送端的压力直到系统的吞吐量不再上升,但是处理时间不断拉长,系统出现了性能瓶颈期,这时便得到了系统的最佳吞吐量。如图3所示,Kafka吞吐量为5.24万条性能高于RabbitMQ的4.35万条和RocketMQ的2.12万条,通过测试,表明Kafka更适合处理I/O高吞吐数据,因此本文将Kafka作为分布式系统的消息中间件组件。
2.3 基于Spark Streaming的数据解析算法
Spark作为新一代大规模数据处理引擎,具有高效性、易用性、通用性和兼容性等特点[9]。Spark Streaming是运行在Spark之上的流式计算框架[10],工作原理如图4所示。Spark Streaming从Kafka接收到WiFi数据之后,首先将数据流进行切分成多个batch(分片),将多个batch高层抽象为DStream。每个Dstream代表了一系列连续的弹性分布数据集(Resilient Distributed Dataset, RDD),RDD是Spark中最重要的概念,在Spark中RDD是一个提供多种操作接口的数据集合。Spark Streaming将batch序列输入到Spark Engine中,Spark Engine 將多个batch分派到Spark集群中的Worker节点进行WiFi数据的解析工作,最终将数据解析的结果存储到HBase数据库。
本文的数据解析算法根据WiFi探针上传数据时的数据协议将原始的WiFi数据进行数据解析,原始的WiFi数据是以十六进制字节数组进行传输,数据格式如图5所示。
数据解析算法是运行在Spark Streaming框架之上的并行流式算法,如图6所示。原始WiFi数据分配到不同的Worker计算节点之后,首先找到数据的同步字段,该同步字段表示数据帧的开始,找到同步字段后,根据CHK字段结合CTL,LENGTH,SN三个字段进行CRC8校验,最后进行数据完整性校验。通过三步检验后将DATA字段根据数据协议进行数据解码,最终将解析后的数据添加到Put对象中进行HBase数据存储。
2.4 基于Spark的三边定位算法
使用Spark进行数据计算时,数据处理算法的设计和程序编写的最关键部分就是利用Spark丰富的操作函数对原始数据产生的RDD进行多次变换,通过RDD转换过程得到期望的计算结果。文献[11?14]中将Spark分别应用到智慧城市系统、空间大数据分析、油田应用日志分析和推荐系统中,均验证了Spark作为大规模数据处理引擎的优势。本文提出的基于Spark的定位算法是将传统的基于RSSI测距的室内三边定位算法[15]进行重新编写,使定位算法运行于Spark框架之上,算法流程如图7所示。
具体的算法步骤描述如下:
1) 创建弹性数据集RDD1,从数据库中查出需要定位计算的数据并存入到弹性数据集RDD1中,其中每一条数据包括phoneMac(手机MAC地址)、 ScaMac(WiFi探针的MAC地址)、timeStamp(数据采集时的时间戳)、isCalculate(计算标志位)。
由表1可知,本文提出的基于Spark的定位算法计算结果与传统算法保持一致,证明了该算法在提高计算效率的同时并没有影响算法的准确性。
4 结 论
为了解决传统架构系统计算效率低、实时性差和稳定性差的问题,本文结合Kafka,Spark,HBase等大数据组件,设计基于海量WiFi数据的分布式定位分析系统。通过多组实验测试,验证了该系统在保持定位准确性的条件下,仍然具有稳定、实时、高效的定位分析能力。下一步工作:研究定位算法提供更准确的定位算法模型,丰富系统功能使系统进一步完善。
参考文献
[1] 张晓海,梁旭.WiFi定位技术在机场的应用研究[J].综合运输,2017,39(2):84?86.
[2] 江聪世,刘佳兴.一种基于智能手机的室内地磁定位系统[J].全球定位系统,2018,43(5):9?16.
[3] 乐燕芬,罗红玉,赵妍,等.基于位置指纹的室内移动目标定位系统[J].电子科技,2018,31(11):42?46.
[4] 罗健宇,张卫强,徐艇.基于RSSI优化模型的室内定位系统[J].无线通信技术,2018(3):25?30.
[5] 徐海荣,陈闵叶,张兴媛.基于Flume、Kafka、Storm、HDFS的航空维修大数据系统[J].上海工程技术大学学报,2015,29(4):303?305.
[6] 金双喜,李永,吴骅,等.基于Kafka消息队列的新一代分布式电量采集方法研究[J].陕西电力,2018,46(2):77?82.
[7] 杨洁.利用Kafka技术实现用户实时账单的短信提醒功能[J].数字通信世界,2017(11):219?221.
[8] 王岩,王纯.一种基于Kafka的可靠的Consumer的设计方案[J].软件,2016,37(1):61?66.
[9] 赵文芳,刘旭林.Spark Streaming框架下的气象自动站数据实时处理系统[J].计算机应用,2018,38(1):38?43.
[10] ZAHARIA M, CHOWDHURY M, FRANKLIN M, et al. Spark: cluster computing with working sets [C]// Proceedings of 2nd USENIX Conference on Hot Topics in Cloud Computing. Boston: ACM, 2010: 10?16.
[11] 石磊.基于Spark技术在智慧城市系统中的应用[J].电子技术与软件工程,2018:58?59.
[12] 周尧,刘超,徐树楠,等.基于Spark与MongoDB的地理空间大数据应用分析系统设计与实现[J].测绘与空间地理信息,2018,41(9):71?74.
[13] 陈雷鸣,张伟光,李翛然,等.基于Spark的油田应用日志行为分析系统[J].计算机系统应用,2018,27(9):74?80.
[14] 张靓,肖俊东,赵开敏.基于Spark的舰船网络数据解析存储系统设计与实现[J].舰船电子工程,2017(11):98?101.
[15] YANG Z L. Study on indoor trilateration algorithm implementation based on positioning of RSSI [J]. Machine tool & hydraulics, 2018, 46(6): 140?145.
[16] 房俊,李冬,郭会云,等.面向海量交通数据的HBase时空索引[J].计算机应用,2017,37(2):311?315.
[17] 吴仁彪,刘超,屈景怡.基于HBase和Hive的航班延误平台的存储方法[J].计算机应用,2018,38(5):123?129.
[18] 张春风,申飞,张俊,等.基于Storm的车联网数据实时分析系统[J].计算机系统应用,2018,27(3):44?50.
[19] ZHANG Chong, CHEN Xiaoying, FENG Xiaosheng, et al. Storing and querying semi?structured spatio?temporal data in HBase [C]// International Conference on Web?Age Information Management. Nanchang: Springer, 2016: 303?314.
