基于多层次深度学习网络的行人重识别
2020-07-23吴绍君
吴绍君 高 玲 李 强
( 山东师范大学信息科学与工程学院,250358,济南 )
1 引 言
行人重识别(re-ID)方法是指在不同摄像机拍摄的视频或图像中查询目标人物的方法[1].行人重识别的过程是指对于在监控视频中出现的目标人物,当该目标人物在其他监控区域中再次出现时能够将该目标重新识别出来的过程,如图1所示.最近行人重识别在利用深度学习模型判别行人[2-6]和利用距离度量学习算法识别行人[7-10]这两方面都取得了很好的进展.
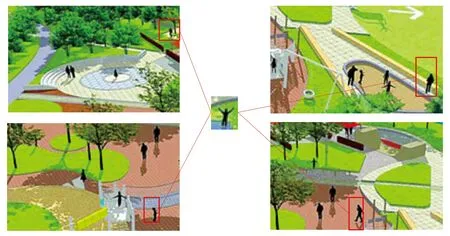
图1 在不同的相机下检索同一行人
深度学习这一网络模型提取的行人特征可以分为两种类型:全局特征和局部特征.从整张图片中提取的行人特征被称为全局特征.全局特征具有不变性、直观性、易于计算的特性,被广泛地用于以识别图像级别的行人特征为主的方法.全局特征包含行人图片中最直观的信息(如行人衣服的颜色),这些提取到的全局信息有助于判别不同身份的行人[6].但是,大多数的行人重识别方法在提取全局特征的同时,也会导致行人图片中的一些细节部分(如帽子,腰带等)被忽略.例如,如果两个人穿着相同颜色的衣服,同时其中一个人戴着帽子,那么仅仅通过提取全局特征判别行人,很难从外观上将两个人区别开来.这时候忽略的局部特征会使判别行人的难度增加.最近的一些工作则主要是利用深度学习模型提取局部特征的方法来解决行人重识别问题[11-13],这些方法的基本过程是利用深度学习网络去提取行人的局部特征,并根据显著的局部细节特征去匹配行人的身份(ID).另外,也有利用神经网络提取行人各个身体部位的局部特征信息的方法[14,15].局部特征间的特征相似度低这一特点更有利于成功识别行人.但是,提取局部特征的方法在一定程度上也会忽略整体的行人架构信息.在多个网络层学习局部特征的同时也会产生部分特征的丢失,从而使得行人重识别方法准确率降低.基于此,本文提出了一个深度学习网络模型,这个网络模型能够同时学习行人图片的全局特征和局部特征.利用整张行人图像的显著特征作为全局特征来进行行人识别.而在全局特征相似的情况下,局部特征的特征与特征之间相似度低,这一特性也为全局特征做了重要的细节补充,同时该模型能够从不同的网络深度提取局部特征,保证每个网络层学习到的局部特征都得到充分的利用.本文提出结合全局特征和局部特征的多级特征融合模型.由于部分行人图像特征会随着网络学习层数的增加而丢失,所以,在网络层中添加了分支网络,使模型能够分别从不同的网络深度提取局部特征.多层级特征融合模型主要由两部分网络组成:基于部分的多层级网络和全局—局部分支网络.多层级网络能够分别从不同的网络层提取局部特征,全局—局部分支网络则从最深层网络提取局部特征以及全局特征.在网络模型提取了全局特征和局部特征之后,通过多分类算法来预测行人身份.该模型在三个经典的数据集上进行了训练和测试并得到了很好的实验结果.
2 相关工作
行人重识别方法是指从不同的监控摄像机中找到匹配的目标人物的方法.近些年来,随着深度学习方法的不断普及,许多国内外的学者开始关注深度学习方法,并利用深度学习网络提取行人特征来处理行人重识别问题.我国学者Li等人[16]首次提出孪生神经网络架构与行人图像的特征学习相结合的方法,这一方法表现出了很好的性能.我国学者Sun等人[11]提出了一个基线模型,该模型将识别行人身份(ID)的方法与ResNet-50网络结合起来,用于目前的行人重识别系统.这一方法大大改善了基于深度学习的行人重识别方法的准确率.Varior等人[17]通过孪生卷积神经网络计算行人图像对的中级特征这一方法来表示局部特征之间的相互关系.我国学者Xiao等人[18]针对跨数据集检索行人这一问题,提出了DGD(Domain Guided Dropout)方法,大大提高了模型的泛化能力.
在提取局部特征方面.Li等人[12]提出了一个深度学习模型STN,该模型主要通过学习行人躯干部位和其他潜在身体部位的深层语义感知来定位行人图像的局部特征.Zhao等人[13]采用深度学习的方法,在对行人图像进行分割后,首先将不同行人图像的相同分割部位进行对齐,然后通过图像块的匹配来实现行人身份匹配.Liu等人[19]利用深度学习网络模型来加强对于行人重点部位的识别,以便提取行人图像重点部位的局部特征. Bai等人[20]利用LSTM网络将行人图像垂直分割成多个部分并提取局部特征,然后将提取的特征块组合在一起来进行特征匹配.另外还可以通过加强对行人图像的身体部位的识别来提高模型精度[21,22].将特征图进行水平分割来提取局部特征,同时,也从不同的网络深度分别提取局部特征来提升深度学习模型的性能.
提取全局特征方面.文献[23]提到的核特征图就是用于表示全局特征的特征图.Liao等人[6]提出了一种称为LOMO(Local Maximal Occurrence)的方法来提取起到积极作用的特征.在本文中,我们将全局特征和局部特征进行结合并用于行人重识别.softmax损失函数被广泛应用于解决多分类问题,它既可以单独作为损失函数使用[24],也可以与其他损失函数结合使用[25-27]. 在行人重识别中,softmax损失函数多被作为分类损失函数使用.也用softmax损失函数解决多分类行人重识别问题.
3 方 法
MFF网络主要包含两个结构:基于部分的多层次网络(Part-based Multi-level Net,PMN)和全局—局部特征分支网络(Global-Local Branch,GLB),如图2所示.PMN网络主要用于提取来自不同网络层的局部特征. GLB网络则在深度学习网络的最深层提取行人图像的局部特征和全局特征.
3.1骨干网络在行人重识别方法中,由于ResNet50网络的体系结构简洁并且性能良好,我们使用ResNet50网络作为MFF网络的骨干网络.如图2所示,ResNet50结构被分为block1,block2,block3和block4四个网络模块,这样分类可以更方便地从每个网络块提取行人图像特征图,并利用分类器来预测行人身份.每个网络块包括卷积块和身份块,其中卷积块中包含多层卷积网络层.在block1块之前是最大池化层.在MFF网络中,一直到block4网络块都保持ResNet50的主干结构不变,然后删除block4之后包括全局平均池化层在内的整个网络层.
3.2多层次特征融合网络本文提出了将局部特征和全局特征融合在一起的多层次特征融合网络.行人图像的全局特征和局部特征组合在一起学到的特征信息更为丰富,更有利于判定行人.在MFF模型中,局部特征和全局特征被用于进行行人身份预测.如图2所示,MFF模型由基于部分的多层次网络和全局-局部特征分支网络组成.
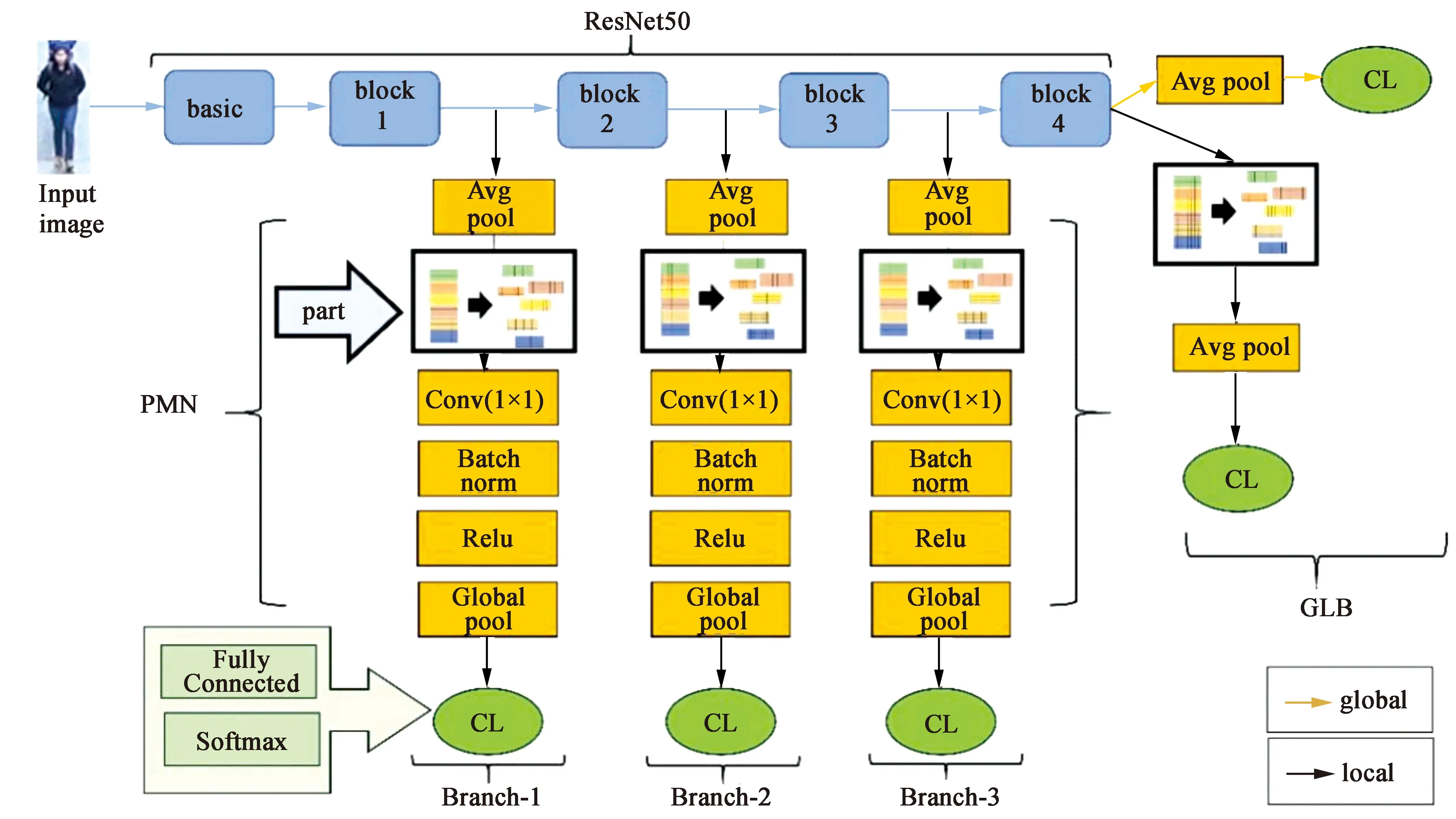
图2 MFF网络结构图
全局—局部特征分支网络可以分别从网络的最深层提取局部特征和全局特征.GLB网络由两部分结构组成,如图2所示.给定一个输入的行人图像,通过骨干网络学习提取行人图像特征图.全局分支中,ResNet50骨干网络之后添加了平均池化层以便获取256-dim的全局特征.分类器由全连接层和softmax函数层组成.添加的分类器将提取的全局特征进行分类,预测行人身份. GLB网络的局部分支则用于提取行人图像局部特征图.在block4模块中得到的特征图水平均分为六个部分来提取局部特征,如图3所示.在将特征图水平均分后,添加了平均池化层和分类器,以便将提取的局部特征进行分类从而预测行人身份.
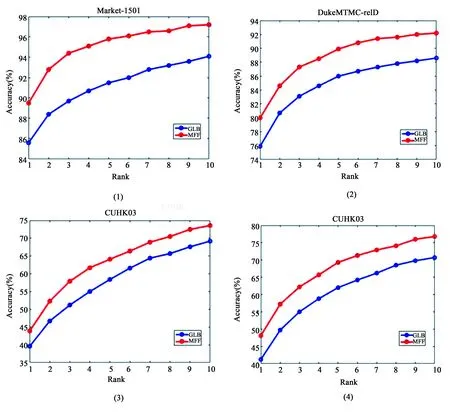
图3 GLB与MFF 在三个数据集上的Rank-1 accuracy至Rank-10 accuracy的比较

图3 行人特征图的水平均分方式
基于部分的多层次网络用于从网络的浅层到深层提取行人图像的局部特征.PMN网络结构分为三个部分:Branch-1, Branch-2和Branch-3. 如图2所示,ResNet50由四个网络模块组成,网络模块之间添加了Branch-1,Branch-2和Branch-3三个网络分支.首先,在每个分支中,对网络模块中学习到的特征图进行平均池化.然后,将特征图水平均分为六个部分(如前段所述).在分割的特征图之后添加一个1×1卷积核(kernel-sized)的卷积层(convolutional layer),一个批处理层(batch normalization layer),一个relu函数层和一个全局池化层(fully-connected layer,FC),得到6×256-dim的局部特征.最后将行人图像的局部特征输入到分类器中.每个分类器都由全连接层和softmax层构成并用于身份预测.其中,Branch-1,Branch-2和Branch-3在网络中是并行运行的.
在多层次特征融合网络中,输入的行人图像经过ResNet50骨干网络进行简单的特征提取,得到特征图.而后,通过多条分支网络来进一步细致提取特征图的局部特征以及全局特征.PMN中提取局部特征是通过将特征图进行水平切块的方式提取每个切块的特征.GLB中通过网络层来将特征图的全局特征进行细致提取,提取到的特征则通过softmax loss(2.3节)来预测提取的特征属于特定行人的概率.多层次特征融合网络主要是应用于识别行人图像,对于视频这类多维度特征提取仍需进一步的研究.
3.3损失函数Softmax损失函数多用于解决多分类问题.行人重识别问题也被视为多类分类问题.目前,Softmax损失函数被广泛用于各种基于深度学习的行人重识别方法中.本文也将Softmax函数作为损失函数来完成分类任务.
在MFF网络结构中,行人重识别问题被视为多分类问题.对于第i个学习到的特征,softmax损失函数如下:
(1)
其中Kc是类c的权重,D是在训练集中包含的行人身份的数量,M是在训练进程中的一个批量(mini-batch)图像集的大小.在MFF网络模型中,GLB和PMN提取的特征皆在softmax 损失函数被使用.
MFF的总损失函数为
(2)

4 实 验
4.1数据集本文提出的网络模型分别在Market-1501[28],DukeMTMC-reID[6]和CUHK03[29]三个数据集上进行实验来评估MFF模型的性能.
Market-1501[28]数据集:六个摄像机拍摄到的1 501个行人身份(id),在不同摄像机视角下检测到的行人总数为32 668个.在这个数据集中,每个行人至少被两个不同的摄相机拍摄到.在Market-1501中,训练集由751个行人身份组成,平均每个行人身份包含17.2个行人图像;测试集由750个行人身份组成,测试集由19 732张图像组成.数据集使用mAP(mean Average Precision )来评估行人重识别算法的性能.
DukeMTMC-reID[6]数据集:包含1 411个行人身份.在八个不同的摄像头下拍摄到36 411张行人图像.数据集中的每幅图像是从视频中采样得到的,在视频中,每隔120帧采样到一张行人图像.数据集由16 552个训练图像、2 228个查询图像和17 661个图库图像组成.其中一半的行人图像被随机采样为训练集,其他的则作为测试集.
CUHK03[29]数据集:由13 614张行人图像和1 467个行人身份组成.每个行人至少由两个摄像头拍摄到.在此数据集中,行人边界框( bounding boxes)通过两种不同方式提供:自动检测的边界框和人工手动标记的边界框.
4.2实验细节MFF网络先在ImageNet[32]上对ResNet50网络进行了预训练,然后将ResNet50网络中使用的权重也用于MFF模型.整个网络在Pytorch深度学习环境中进行训练.网络代码在python中进行编辑. 实验中计算机配置系统是64位的ubuntu 16.04LTS. MFF网络训练时,使用单个GPU进行训练,GPU的类型为NVIDA GEFORCE GTX1080.同时根据显卡的配置,批处理数量(batch size)被设置为32,下降率设置为0.5.三个数据集分别设置了三个不同的学习率.其中 Market-1501数据集中使用的学习率是0.05. 在DukeMTMC-reID数据集上进行训练时,学习率设置为0.045. CUHK03数据集的学习率为0.08. 整个训练过程将在60轮后终止. 在实验过程中,通过随机选择的方式选取一张图像作为查询图像. 输入的行人图像的尺寸大小调整为384×192.
4.3Market-1501数据集的结果比较表1列举了在Market-1501数据集上本文的方法与现有方法的比较情况.MFF模型的实验结果与近年来在Market-1501数据集上实验的几种最新的行人重识别方法进行比较,其中词袋(bag of words)模型(BoW + KISSME[28])采用了手工绘制的方法,SVDNet[29]使用深度学习模型提取全局特征,PAR (part-aligned representation)[17]使用深度学习网络模型提取图像局部特征.表1 结果表明MFF模型在Ran-1精度,Rank-5精度和Rank-10精度方面都获得了最佳结果.本文将mAP作为行人重识别的评价指标.MFF模型的mAP值在Market-1501数据集上达到了71.7%,比最佳方法[34]高出2.6%.另外,MFF模型的Ran-1精度达到89.5%,比最佳方法[34]高1.8%;Ran-5精度达到95.8%,比最佳比较方法[34]高1.6%.本文提出的MFF模型通过融合全局特征和局部特征来提升模型的性能,同时在提取局部特征时添加PMN结构也有助于获得更好的实验效果.
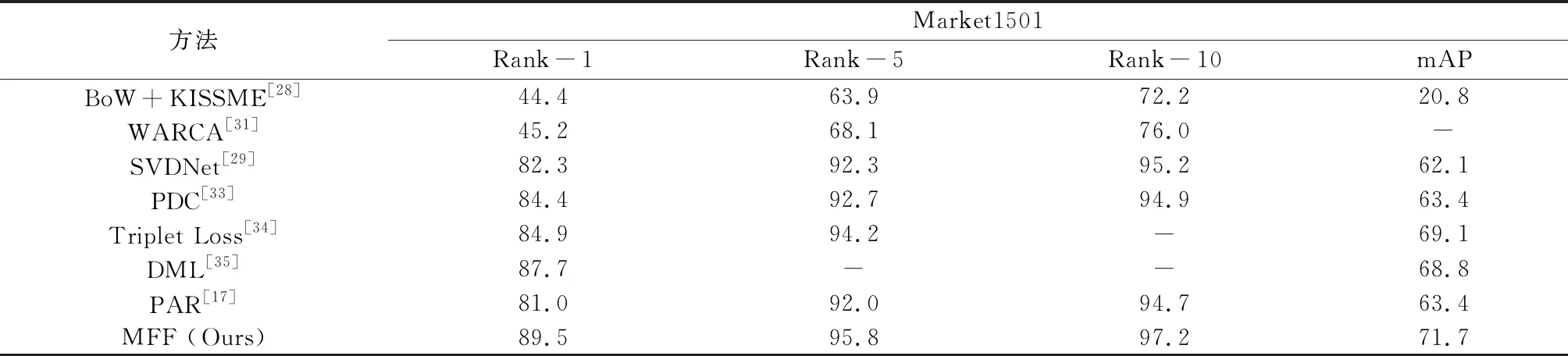
表1 Market-1501结果
4.4CUHK03数据集的结果比较MFF模型分别在CUHK03_detected数据集和CUHK03_labeled数据集上进行了实验.本文在CUHK03_detected和CUHK03_labeled数据集上使用单一行人图像查询的方式进行实验,同时与许多先进的算法和网络模型进行了比较,例如使用horizontal occurrence 模型的LOMO + KISSME[6],使用harmonious attention模块的行人对齐网络(Pedestrian alignment network)[37]和HA-CNN[22].在实验中,Rank-1精度和mAP作为性能评价的指标.根据表2所示,MFF模型的Rank-1精度达到43.9%,比在CUHK03_detected上的最佳方法[21]高了2.2%. mAP值达到40.0%,比最佳实验结果高1.4%.在CUHK03_labeled上的比较结果如下: Rank-1精度比HA-CNN[21]高出3.7%. MFF模型的mAP达到42.9%,分别比HA-CNN[21],SVDNet[29]和MSR[38]高出1.9%,5.1%,2.4%.
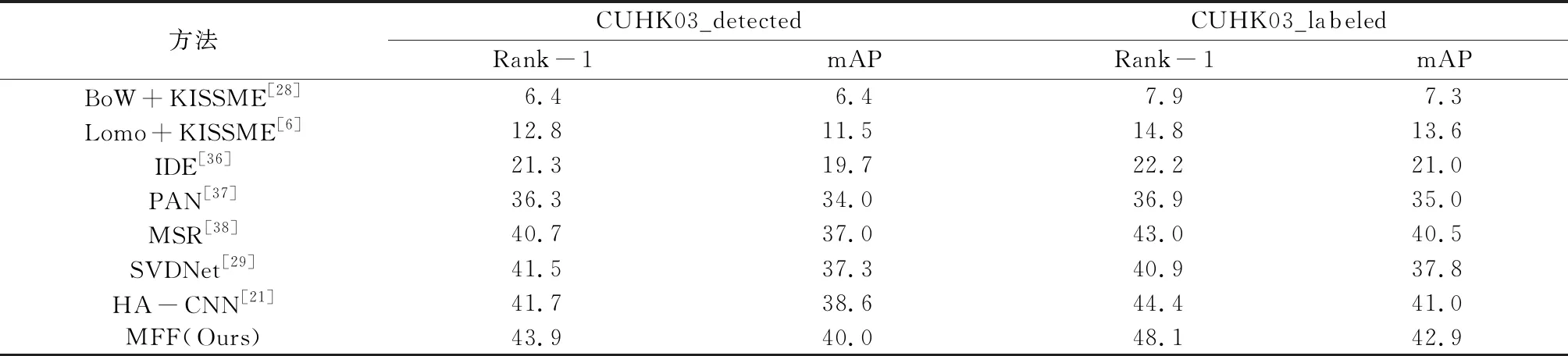
表2 CUHK03结果
4.5DukeMTMC-reID数据集的结果比较表3显示了MFF模型与在DukeMTMC-reID数据集上的最新方法结果的比较.在表3展示的算法中,其提取特征的方式各有不同,例如:LOMO+KISSME[6]使用horizontal occurrence模型提取局部特征,PAN[37]和SVDNet[29]使用深度学习模型提取全局特征.在DukeMTMC-reID数据集上的实验评估结果表明MFF模型在行人重识别中展现了很好的性能.MFF模型的Rank-1精度达到80.0%,mAP值达到61.8%,分别比ARCN[40]、SVDNet[6]和MSR[38]高9.8%,5%,1.2%.
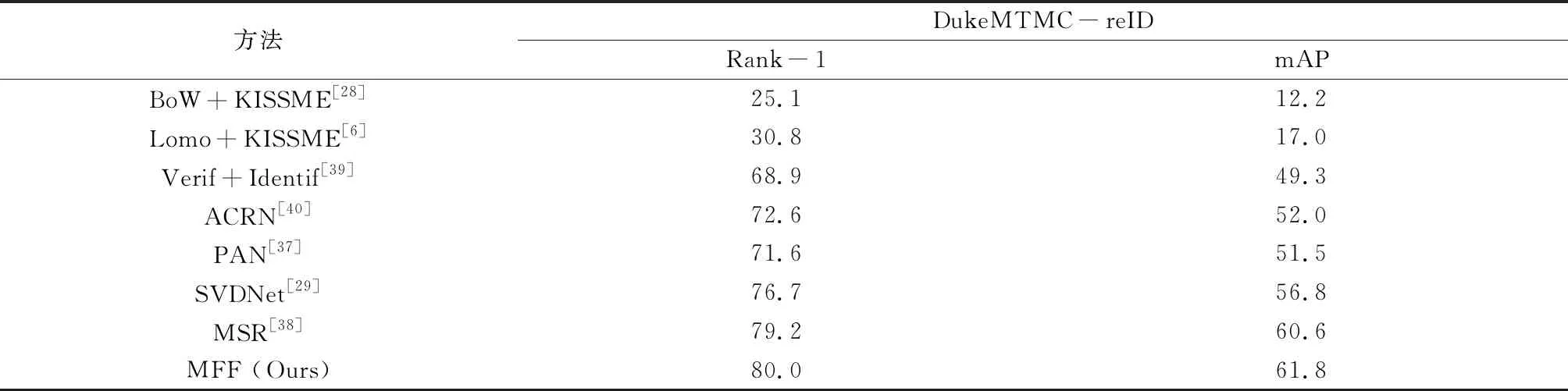
表3 DukeMTMC-reID结果
4.6PMN结构的作用评估本文分别在三个经典数据集上评估了MFF网络的效果:Market1501,CUHK03和DukeMTMC-reID.本文提出的PMN这一网络模型分别从浅层网络到深层网络图像提取局部特征.为了进一步探讨PMN结构的影响,在每个数据集上分别进行了两个实验:1) 去掉了MFF网络中的PMN结构,只通过GLB结构提取局部特征和全局特征;2) 保留MFF网络中的PMN结构,利用GLB和PMN提取局部特征和全局特征.如图3所示,GLB是没有PMN模型的网络.单独在GLB网络上运行得到的实验结果清楚地展示了去掉PMN结构时的网络模型性能.本文分别在三个数据集上训练MFF模型,并在图3中展示了实验结果.
5 结 语
本文主要验证了MFF模型在解决行人重识别问题中的重要作用,提出的MFF模型来提取局部特征和全局特征,提出的PMN结构不仅可以分别从网络的浅层到深层提取更为全面的局部特征,还可以被灵活地应用于不同的深度学习模型当中. PMN结构极大地提高了MFF网络的性能.本文提出的MFF网络有效地提高了行人重识别中目标人员搜索的精确度,并且在多个数据集上表现效果都为最佳,这充分表明了模型的有效性.
