基于上证180指数的风险价值研究
2020-07-23周木子
周木子
(西南大学数学与统计学院,重庆 400000)
一、选题背景与意义
(一)选题背景
风险指的是当与其有关的影响因素发生变化的时候,引发的投资者持有资本受损的过程。通常情况下,风险发生的可能性未知,并且发生之后带来的市场损失也未知,这也是风险所具有的基本属性。一般情况下金融风险本身很难人为规避,在风险发生后造成的个人、机构乃至国家损失也无法轻易避免。因此,如何对金融风险进行有效的管控是上至全球每个国家,下至每个金融投资者都需要密切关注的问题。在风险控制过程当中,对风险值进行有效和精确的计算是前提条件也是重要环节,往往决定着是否可以对风险进行有效管控。因此找出一个能够精确度量金融风险的方法便具有重要意义。本文在国内外现有研究的基础之上,通过一系列理论分析,将四种计算风险的VaR模型结合相关股票数据应用的实证分析中,通过比较几种不同的度量方法的优缺点以及它们的适用环境,试图找出能够精确衡量风险的最有效方法,并根据最终的模型结果来分析上证180 指数风险。由于国内目前对于金融市场风险度量方面的具体研究深度与广度都低于西方,对于风险管理方法的研究应用也都尚未成熟,因此对于风险测度VaR方法的研究也有待深入。本文旨在通过对于风险测度VaR模型的理论和实证分析研究对比研究得到最合适的风险度量方法,最终提出可行性建议。
(二)文献综述
风险的定义最早是由奈特在1921年提出,他在《风险、不确定性及利润》一文中表示随机事件的不确定性就是风险。紧接着在1963 年,Bautnol W 首次提出了利用风险价值VaR 量化投资风险的概念。G30 集团在1993 年正式提出用来度量市场风险的风险价值(VaR)模型。
Chun-Pin[1]在2012年运用半参数方法,通过联合极值理论和多样Copula 模型的构建计算VaR 的值,成功克服金融数据的不良特征。Gregor N[8]在2013年将C-GARCH 模型与动态条件相关模型两种预测VaR值的方法比较分析,对比准确性。Cheng-Few Lee[10]在2012 年通过广义t 积分对资产报酬进行拟合,解决了在正态分布的假设条件下,金融数据VaR值尖峰厚尾的不良特性。极值问题是由Bortkiewicz于1923年第一次提出,接着Fisher和Tippet 对极值分布做了更深一步的探讨并提出著名的极值理论。从国内外大量的实证研究资料可以看出,随着金融市场不断地发展,学者对于VaR 模型也在不断地进行完善,提高精确度,得到更为精准有效的VaR值,但哪种模型为最优模型始终没有定论,还是各国专家学者的研究重点。
(三)研究内容、方法、创新与不足之处
1.研究内容
本文研究的主要目的是寻求到更加准确的风险度量方法,通过四种模型来计算股票数据的VaR 值,再通过Kupiec提出的方法对于四个模型分别进行有效性检验,经过比较后得到最优风险测度模型。为了验证理论,利用股票数据进行了进一步的实证分析,用不同的模型分别计算出估计的风险值VaR,并通过最终的返回测试检验预测的失败率,从而将四种不同方法模型预测出的精确度进行比较,选择出最为有效的模型。综上所述,本文分别从理论和实践两个方面对比研究计算VaR的不同方法,并最终筛选出最优的预测模型加以分析。
2.研究方法
文中先是从理论方面对测量模型进行研究,接着构建模型进行实证分析,在计算出每个模型的VaR 估计值之后,通过检验四个模型计算结果的成功率来比较衡量每个模型的精确度。因此采用的是理论结合实证的方法,通过理论研究将四种方法:方差协方差法、历史模拟法、GARCH模型拟合法以及极值模型应用到实证分析过程中,利用收集到的股票数据对四种方法依此进行实证研究,可以分别得到四种模型计算出来的上证180 指数的VaR估计值,接着再对得到的结果进行返回测试,通过对比测试结果可以选择出一个相对最优模型的结果做最终分析。文中的实证分析过程和结果主要通过R软件实现。
二、实证研究
本文是选择可以代表上海股市并且具有较大涵盖度规模的上证180 指数作为实证分析的数据。上证180指数具有较大的波动情况,用来做实证分析更具有现实意义。文中选取的数据区间为:2015年1 月到2019年12 月共有1219 个数据,数据是从大智慧软件中获取。
(一)数据预处理
1.数据清理:本文只保留交易日的数据,这样一来在交易时间上肯定是不连续的,为了不把问题复杂化,本文将原始数据交易时间设为相等间隔,并选用日作为时间单位。
2.数据转换:在经过数据清理后可以得到收盘价序列pt,由于上证180股票数据中包含的每一只成分股价格都有或大或小的差异,因此考虑采用收益率来衡量风险大小,收益率最常见的是以下两种形式:
常规定义为:pt/pt−1−1,
另一种是对数收益率定义:rt=ln(pt)−ln(pt−1)
本文中采用第二种对数收益率的定义方式。
(二)历史模拟法计算VaR
在上一章已经提过,历史模拟法的优点是不需要对数据分布进行假定,就能够求出风险值,但同时求出的结果是比较粗糙的,只能确定风险值的大致范围。因此,在对收益率序列的分布没有进行研究和假定之前,我们的第一选择依然是历史模拟法。大致的操作步骤如下:
先对上证180指数收益序列从小到大进行完整排序,接着在给定置信水平1−α((其中α= 0.05)的条件下,定位出收益率序列中位于此处的数据,该数据便可当作风险值的近似取值。实际代入数据后,通过计算可知该位置是60.9,该位置上的数据取值为61。由此得到的最大收益率为-2.287845,因此每单位资本投在这股票上所面临的风险为:
VaR=I*|Rmax|=2.29
(三)协方差矩阵法计算VaR
上文中已经提到,协方差矩阵法需要提前假定收益率序列服从正态分布,利用方差协方差计算VaR值的基本步骤为:
1.根据上证180指数收集到的收盘价历史数据计算出该序列的对数收益率。
2.计算出相应对数收益率的方差、协方差与标准差。
3.在给定的置信水平下,根据公式求出VaR值。
计算公式与结果如下:
VaR=I0*zα* σ
通过公式代入数据可求得σ = 0.785712,因此
VaR=1*1.96*(0.785712)=1.54
(四)GARCH模型计算VaR
在使用GARCH模型拟合序列时,通常情况下,残差分布有正态分布、t 分布和GED 分布三种假设,而通过对于序列的分析,可以看出收益率序列具有显的尖峰后尾和不对称特性,因此本文选择可以体现该特性的t分布进行拟合。一般情况下,在对金融数据收益率序列进行GARCH 模型拟合时用低阶模型就有很好的效果,因此本文建立基于t分布的四个低阶GARCH模型,并分别进行拟合,然后根据AIC和BIC准则,确定拟合效果最好的模型。在显著性水平0.05的条件下,只有GARCH(1,1) 模型的系数全部通过了t检验,并且拟合效果较好,而其余三个模型均有系数未通过检验。下面是四个模型的AIC与BIC值:根据模型拟合结果,可以得到最终GARCH(1,1)模型:

表2 -1 GARCH模型AIC与BIC

1.计算VaR
根据前文,可以知道当收益率序列的条件方差被求出后,第t期的风险值VaR 可以表示成如下形式:
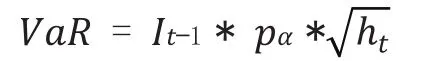
其中It−1表示的是第t-1期的投资数额,,pα表示的是在给定置信水平下t 分布对应的分位数,当中α= 0.05时,,pα表= 1.96,因此可以求得
VaR=1*1,142857*1.96=2.24
根据GARCH模型,可计算VaR的十期预测值VaR1,VaR2,...VaR10 如下:

表2 -2 VaR十期预测值
2.VaR事后检验
由于我们的研究对象是风险值VaR,因此即使模型可以比较好地拟合收益率序列,也并不能说明预测的准确性,先要验证精确度需要进一步的检验。本文采用的检验方法为Kupiec检验法,也就是检验预测失败的频率,在显著性水平中α=0.05的情况下,可以绘制出预测失败频数图:
由输出结果可以看出,可以接受超出风险值损失个数区间是[20,43],而在本例中根据数据计算出来超出VaR值的损失共有35 次,处于可接受区间内,进一步印证了所选模型GARCH(1,1)可以很好地拟合上证180 指数风险。
(五)基于极值理论计算VaR
1.选取阈值本文采取的是相对比较简单直观的MEF法,也就是通过观察期望图30的线性走势来选取门限值。由图2-2可以看出,图形呈现线性的取值范围是收益率为-2以内,与此对应的阈值取值为2。在阈值为2左右时,模型估计的参数是基本保持不变的,因此可以选取2为阈值。

图2 -1 Kupiec失败频数图

图2 -2 超限期望图
2.参数估计利用样本数据对数收益率拟合GPD模型参数,方法选取最大似然估计法,来估计GPD分布中的尺度与形状参数,结果如下表所示:

表2 -3 GPD模型参数极大似然估计
3.利用GPD模型计算VaR值:
利用GPD模型计算风险值VaR的公式可以表示为:
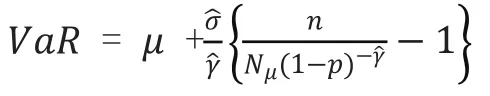
由此,可以得到在置信水平为(1−α)(α=0.05)的条件下,基于GPD 模型的极值理论估计出的VaR值为2.96。
(六) 模型有效性检验
1.Kupiec检验法
可以将检验过程看作检验N/T的期望值与超额损失概率p是否有显著不同。因此,期望概率为p,给定置信水平1-中α ,原假设是:N/T=P,预测失败概率为N/T,构造似然比检验统计量如下:

这个统计量服从的是自由度为1的卡方分布。
2.检验结果
由收集到的上证180指数样本数据进行有效性检验,结果如下表:

表2 -4 不同模型的返回测试值
通过表中结果可以看出:利用方差协方差方法,在置信水平为95%的条件下,计算出的失败率大于5%,而由历史模拟法和基于GARCH模型计算出来的结果相对比较准确,在95% 的置信水平下,模型计算出的失败率都非常接近5%。GARCH模型的误差相对最小,是由于该模型还能很好的解决异方差函数所具有的长期自相关的问题。基于极值理论的VaR模型,在给定95%的置信水平下,失败率远小于5%,误差也是比较大的,可见该模型在用来估计风险值时也具有一定的缺陷。
三、结论与展望
(一) 结论
本文先是对风险进行概述,描述了风险对金融市场和金融投资者带来的可能影响,然后进一步阐述为了有效管控风险,要对风险进行度量,并详细介绍了度量风险的几种方法。文中实证分析部分主要是运用四种方法模型来进行风险度量,具体是协方差矩阵法、历史模拟法、基于GARCH模型的参数法以及极值法。重点对后两种方法进行详细介绍,同时对计算出的VaR值进行了有效性检验。经过上一章基于上证180指数收益率的实证分析,可以得到如下几个结论:
1.利用方差协方差和历史模型法模型计算出的VaR值精确度不高,是由于样本数据上证180指数收盘价收益率序列不是服从正态分布,而是尖峰厚尾。这个从最后的有效性检验可以看出,该模型在给定的置信水平下估计出的结果失败率偏大,风险值被低估。
2.基于GARCH-t模型计算出的VaR值,精确度较高,在给定的置信水平的条件下计算出来的结果误差很小,因此可以人为在一般不出现极端事件的情况下,利用该模型度量风险是比较准确有效的。
(3)基于极值理论的VaR模型,不用对数据的分布做出假设,可以避免因对样本数据分布判断失误而导致预测精度下降。从上一章中实证检验结果可以看出,在给定置信水平的条件下,基于GPD模型计算出来的VaR估计值结果不是特别理想,在返回测试中的失败率都小于显著性水平,导致这个结果出现的原因是基于极值理论建立的GPD模型并没有考虑到金融市场上数据普遍存在的波动性,因此作为静态模型在度量风险值时存在一定的缺陷性。
(二)不足
本文主要运用VaR模型来计算股市风险,主要针对计算VaR的不同方法展开详细研究,在经常使用的方差协方差模型基础之上,又进一步采用历史模拟法、GARCH模型和极值理论的VaR 模型来计算上证180 指数风险,最终用数据检验结果的精确度,返回测试比较模型的VaR 值。同时通过对模型预测结果的有效性检验对四种方法进行对比研究。选取的样本区间从2015年1月到2019年12月,时间跨度较大,样本数据比较新,使得实证分析出的结果更具有现实意义。不足之处在于选取的样本数据覆盖面可能不够广,选取上证180指数对于上海的股票市场具有价值但对其他金融市场的参考性可能不是特别大。
(三)展望
金融市场中资产收益数据往往都具有波动集聚性和尖峰厚尾性,而利用传统方法方差协方差和历史模拟法,并不能将其特性很好的考虑进去,因此在度量金融市场风险值时精确度不高。而文中的GARCH模型和极值模型度量VaR值则分别可以解决金融市场的波动率和极端值问题,因此相较于前两种方法更为有效。但同时,这两种方法也只能是分别针对其中一个特点的改进方法,并不能将两种特质同时考虑进去,因此用来测度风险的结果还是不够精确。接下来可以继续研究更为全面完善的方法,将金融市场数据特点都考虑在内,进一步提高模型的精确度。
