基于Hadoop 的电影用户行为预测系统设计
2020-07-21孙妍姑
冯 辉,陈 磊,孙妍姑
(淮南师范学院 计算机学院,安徽 淮南 232038)
1 引 言
据权威部门统计,截止2018 年7 月底,我国互联网用户规模已达8.02 亿, 其中视屏用户规模达6.09 亿[1]。电影服务类网站随着用户数量的急剧增加,产生了海量的电影用户评价数据,这些数据为我们分析用户行为提供了有效支持。然而,一方面,基于海量电影用户评价数据(以下简称海量评价数据)的用户行为模型(User Behavior model,UBM)构建具有挑战性,另一方面,采用传统单机串行数据处理系统处理海量用户评价数据显得相形见绌,使用户行为计算、预测变得比较困难。
贝叶斯网络(Bayesian Network,BN)是有向无环图(Directed Acyclic Graph,DAG)的一种,用条件概率表(Conditional Probability Table,CPT)描述网络中各节点依赖关系值,是一种帮助人们在不同应用场景下分析模型各属性间依赖关系的有效工具,它将概率统计引入,能够进行各属性间不确定性推理[2](P9-12),在不同领域都有着广泛应用。 如图1 所示。采用贝叶斯网络能够较好的反映出电影用户行为的不确定性,为系统实现提供了技术支持。
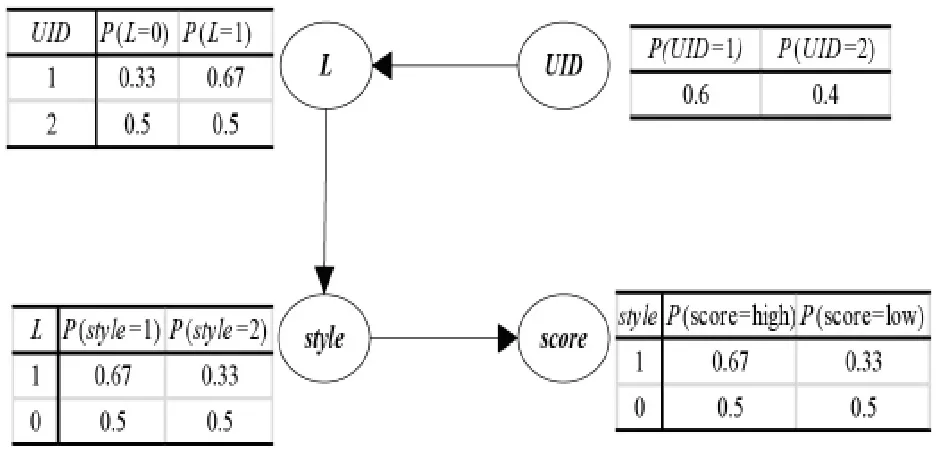
图1 贝叶斯网络
面对海量评价数据,传统单机串行数据处理系统已经不能满足人们对数据处理实时性及高效性的要求。Hadoop 是一个分布式海量数据处理平台,以Hadoop 分布式文件系统 (Hadoop Distributed File System,HDFS)和离线计算框架MapReduce 为核心,主要有高可靠性、高拓展性、高效性、高容错性等优点[3](P48-50)。 用户可以根据不同的应用场景,编写符合自身业务需求的MapReduce 程序, 实现海量数据实时、高效处理的功能。Hadoop 的出现为分析海量评价数据、构建UBM 以及对用户行为预测提供可能。
目前,以贝叶斯网络为基础,以Hadoop 为平台构建UBM,分析、预测用户行为这一课题吸引着众多学者进行研究。王飞考虑到电影用户评价数据及其评价行为随着时间的变化而变化这一特性,将用户评价行为作为贝叶斯网络中用户属性的隐变量,构建可以描述用户动态行为的评价模型[4],建立在Hadoop 平台的实验验证了此方法实现用户行为预测的高效性。徐雅芸为了提高用户行为预测准确率,改进了BiGRU-ADtt 模型,考虑到用户评价数据服从幂律分布及对称特点, 首先采用BiGRU模型分析出不同用户评价行为之间的依赖关系,然后将评价数据的对称性特点作为衡量评价行为的依据, 最后建立在Hadoop 上的真实数据表明该方法能够充分挖掘用户行为习惯,实现高准确率的用户行为预测[5,6]。
本文以贝叶斯网为基础, 以Hadoop 平台为工具,首先将海量评价数据及初始UBM 存入Hadoop分布式数据库(Hadoop Database)HBase 中,然后利用MapReduce 结合期望优化 (Expectation Maximization ,EM) 算法将缺失的描述用户行为的数据补全, 接着并行化爬山算法, 以贝叶斯信息准则(Bayesian Information Criterion,BIC) 为度量标准,高效构建并选择最优UBM, 最后根据模型预测用户行为。
2 系统设计
2.1 系统架构设计
针对上述问题,本系统从可维护性及可拓展性出发,采用层次化设计结构,主要分为数据层、算法层、业务层以及用户接口层,总体设计架构如图2所示。
1. 数据层: 该层是整体架构的最底层, 包含HDFS 分布式文件系统及HBase 分布式数据库,主要是对海量评价数据以及初始UBM 进行存储,并与MapReduce 计算框架交互, 为后续计算用户行为、构建UBM 提供数据支持。
2.算法层:主要是对EM 算法、爬山算法并行化, 并结合BIC 评分寻找描述用户行为的最优模型,根据模型计算、预测用户行为。
3. 业务层: 该层是用户行为预测功能实现层次,主要包含数据存储模块、数据处理模块、UBM构建及预测模块。
4.用户接口层:用户接口层实现了用户与系统进行交互的层次,用户可以通过用户接口向系统提交请求,并得到相应的响应。
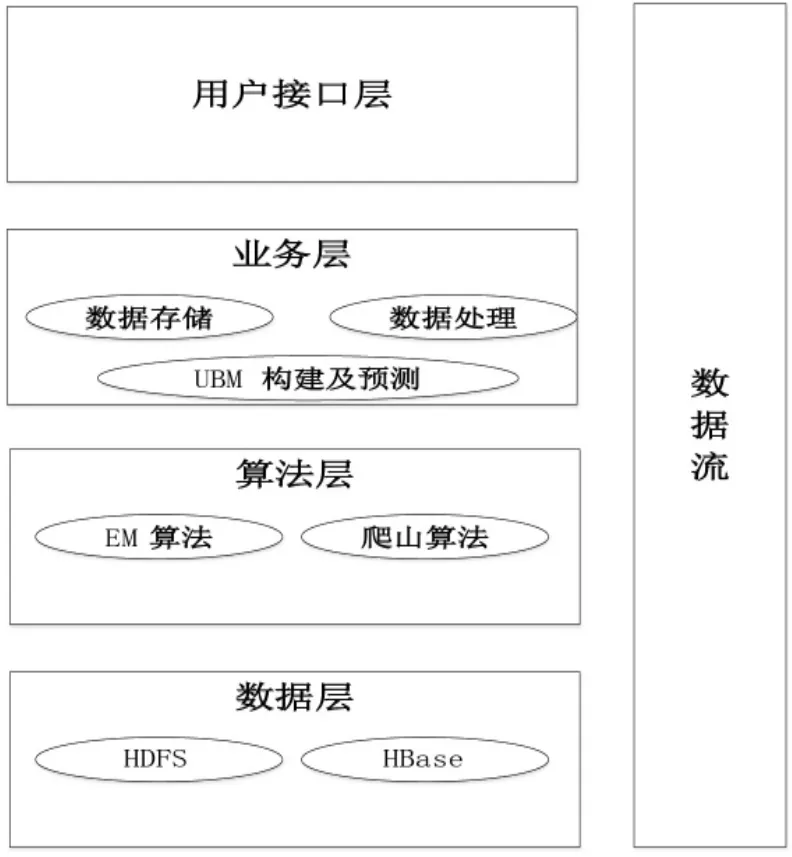
图2 系统整体架构图
2.2 系统功能设计
通过对系统业务层进行分析,按照其需求将系统划分成不同的功能模块,具体的功能模块结构如图3 所示。

图3 系统功能模块图
2.2.1 数据存储模块
数据存储模块包含三个功能子模块,即海量评价数据的存储、 贝叶斯网DAG 结构以及条件概率表(CPT)的存储。 在存储海量评价数据之前,需要对数据进行预处理,提取出评分数据属性[7]作为评分的特征信息,并存入HBase 中。 贝叶斯网是描述用户评价数据各属性之间关系及构建UBM 的工具,对其存储是一个技术热点,主要是对其DAG 结构以及描述有向边关系的条件概率表(CPT)的存储,这里定义二元组[8]R=(Gu,S)来表示一个贝叶斯网, 其中Gu 为贝叶斯网的DAG 结构,S 为条件概率表(CPT)的集合,分别使用Map 函数并行读取Gu、S,再使用Reduce 函数进行合并、规约操作,最终生成包含DAG 结构以及CPT 的键值对,最终存入HBase 中。
2.2.2 数据处理模块
在实际的用户评价数据集中,并不包含用户行为这一属性,而本文研究的重点就是从海量评价数据出推演用户行为,因此挖掘用户行为是一项重要工作。数据处理模块主要功能就是以海量评价数据为基础,将EM 算法与MapReduce 相结合,实现并行化挖掘用户行为功能,具体过程我们将在第3 章进一步阐述。
2.2.3 UBM 构建及预测模块
UBM 构建及预测是本文的核心模块, 通过构建好的UBM 实现行为预测功能,其中主要使用了爬山算法及贝叶斯信息准则。
爬山算法是经典的贝叶斯网结构学习算法,目标是从众多候选模型中找出评分最高的模型。 首先,从初始模型开始搜索,一般把初始模型定义为无边模型,在进行搜索时,利用三个搜索算子(即加边、减边、转边)对选定模型进行局部修改,然后对每一个经过局部修改后的模型进行BIC 度量,选择评分最高的模型与选定模型进行比较,若选定模型的BIC 评分值比评分最高模型的分值小,则将后者作为下一个选定模型,继续搜索,具体过程我们将在第3 章进一步阐述。
贝叶斯信息准则(Bayesian Information Criterion,BIC)是一种可以度量UBM 与用户评价数据之间关系的方法,并用拟合程度表达,拟合程度越高,则表示当前UBM 的BIC 分值就越高。
由数据存储模块、数据处理模块分别得到初始描述用户行为的贝叶斯网络以及带有用户行为的完整评价数据集, 然后利用MapReduce 与爬山法及BIC 评分相结合,并行化构建用户行为构建,最后根据用户模型,计算用户行为。
3 算法层详细设计
3.1 EM 算法设计
如2.2.2 节所述, 在实际的用户评价数据集中并没有用户行为这一属性,这里把用户行为称为缺失值。
期望优化(Expectation Maximization,EM)算法是经典的参数学习算法, 通过E、M 步骤的反复迭代,达到对缺失值进行补全的目的。
本文用ti表示用户评价某个时间片,L 表示用户行为(L∈{0,1}),θ 为结点CPT 集合,对给定的DAG 结构, 采用EM 算法对含有N 个评价实例的评价数据集[4]的用户行为进行填充时,从随机产生的初始值θ0开始迭代, 设已经进行了l 次迭代,得到参数估计为θl,第l+1 次迭代过程可由算法1 表示。 为了提高计算效率,将MapReduce 计算框架引入,实现EM 算法的并行化,并生成相应的key/value键值对,算法流程图如4 所示。
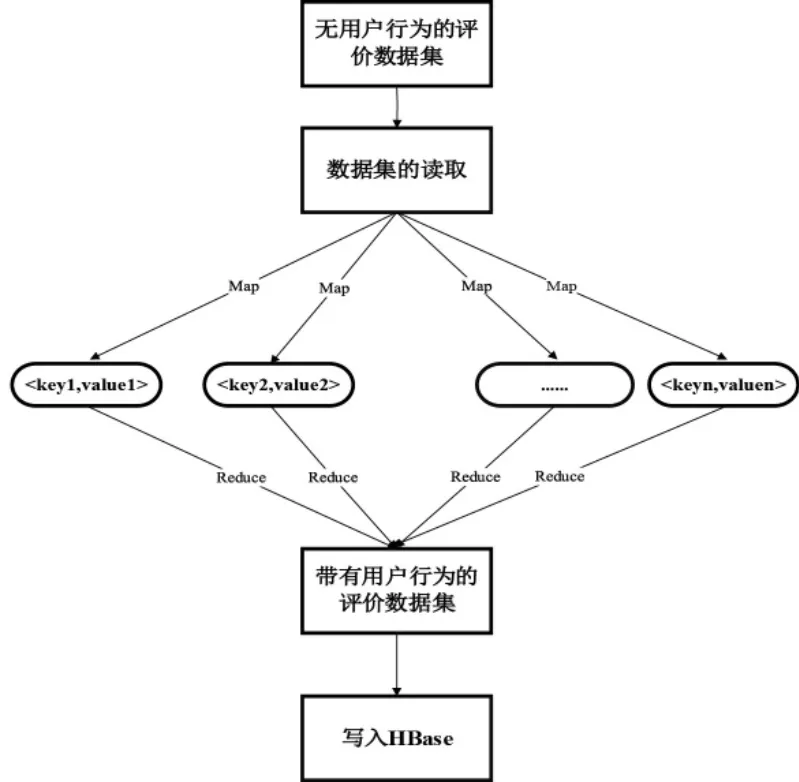
图4 并行化EM 算法流程图
算法1:并行化EM 算法
输入: δ—收敛阈值;
Dti—ti缺失用户行为的评价数据集;
G—ti爬山算法得到的UBM;
输出:Dti—ti中带有用户行为的评价数据集。
步骤:
l←0;θ0←随机参数值;
/*计算θl基于Dti的对数似然值*/
oldValue←L(θl|Dti);
while(true)
E-步骤:
Mapper 函数
key ←计算L 取值概率;
value ←计算L 取值概率和;
M-步骤:
Reducer 函数
计算参数θl+1;
计算θl+1基于Dti的对数似然值;
newValue←L(θl+1|Dti);
if (newValue-oldValue>δ)
oldValue←newValue;
l←l+1;
else
选择概率最高的填充值填充Dti;
return Dti.
end if
end while
3.2 爬山算法设计
由2.2.3 节所述, 通过爬山算法可以对基于贝叶斯网络的UBM 进行搜索操作,由三个搜索算子(加边、减边、转边)可产生多个候选UBM,再通过BIC 评分度量, 选择评分最高的UBM 与当前选定的UBM 进行比较, 若选定UBM 的BIC 分值比评分最高的UBM 分值小,则将后者作为下一个选定UBM,继续搜索。 为了提高模型搜索、打分效率,这里将爬山算法与MapReduce 相结合,实现模型搜索、评分地并行化,主要过程见算法2,流程图见图5。
算法2:并行化爬山算法
输入:δ—收敛阈值;
f=ValueBIC(g|Dti)—模型选择BIC 打分函数;
Dti—ti中评价数据集;
g0—初始DAG 结构;
输出:时间片ti中UBM 结构g.
步骤:
Mapper 函数
/*初始化g 结构最大似然估计g0*/
g ←g0;
/*调用算法1 填充用户行为值*/
θ←FillValue(g,Dti)
key←g;
value←θ;
oldValue←ValueBIC(g|Dti)
Reducer 函数
while (true)
g*←null;θ*←null;
newValue←-∞
for(爬山算法对g 搜索而得到的候选结构g′)
θ′←FillValueBIC(g′,Dti);
tempValue←ValueBIC(g′|Dti);
if (tempValue>newValue)
g*←g′;θ*←θ′;
newValue←tempValue;
end if
end for
if(newValue>oldValue)
g ←g*;θ←θ*;
oldValue←newValue;
else return g.
end if
end while
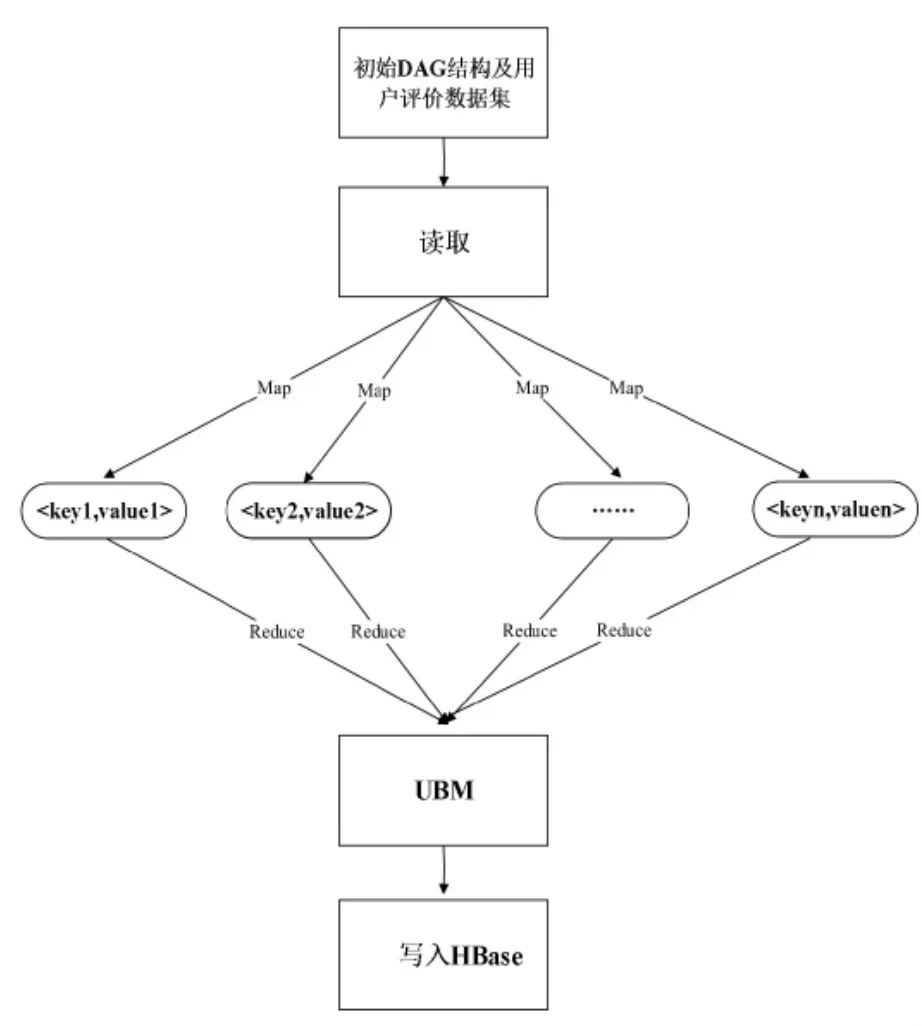
图5 并行化爬山算法流程图
4 系统实现
4.1 数据存储模块实现
1.测试数据来源。
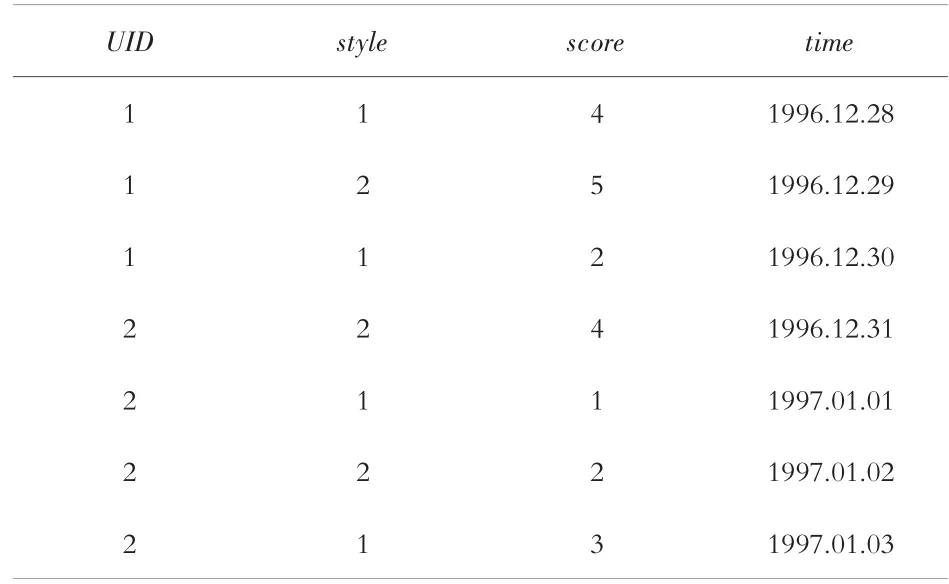
表1 用户评价数据
MovieLens 是一个关于电影评分的数据集,源于美国Minnesota 大学计算机科学与工程学院创建的一个非商业性质的、 以研究为目的的实验性站点,主要是对不同种类的电影进行描述,包含用户名称、电影类型、评分值、时间戳等基本信息[9]。 我们从中选取7 条评分数据作为测试,如表1 所示,其中UID 表示用户ID,style 表示影片类型,score表示用户对该电影的评分值,time 表示用户评价时间。
2. 评价数据存储。 分别启动HDFS、Yarn、HBase,调用MapReduce 计算框架,将最终的计算结果存储到HBase 中,命为UserData 表,如图6 所示。 对于给定的用户评价数据,逐行进行读取,并以时间time 为标识进行存储。

图6 UserData 表中的数据
3.贝叶斯网DAG 及CPT 存储。 针对表1 的用户评价数据,初始化一个UBM,如图6 所示,其中L 表 示 用 户 行 为,UID、style、score 为 评 价 数 据 属性, 属性之间的不确定性关系用条件概率表CPT表示。
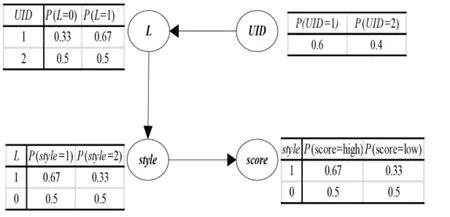
图7 初始的UBM
针对L 节点,在Map 阶段,Mapper 函数会读取该节点对应的CPT,即P(L=0|UID=1)=0.33、P(L=1|UID=1)=0.67、P(L=0|UID=2)=0.5、P(L=1|UID=2)=0.5, 然后根据以上读取的数值, 设置key=(L=0|UID=1),value=0.33、key=(L=1|UID=1),value=0.67、key=(L=0|UID=2),value=0.5、key=(L=1|UID=2),value=0.5,最后生成相应的key/value 键值对,即
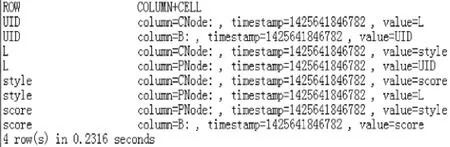
图8 DAG 表
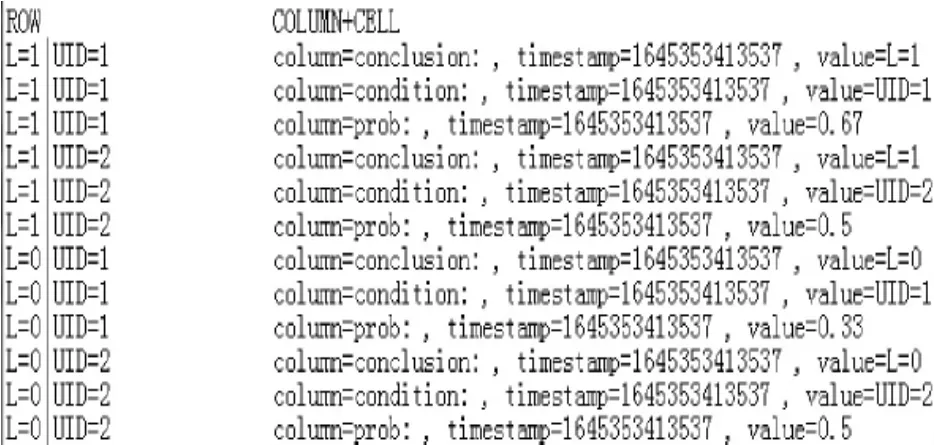
图9 CPT 表
4.2 数据处理模块实现
根据4.1 节存入的用户评价数据及初始UBM,调用算法1 对其进行用户行为补全,并最终将补全的完整用户评价数据写入HBase,如图10 所示。
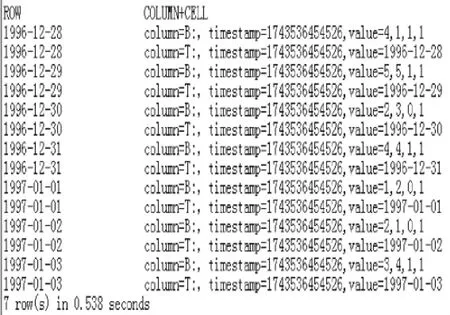
图10 完整用户评价数据
如1997.01.01 用户2 对于1 类型的电影评分为1,那么经过计算,将用户行为的值补全为1。
4.3 UBM 构建及预测模块实现
1.模型构建实现。调用算法1、2,基于完整评价数据集,对初始用户模型迭代搜索,并用BIC 评分对每个模型的搜索结果进行拟合程度评估,选取拟合度最高的模型作为最终的UBM, 并将最终结果写入HBase,如图11、12 分别表示描述最终构建完成的用户模型DAG 表及CPT 表。

图11 用户模型的DAG 表

图12 用户模型的CPT 表
根据上述的DAG 表与CPT 表,可以刻画出最终的UBM,如图13 所示。
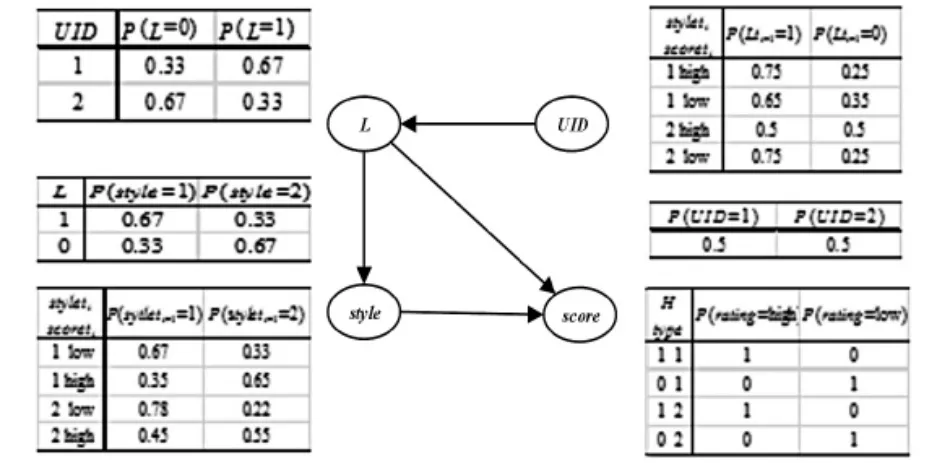
图13 最终的UBM
2. 用户行为预测。 从HBase 中读取构建好的UBM,采用贝叶斯网推理方法,预测用户行为。

图14 用户行为预测
从图14 可以发现,用户2 对于2 类型的电影,喜欢的概率为0.75,我们就认为用户2 对2 类型的电影存在偏好,并在以后的时间片内对2 类型电影有着较高概率的需求, 那么就可以根据这个结果,在近期为用户2 做2 类型的电影推荐。
5 系统测试
5.1 系统有效性测试
为了测试本系统预测用户行为的有效性和高效性, 本文截取了MovieLens 从1993-2013 年13 255个用户对18 种电影类型共12 435 232 行评价数据作为测试[10]。 实验环境设置主要包含一个Master 节点和三个Slave 节点,具体设置如表2 所示。
BPTF (Bayesian probabilistic tensor factorization)贝叶斯概率张量分解技术,在用户行为建模及预测领域有着广泛应用[11](P211-222)。
TCAM (temporal context-aware mixture model)也是一种受欢迎的用户行为预测模型,考虑到用户行为受时间变化的影响, 该模型融合了时间序列,使用户行为的预测更加精准[12]。
我们将采集到的1 243 522 行评价数据中前70%作为建模数据,后30%作为测试数据。 测试了BPTF、TCAM、UBM 用户行为预测的准确率(Precision)和覆盖率(Coverage)。 用precision@k 表示各模型返回k 个用户行为的准确率[13];用coverage@k表示各模型返回k 个用户行为的覆盖率[14],分别如表3、4 所示, 从表可知UBM 在预测用户行为的准确率、覆盖率均高于其他模型,这验证了本文提出的基于UBM 的系统在预测用户行为的有效性。

表2 节点软硬件配置表
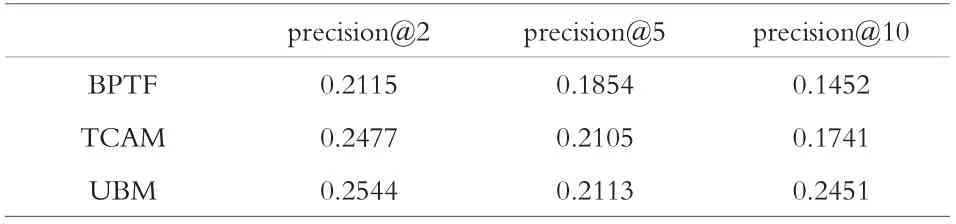
表3 准确率
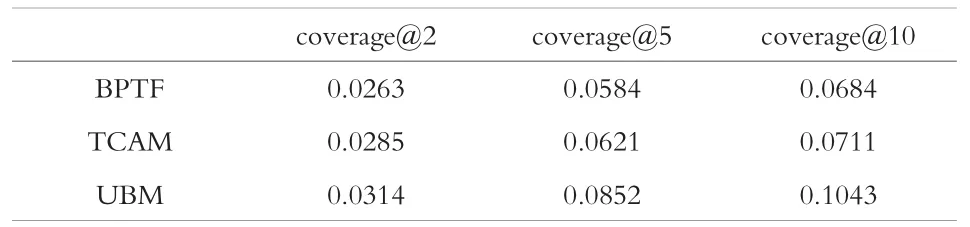
表4 覆盖率
5.2 系统运行效率测试
基于表2 的Hadoop 分布式计算集群的配置,我们将测试数据分为100KB、1MB 及10MB 三个级别,测试了算法在并行、串行环境下的执行效率,测试结果见表5。
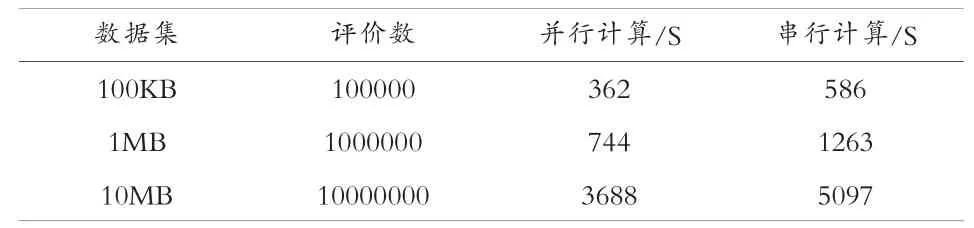
表5 并行计算与串行计算运行时间对比
从表5 的实验结果我们可以看出,随着测试数据量的增加,传统单机串行系统的算法执行效率明显低于Hadoop 分布式集群[15]。
6 总结与展望
本文从海量电影用户评分数据出发,以Hadoop 平台中的MapReduce 计算框架为依托,以贝叶斯网络为不确定性推理工具,并结合期望优化(EM)算法、爬山算法、贝叶斯信息准则(BIC),设计了一种能够从海量电影用户评价数据中构建用户行为模型(UBM),并进行用户行为预测的系统,实验验证了本系统的有效性及高效性。
本文为在海量用户评价数据情况下,用户行为建模、计算及预测提供了思路。 但这只是用户行为预测初步探索,随着新的评价数据不断追加[13],用户行为不断演变, 如何在数据发生变化的时候,模型的训练依旧取得较好的效果,这是今后要开展的工作。
