Prediction method of restoring force based on online AdaBoost regression tree algorithm in hybrid test
2020-07-20WangYanhuaJingWuJingWangCheng
Wang Yanhua Lü Jing Wu Jing Wang Cheng
(Key Laboratory of Concrete and Pre-stressed Concrete Structures of Ministry of Education, Southeast University, Nanjing 210096, China)
Abstract:In order to solve the poor generalization ability of the back-propagation(BP) neural network in the model updating hybrid test, a novel method called the AdaBoost regression tree algorithm is introduced into the model updating procedure in hybrid tests. During the learning phase, the regression tree is selected as a weak regression model to be trained, and then multiple trained weak regression models are integrated into a strong regression model. Finally, the training results are generated through voting by all the selected regression models. A 2-DOF nonlinear structure was numerically simulated by utilizing the online AdaBoost regression tree algorithm and the BP neural network algorithm as a contrast. The results show that the prediction accuracy of the online AdaBoost regression algorithm is 48.3% higher than that of the BP neural network algorithm, which verifies that the online AdaBoost regression tree algorithm has better generalization ability compared to the BP neural network algorithm. Furthermore, it can effectively eliminate the influence of weight initialization and improve the prediction accuracy of the restoring force in hybrid tests.
Key words:hybrid test; restoring force prediction; generalization ability; AdaBoost regression tree
The hybrid test, first proposed by Hakuno in 1969, is an effective test technique which combines a physical loading experiment and numerical simulation to evaluate seismic responses of large complex civil structures. At present, it has been widely focused on by researchers, and certain research results have been achieved such as a numerical integration algorithm[1-2], real time hybrid test[3], loading control[4], time delay compensation[5], boundary condition[6], remote network collaborative hybrid test[7], and an accurate numerical element[8], etc. The hybrid test has been widely used in the test of large and complex civil structures[9-10]. However, when the hybrid test is conducted on large complex structures, it is impossible to perform a physical loading test on all critical parts. Thus, some key components or parts of the structure are modeled and analyzed in the numerical substructure. Due to model errors, the inaccuracy of the numerical simulation will increase when the entire structure enters nonlinearity. The two main reasons for model errors are: 1) The assumed numerical model is too simple to describe the nonlinear behaviors of the real structure or component; 2) The uncertainty of model parameters. When the proportion of the assumed numerical models with model errors become larger, the accuracy of hybrid tests will be reduced. Therefore, how to improve the model accuracy and restore the force prediction accuracy of the numerical substructure has become an urgent problem.
Model updating is an effective method to improve the accuracy of hybrid tests, which has been widely used in finite element analysis over the past two decades. The theory of model updating can be specified as follows: In the process of hybrid tests, the data of the experimental substructures can be used to recognize and update the numerical model of numerical substructures with similar hysteresis behaviors. Therefore, the model errors of the numerical substructure are reduced, and the ability to predict the structural actual behaviors is improved.
1 Principle of Model Updating in Hybrid Tests


Fig.1 Procedure of model updating hybrid test
Among all the parameter identification methods, the initial selected numerical model is usually simplified from the experimental results, which means that the limited number of parameters cannot fully describe the real nonlinear behaviors. In other words, the model gap between the simplified model and the real model exists from the early beginning of the hybrid tests. In contrast, the intelligent algorithms can acquire more hysteresis information that does not exist in the initial assumed numerical model, and can directly fit the constitutive model of the numerical substructure. Therefore, the intelligent algorithms address the shortcomings of the parameter identification methods. However, in intelligent algorithms, the BP neural network has a poor generalization ability and it is relatively sensitive to initial weight, which will influence the accuracy of the constitutive model.
In order to solve the problem of poor generalization ability and sensitivity to the initial weight of the BP neural network, an online AdaBoost regression tree algorithm is proposed and adopted. First, some weak regressors are selected for training; then the multiple weak regressors are integrated into a strong regressor; and finally the training results are generated. In order to verify the effectiveness of the proposed model updating method, a numerical simulation of a 2-DOF nonlinear structure is carried out, and the results are compared with the BP neural network algorithm.
2 Principle of Regression Tree Algorithm
The regression tree is a type of decision tree for regression. A decision tree is a tree-like model defined in the feature space, as shown in Fig.2. The regression tree algorithm proposed by Breiman et al.[17]mainly includes two steps: regression tree generation and regression tree pruning.

Fig.2 The regression tree model diagram
2.1 Regression tree generation
The regression tree model consists of nodes and directed edges as shown in Fig.2. The nodes include internal nodes and leaf nodes. The circles and boxes in Fig.2 represent internal nodes and leaf nodes, respectively. The internal nodes represent the characteristics or attributes of the samples, and the leaf nodes represent the prediction value of the samples. The least squares algorithm is used to generate the regression tree. The specific process is as follows:
It is supposed thatxandydenote the input and output variables, respectively, and the training data set isD={(x1,y1),(x2,y2),…,(xN,yN)}. The input space is divided intoMregions, namely,R1,R2,…,Rm,…,RMand each regionRmhas a fixed output valuecm. Thus, the regression tree model can be expressed as
(1)

(2)
The heuristic algorithm is used to segment the input space. Thej-th variablex(j)and the corresponding valuesare selected as the split variable and split point, respectively. The next two regions are defined as
R1(j,s)={x|x(j)≤s},R2(j,s)={x|x(j)>s}
(3)
Then, the best split variablex(j)and the split pointsare searched for by solving the minimum value:
(4)
The best split points inR1(j,s) andR2(j,s) are as follows:
(5)
After all the input variables (j,s) are traversed, the optimal partition variablex(j)is established and the input space is divided into two regions one by one. Next, the above segmentation process is repeated for each region until the stop condition is reached. Thus, a regression tree is generated.
2.2 Regression tree pruning
In order to prevent the over fitting of the above-mentioned regression tree model, it is necessary to prune the generated regression tree to ensure its generalization ability. The pruning algorithm performs recursive pruning according to the principle of loss function minimizing, including the following two steps:
From the bottom of the regression treeT0to the top, pruning is continued until the procedure reaches the root nodes. Then, a pruned subtree sequence {T0,T1,…,Tn} is formed and the loss function of the subtrees during pruning is calculated as follows:
Cα(T)=C(T)+α|T|
(6)
whereTis an arbitrary subtree;C(T) is the prediction error of the training data; |T| is the number of leaf nodes in a subtree; and the parameterα(α≥0) measures the fitting degree of the training samples and the complexity of the model.Cα(T) indicates the entire loss of the subtreeTwhen the parameter isα. The pruning process is repeated till the root node.
Based on the validation data set, the cross validation method is used to test the subtree sequence obtained from the above process. Also, the optimal subtreeTαis obtained based on the independent verification data set. The decision tree with the smallest square error in the subtree sequence {T0,T1,…,Tn} is selected as the optimal one. The pruning diagram of the regression tree is illustrated in Fig.3

Fig.3 The regression tree pruning diagram
3 Implementation of online AdaBoost regression tree algorithm
For the constitutive model recognition of the nonlinear components, large generalization errors cannot be avoided when only one neural network model is adopted for training. The training results of multiple neural network models are more accurate than those of the single neural network model, which is called the boosting method. The representative boosting method is the AdaBoost algorithm proposed by Freund and Schapire[18]in 1995. Firstly, the regression tree is selected for training and the weight of each training sample is adjusted in each round of training. Then, these regression tree models are integrated linearly to vote out the final results. The diagram of the Adaboost regression tree algorithm is shown in Fig.4.
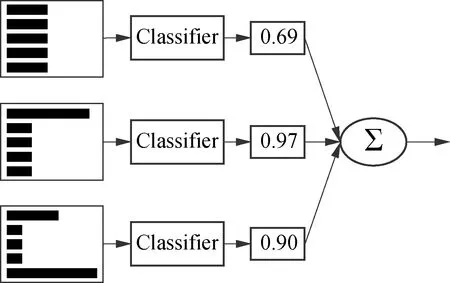
Fig.4 The diagram of Adaboost regression tree algorithm
In hybrid tests, the samples of the experimental substructure in the current step are input into the Adaboost regression tree model for training, and a strong regressor is obtained. Then, after inputting the displacement of the numerical substructure in the current step into the trained strong regressor, the corresponding restoring force can be directly predicted. The procedure based on the proposed method is illustrated in Fig.5.
3.1 Collecting training samples


Fig.5 Procedure based on the proposed method in hybrid test
3.2 Weight initialization of training samples
In the first loading step, the initial weight of training samples is set to be
(7)
In thei-th step, the initial weight vector of the training samples is set to be the weight vector trained afterMiterations in the (i-1)-th step:
(8)

3.3 Training AdaBoost regression tree model

The updating criterion of the training sample weight is: If the regression error of a certain sample point is small, the weight of this sample will be reduced in the next iteration; on the contrary, if the regression error of a certain sample point is large, the weight of this sample will be increased in the next iteration. Following the learning rule of the AdaBoost regression tree algorithm, the weight of unpredictable samples is increased and the prediction accuracy of the restoring force is finally improved. The training process mainly includes the following steps.

(9)
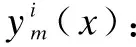
(10)

3) The weight of the training samples is updated in each iteration. The update rules are
(11)
(12)
(13)
3.4 Combining regression tree models
TheMregression tree models are linearly integrated into a strong regressorYi(x) in thei-th step:
(14)
The diagram of integrating regression tree models is shown in Fig.6.
3.5 Prediction of restoring force in hybrid tests
The restoring force of the numerical substructure in thei-th step can be predicted by inputting the displacement into the integrated regressor obtained above. Then, the restoring force of the experimental substructure and numerical substructure are fed back to the equation of motion. The five steps are repeated until the ground motion input is completed.

Fig.6 The diagram of integrating regression tree models
4 Numerical Validation
4.1 Model description
The online AdaBoost regression tree algorithm is evaluated on a 2-DOF nonlinear structure as shown in Fig.7. It is assumed that there are no complex incomplete boundaries and no obvious different loading histories.

Fig.7 A 2-DOF nonlinear structure model
The masses of the experimental substructure and numerical substructure areM1=M2=2 500 t; the initial stiffnesses areK1=K2=394 785 kN/m; and the damping coefficients areC1=C2=5 026.5 kN/(m·s-1). The ground motion recorded at the SimiValley-Katherine Rd station on January 17, 1994 at the Northridge earthquake is selected for numerical simulation. The peak seismic acceleration is adjusted to 200 cm/s2. The Runge-Kutta method is applied as the numerical integration scheme and the sample time is set to be 0.01 s. In this numerical study, it is assumed that the real constitutive models of the experimental substructure and numerical substructure are both the Bouc-Wen model, that is
(15)
whereFis the restoring force of the structure;αis the second stiffness coefficient;Kis the initial stiffness of the structure;Zis the hysteretic displacement; andβ,γ,nare the model parameters that control the shape of the hysteresis curve. The real model parameters of the experimental substructure and numerical substructure in this numerical study are both set to be as follows:K=394 785 kN/m,α=0.01,A=1,β=100,γ=40,n=1.
The input variables of the nonlinear hysteresis model are set to be 6 variables as follows:di,di-1,Fi-1,Fi-1di-1,Fi-1ΔdiandEi-1.diis the relative displacement of the structure in thei-th step; Δdi=di-di-1;Fi-1is the restoring force of the structure in thei-th step;Fi-1di-1is the energy consumption of the structure in the (i-1)-th step;Fi-1Δdiis the energy consumption of structure in thei-th step;Ei-1[19]is the cumulative energy consumption of the structure in the (i-1)-th step,Ei-1=Ei-2+|Fi-1di-1|.
4.2 Results analysis
In order to verify the effectiveness of the proposed method, three types of hybrid tests are analyzed and compared in this numerical simulation, as shown in Figs.8 and 9. The reference in the figures represents the true hybrid test; the BP algorithm in the figures represents the model updating hybrid test based on the BP neural network algorithm; the AdaBoot algorithm in the figures represents the hybrid test of model updating based on the AdaBoot regression tree algorithm.

Fig.8 Comparison of the restoring force prediction of the numerical substructure with online AdaBoost regression tree and BP neural network algorithm

Fig.9 Comparison of the restoring force prediction error of the numerical substructure with an online AdaBoost regression tree and BP neural network algorithm
Fig.8 and Fig.9 show the comparison of restoring force prediction error and restoring force prediction error of the numerical substructure in three simulation cases, respectively. It can be seen from Fig.8 that the restoring force of the numerical substructure predicted by the AdaBoost regression tree algorithm is in good agreement with the real value, while the restoring force predicted by the BP algorithm has a large error at the turning point.
Fig.9 shows that the maximum absolute error of the predicted restoring force based on the BP neural network algorithm is larger than that of the AdaBoost regression tree algorithm on the whole. The AdaBoost regression tree algorithm gradually adapts to the new data through online training and reduces the prediction error of the restoring force over time.
In order to quantify the prediction error of the restoring force, the dimensionless error index is utilized in this study. The root mean deviation (RMSD) is
(16)
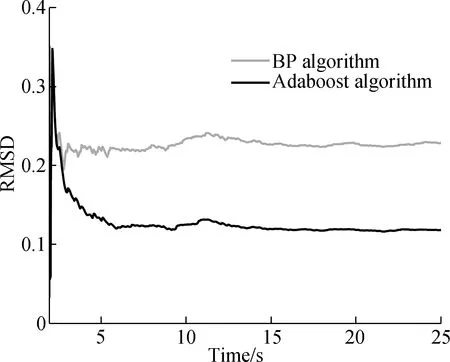
Fig.10 Comparison of the RMSD with the online AdaBoost regression tree and BP neural network algorithm
It can be seen from Fig.10 that in the initial stage of hybrid tests, the prediction errors of the BP neural network algorithm and AdaBoost regression tree algorithm are relatively large. However, as time goes on, the prediction errors of the restoring force in both cases gradually decrease and tend to stabilize.
In the stable stage, the RMSD of the online AdaBoost regression tree algorithm is 0.117 9, and that of the BP neural network algorithm is 0.228 2. The prediction accuracy of the online AdaBoost regression algorithm is 48.3% higher than that of the BP neural network algorithm. In addition, the average one-step time of the proposed method is 0.12 s, which meets the requirements of slow hybrid tests. Therefore, the method proposed in this paper can significantly improve the model accuracy in hybrid tests, and has reference value for the application of intelligent algorithms to the hybrid test of model updating.
5 Conclusion
1) The numerical analysis of a 2-DOF nonlinear structure is conducted to verify the effectiveness of the proposed method.
2) Compared with the online BP neural network algorithm, the absolute error of the restoring force prediction is reduced by 72.5% and the relative root mean square error is reduced by 48.3% when the online AdaBoost regression tree algorithm is adopted, which verifies the effectiveness of the proposed method.
3) The generalization ability of the recognition system is improved. The research results are significant for the application of intelligent algorithms to improve the model accuracy in a hybrid test.
杂志排行

Journal of Southeast University(English Edition)的其它文章
- Influence evaluation of titania nanotube surface morphology on the performance of bioelectrochemical systems
- Size-dependent behaviors of viscoelastic axially functionally graded Timoshenko micro-beam considering Poisson effects
- Arterial traffic signal coordination modelconsidering buses and social vehicles
- A customized extended warranty policy with heterogeneous usage rate and purchasing date
- Diagonal crossed product of multiplier Hopf algebras
- Online SOC estimation based on modified covariance extended Kalman filter for lithium batteries of electric vehicles