考虑时间序列关联的大坝监测异常数据清洗
2020-07-16郑霞忠陈国梁
郑霞忠,陈国梁,邹 韬
(三峡大学水利与环境学院,湖北 宜昌 443002 )
0 引 言
通过分析大坝安全监测数据,评估大坝安全性态,是减少大坝运行风险的重要手段。在监测数据采集过程中,受人为因素、作用环境以及仪器故障等影响,监测数据中不可避免地存在数据异常问题,其中异常数据中粗差的识别与剔除关系到后期大坝安全评估的可靠性。
目前,消减大坝监测数据异常值的方法主要从两条途径展开:一是基于假设检验辨识异常数值。该类方法假设监测数据中存在异常值,通过均值漂移模型重构监测数据,并计算其与历史数据间的粗差估计,但受异常值位置的不确定性和最小二乘法的均摊效应影响,数据的整体质量无法保证[1-2]。二是抗差估计,通过构造估值方法控制监测数据与估计值的偏离程度。但该方法普遍存在时效性较差和算法复杂等缺点,不适用于识别由时效性引起的大坝安全监测异常数据[3- 4];并且传统异常数据清洗方法均是针对单一数据类型,分析数据中的异常值,且过度依赖单一数据变化过程中的突变平滑关系[5],难以甄别异常值是由环境突变还是粗差引起,而由环境突变引起的异常数据是大坝工作状态的真实反映,不需要进行剔除[6-7]。
考虑到在大坝安全监测过程中,大坝监测的效应量(变形、应力、渗流等)与致因因子(水位、坝体温度等)间常存在明显关联性[8],可利用这些关联性约束,提高大坝安全监测数据中异常值清洗的准确性。为此,本文提出了一种考虑监测序列间关联性的数据清洗方法,即通过Apriori算法分析监测序列间的关联性,筛选强关联性监测序列,结合DBSCAN算法识别异常数据,根据清洗规则分析辨识异常数据中的粗差,利用粒子群算法(PSO)优化最小二乘支持向量机(LSSVM)数据拟合过程,重构异常数据,从而实现对异常数据的准确清洗。
1 基于关联规则的监测序列关联性分析
1.1 关联规则原理
关联规则(Association Rules)是数据挖掘技术中常用的算法,主要用于分析数据间的关联性。根据关联规则的相关定义[9-10],罗列其中重要概念如下:
(1)事务数据库。即子集事务的集合,记作C,事务数据库中子集事务总数记作|C|。
(2)关联规则。若项集存在A⊂C,B⊂C,且A∩B≠∅的关系,则表明A→B存在关联信息,A、B项集为关联规则中的先导和后继。
(3)支持度。关联规则A→B中A∪B项集组合在事务数据库C中同时出现的概率,记作Psupport(A→B)。ncount(A∪B)为A∪B在事务数据库C中出现的个数,其数学表达式为
(1)
(4)频繁项集。若关联规则的支持度满足最小支持度要求,则该关联规则中的项集为频繁项集。
(5)置信度。在包含项集的子集事务中,同时出现项集B的概率,即项集A发生条件下,项集B的条件概率,其数学表达式为
(2)
(6)序列关联度和置信度。为分析监测序列间的关联性,基于关联规则的分析原理,本文定义监测序列关联度和置信度数学表达式。对于监测序列A和B,若它们之间蕴含有关联规则,且其中存在n条关联规则Xi→Yi满足最小支持度要求,则关联度和置信度表达式分别为
(3)
(4)
监测序列关联性分析过程中,关联度越高,则表明序列间关联性越强;为分析序列关联性的可信度,引入置信度概念衡量关联规则可信程度,监测序列的置信度趋近1,表明关联规则具有较高的可信度。若监测序列的关联规则中的支持度和置信度均满足最小阈值0.5的参数要求,则称该组序列为强关联性序列;否则认为序列间关联性较弱或不存在关联。
1.2 监测序列符号化及关联分析流程
为满足关联分析中Apriori算法运算要求,需要对监测序列进行符号化处理。首先,使用滑动窗口L对原始监测序列截取子序列;然后,对子序列进行线性拟合,并对线性方程的斜率值进行标准化处理,使其均处于[-1,1]区间内;最后,依据符号转换规则,对子序列进行符号化处理,符号转换规则如表1所示。
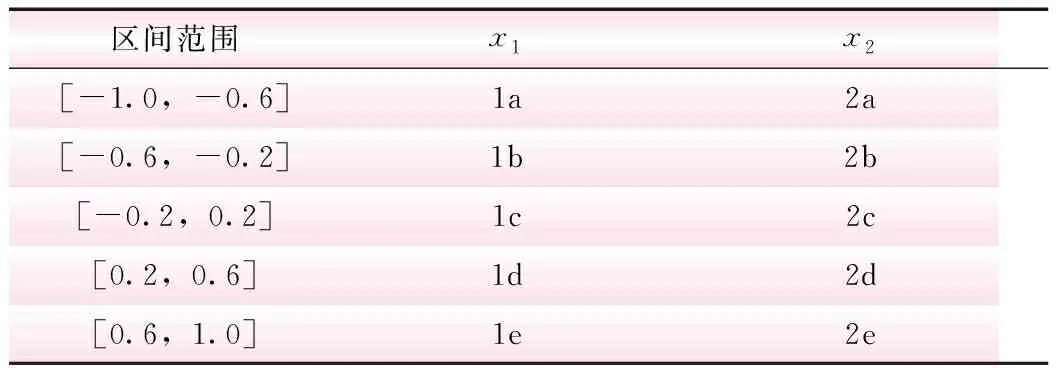
表1 序列符号化表示
符号化处理后的监测序列运用Apriori算法计算其支持度和置信度,根据参数阈值要求,筛选频繁项集并计算序列关联度与置信度,最终输出强关联性的监测序列。监测序列关联性分析流程如下:①根据滑动窗口长度截取子序列,并进行符号化处理。②利用Apriori算法选取关联规则中的频繁项集。③利用式(3)、(4)计算序列间的关联度及置信度,输出强关联性的监测序列。
1.3 监测序列关联性分析实例
选取某拱坝15号坝段垂线监测径向位移和上游水位过程线的历史数据,数据采集从2013年5月4日开始至2018年6月10日截止,图1为原始监测数据图像;数据样本长度为Ldata=890,设置滑动窗口L=10,得到89个子序列;根据符号转换规则对序列进行符号化处理,利用Apriori算法进行关联性计算,结果见表2。
由表2可知,15号坝段垂线测点的径向位移监测序列和上游水位序列间关联度和置信度均满足最小阈值0.5的要求,径向位移监测序列和上游水位序列间存在强关联性,与图1中序列监测直观结果一致,在后续监测异常数据处理中可结合序列间的关联性进一步分析。
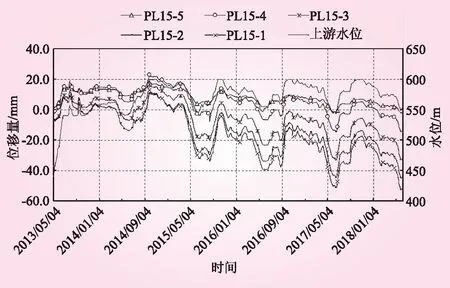
图1 上游水位和15号坝段径向位移过程线
表2 上游水位和15号坝段径向位移关联性结果
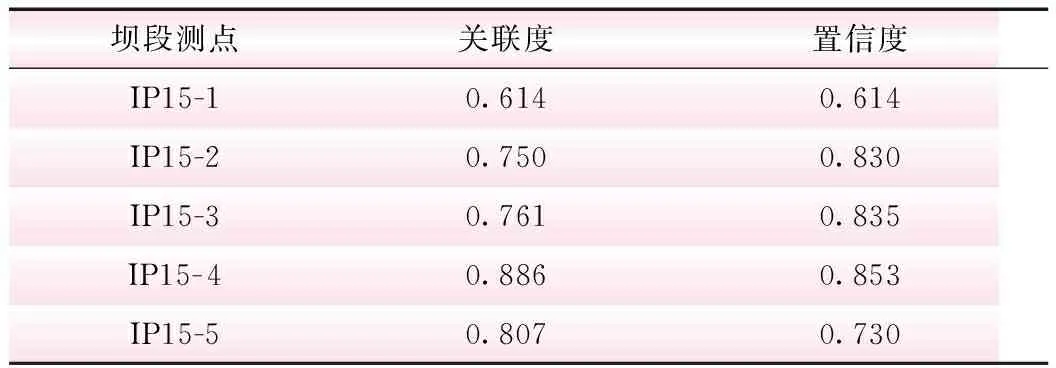
坝段测点关联度置信度IP15-10.6140.614IP15-20.7500.830IP15-30.7610.835IP15-40.8860.853IP15-50.8070.730
2 大坝监测数据异常检测和数据清洗
2.1 数据异常值检测
监测过程中的异常数据与正常数据间存在一定的相异程度,在空间中表现为不同形状的簇群。为剔除大坝安全监测数据中的异常数据,使用基于密度聚类的DBSCAN算法识别序列中异常数据。该算法在数据聚类过程中具有良好的抗噪性能,能够在多维空间数据中克服噪声影响,并识别出任意形状的相似簇群[11]。DBSCAN算法检测时间序列的异常值流程如下:①在数据库中随机选取一数据点;②检查数据点是否为核心对象,若是以该点为核心,形成簇群;③否则标记该点为噪声点,重新寻找(跳转步骤1)。
2.2 大坝监测序列数据清洗流程及规则
数据清洗是对序列中的异常值点进行剔除和重构,根据产生异常点的原因,异常点可以归纳为传感数据异常和大坝状态异常两类。传感数据异常指在数据在采集、传输过程出现误差,导致数据异常,该类异常数据属于数据监测过程的粗差,必须对其进行剔除和重构,以实现数据清洗目的;大坝状态异常指的是环境突变等原因使得大坝工作状态出现异常,在监测数据中表现为监测效应量出现突变或极值,该类异常点数据反映了大坝的异常工作性态,数据清洗过程中需将其识别出来,并对大坝安全性态进行分析。
大坝监测数据清洗流程及规则如下:
(1)使用Apriori算法分析大坝监测效应量间的关联规则及关联程度。
(2)对弱关联性的效应量利用DBSCAN算法识别异常点,跳转步骤4对异常数据进行重构。
(3)对蕴含强关联规则的监测序列,利用DBSCAN算法进行异常数据识别,并对比分析两组关联序列中异常数据出现时刻。若检测结果中异常数据位于两组序列的相同时刻,则认为该点异常为环境变量引起与其相关联的大坝监测效应量的变化,属于大坝状态异常数据类型;当异常点单独出现在个别序列的某一时刻,该类异常数据属于传感异常。考虑到当数据异常波动较小时,序列异常数据检测过程中DBSCAN算法中可能会出现遗漏,利用PSO-LSSVM模型预测强关联序列中的另一组序列数据,分析关联序列中是否出现异常数据检测的遗漏项。若预测结果与采样原数据间存在较大偏差,表明原始监测数据在采集过程出现误差,该数据点为异常数据识别的遗漏项,根据关联序列中同时出现异常数据的判别规则,认为该异常点属于大坝状态异常数据;若预测偏差较小,表明相关联的一组序列并未出现异常数据检测的遗漏项,异常数据单独出现在序列中,最终甄别该异常点为传感数据异常,需要对该数据进行清洗。
(4)利用PSO-LSSVM模型对序列进行预测,重构异常数据。
2.3 基于PSO-LSSVM的数据异常值清洗
考虑到最小二乘支持向量机(LSSVM)在拟合非线性、大体量数据的优势[12-13],本文采用LSSVM模型对大坝监测序列进行拟合,重构异常数据,实现数据的清洗。同时,为保证LSSVM模型和核函数中参数设置的客观性,利用粒子群算法优化参数计算。LSSVM模型中参数计算的目标函数为
(5)
式中,ω为权向量;θ为误差向量;γ为惩罚因子,且γ>0。
考虑径向基核函数常被用于处理非线性映射关系,将其作为LSSVM的核函数。
(6)
式中,ωi为Lagrango乘子;xi、xj为任意两个样本。
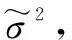
3 案例分析
3.1 无关联监测序列清洗案例分析
对15号坝段垂线测点PL15-3的切向位移监测数据与上游水位数据进行关联性分析,发现两者间关联程度较低,不存在强关联规则。以15号坝段垂线测点PL15-3的切向位移监测数据为例,进行无关联性序列异常数据清洗。该测点切向位移监测序列区间为2013年5月4日~2018年1月4日,样本长度为813。为验证本文模型的有效性,对原始数据人为加入异常,分别在第70~80数据点间添加高斯白噪声,第340个数据点加入异常,第400个数据点剔除数据,异常化处理后序列见图2。
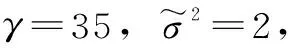
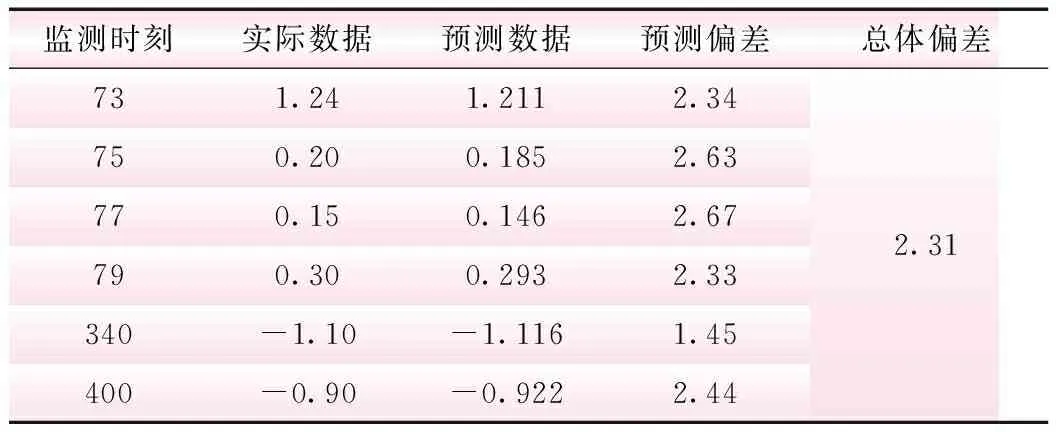
表3 异常点清洗结果
为验证本文数据预测模型的准确性,针对第77个数据点,选取传统BP神经网络模型、小波神经网络模型及支持向量机模型进行预测比较,其预测结果偏差分别为2.85%、3.58%、2.98%,均大于本文模型预测偏差,验证了本文所提出模型的准确度。
3.2 强关联性监测序列清洗案例分析
1.3节中序列关联性分析实例中已论证了15号坝段PL15- 4测点垂向位移监测数据与上游水位序列间存在强关联性,在本节中以这两组监测序列为案例,进行强关联序列间的数据清洗。利用DBSCAN算法识别两组监测序列间的数据异常点和缺失点,若待清洗数据点为传感数据异常,则利用基于PSO-LSSVM模型进行数据重构。
(1)两组关联序列数据采集时间段均为2013年5月4日~2018年6月10日,采集间隔时均为2 d采集一次。利用算法同时对两组序列进行异常数据检测,发现在第76、107、411、512、536、619、744、887个数据点处两组监测序列同一时刻均出现异常数据。已知测点PL15- 4垂向位移监测数据与上游水位序列间存在强关联性,若在同一时刻出现异常数据,根据清洗规则,认为该类数据是由环境发生较大变化时所引起大坝状态变化,为大坝状态异常数据。该类异常数据为大坝工作性态的真实反映,不需要进行清洗,必要时可发出监测预警。
(2)第二类异常点为单独出现在测点PL15- 4垂向位移监测序列中的异常数据点。对第二类异常数据点进一步区分,判断相关联的序列在同一时刻的数据是否为异常数据遗漏项。根据关联数据清洗流程,对关联序列中的另一组数据上游水位进行预测,计算预测偏差。上游水位在第66、368、482数据点预测偏差分别为10.87%、3.94%、1.37%。第368、482数据点的预测偏差较小,表明上游原始监测数据正常,非异常数据检测的遗漏项,从而判断测点PL15- 4垂向位移监测序列在第368、482数据点的异常数据为传感器异常,需要对其进行数据清洗;上游水位在第66个数据点预测偏差为10.87%,大于10%的误差阈值,说明DBSCAN算法异常数据检测过程中将其遗漏,该点数据应为上游水位传感器异常数据。根据关联序列异常数据判断条件可知,认为测点PL15- 4垂向位移监测序列在第66个数据点为大坝异常数据,不需要进行数据清洗,应对该点大坝工作状态进行进一步分析。
4 结 论
本文提出考虑监测效应量间关联性的异常数据清洗方法,并结合大坝典型位移监测数据进行了实例分析,得到如下结论:
(1)考虑监测异常数据中可能包含外界环境引起监测效性量突变,结合异常数据成因,细分异常数据类型,过滤不需清洗大坝状态异常数据。
(2)引入PSO计算LSSVM模型及核函数中相关参数,克服参数设置的主观性,与常用序列预测方法比较,PSO-LSSVM模型能进一步提高数据拟合精度。
(3)利用大坝安全监测数据间的关联性特点,将关联规则结果运用到异常数据分析过程中,并结合PSO-LSSVM模型,提高了数据清洗的准确性。
