视频行人重识别研究进展
2020-07-16李梦静吉根林
李梦静,吉根林
(南京师范大学 计算机科学与技术学院,江苏 南京 210023)
视频行人重识别(又叫行人再识别)是指在不同摄像头拍摄的行人视频中检索特定行人的技术,即给定一个行人视频,跨摄像头检索该行人,得到其在其它摄像头下的视频. 这种针对特定人的视频检索具有重要的研究意义,在失踪者定位、犯罪跟踪和行人视频检索等方面有着广泛的应用.
行人重识别问题的研究最早可以追溯到跨摄像头多目标跟踪问题上,2005年,文献[1]提出了当目标行人在某个摄像头视频丢失之后,如何将其在其它摄像头视频中再次匹配的问题. 2006年,文献[2]第一次提出了行人重识别的概念,将其从跨摄像头多目标跟踪问题中抽离出来,作为一个独立的问题进行研究. 早期的行人重识别研究使用传统方法,例如提取手工设计的特征. 2014年以后,深度学习得到了迅猛发展,学者们试图将深度学习技术应用在了行人重识别领域,获得了更好的效果.
根据输入数据的不同,行人重识别可以分为图像行人重识别和视频行人重识别,这两者既有相同点也有不同点,相同点是它们都面临着摄像头本身的低分辨率、拍摄场景的多样性、物体遮挡、光照变化等等问题带来的挑战. 不同点是相比于图像,视频数据中蕴含的信息更多,视频中包含了行人的运动信息和时间信息,数据量更多、计算量更大,更复杂,且视频数据存在高度冗余,如何提取具有鉴别力的部分也更值得研究. 与图像行人重识别相比,视频行人重识别的研究工作较少,但是视频行人重识别更接近真实应用,自2016年以后,越来越多的学者开始关注视频行人重识别问题,提出了各种不同的解决方法.
1 视频行人重识别的处理过程
一般来说,视频行人重识别问题处理过程主要分为3个阶段:(1)视频数据预处理:将视频按帧切分成图像序列,利用行人检测技术得到行人检测框,并处理图像噪声、光照变化等问题;(2)特征提取:提取描述行人外观的有区别的、稳定的特征;(3)距离度量:找到更有效的行人相似性度量方法,建立一个新的特征空间,使相同行人的特征距离更小,不同行人的特征距离更大.
视频行人重识别传统处理过程如图1所示. 训练视频首先经过预处理,再进行特征提取和距离度量,最后通过损失函数反馈训练,不断迭代,直到获得较好的特征学习模型. 在检索过程中,检索视频和多个候选视频分别进行预处理,然后输入到已训练完成的特征提取模型中,得到每个视频的特征,再利用合适的距离度量方法计算检索视频与每个候选视频之间的距离. 最后按照距离的大小,输出所有候选视频的排序结果.
2 特征提取方法
特征提取方法主要分为基于手工设计的特征提取和基于深度学习的特征提取. 如表1所示,基于手工设计的特征主要有颜色特征[3-4]、光流特征和属性特征[5],其中前两者属于视觉特征,容易被周围环境干扰,而属性特征属于中层语义特征,更具有鲁棒性. 随着深度学习的发展,2016年以后使用深度学习模型提取特征成为主流.

表1 行人特征分类Table 1 Pedestrian feature classification
基于深度学习的特征主要有:(1)时空特征,视频中含有丰富的时空信息. 空间信息指图像的每一帧不同位置具有的特征,时间信息指视频不同帧之间的联系,空间信息与时间信息是互补的. 如果缺少信息的任何一部分,行人的信息就不能得到充分的表达. (2)局部特征,早期特征提取模型都是一幅图像提取一个特征,不考虑一些局部信息,随着行人重识别数据集越来越复杂,全局特征并不能得到很好的效果,提取更加复杂的局部特征成为一个新的解决方法. 详细的特征提取方法特点及应用整理如表2所示.
2.1 时空特征提取
提取时空特征的方法可以分为3类:(1)额外给CNN(Convolutional Neural Network)输入光流等动态光流特征[6-8];(2)先提取帧级空间特征,再将所有帧特征输入到循环神经网络中提取时间特征[9-11]或是利用时间汇聚或者权重学习得到时间特征[12-14];(3)将视频看作三维数据,通过3D CNN等方法提取时空特征[15-16].
2017年,Zhou等[13]利用CNN网络提取每帧图像的空间特征,然后提出了一种时态注意模型TAM(Temporal Attention Model)来提取时间特征. 2019年,Chen等[10]提出了一种联合关注时空特征聚合网络(Joint Attentive spatial-temporal Feature aggregation Network,JAFN),同时学习质量感知模型和框架感知模型,利用CNN学习空间特征,同时引入LSTM(Long-Short Time Memory)学习时间特征.
上面两种方法都是先提取帧级空间特征,再利用LSTM网络或者注意力机制生成视频级的时间特征,都是直接在高层特征上建立时间连接,因此无法捕获图像局部细节上的时间信息. 为了解决这个问题,Li等[15]受3D卷积神经网络在动作识别领域得到的成功所启发,提出了双流M3D(Multi-Scale 3D)卷积神经网络将多个多尺度三维卷积层插入到二维CNN网络中,同时提取时间和空间信息.
2.2 局部特征提取
局部特征是特征提取模型自动关注视频的某些局部区域. 相比于全局特征,局部特征对光照变化的鲁棒性更强,且能减弱遮挡的影响. 提取局部特征的主要方法有:(1)人工将图像划分成块,根据人体固有的特点,将图像划分成头、上身、下身几个部分;(2)提取人体骨架关键点,利用注意力机制关注局部身体部位处的特征;(3)构建人体部位特征邻接图,对不同部位特征之间的关系进行建模.
Liu等[17]提出一种新的时空特征混合模型,首先将人体水平分割成N个部分,包括头部、腰部、腿部等信息. 然后整合每个部分的特征,以实现对每个人更有鉴别力的表达. 2019年,文献[18]认为行人身份信息主要表现在躯干、肘部、手腕、膝盖、脚踝等身体部位. 首先检测人体关键点,然后获取行人图像中人体关节的重要系数矩阵,根据系数矩阵通过注意力机制整合CNN得到的图像外观特征.
这两种方法忽略了人体各部位之间的相关性,而人的各个部位之间的关系有助于降低复杂情况(如遮挡、不对齐和杂乱背景)的影响. 为了利用各部位之间的关系,Wu等[19]提出了一种新颖的自适应图表示学习方案,首先利用位姿对齐连接和特征关联连接来构造一个自适应结构感知邻接图,利用该邻接图对图节点间的内在关系进行建模. 自适应地捕获行人身体部位特征之间的内在关联结构信息,并进一步传递互补的上下文信息,丰富行人外观特征表示.
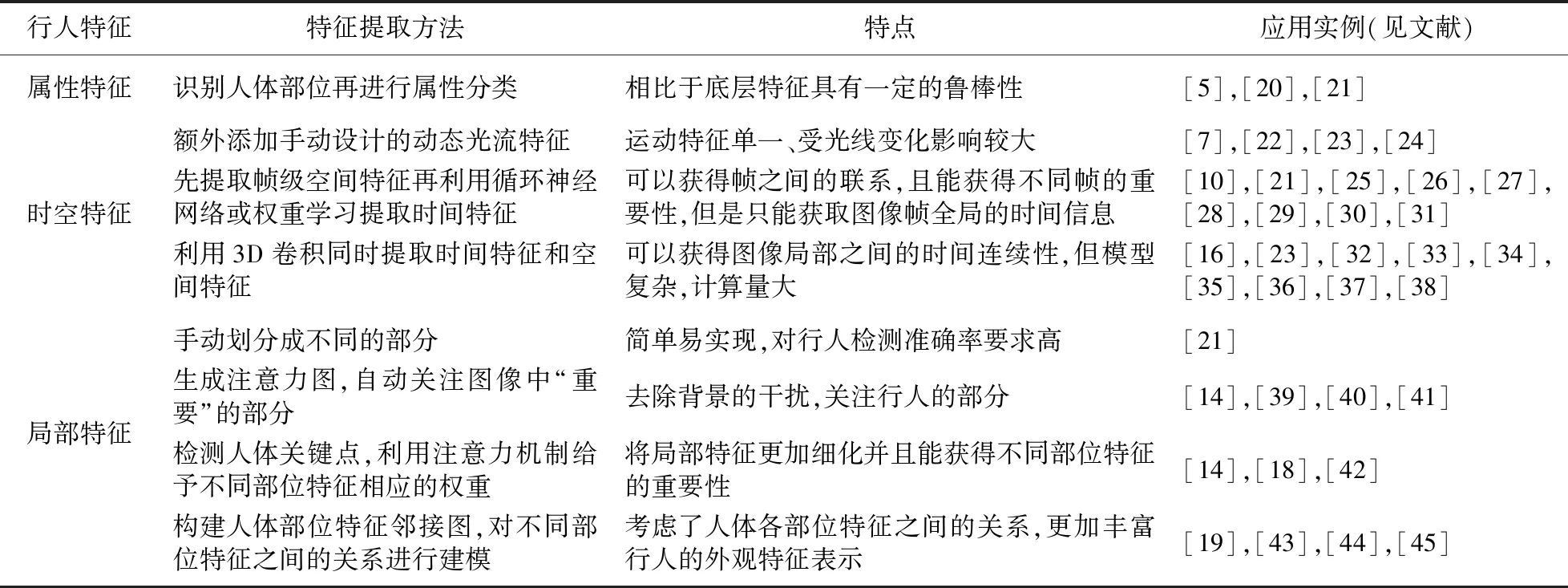
表2 特征提取方法特点及应用Table 2 Characteristics and application of feature extraction methods
2.3 特征融合
特征融合分为两类:(1)多特征融合:对同一个视频提取多种特征,例如颜色、光流、时空等等,然后将多种特征融合作为最终行人特征;(2)多帧融合:视频本质上属于图像序列,常规方法是对每一帧提取一个特征,再将多帧的特征融合,得到视频级特征.
多特征融合:早期的特征提取采用低级特征,2016年,文献[7]利用颜色和光流信息来捕获图像和运动信息,Zheng等[46]将颜色直方图与SURF(Speeded Up Robust Feature)特征相结合提取特征,但随着深度学习在计算机视觉领域取得巨大成功,研究者们开始使用深度学习来学习更具鉴别力的特征. 将手工特征与深度学习得到的特征相融合,2017年,Li等[47]将手工设计的局部特征与PCN(PCA-based Convolutional Network)生成的深度特征进行融合. 2018年,Sun等[22]利用孪生神经网络学习深度特征,将光流特征与深度特征进行融合作为行人特征描述符.
多帧融合:从帧级特征到视频级特征,必然的方法就是进行多帧特征融合,最简单的方法是将所有帧的重要性视为相同,将所有帧级特征进行平均池化得到视频级特征,但是显然因为光照、遮挡等因素的影响,不同的帧等提供的有用信息是不一样的. 基于这样一个事实,文献[48]提出一种时域注意方法,其中采用一个全卷积的时间注意模型来生成注意力分数,它代表每一帧的重要性. Ouyang等[49]利用深度强化学习剔除质量差、误导和混淆的帧,从视频中挑选出具有代表性的帧,再进行多帧融合. 文献[50]提出的视频协方差方法还研究了视频帧之间的相关性,利用相关性对多帧特征进行整合,提升了特征表示的鉴别力.
3 距离度量方法
距离度量阶段的任务是定义一个距离度量函数计算两个特征向量之间的距离,通过最小化网络的度量损失,得到一个最优的特征空间,使得相同行人的视频之间的距离尽可能小,不同行人视频之间的距离尽可能大. 传统的距离度量学习方法有LMNN[51]、KISSME[52]、XQDA[53]、LFDA[54].
行人视频是由不同相机拍摄的,光照变化、视角变化都会使视频间产生较大的差异,可以观察到:(1)同一个人的不同视频之间存在严重差异;(2)每个视频内的不同帧或步行周期之间也存在较大差异. 两种差异都会对行人视频之间的匹配带来不利影响. 2018年,Zhu等[55]提出了一种同步的视频内和视频间的距离度量学习方法SI2DL. 如图2所示,该方法首先将单个视频内距离拉近,然后拉近类内距离,同时推远类间距离,从而使得不同行人的视频分开.
相似地,为了减少视频内特征的差异,2019年,Zhang等[56]引入“均值-体”的概念,定义一个视频内的损失,以解决同一视频时空特征之间的变化,然后结合视频内损失和孪生损失来提高训练速度.
在实际应用时,视频数据是一个流式数据,图像帧是不断加入原有的数据中的,这就要求损失函数不仅能够计算最终特征向量之间的距离,还要在新的数据加入时,对原有距离进行更新. 2019年,Navaneet等[57]提出了排名损失. 它可以在新数据加入时,确保距离度量的质量在不断改善,并防止由于质量差的帧加入而导致的退化.
4 视频行人重识别研究面临的挑战
虽然近几年视频行人重识别取得了重大的发展,但是还是面临着许多挑战,在真实场景下,行人重识别问题会遇到跨摄像头导致的姿态变化、遮挡、光照变化等问题.
4.1 行人不对齐且姿态变化
行人重识别数据集中普遍存在的一个关键问题就是图像对之间的不对齐,如图3所示,由于背景杂波和位置不对齐,直接比较未对齐的图像对效果非常差. 另一个问题就是姿态的变化,如图4所示,人体的姿态总是根据相机的不同视角、行走路径、行为等发生变化,这个问题显著降低模型的性能.
针对这两个问题,近几年,姿态估计对齐方法[58-59]得到了广泛的应用. Chen等[60]针对图像不对齐的问题提出了基于位置引导的空间转换子网络STSN(pose-guided Spatial Transformer Sub-Network). STSN首先对输入图像的各种转换参数进行回归,然后使用仿射变换将图像转换为对齐的图像. 针对姿态变化的问题,提出了一种新的训练策略,称为关键帧选择,它可以选择具有最大转换贡献值的帧作为关键帧,然后用这些关键帧来训练网络,从而减少姿态变化的影响.
上述方法的缺点是需要额外的姿态标注. Wu等[61]提出了一种半监督的方法,将训练好的姿态估计模型直接应用到行人重识别数据集上,避免了在行人重识别数据集上标注姿态的麻烦.
4.2 遮挡问题
现实场景中,行人的任何部分都可能被其他行人或环境物体(如车和指示牌)遮挡,如图5所示,这会导致行人外观的巨大变化.
相比于基于图像的行人重识别,视频行人重识别已经弱化了遮挡的影响,因为一般来说视频中只有一部分图像帧存在遮挡问题. 但这显然不能得到很好的效果. 后来,学者们提出了基于注意力机制的方法,2017年,Zhou等[13]提出通过时间注意模型自动选择出视频中最具鉴别力的帧,对质量好的帧进行特征提取. 同年,Xu等[62]设计了注意力时间池化从图像序列中选择信息帧. 2018年,Li等[14]同样使用时间注意模型从所有帧中提取有用的信息.
虽然这些方法一定程度上解决了部分遮挡的问题,但是丢弃遮挡图像的方法并不理想,一方面,丢弃帧的剩余可见部分可能存在有用的信息;另一方面,丢弃帧中断了视频的时间信息. 针对以上的问题,2019年,Hou等[63]提出时空补全网络STCnet(Spatial-Temporal Completion network),试图恢复被遮挡部分的外观来解决部分遮挡的问题.
4.3 光照变化
突然的光照变化会严重降低行人重识别模型的性能,因为现有的大部分解决方法十分依赖颜色特征,而光照变化会带来图像颜色的巨大变化,如图6所示.
2010年,Farenzena等[64]遵循水平垂直对称原则对人体轮廓进行分割,并从每个分割的身体部位积累局部颜色特征,在对数色度空间中,通过考虑不同光照条件下的颜色分布,建立了基于颜色的不变特征. 2014年,Ma等[65]提出了生物协方差描述符(gBiCov)来处理光照变化,该方法使用了Gabor滤波器来增强模型对光照变化的鲁棒性,然后使用协方差描述符计算相邻尺度下特征的相似性,大部分光照变化带来的影响会被协方差矩阵吸收. 文献[66]使用Retinex算法对图像进行预处理. 通过考虑光照变化和颜色感知来生成一致的彩色图像. 它消除了阴影区域,产生具有增强色彩信息的图像.
处理光照变化的一类方法就是提取对光照变化具有鲁棒性的特征;第二类在正常图像和光照变化图像之间建立一种联系,通过协方差矩阵等方法处理两者之间的不同;第三类就是采用合适的方法对视频进行预处理,使颜色变化平缓.
4.4 跨模态检索
现有大多数行人重识别模型单独关注图像或视频行人重识别问题. 事实上,从图像到视频的行人重识别在失踪者定位、犯罪跟踪和行人视频检索等方面具有重要的意义. 在图像-视频行人重识别任务中,由于图像与视频存在着巨大的跨模态差异,如何融合图像特征与视频特征,以及如何在外观图像特征与时空视频特征之间进行准确的匹配是该问题的关键挑战.
针对融合问题,2018年,文献[67]提出了3种融合方案,包括早期融合,乘积规则融合和自适应查询的后期融合,并分析了3种时期融合的效果. 早期的融合方案将手工特征KDES和深度特征结合起来并反馈到SVM模型中,基于乘积规则融合方案根据乘积计算相似度融合特征,而后期的融合方案则是通过计算特征的得分曲线评估一个特征的有效性,并在融合时分配不同的权重. 实验表明,在3种融合方案中,后两种延迟融合方案效果优于第一种. 2019年,他们在特征提取阶段添加了GOG特征和ResNet学习到的深度学习特征[68],提升了特征的表达能力.
针对匹配问题,2018年,Zhu等[69]通过学习图像与视频间的异构字典将图像和视频特征转化为具有相同维数的编码系数,再利用编码系数进行匹配. Wang等[70]学习了一种图像到视频的距离度量方式来完成两者之间的匹配,此方法在MARS-P2S数据集上Rank-1只有55.25%,还有很大的提升空间,值得进一步研究.
5 实验数据集与评价标准
5.1 实验数据集介绍
为了使研究场景更加接近真实情况,人们采集了若干视频行人重识别数据集,为了解决特定应用场景下的行人重识别问题,学者们也收集了一些针对特定问题的数据集. 数据集信息如表3所示. 最常用的 4个数据集如下,
(1)PRID2011数据集[71]于2011年发表,由两个摄像头拍摄,A相机下有385组行人序列,B相机下有749组行人序列,每个序列长度大约是100到150帧,但是只有200人同时在两个相机下出现过.
(2)iLIDS-VID数据集[72]于2014年发表,拍摄于机场到达大厅. 它由300个随机采样的人的600个图像序列组成,每个人在两个摄像机视图中都有一对图像序列. 每个图像序列的长度可变,从23到192不等,平均数量为73. 该数据集存在严重的遮挡问题,极具挑战性.
(3)Mars数据集[73]于2016年发表,拍摄于清华大学校园,是第一个可以用于深度学习的大型视频行人重识别数据集. 它由6台摄像机拍摄,总共有1261个不同的行人,20715个图像序列,每个行人至少被 2个摄像机捕获.
(4)DuckMTMC-VideoReID数据集拍摄于杜克大学,是多摄像头跟踪数据集DukeMTMC的子集,包括702个用于训练的身份,702个用于测试的身份,以及408个干扰项. 总共有2 196个视频用于训练,2 636个视频用于测试.
除此之外,一些针对特定问题的数据集如下:
(1)EgoReID数据集[74]的视频为可穿戴相机或手机等拍摄的第一人称视角视频,具有自我运动、模糊、视角扭曲等特点. 其中包含900个不同的行人,10 200个视频.
(2)Motion-ReID数据集[75]专门为长期场景中的行人重识别问题收集,拍摄于办公楼,由两个独立的监控摄像头拍摄,一共收集了30个人的240个视频片段,每个行人在两个摄像机下记录的间隔时间较长,至少一周.
(3)HLVID数据集[76]针对监控视频中普遍存在的分辨率低问题收集,拍摄于公共交通道路,由两个摄像头拍摄,总共包含200个不同行人,每个视频长度从56到236不等,平均长度为126. 其中,高分辨率图像分辨率范围从44*120到173*258,平均分辨率为105*203;低分辨率图像分辨率范围从8*19到19*31,平均分辨率为11*21.
(4)CGVID数据集[77]针对现实应用中既存在彩色视频又存在灰度单色视频的问题收集,拍摄于武汉大学,由两个摄像头拍摄,总共包含200个不同行人的52 723幅图像,每个视频长度从58到262不等,平均长度为130.
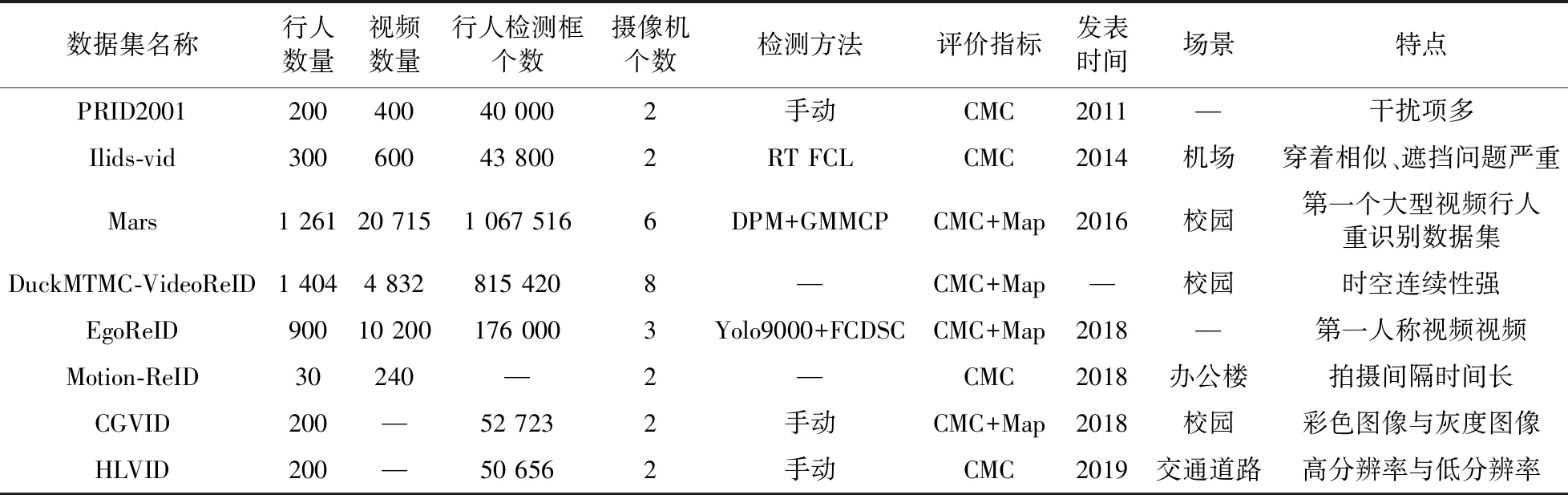
表3 视频行人重识别实验数据集Table 3 Video-based person re-identification data sets
5.2 评价标准
评价行人重识别方法的性能指标主要有两个,一是累计匹配曲线CMC(Cumulative Match Characteristic)曲线;二是mAP(mean Average Precision).
CMC曲线:反映的是top-k的击中概率,主要用来评估排序结果的正确率. 具体含义是指,在候选视频中检索查询视频,前k个结果中包含正确匹配结果的比例. 如图7所示,它表示在所有的查询视频中,30%的查询视频返回的top-1结果是正确的. 计算方式如下:
式中,|P|为查询集的大小,即P={p1,p2,…,p|P|},pi为查询集中的第i个人,一一计算其与候选集gi∈G的距离(G={g1,g2,…,gn}),并进行排序. 正确的目标记为gpi,其在排序中的位置记为r(gpi),I(gpi)为示性函数.
mAP:是每一个查询视频结果与正确结果的匹配程度,与CMC曲线不同的是,它更加重视结果的排序,即正确的结果位置越前越好. 计算公式如下:
式中,AP为平均准确率,实际上就是CMC曲线与坐标轴的面积. 每次查询的结果对应一个AP,mAP是总的查询结果AP的算术平均值.
6 未来研究问题
在实际生活中存在拍摄视频分辨率差距大、彩色视频与灰色视频混杂或者行人更换服饰等现象,现有的大部分视频行人重识别研究大多假定不存在上述现象,在实际应用中有一定的局限性. 为了进一步拓展视频行人重识别技术的应用场景,未来仍有三个问题值得进一步研究.
6.1 尺度失配
在实际生活中,由于某些相机质量差或者行人与摄像头之间的距离太远,通常会导致采集的行人视频为低分辨率视频,从而导致视频中有用信息的丢失,所以在低分辨率和高分辨率的视频之间进行重识别是未来的一个研究问题.
现有的方法十分依赖图像的颜色特征,而且需要先检测行人,所以行人轮廓是非常重要的,但低分辨率图像无法提供高质量的像素,行人轮廓模糊,且行人服装与背景混为一体. 针对这些问题,2017年,Zheng等[78]首先对图像进行预处理,消除图像之间的混色差异,从而使同一个人的色彩特征相等,虽然行人轮廓信息丢失,但人的头部、夹克等某些宽区域的颜色和垂直位置并没有发生明显的变化. 因此将人的图像分成这些大的区域,并从每个区域提取颜色特征.
上述方法解决了处理低分辨率的问题,但是没有考虑低分辨率图像与高分辨率图像之间的匹配问题. 2019年,Ma等[76]提出了一种基于半耦合映射的集对集距离学习方法SMDL(Semi-coupled Mapping based set-to-set Distance Learning),发现高分辨率图像与低分辨率图像之间的映射关系,得到的映射矩阵可以补偿低分辨率图像的损失信息.
6.2 成像风格失配
现实场景中,因为相机故障或者相机为灰色模式会导致采集的行人视频为灰色单色视频,颜色信息会大量丢失,这需要采取有效的方法在彩色和灰度视频之间进行行人重识别,称之为CGVPR 任务(Color to Gray Video Person Re-identification). 为了解决CGVPR 任务,2020年,Ma等[77]认为同一个人的彩色和灰度视频之间存在着内在关系,提出了一种基于非对称视频内投影的半耦合字典对学习方法SDPL(Semi-coupled Dictionary Pair Learning),该方法分别学习一对视频内投影矩阵、一对彩色和灰度视频字典以及半耦合映射矩阵. 学习到的字典对和映射矩阵可以一起弥合真彩色和灰度视频的特征之间的差距.
6.3 长时视频行人重识别
现有的行人重识别方法依赖视频中行人的外观特征,如颜色特征,所以大多假设行人短时间内没有显著的外貌变化,不能解决行人换装的问题. 然而,在许多现实场景中,行人可能在长时间间隔后重新出现在监控视频里,但是衣着不一样. 由于着装的改变,利用行人的外观特征进行视频之间的匹配不再适用. 2018年,Zhang等[75]认为同一个人即使换装,但步态、身体动作等特征不会发生变化,提出一种基于动态线索的精细运动编码模型,从视频中提取行人的动态运动模式,根据运动模式的不同来区别不同的行人,一定程度上解决了这个问题,但还值得更深入的研究.
7 结论
本文探讨了视频行人重识别的处理过程,详细描述了处理过程中最重要的两个阶段:特征提取和距离度量. 介绍了视频行人重识别现有实验数据集和评价标准,然后提出了该研究领域目前面临的四大挑战,包括姿态变化、遮挡、光照变化、跨模态检索等,给出了相应的解决方案,并展望了视频行人重识别未来的研究问题.
