一种改进的YOLO V3目标检测方法
2020-07-15邱晓晖
徐 融,邱晓晖
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
目标检测(object detection)是计算机视觉领域的基本任务之一,在学术界已有二十多年的研究历史[1]。传统的目标检测算法首先要在给定的图像上进行区域选择(滑窗),然后对这些区域进行特征提取,最后使用训练好的分类器进行分类[2]。这类方法使用手工设计的特征,鲁棒性差,过程复杂。
近年来,随着卷积神经网络的发展,深度学习被广泛应用于目标检测。与传统的目标检测方法相比,使用深度学习进行检测具有很多优势。例如传统方法需要研究人员利用相关知识及经验手动提取特征,基于深度学习的方法可以通过大量数据学习相应数据差异的特征,并且所得到的特征更具代表性。深度学习模型通过模拟人脑的视觉感知系统,直接从原始图像中提取特征,并逐层传递,以获得图像的高维信息。目前优秀的深度学习模型大致可以分为两类:第一类模型将目标检测分为两步(two stage)进行,如R-CN[3]、SPP-Net[4]、Fast-RCNN[5]、Faster-RCNN[6]等,这类算法首先从目标图像的区域候选框中提取目标信息,然后利用检测网络对候选框中的目标进行位置的预测以及类别的识别;第二类模型则是基于端到端(one stage)进行的,如SSD[7]、YOLO[8-9]等,这类方法不需要从图像中预先提取候选网络,而是直接对图像中的目标进行位置的预测以及类别的识别。因此,第二类网络比第一类网络具有较快的检测速度。
为了提高网络目标检测的精度,文中以YOLO V3[10]为基础,在PASCAL VOC数据集上进行训练和测试。首先对YOLO V3的网络结构进行改进,将经过2倍降采样的特征图进行卷积,再分别添加到第二及第三个残差块的输入端,最大化利用浅层特征信息。此外,在8倍降采样的特征图后连接RFB(receptive field block)模块[11]来融合不同尺寸的特征。
1 YOLO V3网络模型
YOLO,即You Only Look Once的缩写,是一个基于卷积神经网络(CNN)的目标检测算法。YOLO V3使用维度聚类得到的锚框来预测边界框,每个边界框预测4个坐标:边界框的中心坐标以及边界框的宽和高。其使用逻辑回归预测每个边界框的类别得分,并使用均方和误差作为损失函数。通过置信度来表示边界框含有目标的可能性大小。如果某个先验边界框与真实对象重叠超过任何其他边界框,则该值置为1。如果边界框的优先级不是最高但是与真实对象重叠超过某个阈值,那么该值置为0。YOLO V3使用DarkNet53网络进行特征提取,其网络结构如图1所示。

图1 YOLO V3网络结构
DarkNet53融合了ResNet[12],共包含5个残差块,每个残差块由数量不等的残差单元组成,每个残差单元又由两个DBL(Darknetconv2d_BN_Leaky)单元及残差操作构成[13],如图2(a)所示。其中,每个DBL单元又是由卷积层、归一化(batch normalization)[14]和激活函数(leaky relu)组成,如图2(b)所示。残差块的使用既可以防止有效信息的丢失,也能够防止深层网络训练时出现梯度消失[15]。除此之外,该网络中没有池化层,它使用步长为2的卷积做下采样来代替池化操作,进一步防止有效信息的丢失,这对小目标来说是十分有利的。

(a)残差单元

(b)DBL单元图2 残差单元构成
YOLO V3网络使用均方和误差作为损失函数,其由三部分组成,分别预测框定位误差、有无目标的IOU误差以及分类误差。损失函数loss如下所示:
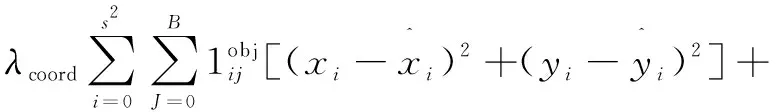

2 改进的YOLO V3网络
2.1 数据集聚类分析
原YOLO V3网络是通过对COCO数据集的聚类来生成9个锚框,每个尺寸的特征图分别对应3个锚框。网络在训练阶段,需要计算真实框与哪个锚框的IOU最大,标记该锚框对应的置信度为1。在计算loss时,这个锚框对应的预测有回归、置信度和分类的误差,大于某个阈值但不是最优的锚框对应的预测值则没有置信度和定位损失,小于阈值的则有置信度损失。需要说明的是,训练时预测的值为高和宽相对于锚框高和宽的值。在测试阶段,则根据置信度与阈值的关系来判断预测的边框是否有效,这时锚框的作用就是还原预测边框在输入图像中的大小。而文中采用的是PASCAL VOC数据集,所以需要重新进行聚类。
2.2 改进的YOLO V3模型
YOLO V3网络中采用特征金字塔来增强检测效果,输出的特征图分别经过了8倍、16倍、32倍的降采样,也就是说当被检测目标不足8 pixel×8 pixel时,最后在输出的特征图上将很难检测到它。为了使更多的小目标信息得以更充分地利用,文中将经过一次降采样的特征图叠加到第二及第三个残差块的输入端。此外,在52×52的特征图后连接RFB(RF Block)模块。RFB模块通过模拟人类视觉的感受野结构(receptive fields,RFs)来加强网络的特征提取功能。特征图首先通过由不同尺寸卷积核构成的多分支结构,然后再经过空洞卷积层增加感受野,最后将不同尺寸的卷积层输出进行concat操作,从而达到融合不同特征的目的。连接结构如图3所示。

图3 RFB连接结构
3 实验结果
文中利用PASCAL VOC 2007+2012数据集中的训练图片对改进后的网络进行训练,使用PASCAL VOC 2012中的测试图片进行测试。采用平均精确值(mean average precision,mAP)作为评价指标,与原网络进行比较实验。
为了验证提出的改进网络的有效性,在PC机上进行了实验,机器配置如下:Window10操作系统,Intel Core i7-8750H处理器,NVIDIA GTX1060独立显卡,6 G显存,8 G内存。采用Tensorflow框架进行训练,时长为24小时。
3.1 实验步骤
(1)训练算法:每次训练随机选取8张图片,初始学习率为1e-4,且逐步递减,但不小于1e-6,IOU置为0.5;
(2)网络参数微调:采用反向传播对网络参数进行微调。前20个epoch先对最后一层网络参数进行优化,后30个epoch对整个网络的网络参数进行调整;
(3)训练数据:采用PASCAL VOC数据集进行训练和测试,其中将VOC2007与VOC2012的trainval文件夹下的图片(共12 000多张)作为训练集;测试集选用VOC2007的测试集。
3.2 实验结果分析
为了验证改进之后网络模型检测的准确率,分别选取原网络第60 000次训练得到的权重和改进网络第50 000次训练得到的权重进行对比实验。改进之前原网络的mAP为80.26%,改进之后网络的mAP为81.35%,提升了1.09%。
图4给出了三组分别基于原YOLO V3网络及改进后网络的实验结果。



((a)、(c)、(e)为原网络的检测结果,(b)、(d)、(f)为改进后网络的检测结果)
图4 YOLO V3网络改进前后的实验结果对比
从前两组对比图中可以看到:图4(a)、图4(c)中出现了漏检的情况,图4(b)、图4(d)检测出了更多的小目标;图4(e)中不仅出现了漏检的情况,而且将dog类检测为person类,图4(f)则检测正确。由此可以看出,改进后的网络对小目标有更好的检测效果,漏检率更低。
4 结束语
提出了一种改进型YOLO网络,通过将经过2倍降采样的特征图进行卷积,再分别叠加到第二及第三个残差块的输入端的方法来增强浅层特征的利用;通过在8倍降采样的特征图后增加一个RFB模块,通过模拟人类视觉的感受野加强网络的特征提取能力。实验结果表明,改进后的网络具有更好的检测效果。
