高管个人特征与公司业绩①
——基于机器学习的经验证据
2020-07-13张叶青赵浩宇
陆 瑶, 张叶青, 黎 波, 赵浩宇
(清华大学经济管理学院, 北京 100084)
0 引 言
“高管特征与公司绩效的关联”一直以来是公司治理领域的重点研究问题.以往研究一方面探究了高管是否在公司决策中担任了至关重要的角色, 另一方面挖掘出了可能会影响公司绩效的一系列高管的个人特征[1,2].那么公司高管的个人特征能够帮助预测公司业绩吗?在这些可能预测公司绩效的高管特征中, 哪些特征更为关键呢?它们的预测机制又是怎样的?以往研究主要围绕单一特征与公司业绩之间的因果关系推断进行研究, 而缺乏从预测能力出发的系统定量的结论.本文试图通过运用机器学习的方法来弥补这一空白.
目前, 大部分公司金融实证研究的目的是推断变量之间的因果关系.因果解释性模型从假设性理论出发, 利用统计模型来验证理论中可观测变量之间的因果关系.这一类建模过程被称为解释性建模 (explanatory modeling), 其中最常用的模型是线性回归模型和结构方程模型.与解释性建模不同, 预测性建模 (predictive modeling) 的目的是准确预测未来的观测值.
预测性分析虽然较少出现在公司金融 (特别是公司治理) 的实证研究中, 但在学术研究中同样至关重要.首先, 预测性模型没有假设变量之间因果关系, 而大部分拟合效果好的模型也没有假设变量之间特定的函数形式 (比如线性关系、U型关系、指数关系等); 相对地, 解释性模型预先对因果关系提出假设, 然后利用数据来进行检验.因此, 预测性模型能够发掘出数据中更为复杂的规律, 有助于提出并验证新的理论来解释数据中存在的规律, 从而推动解释性模型和理论的进步.其次, 预测效果提供了一个评估解释性模型的新角度[3], 衡量每个变量对预测表现的贡献度能刻画该变量的重要程度, 进而检验以往理论的可靠性.第三, 预测性模型帮助研究者比较不同的解释性模型.最后, 预测能力的强弱程度能够反映理论解释现象的能力的强弱程度[4].如果某一个解释性模型的预测效果特别差, 则说明其所依托的理论不足以解释现象, 该理论仍存在较大的发展空间.但值得一提的是, 虽然预测性模型和解释性模型分别从“预测”和“理解”的角度出发, 但两者之间并非是完全对立的.本文预测性模型的设计基于一系列相关经济金融学文献, 而非单纯从数据中凭空构建.因此, 本文与以往理论和实证研究的关系密不可分、相辅相成.
绝大多数对于高管特征与公司业绩的研究仅仅关注了两者之间的因果关联, 而忽视了高管特征对公司业绩的预测能力.解释性模型和预测性模型从概念和优化目标上存在很大差异[5,6](1)从概念方面, 解释性模型基于理论中变量的因果关系, 而预测性模型则基于可测变量之间的关联; 从优化方法的角度, 解释性建模的目标是最小化模型偏差以准确地刻画潜在的理论模型, 而预测性建模的目标是同时最小化模型偏差和样本方差.模型偏差和样本方差的最小化之间存在一定的权衡关系, 因此预测准确性的提高需要牺牲一定的理论解释性., 对公司业绩有解释力的高管指标并不一定能准确预测公司业绩, 因此无法从因果推断模型的估计结果中得出预测效果的结论.本文的研究目标是通过直接探究高管特征对公司业绩的预测效果来弥补这一学术空白.
那么, 为什么要采用机器学习的方法来解答这一问题呢?首先, 改革开放以来, 我国经历了从中央高度集中的计划经济体制到中国特色社会主义市场经济的转轨阶段.从公司的股权结构来看, 国有企业高管的选拔和任命往往出于政治性因素的考虑, 而国企高管面临的非市场化的晋升考核体制也使得他们在任职期间的目标不是企业的经营业绩, 而是政治诉求[7-8].在转型期经济环境下, 国有企业的改革不断推进, 中国特色社会主义市场经济体制逐步建立, 经济环境出现明显波动.经济环境的波动可能导致高管特征与公司绩效之间的关联不是一成不变的, 而是随经济环境波动而动态变化的.以往研究最常使用线性拟合模型, 该模型假定变量之间的相关性是恒定的, 并在此基础上进行模型估计, 因此难以在经济环境波动的情形下得到可靠准确的预测模型.第二, 已有文献发现高管的个人特征与公司绩效之间的非线性关系以及这些特征之间的交互作用(2)比如Adams等[9]发现管理层的特征与组织变量的相互作用对公司表现有显著影响., 这些研究意味着传统的简单线性拟合模型难以清晰、准确地厘清变量之间的复杂关系.基于此, 为了全面挖掘高管特征与公司绩效之间关联, 本文引入处理复杂预测问题的机器学习模型, 试图针对这一公司治理的传统问题提供一个更为全面的解答.
本文以2008年~2016年的上市公司为样本, 实证评估了高管特征对公司绩效的预测能力, 进一步挖掘了对公司业绩预测能力较强的高管的个人特征, 并刻画了它们的预测机制.本文采用的机器学习方法为“Boosting回归树”.该方法的基本思想是: 从初始训练集中得到一个基回归树, 然后在当前预测误差的基础上训练新的基回归树, 每次迭代都向损失函数负梯度的方向移动, 从而达到损失函数随着迭代次数增加而逐渐减小的效果, 最后加权结合多个基回归树得到回归函数.进一步地,基于训练模型分析了各个高管特征在预测公司业绩中的重要程度和预测效果.研究结果发现: 整体而言, 在我国公司CEO和董事长的特征对公司业绩的预测能力较弱.而在众多高管特征之中, 持股比例和年龄对公司业绩的预测能力较强, 且它们与公司业绩之间的关系呈现出明显的非线性的特点.在更换了拟合的滚动窗口期、公司绩效的衡量指标、Boosting模型的参数、其他机器学习算法后, 上述结果仍然稳健.
与现有文献相比, 本文的贡献如下: 第一, 首次应用机器学习方法来研究中国的公司治理问题, 评估了公司高管特征整体对于公司绩效的预测能力, 本文的研究丰富了“高管特征与公司绩效的关联”这一领域的文献.第二,采用前沿的Boosting回归树的方法, 规避了传统线性模型的缺陷, 更好地分析了变量之间的非线性和交互关系.第三,探究了不同高管特征对于预测公司绩效的重要程度, 并分析了相对重要的高管特征对公司绩效的预测机制, 这一系列结论对选聘公司高管具有非常重要的启示意义.
1 文献综述
1.1 高管特征与公司业绩
在现代公司制度下, 高管是公司的核心决策者, 因此“高管特征与公司业绩的关联”是经济、金融和管理学中的经典研究问题.早期的实证研究发现, 高管的个人特征能够很大程度上解释公司的资本结构、投资决策和组织架构[2,10].后续的一系列研究从高管特征的不同角度出发, 验证了多维度的高管特征对公司业绩的影响.这些高管特征的维度可以被归纳为以下五类: 先天特质、人生经历、个性特征、能力水平以及管理风格.同时,公司组织结构也可能影响高管作用.
先天特质方面, 已有文献从高管的性别、年龄、容貌等角度研究.Kaplan和Sorensen[11]的研究发现男、女性高管在管理风格上没有显著差异.高管年龄的影响主要体现在年龄较大的高管的管理风格更加保守[2,12].
高管的人生经历一方面是高管个人特征的反映, 另一方面也可能会通过影响他们的风险偏好、专业技能、对行业发展的预期来影响公司决策的制定.这部分研究的切入点主要包括幼年生活经历[13,14]、家庭生活[15,16]、职业经历[2, 12,13,17]和教育经历[2,12]等.
高管的性格特点也会影响公司决策和公司绩效.比如过度自信的高管可能会高估自己的能力和公司的收益, 从而制定更激进的投资和财务决策, 特别是公司的研发创新投入, 进而影响公司绩效[18-20].此外, 高管是否乐于寻求刺激[21]和他们的风险态度[22-24]也会影响他们的管理风格.
近年来, 针对高管个人能力的研究也非常丰富, 受到研究者关注的高管个人能力主要包括基本能力、沟通交流能力和执行能力等.个人能力本身是难以度量的, 因此越来越多的研究通过非结构化数据和机器学习技术来构建高管的多维能力指标, 并分析这些指标与公司绩效之间的关联[11,25,26].
与上述维度相比, 高管的管理风格是内生性更强的指标.一方面, 管理风格受到高管个人经历、性格、专业水平等特质的影响; 另一方面, 管理风格本身难以观测和度量.比较典型的研究是Bandiera等[27]利用高管的日程记录和非监督机器学习算法, 刻画了“领导型”和“管理型”两种管理风格, 并发现领导型高管所在的公司的绩效更佳.
此外, 公司的组织结构也是影响高管作用的重要因素.例如, 管理层的薪酬制度和高管持股情况通过影响高管工作的努力程度和公司治理水平来影响公司绩效[24,28,29].创始人高管以及家族企业中的高管对公司绩效的影响也有所不同, 比如创始人高管会有更多的研发投入、资本支出和兼并收购活动[30,31].Khanna等[32]发现高管在企业内部的裙带关系会影响上市公司违规犯罪的概率.
关于中国上市公司高管与公司业绩之间关联的研究也层出不穷, 但限于数据的可得性, 国内的研究大多立足于一些可观测的高管特征指标, 并且更多地考虑了中国独特的公司体制和经济环境.具体而言, 中国上市公司高管特征的分析大多围绕高管的职业经历展开, 比如有政府任职经历的高管会更多地参与非生产性活动, 从而降低资源配置效率, 损害公司业绩[33], 但是民营公司高管的政府背景对公司价值没有显著影响[34].高管的学术经历能帮助降低公司的债务融资成本[35], 但人大代表或政协委员的经历会提高发债成本[36].程新生和赵旸发现权威专业董事能够促进企业创新活跃度[37].此外, 徐莉萍等[38]从个人家庭生活经历的角度入手, 发现高管离婚后公司盈利能力和市值水平都有所下降.风险投资和创始人持股会对公司治理效果产生影响[39].此外, CEO与董事之间的关联关系也受到学者的关注, 比如CEO对董事会的影响力的提高使得CEO的违规倾向增加[40], CEO与董事之间存在“老乡”关系会提高公司违规的可能性和公司的财务风险[41,42].而不同类型的董事 (咨询董事或监督董事) 与CEO的互动关系也有所差异[43].
从上述研究可知, 以往关于高管特征的研究主要围绕某一类个人特质, 探讨其对公司决策及业绩的影响, 缺少全面比较公司高管特征相对重要性的研究.此外, 我国特有的制度和文化环境也使得国内的高管研究难以直接借鉴西方的研究结论, 需要更加综合地考虑高管特征对公司业绩的影响.这为本文的研究提供了难得的契机.在已有文献的基础上, 本文结合了各角度的高管特征来探讨哪些特征与公司业绩有更为显著的关联.
1.2 机器学习与公司金融研究
机器学习作为一种新兴的统计工具, 越来越多地受到研究者的关注.目前, 已有研究从两个角度尝试将机器学习应用到公司金融的研究领域: 无监督学习 (unsupervised learning) 和有监督学习 (supervised learning).
在无监督学习中, 训练样本并不对应标记信息, 因此它的目标是通过训练总结、刻画出多维数据的内在关联, 进一步将高维甚至非结构化的变量转化为低维的、可解释性强的变量.这一方法能够从复杂的数据集中归纳、生成本身难以观测的变量, 从而帮助解决公司金融研究中常面临的关键变量难以精确度量的问题.典型的研究包括Bandiera等[27]利用无监督学习中的潜在狄利克雷配置方法来分析CEO日常活动记录的数据, 刻画出了“领导型”和“管理型”两种CEO的行为特征, 并进一步发现“领导型”CEO与好的公司业绩更相关.Li等[44]采用单词植入模型, 构建了五个公司文化价值的指标, 并研究了其对公司行为决策的影响.总体而言, 无监督学习有助于基于大数据来构建难以直接观测和衡量的指标, 大大拓展了公司金融中可研究的领域.
有监督学习主要解决从特征变量(x)到结果变量(y)的预测问题.与传统的线性回归模型相比, 机器学习模型能够应对变量之间更加复杂的非线性和交互关系, 在样本外达到更好的拟合效果[45].近年来, 有监督学习已经在资产定价领域备受关注[46-48], 但在公司金融领域的应用较少.只有Gow等[49]基于CEO个性特征来预测公司样本外的特征, 包括融资决策、投资决策以及经营表现.简言之, 有监督学习提高了传统方法的预测精度, 在公司金融领域的应用仍有广大的探索空间.
2 数据来源和变量说明
2.1 数据来源
本文选取的样本为2008年 ~ 2016年所有的中国A股上市公司, 研究对象为上市公司的最高管理层——CEO和董事长.数据来源为国泰安经济金融研究数据库 (CSMAR) 和锐思数据库 (RESSET) .其中CEO和董事长的个人特征数据来自CSMAR从2008年起开始数据收录的“上市公司人物特征”子数据库.剔除了CEO特征与董事长特征存在缺失的样本点, 同时保证了CEO和董事长个人特征数据的完整, 最终保留样本18 170个, 平均占各年度全部上市公司的85.06%.表1报告了样本分布情况.
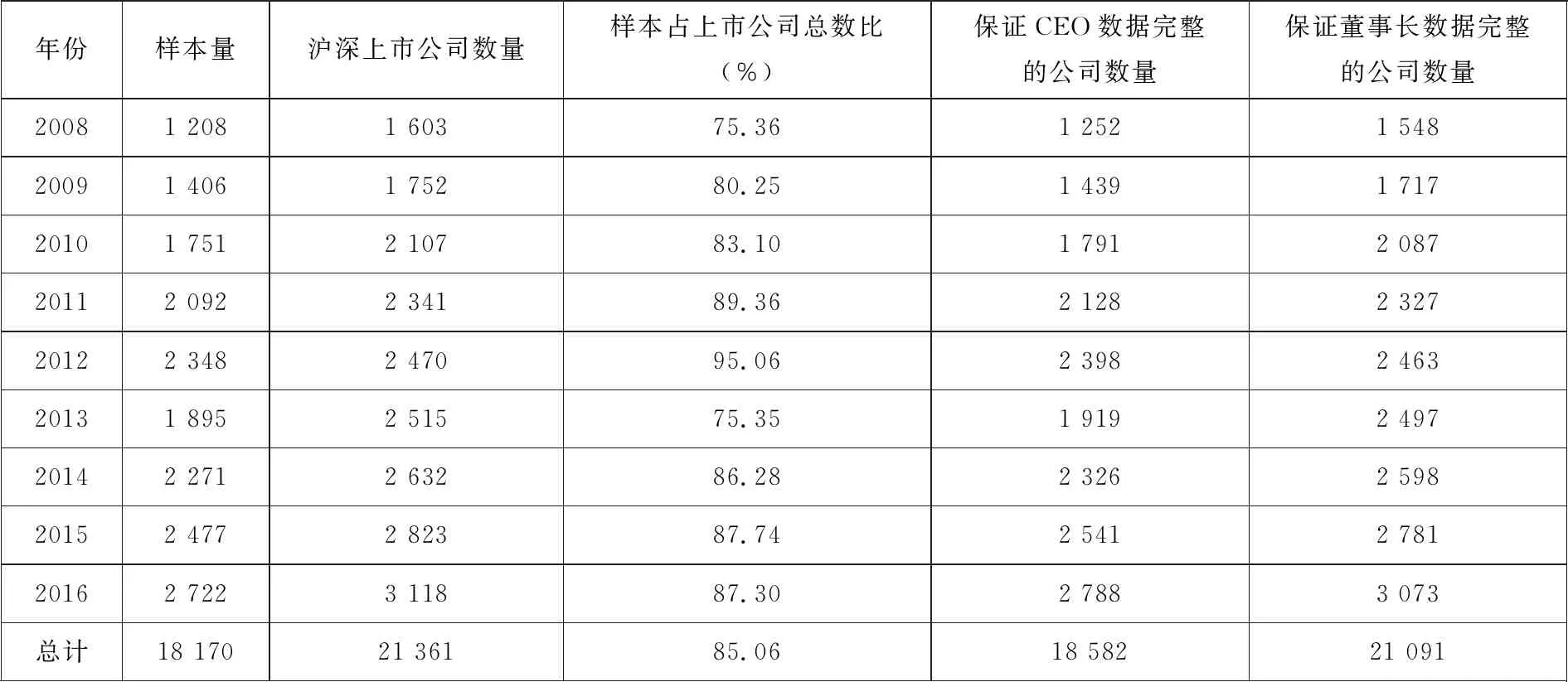
表1 样本分布
2.2 变量定义
本文从盈利能力和价值这两个角度对目标变量——公司绩效进行衡量.公司的盈利能力对应公司的财务绩效, 公司的价值对应公司的市场绩效.具体而言, 本文采用行业中值调整后的资产收益率(adEBITDAper)作为财务绩效指标, 采用行业中值调整后的托宾Q值(adTobinQ)作为市场绩效指标.其中资产收益率定义为息税折旧摊销前利润除以期末总资产; 托宾Q值的定义为公司总市值除以总资产.考虑到公司业绩受行业因素和宏观经济因素影响, 在实际分析过程中, 本文基于行业中值对这两个公司绩效指标进行了调整, 即实际绩效指标减去公司所属行业所有公司当年该绩效指标的中位值.
CEO和董事长的多维度个人特征是本文的核心变量.本文结合文献和中国A股上市公司数据可得性两个方面来选取相关变量.在文献综述部分, 将高管特征的维度归纳为先天特质、人生经历、个性特征、能力水平、管理风格, 以及公司的组织结构.其中, 先天特质包括性别、年龄和容貌等高管与生俱来的种种特征, 而在这些特征当中, 能够被客观测度并可得的变量包括性别和年龄; 人生经历和能力水平可以从高管的职业经历以及教育经历来切入, 本文从生产经营、市场管理、财务法律、金融领域的职业经验来衡量高管在各个领域的专业水平, 同时海外经历以及研究经历也是本文关注的指标.此外, 考虑到国有企业在中国经济中发挥的影响, 本文认为高管的政府工作经历也可能是预测公司绩效的重要指标.组织结构方面,采用高管持股和兼职情况来对公司绩效进行预测.而由于个性和管理风格方面的特征难以观测和准确度量,暂时未将其纳入考虑, 但这会是下一步的重要研究方向.
具体而言, 本文选取的高管特征包括年龄、性别、话语权、年末持股比例、公司外兼职、职能经验、海外经验、学术经验、金融工作背景和政府工作背景.其中, 话语权由CEO和董事长是否两权分离来衡量; 职能经验涵盖三个方面, 第一是生产、技术和设计岗位经验, 第二是市场、人力、管理岗位经验, 第三是财务、法律职能岗位经验, 这三方面职能经验描述了高管主要的职场经验和能力; 海外经验反映该CEO或董事长是否有海外工作或求学经历; 学术经验反映该CEO或董事长是否有学术研究工作经历; 金融背景反映该CEO或董事长是否曾任职于金融机构(3)此处统计中的金融机构包括监管部门、政策性银行、商业银行、保险公司、证券公司、基金管理公司、证券登记结算公司、期货公司、投资银行、信托公司、投资管理公司、交易所等.; 政府工作背景反映该CEO或董事长是否曾任职于政府部门, 衡量其政治关联度.
在基准模型中, 公司层面的变量包括: 公司规模、公司寿命、杠杆率、重资产率和股权性质.其中, 公司规模由公司总资产规模衡量; 杠杆率由上市公司总负债与总资产的比率衡量; 重资产率由上市公司固定资产净额与总资产的比率衡量; 股权性质指的是国有股份占比.上述所有变量的具体定义, 均在表2中列明.
从探究因果关系的角度出发, 上述变量之间存在明显的内生性问题, 而对变量之间内生性的处理方式也是本文与以往大部分高管相关研究相比的重要区别之一.内生性指的是在解释性模型中, 解释变量与残差项之间的相关性, 通常由遗漏解释变量、反向因果和测量误差导致[4].解释性建模旨在识别模型和证明因果关系, 因此内生性的存在会使得参数估计有偏.然而, 与证明因果关系的解释性建模不同的是, 本文的预测性建模并不关注因果关系, 而是相关关系, 所以变量之间内生性的存在并不会影响对预测效果的评估[4].
2.3 描述性统计
表2分别列出了被预测变量、CEO特征、董事长特征和公司层面其他变量的描述性统计, 包括样本量、均值、标准差和中位数.为了防止极值带来的统计偏差, 本文对连续型变量进行了1%和99% 的Winsorize处理.
从高管的个人特征变量的描述性统计结果 (面板B和面板 C) 中,可以发现: 首先, 近四分之一 (24.96%) 样本中CEO和董事长由同一人担任; 第二, 男性在公司“一把手”职位中占绝对优势, 女性CEO仅占6.02%, 而女性董事长仅占4.53%; 第三, 我国上市公司CEO在其他公司兼职的比例高于董事长, 超过一半 (52.92%) CEO在其他公司兼职, 董事长在其他公司兼职的比例仅为26.51%; 第四, 我国上市公司CEO和董事长在职能背景方面具有类似的特征, 平均25%至30%的CEO或董事长具有生产、技术、设计等职能经验, 约18%的CEO或董事长具有财务、法律等专业职能经验, 超过90%的CEO或董事长具有市场、战略、人力等管理职能经验; 第五, CEO或董事长具有海外工作、求学经历的比例较低, 仅约5%; 最后, 我国上市公司的董事长比CEO具备更丰富的政府工作、学术研究和金融工作经历.
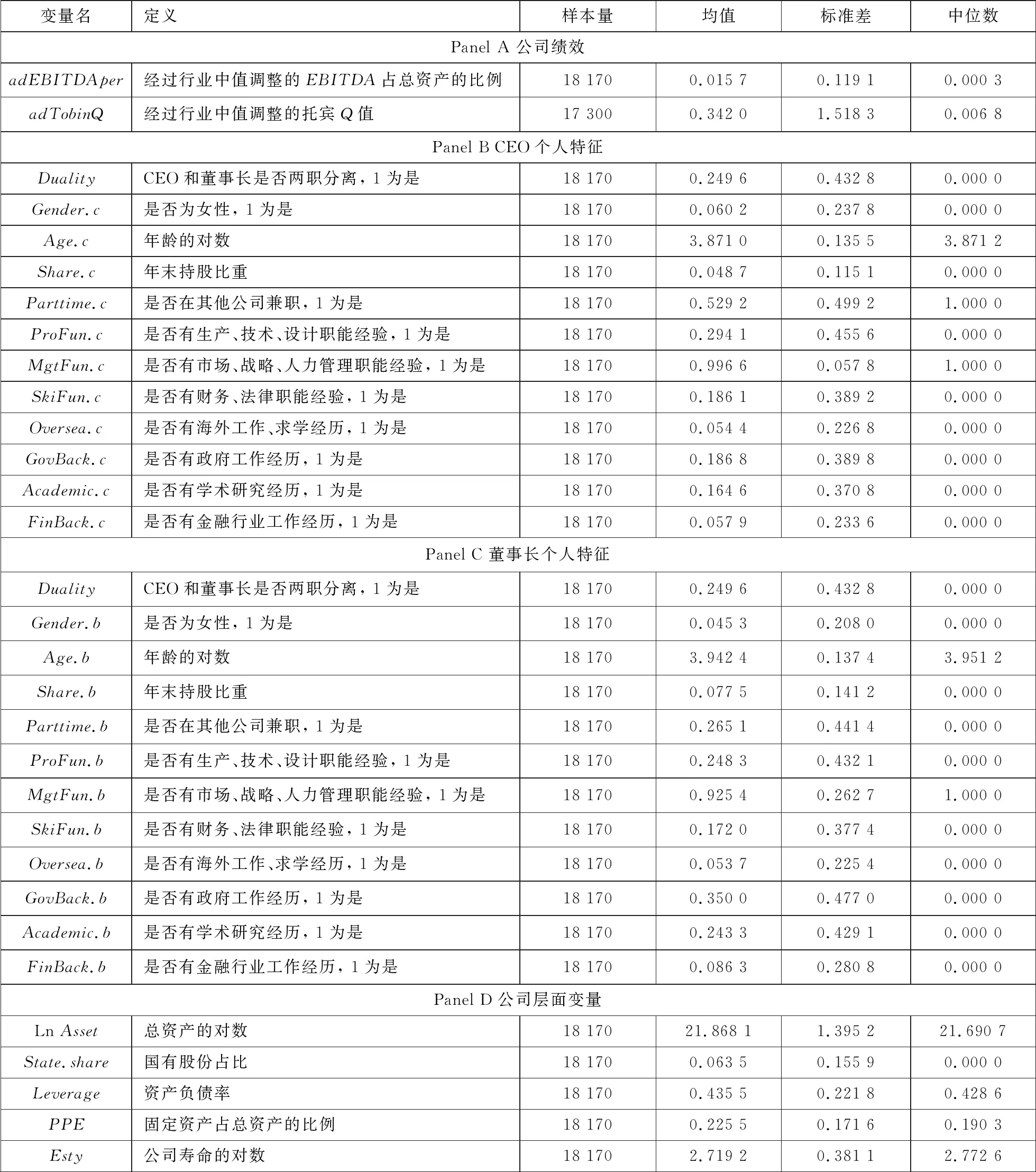
表2 主要变量的定义和描述性统计
3 研究方法和模型构建
3.1 Boosting回归树
本文采用的机器学习方法为渐进梯度回归树 (gradient boosting regression trees, GBRT)(4)本文使用的Boosting算法是Ridgeway[50]使用的R语言工具包“gbm”, 参数设置如下: distribution=“gaussian”, n.trees=10 000, interaction.depth=6, shrinkage=0.001.在稳健性检验部分验证了参数调整对预测效果的影响., 简称“Boosting回归树”[51,52].Boosting回归树有效地结合了机器学习中的决策树和集成思想, 通过加权多个基回归树来提高拟合效果, 在样本内和样本外的拟合精确度都非常高[53].
(1)
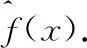
(2)
即使得误差平方和最小的常数.计算损失函数的负梯度
(3)
利用损失函数负梯度在当前模型的值(zi)作为残差的近似值, 基于xi拟合出新的回归树模型
g(x)=Ε(z|x)
(4)
选择使得误差最小的梯度下降幅度
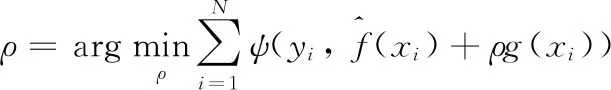
(5)
进而得到经过本轮迭代后新的预测函数
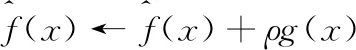
(6)
然后循环以上迭代过程(t=1,…,T) .
Boosting回归树的估计过程主要涉及三个参数: 回归树的交互深度 (interaction depth) 、收缩参数 (shrinkage parameter) 和回归树的数量.在本文的模型中, 参数的调整优化 (tuning parameters) 仅建立在样本内信息之上, 而最优参数的搜索范围则是根据经验法则和运算成本来确定的.
交互深度指的是每个基回归树有几次分叉.根据经验法则和算力限制设置了最大交互深度, 即最优交互深度的搜索范围.较多的分叉意味着基回归树能考虑到更复杂的交互性, 但更容易过度拟合.同时, 过高的交互深度也会带来较大的计算成本.Hastie等[54]认为在多数问题中最优交互深度都较低, 因此本文的研究将交互深度的上限设置为6.
收缩参数指的是被加入模型中的新的基学习器的权重.根据以往基于GBRT模型的研究经验[50,54], 收缩参数一般设置为0.01或0.001, 且在算力允许的情况下取值尽可能小.越小的收缩参数越可能带来更优的预测效果, 但本文并没有尝试小于0.001的收缩参数, 主要原因是更小的收缩参数需要更高的运算性能, 会极大地提高计算成本(包括存储成本和CPU运算时间), 且对预测的边际提升效果很小[54], 容易过度拟合[52].因此, 本文取收缩参数值为0.001.
最优的收缩参数和最优的回归树数量是相互影响的.基回归树的数目与收缩参数之间需要一定的平衡, 小的收缩参数往往需要更多的基学习器.本文的模型中基回归树的数目上限设置为10 000.(6)本文分析部分所涉及的拟合过程取得最佳优化效果时的回归树的数量通常处于3 000至5 000之间.在每一次滚动的训练样本中,采用5折交叉验证 (cross-validation) 的方法来确定最优的基回归树的数目.上述模型参数的优化过程完全没有用到样本外的信息.
作为一种集成的树形回归算法, Boosting虽然可以显著提升预测准确度, 但模型的可解读性却不尽如人意.为了解决这一问题,采用了相对重要性 (relative importance) 和部分依赖图 (partial dependence plot)来进一步挖掘模型背后的经济学内涵.本文的目的并非仅仅是预测, 更是试图回答哪些变量对预测效果影响较大以及预测模式如何.这些问题的回答一方面能够有助于验证以往文献中“因果关系”的可靠性以及预测模型的可靠性, 比如本文通过部分依赖图关系图印证了高管持股比例与公司业绩之间存在着非线性的复杂关系; 另一方面能够推动对变量之间关系的理解, 从而提出新的理论[4].上述两点意义对于正在形成期的理论而言尤为重要[55,56].如果仅仅关注预测效果, 而忽视预测模型的可解释性, 那么整个模型就变成了一个“黑箱模型”, 内在预测机制被掩盖, 无法带来更多启发.
一个变量的相对重要性指的是一个变量在模型拟合过程中, 相对于模型中其他变量的重要程度.根据Friedman[52],将变量重要性的定义为给定模型中其他部分不变, 在模型中加入该变量带来的平方误差的下降幅度.换言之, 相对重要性即在模型中其他部分不变的前提下, 在模型中去掉该变量或用一个随机数变量将该变量替代后, 模型拟合能力的恶化程度相对于在其他变量上做相同操作后模型拟合能力恶化程度的大小.如果一个变量对应的恶化程度相对较大, 则其在模型拟合过程中的相对重要性较大.本文通过计算相对重要性来回答高管的高维特征之中, 哪些特征对于公司绩效的预测效果贡献更大的问题.为了便于比较, 模型中所有变量的相对重要性指标之和被标准化为1.
本文希望基于Boosting模型的估计挖掘出一些解释性意义, 因此进一步引入部分依赖图来分析单个变量对于预测结果的影响模式.某一特征变量对于被预测变量的部分依赖关系是在控制其他特征为观测值的情况下, 衡量这一特征变量值的变动对模型拟合效果的影响.这一指标能够在一定程度上解决relative importance无法反映正负关系的问题.利用部分依赖图, 可以考察某一高管特征对公司绩效的预测模式
(7)
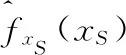
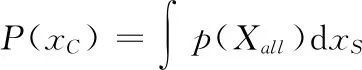
(8)
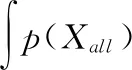
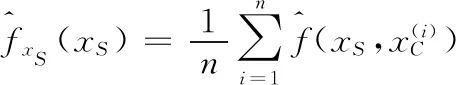
(9)
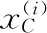
(10)
本文选择Boosting回归树作为主要研究方法有以下两点原因.1) Boosting回归树有较强的拟合能力.根据Hastie等[54]的论述, 在众多统计学习方法中, 基于“树”的学习器具有易于构建、可解读、对变量的严格单调变换保持不变、不受极端值影响等优点.另外, 回归树本身能够进行变量筛选, 因此即使加入不相关的变量, 也不会对结果造成影响.但是, 回归树是一种弱学习器, 单独使用会得到不精确、波动大的结果.因此,Boosting回归树通过对集成许多基回归树, 能在尽量保持其固有优势的情况下, 显著提升其准确性.2) Boosting回归树有较好的可解释性.大多数有监督的机器学习方法的唯一目的是预测, 因此往往会为了提高模型的复杂度和预测准确性而牺牲模型的可解释性[57], 导致了绝大部分机器学习方法都是“黑箱模型”, 极大地限制了机器学习在公司金融领域的应用.而Boosting回归树是机器学习中为数不多的解释性较强的模型(7)随机森林 (random forest) 模型和XGBoost也是可解释性较强的模型, 本文在稳健性分析中加以讨论., 不仅可以提高模型的预测性, 而且能通过计算变量的相对重要性和绘制部分依赖图来促进对理论的探索.
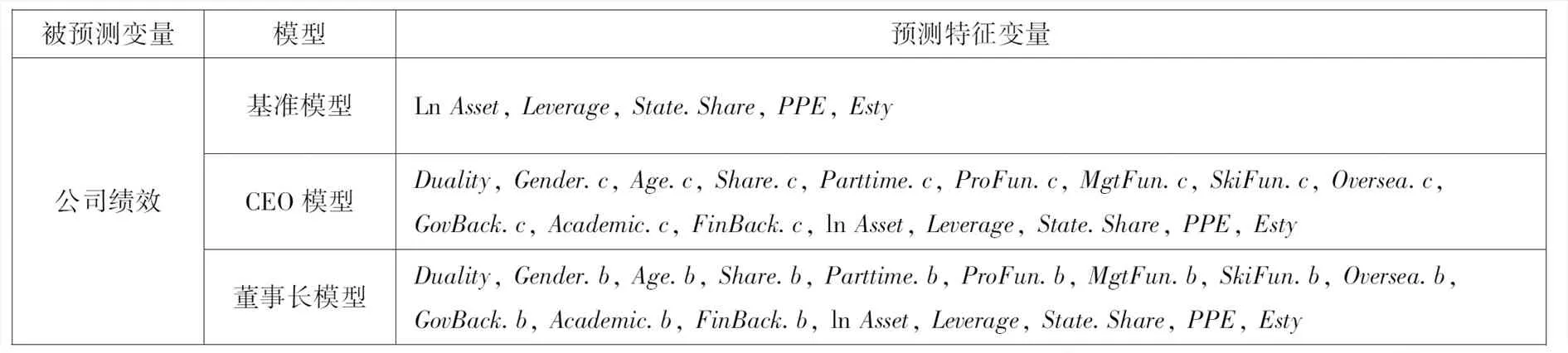
表3 模型构建
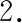
3.2 模型构建
本文对中国上市公司高管的个人特征进行综合考量.首先构建了只包含公司基本特征但不含公司高管人物特征的基准模型 (以下简称“基准模型”) .基准模型仅由五个描述公司特征的控制变量组成, 包括公司规模(lnAsset)、杠杆率(Leverage)、国有股份占比(State.Share)、重资产比例(PPE)和公司寿命(Esty).在基准模型的基础上,分别加入CEO特征族和董事长特征族, 进一步构建了两个包含高管人物特征的模型(以下分别简称为“CEO模型”和“董事长模型”).三个模型如表3所示.
基于上述模型, 本文的研究设计主要按照以下几个步骤进行:
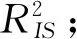
(11)
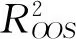
第二, 考察高管各项特征对于预测公司绩效的相对重要性.利用Boosting回归树的相对重要性指标, 计算三个模型中各变量的对于模型拟合的相对重要性, 取T次拟合结果中各变量的相对重要性的均值作为该变量综合的相对重要性.在CEO模型和董事长模型中,将各人物特征的相对重要性相加可以得到CEO或董事长人物特征的综合的相对重要性, 从而可以进一步对比CEO或董事长特征族在模型中的相对重要程度, 从中总结出对公司绩效预测能力较强的高管特征.
第三, 对于相对重要性较高的高管特征,利用Boosting回归树生成部分依赖图, 进一步分析其对于公司绩效的预测模式和边际影响.
最后, 对本文主要的分析结论进行稳健性检验, 包括改变滚动时间窗口、改变公司绩效衡量方式、调整Boosting模型的估计参数、更换机器学习方法和更换高管特征变量.
4 实证检验与结果分析
4.1 高管特征能够预测公司业绩吗?
本部分利用Boosting回归树的方法和中国A股上市公司的样本, 分别实证检验了CEO和董事长的个人特征是否能够较大程度上提高模型对公司业绩的预测效果.表4列出了“Boosting-CEO模型”和“Boosting-董事长模型”的拟合效果, 并加入了仅包括公司层面指标的“Boosting-基准模型”作为对照, 通过分析二者相对于“Boosting-基准模型”的拟合效果分别提升的程度, 判定CEO和董事长的个人特征整体对公司业绩预测的贡献程度.同时,将“OLS-基准模型”、“OLS-CEO模型”和“OLS-董事长模型”(8)与Boosting模型类似, OLS模型也是采用一年期滚动窗口回归, 并分别计算了其在样本内的拟合效果和在样本外的泛化能力.作为对照组, 检验Boosting回归树的机器学习方法是否能显著提高模型的预测能力.在表4的面板A和面板B中,分别以财务绩效和市场绩效作为公司业绩的代理变量.
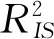
表4 主要拟合结果
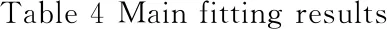
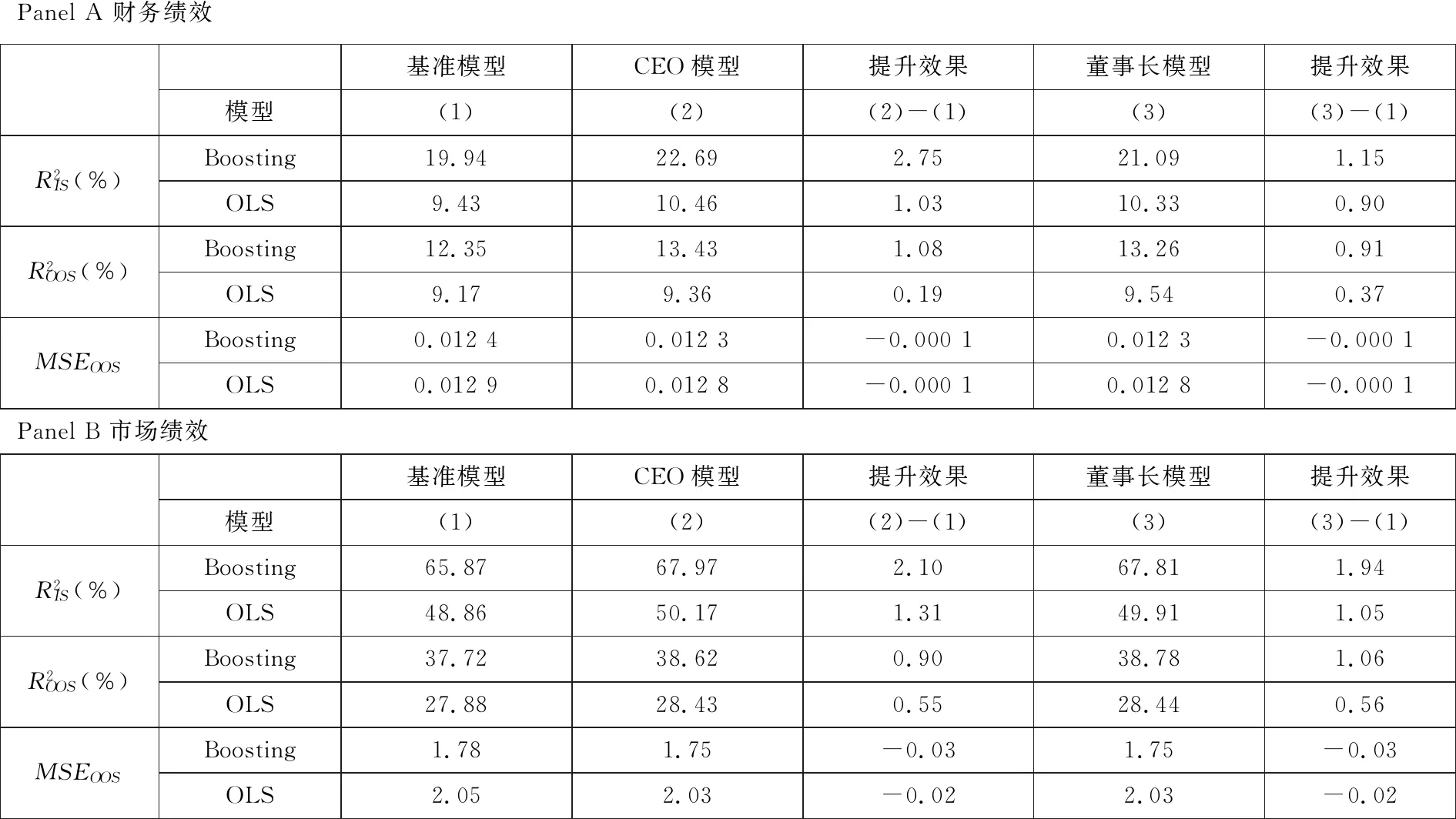
PanelA财务绩效基准模型CEO模型提升效果董事长模型提升效果模型(1)(2)(2)-(1)(3)(3)-(1)R2IS(%)Boosting19.9422.692.7521.091.15OLS9.4310.461.0310.330.90R2OOS(%)Boosting12.3513.431.0813.260.91OLS9.179.360.199.540.37MSEOOSBoosting0.01240.0123-0.00010.0123-0.0001OLS0.01290.0128-0.00010.0128-0.0001PanelB市场绩效基准模型CEO模型提升效果董事长模型提升效果模型(1)(2)(2)-(1)(3)(3)-(1)R2IS(%)Boosting65.8767.972.1067.811.94OLS48.8650.171.3149.911.05R2OOS(%)Boosting37.7238.620.9038.781.06OLS27.8828.430.5528.440.56MSEOOSBoosting1.781.75-0.031.75-0.03OLS2.052.03-0.022.03-0.02
4.2 高管个人特征的相对重要性分析
表5中报告了CEO模型和董事长模型中各变量对于预测公司绩效的相对重要性, 其中面板A和面板B分别展示了各变量对于预测财务绩效和市场绩效的结果.每一个面板的左侧为CEO模型, 右侧为董事长模型.为了便于区分,在属于人物特征的变量后标记了“*”.从而发现: 在众多的高管特征中, 持股比例和年龄对预测公司绩效的相对重要性较高 (在面板A和面板B中都大于1%) , 而其他诸如政府背景所代表的政府资源、金融工作背景所代表的金融资源和不同职能的工作经验等特征的相对重要性较低.
表5 各变量相对重要性排序
Table 5 The ranking of relative variable importance

排序CEO模型董事长模型变量相对重要性(%)变量相对重要性(%)1资产负债率31.77资产负债率32.252公司规模21.27公司规模21.303重资产占比18.52重资产占比18.734年龄*6.45年龄*6.395国有控股比例5.51公司寿命5.666公司寿命5.50国有控股比例5.597持股比例*4.91持股比例*4.928影响力(兼职)*1.05管理职能*0.819专业职能*1.00金融工作背景*0.7710学术经验*0.83政府背景*0.7511政府背景*0.76专业职能*0.7012金融工作背景*0.68CEO董事长兼任*0.4713性别*0.49学术经验*0.4214CEO董事长兼任*0.49性别*0.3515生产职能*0.41生产职能*0.3416海外经历*0.35影响力(兼职)*0.3417管理职能*0.00海外经历*0.22CEO特征族相对重要性总计17.43董事长特征族相对重要性总计16.47
表5 (续)
Table 5 (Continue)
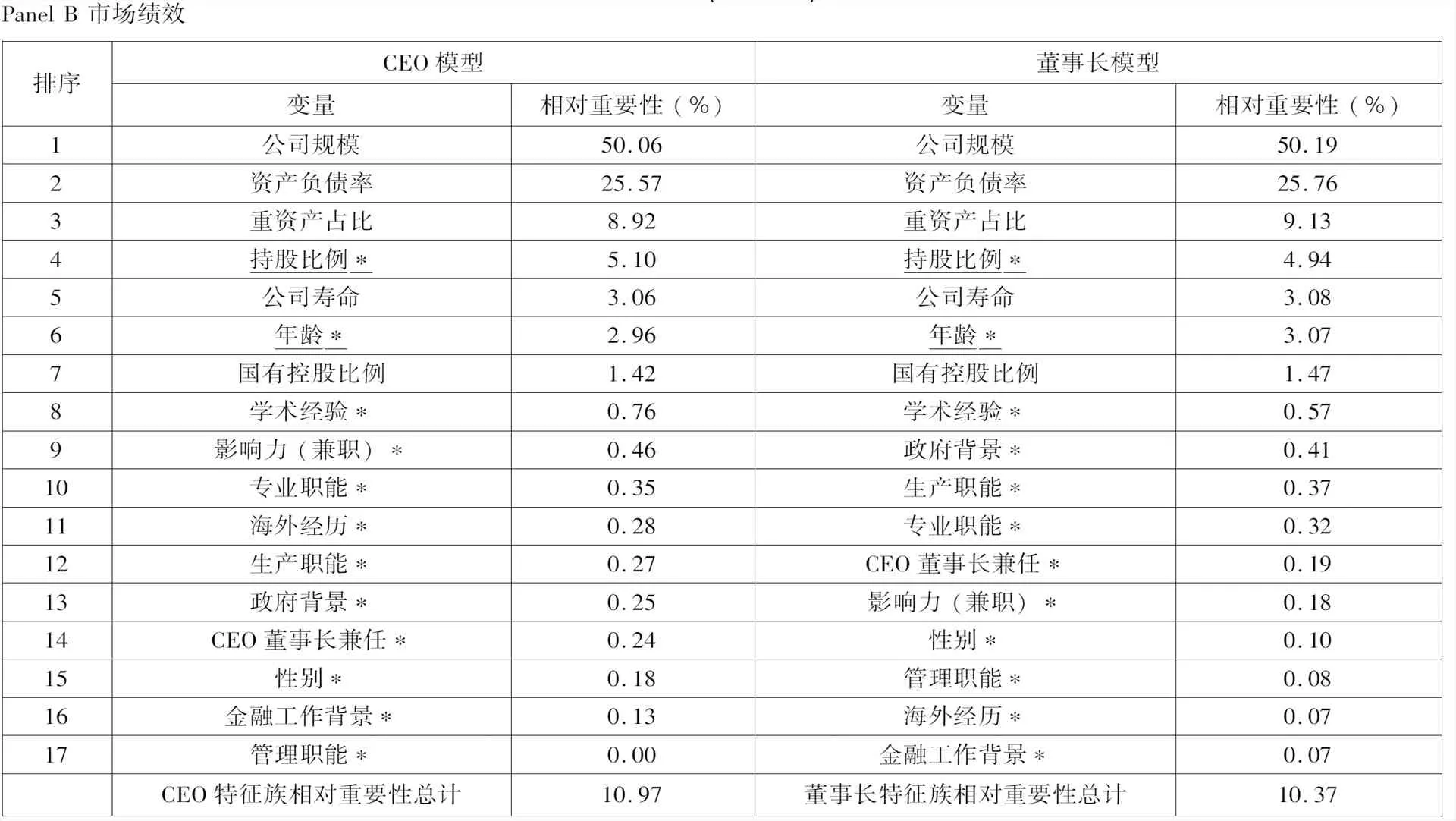
排序CEO模型董事长模型变量相对重要性(%)变量相对重要性(%)1公司规模50.06公司规模50.192资产负债率25.57资产负债率25.763重资产占比8.92重资产占比9.134持股比例*5.10持股比例*4.945公司寿命3.06公司寿命3.086年龄*2.96年龄*3.077国有控股比例1.42国有控股比例1.478学术经验*0.76学术经验*0.579影响力(兼职)*0.46政府背景*0.4110专业职能*0.35生产职能*0.3711海外经历*0.28专业职能*0.3212生产职能*0.27CEO董事长兼任*0.1913政府背景*0.25影响力(兼职)*0.1814CEO董事长兼任*0.24性别*0.1015性别*0.18管理职能*0.0816金融工作背景*0.13海外经历*0.0717管理职能*0.00金融工作背景*0.07CEO特征族相对重要性总计10.97董事长特征族相对重要性总计10.37
注:1. 依照相对重要性高低进行排序, 人物特征后标记*.
2. 下划线代表相对重要性指标在面板A和面板B中的均大于1%的人物特征变量.
持股比例反映了高管对公司决策的话语权和公司绩效对公司高管的激励水平.高管年龄反映了高管对用于生产经营和管理公司的内部资源的积累.相比而言, CEO和董事长的其他人物特征反映的是其对个人自身技能和外部资源的积累.例如, 生产职能、专业职能和管理职能的工作经验和学术经验可以反映个人自备技能的积累, 政府工作背景、金融工作背景和海外经历等可以反映外部资源积累.上述分析结果表明高管的持股比例和年龄能够更大程度上预测公司绩效.其原因主要是在中国A股上市公司中, 高管对公司内部资源的积累和把控能力对于公司绩效的影响大于其个人自身技能和对外部资源的积累把控能力带来的影响.
4.3 重要高管特征对于公司绩效的预测模式
在变量重要性的分析中, 本文发现持股比例和年龄是高管特征中两个最为重要的预测公司绩效的因素.那么这两个特征和公司绩效的关联究竟是怎样的呢?为了回答这一问题, 本文中采用部分依赖图来考察持股比例与年龄对于公司绩效的预测模式.图1至图4展示了CEO持股比例和年龄对于公司绩效的预测模式(9)董事长的持股比例和年龄的分析结果与CEO的类似.限于篇幅, 本文在正文中仅报告了CEO相关的部分依赖图., 横轴为持股比例或年龄, 纵轴为公司绩效.
图1和图2分别展示了中国A股上市公司的CEO持股比例与公司财务绩效和市场绩效的部分依赖图.根据表2描述性统计的结果, 中国A股上市公司的CEO和董事长的持股比例平均值很低, 中位数皆为0.进一步观察发现, 18 170个观察值中, 仅有53个CEO的持股比例高于60%, 仅有76个董事长的持股比例高于60%, 高比例占股的现象极少.因此本文主要分析持股比例在0%到60%区间的部分依赖图, 高管的持股比例对公司绩效的预测效果具有明显的非线性特点.整体来看, 随着高管持股比例的提升, 公司绩效呈上升趋势.公司绩效受到CEO持股比例影响的程度在不同持股比例下是不同的.部分依赖图中的曲线初始阶段较为平缓, 后半段陡升.这说明当持股比例处于中等以下水平区间时 (0%至约40%) , 持股比例增加对提升公司绩效的作用较为微弱; 而当持股比例处于较高水平时 (约40%以上) , 增加持股比例对于提升公司绩效的作用明显.
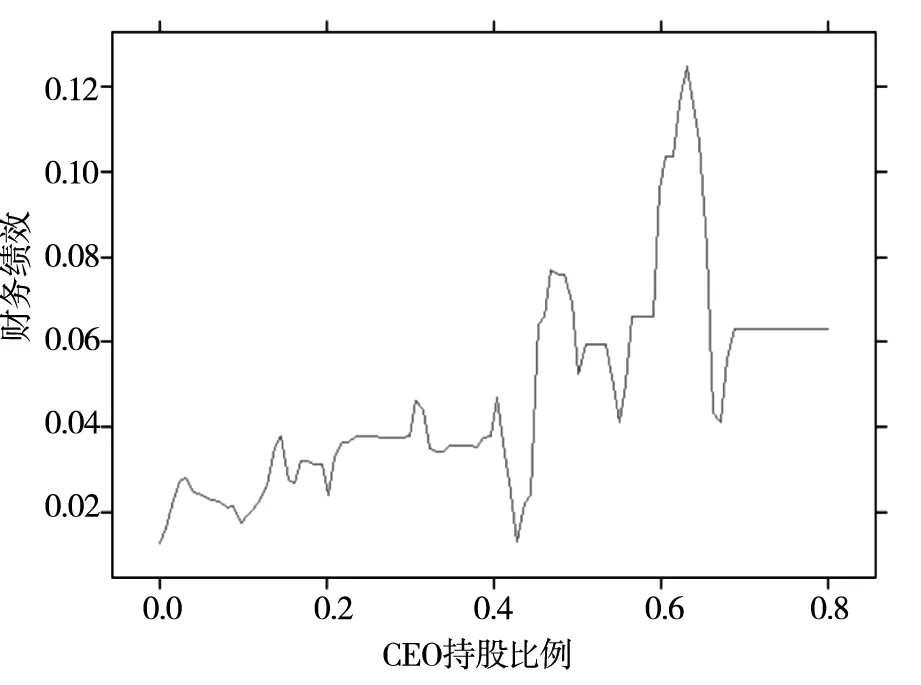
图1 CEO持股比例与财务绩效
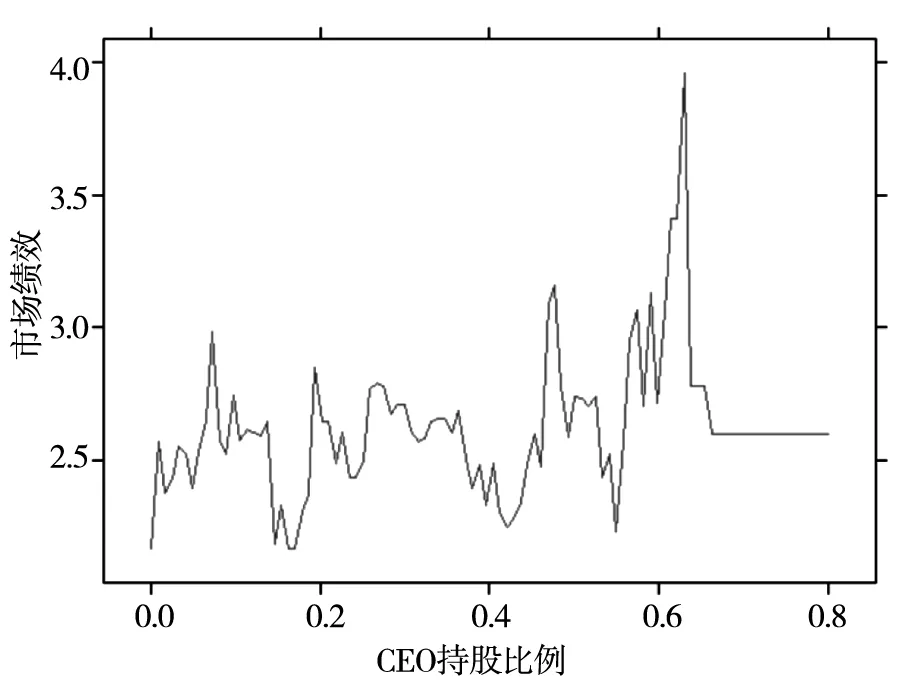
图2 CEO持股比例与市场绩效
以往文献中针对高管持股的激励效果存在争论, 主流观点有以下三种.首先, 管理层所有权的增加可以使得管理者与股东的利益趋同, 缓解代理问题[61].其次, 当高管持股水平超过一定阈值后, 他们的权力难以受到控制, 就能更多地谋取自身的利益而牺牲股东利益, 即“壕沟防守效应 (entrenchment effect) ”[62].最后, 高管持股与公司绩效之间也可能没有明显关联[63].基于这三类效应, 目前大量的实证结果验证了高管持股与公司业绩之间的非线性关联(10)对于财务绩效, 刘鲁彬[64]的实证研究发现, 当高管持股低于约23%或高于约61%时, 其与扣除了非经常性损益后的净资产回报率呈显著正相关, 否则呈显著负相关.对于市场绩效, Morck等[65]的分段回归分析表明, 高管持股比例低于5%或高于25%时, 其与托宾Q值呈显著正相关, 否则呈显著负相关.类似地, 韩亮亮等[66]利用小规模的中国市场样本发现当高管持股比例低于8%或高于25%时, 其与托宾Q值呈正相关, 否则呈负相关关系..
基于上述理论, 本文认为图1和图2的结果是因为当高管持股比例较高时, 利益趋同效应更加明显.与此同时, 随着持股比例的提升, 其对公司绩效的作用会在局部出现“下探”现象, 即在局部区间对公司绩效有负面影响.理论上, 这种“下探”对应着“壕沟防守效应”, 即提升高管持股比例可能使高管对公司的控制能力增强, 受到的约束变弱, 进而可以追求更大范围的个人利益, 提高代理成本.该非线性关系也与Kim和Lu[24]的发现一致: 当高管持股比例高于一定水平时, 经理人会过于风险厌恶, 从而放弃一些对公司有利的但高风险的投资行为 (例如研发投资) , 从而导致企业价值下降.总体而言, 本文发现高管持股对公司业绩的作用效果是非线性的, 且在不同持股比例区间可能呈现出利益趋同效应、壕沟防守效应或没有影响, 这对已有理论是互相补充印证的.
图3和图4分别展示了中国A股上市公司的CEO年龄与公司财务绩效和市场绩效的部分依赖图.高管的年龄对于公司绩效也具有明显的非线性预测作用, 且对财务绩效和市场绩效的预测模式差异较大.从财务绩效来看, 年龄与绩效的关系近似与“U”型结构, 特别年轻CEO与特别年长的CEO管理的公司财务绩效更佳.而市场绩效却会随着CEO年龄增长而逐步提升, 同时在年龄超过一定范围后, 市场业绩会出现随年龄增长而大幅下降的趋势.这说明年龄与公司绩效之间的关联较为复杂.
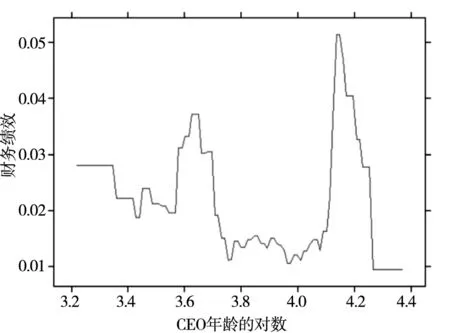
图3 CEO年龄与财务绩效
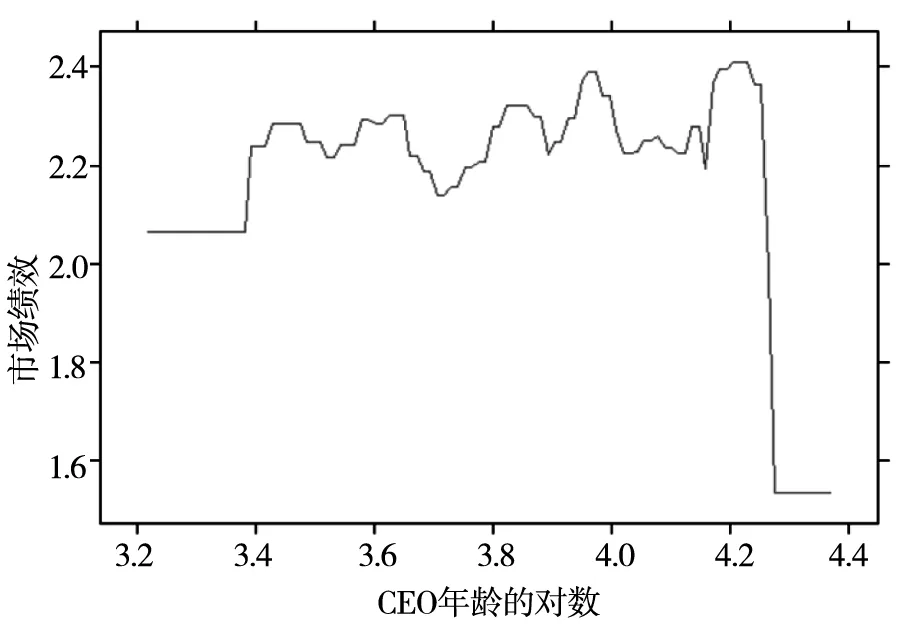
图4 CEO年龄与市场绩效
从理论上看, CEO年龄可能会有三种机制来预测公司决策和公司业绩.第一, 年龄的变化给高管带来的个人心理和生理的变化将会间接影响公司的投融资行为.比如年轻的CEO容易过度自信, 因此更容易从事并购以及高风险项目, 而年老的CEO管理风格更为保守[67, 68].其次, CEO年龄是其在公司中的地位与权力的体现, 年龄大的CEO在公司拥有更强的控制力, 会利用自身权力谋取私利, 不利于公司业绩提升.最后, 年龄大意味着更高的社会资本和经验, 因此年龄大的CEO为企业贡献更多的人力资本, 帮助企业提升业绩.
结合图3和图4的结果, 本文认为年龄与公司业绩的关系体现了上述三种预测机制, 且不同作用机制的相对强弱与其他变量存在较强的交互关系, 比如企业的国有性质会使得年龄带来的管理权力效应更为显著.因此, 年龄与公司业绩的关联较为复杂,会在未来研究中关注.
5 稳健性检验
5.1 更换滚动时间窗口

表6 更换滚动窗口期 (三年)

表7 更换公司绩效的衡量方式

表7 (续)
5.2 更换公司绩效的衡量指标
在基本分析中,分别采用行业中值调整后的资产收益率(息税折旧摊销前利润除以期末总资产) 和托宾Q值作为公司的财务和市场绩效评价指标.为了避免可能的变量衡量误差带来的结果偏差,更换了一组公司绩效衡量指标来分析.财务指标更换为行业中值调整后的资产收益率 (净利润除以期末总资产) , 市场指标更换为行业中值调整后的个股年度超额回报率.
5.3 Boosting模型的参数调整
Boosting模型的估计过程中设定了多个参数, 包括回归树的交互深度、收缩参数和回归树的数量.其中,模型将回归树数目的上限设为10 000, 而模型的回归树数目是通过交叉验证最优选择的.本文拟合过程取得最佳优化效果时的回归树的数量通常处于3 000至5 000之间,因此上限设置是合理的.
本文还检验了回归树的交互深度和收缩参数的选择是否合理.在绝大多数的GBM模型中, 回归树的交互深度都在2至9之间, 而收缩系数在0.001和0.1之间[54].基于参数检验的基本思想,构建了一系列可能的参数组合, 遍历这些参数下的估计结果, 从而判断在基本分析中所使用的参数是否合理.如果预测结果对参数的选择十分敏感的话, 那么选择的参数则是不合理.
具体而言, 本文将交互深度设为{2, 4, 6, 8}, 收缩参数设为{0.001, 0.01, 0.1}, 共构成12(=4×3) 个参数组合, 并分别在每个参数下进行估计.表8以财务绩效的预测模型为例, 展示了参数变动对预测效果的影响.结果发现在这些参数组合下, CEO和董事长对公司绩效预测效果的提升程度与表4的结果相近.
表8 更换参数组合
5.4 更换机器学习方法
5.4.1 随机森林 (Random Forest)
Random Forest是机器学习算法中另一种常用的回归树模型.文献表明, Boosting的预测能力强于Random Forest, 尤其是在指标维度低于4 000维时[69,70].因为Random Forest在解决回归问题时, 无法做出超越训练集数据范围的预测, 在噪音较大的问题上容易出现过度拟合[45].所以本文没有将Random Forest作为主要的研究方法, 但采用这一方法作为稳健性检验.
表9报告了Random Forest模型拟合的基本结果.发现, 相对于Boosting模型, Random Forest模型的结果中高管特征对公司业绩的预测性有所提高, 但总体而言仍处于较低水平.比如, 高管个人特征的加入对公司财务和市场绩效的预测误差分别降低了0.001 0和0.13.
表9 更换机器学习算法 (随机森林)
Table 9 Alternative machine learning algorithms (random forest)
基准模型CEO模型董事长模型(1)(2)(2)-(1)(3)(3)-(1)R2IS(%)63.5180.8317.3280.8217.31R2OOS(%)15.2022.146.9422.607.40MSEOOS0.01200.0110-0.00100.0110-0.0010基准模型CEO模型董事长模型(6)(7)(7)-(6)(8)(8)-(6)R2IS(%)82.0691.099.0391.129.06R2OOS(%)37.0241.994.9742.045.02MSEOOS1.791.66-0.131.66-0.13
5.4.2 XGBoost
XGBoost (Extreme Gradient Boosting) 是除GBM之外另一种优化GBRT问题的算法, 它与GBRT的主要区别在于在优化过程中不仅考虑了损失函数的一阶导数信息, 而且对损失函数进行了二阶泰勒展开, 同时用到了一阶和二阶导数信息[71].但由于参数数量的增多,XGBoost所需的运算时间更长.在表10中报告了XGBoost的估计结果, 发现高管模型相对于基准模型的提升程度与表4中GBM的结果相似, 多数指标的提升幅度仍处于较低水平.比如, CEO个人特征的加入对财务绩效的样本外预测误差 (MSEOOS) 的降低幅度仅为0.000 2.综上, 本文的基本结果是稳健的.
表10 更换机器学习方法 (XGBoost)
Table 10 Alternative machine learning algorithms (XGBoost)
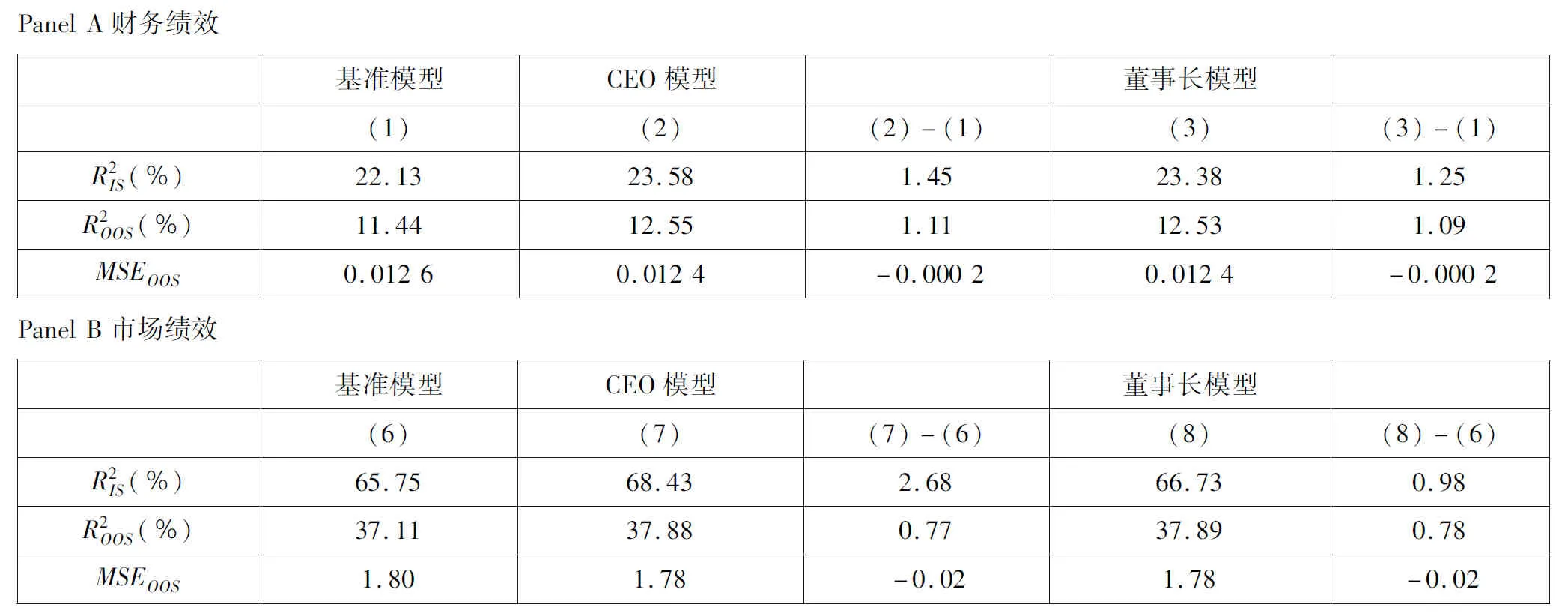
基准模型CEO模型董事长模型(1)(2)(2)-(1)(3)(3)-(1)R2IS(%)22.1323.581.4523.381.25R2OOS(%)11.4412.551.1112.531.09MSEOOS0.01260.0124-0.00020.0124-0.0002基准模型CEO模型董事长模型(6)(7)(7)-(6)(8)(8)-(6)R2IS(%)65.7568.432.6866.730.98R2OOS(%)37.1137.880.7737.890.78MSEOOS1.801.78-0.021.78-0.02
5.5 更换高管特征变量
在主要结果的CEO模型及董事长模型中, 高管个人特征大部分为虚拟变量.而回归树的方法可能会导致这些变量相对于连续型变量的预测能力较低.因此, 在原有一系列指标的基础上,将高管个人特征的虚拟变量转化为高管团队特征的连续变量.例如, 在CEO模型中, 以高管团队作为一个整体,将“是否有学术研究经历”转换为拥有学术研究经历的高管占高管总人数的比重.同理, 本文转换了其他虚拟变量, 包括是否在其他公司兼职、是否有生产、技术、设计职能经验, 是否有市场、战略、人力管理职能经验, 是否有财务、法律职能经验, 是否有海外工作、求学经历、是否有政府工作经历和是否有金融行业工作经历.董事长的个人特征也转化为董事会成员中拥有相应特征的成员占比.模型的拟合结果在表11中汇报.发现, 以特征指标的连续变量为预测指标的模型拟合效果有了一定提升, 比如在对财务绩效的预测中, Boosting-CEO模型相对基准模型的样本外提升效果从1.08变为1.47, 但仍然处于较低的水平, 这说明基本结论是稳健的.
表11 高管特征均值的拟合结果
Table 11 Fitting results on the mean value of executive features
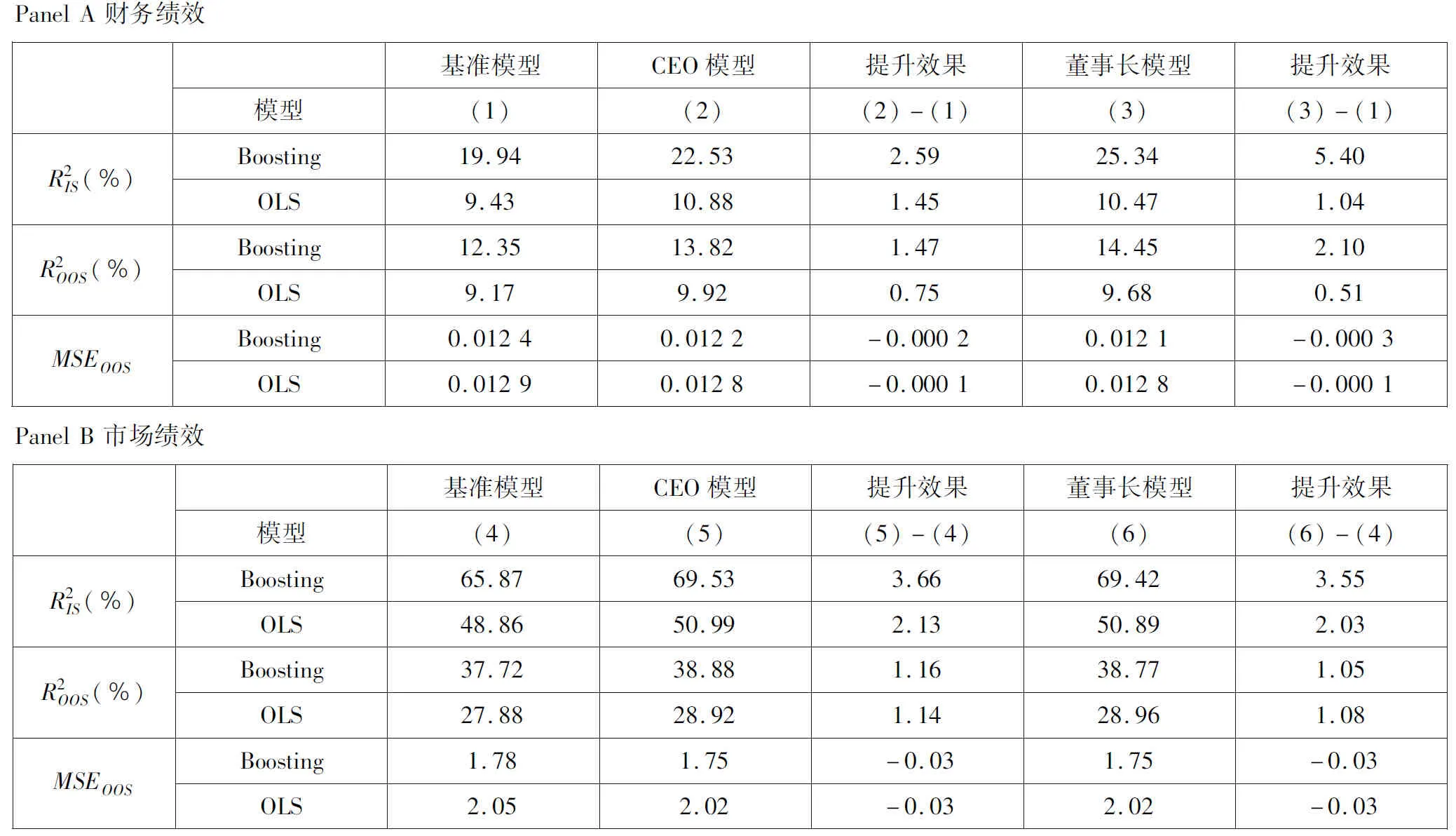
基准模型CEO模型提升效果董事长模型提升效果模型(1)(2)(2)-(1)(3)(3)-(1)R2IS(%)Boosting19.9422.532.5925.345.40OLS9.4310.881.4510.471.04R2OOS(%)Boosting12.3513.821.4714.452.10OLS9.179.920.759.680.51MSEOOSBoosting0.01240.0122-0.00020.0121-0.0003OLS0.01290.0128-0.00010.0128-0.0001基准模型CEO模型提升效果董事长模型提升效果模型(4)(5)(5)-(4)(6)(6)-(4)R2IS(%)Boosting65.8769.533.6669.423.55OLS48.8650.992.1350.892.03R2OOS(%)Boosting37.7238.881.1638.771.05OLS27.8828.921.1428.961.08MSEOOSBoosting1.781.75-0.031.75-0.03OLS2.052.02-0.032.02-0.03
6 结束语
以往高管特征研究大多仅研究单一特征与公司业绩之间的因果关联, 缺乏全面的高管特征分析, 特别是其对公司绩效的预测能力的分析.本文首次采用机器学习中的Boosting回归树算法全面考察了多维度的高管特征与公司业绩之间的关联.具体而言, 本文以我国2008年~2016年上市公司为样本, 总结了高管的高维特征变量, 研究了高管的个人特征是否能较大程度地预测公司业绩, 并进一步分析了对公司业绩预测程度较大的高管个人特征及其预测模式.研究发现: (1) 整体而言, 公司CEO和董事长的特征对公司业绩的预测力较弱; (2) 在众多高管个人特征之中, 高管持股比例和年龄对公司业绩的预测程度较高; (3) 高管持股比例和年龄与公司业绩之间的关联呈现出非线性的特点, 与以往的理论吻合.本研究不仅从一个更为全面的视角推进了中国高管特征与公司业绩关联的研究, 也对公司遴选高管和激励机制设计等提供了有益启发.
本文首次应用机器学习方法来研究中国的公司治理的问题, 评估了公司高管特征对于公司绩效的整体预测能力, 丰富了“公司高管特征与公司绩效之间关系”这一领域的文献.此外, 本文采用前沿的Boosting回归的方法规避了传统线性模型的缺陷, 更加适用于分析变量之间的非线性和交互关系.最后, 本文探究了不同公司高管特征对于预测公司绩效的重要程度, 并分析了相对重要的变量对公司绩效的作用效果, 这一系列结论对于选聘公司高管具有实践意义.
本文开启了中国高管特征研究的一个新的维度: 高维高管特征对公司绩效的预测能力.它对于深入理解中国高管在企业经营管理中所扮演的角色具有重要意义.基于机器学习方法和预测性模型, 未来仍有广阔的研究空间值得探索.首先, 机器学习方法能够利用非结构性数据来构建无法直接观测的变量 (比如高管的性格特点和行为等) , 从而挖掘在理论上尚未证实的重要高管特征, 丰富高管个人特征对公司绩效的影响以及公司治理方面的研究.第二, 除了公司绩效这一直接衡量公司表现的变量之外, 本文用类似的模型可以进一步探究中国高管特征对公司经营决策的预测能力, 从而丰富高管对公司的影响机制方面的研究.总体而言, 本文开拓了新的研究视角, 为后续研究奠定了基础.
