基于复值卷积神经网络样本精选的极化SAR图像弱监督分类方法
2020-07-13秦先祥余旺盛陈天平邹焕新
秦先祥 余旺盛 王 鹏 陈天平 邹焕新
①(空军工程大学信息与导航学院 西安 710077)
②(国防科技大学电子科学学院 长沙 410073)
1 引言
合成孔径雷达(Synthetic Aperture Radar,SAR)是一种主动式微波成像传感器,可以不受云雨等天气影响,全天时、全天候成像,能够获取地物或目标丰富的信息。与常规的单极化SAR相比,极化SAR能同时工作在多种极化收发组合下,信息获取能力更强,这使得极化SAR图像的应用倍受关注[1]。极化SAR图像分类是当前SAR图像解译领域的一个热点研究方向,在军事和民用领域都具有重要的应用价值。例如,在军事上可用于目标毁伤评估和态势理解等;在民用方面可用于城市规划、农作物生长监视、灾情评估和海洋开发评估等[2–5]。
根据是否采用标记的训练样本,极化SAR图像分类方法可以分为无监督[6–10]和监督[5,11–13]分类方法两大类。前者无需标注的训练样本,主要从数据自身特点出发,利用数据间的相似性实现数据的聚类划分,或根据极化分解方法将各像素划分为特定的散射机理类别。这类方法通常易于实现、自动化程度较高,但在实际中也面临诸多问题:例如类别数目难以有效确定,或者感兴趣的类别与散射机理类别不一致而难以满足实际需求等。相比之下,后者先获得标注的训练样本,这些样本不仅反映了用户对类别数目的要求,还蕴含了各指定类别的数据特点,从而能够更有针对性地训练分类器,分类精度往往更高,所得结果与具体应用需求也更为吻合。
近年来,随着深度学习理论与技术的发展,基于深度学习尤其是卷积神经网络(Convolutional Neural Network,CNN)的方法在极化SAR图像分类中受到大量关注,并展现出比很多传统分类方法明显更优的分类性能[14–19]。例如,为了发挥CNN优良的分类能力,文献[16]提出了一种基于CNN的以像素邻域为基本分类单元的极化SAR图像分类方法;为了能够直接处理极化SAR图像复数据,文献[17]研究了复值CNN(Complex-Valued CNN,CV-CNN)并应用于极化SAR图像分类;为了弥补CNN在小样本下性能的不足,文献[18]引入极化特征驱动CNN来实现极化SAR图像分类。目前,这些方法以监督分类方法为主,其性能的发挥通常需要大量标注训练样本作支撑,并且受样本的标注质量影响显著。实际中,与普通光学图像相比,极化SAR图像的视觉直观性较弱,其标注常需要丰富的经验或专业知识,因此要完成极化SAR图像的高质量标注非常费时费力,这很大程度上限制了监督方法尤其是基于深度学习的监督方法在极化SAR图像分类中的应用。
近年来,为减少监督方法对样本标注质量的依赖,弱监督分类方法受到了广泛关注[19–26]。与传统采用精细标注的监督(或称为全监督)分类方法不同,弱监督分类方法利用信息较“弱”的粗略标注的样本,但通过充分挖掘样本信息来弥补标注精度低带来的不良影响。弱监督分类中粗略标注样本的典型方法包括物体框标注、点标注、简笔画标注和图像级标注等[20,21]。相比于传统像素级精细标注方法,这些方法简单易行,实现效率高。
当前,弱监督分类方法在计算机视觉领域得到快速发展,提出了诸多解决方案:如文献[19]提出先利用目标识别预训练网络来获取物体掩膜的策略;文献[23]将弱监督标签作为隐变量来优化分类网络;文献[26]提出在条件随机场框架下结合显著性先验的方法等等。尽管如此,限于现实中相对有限的样本数据集,弱监督分类方法在SAR图像处理领域还处于初步探索阶段[27,28],发展相对滞后。鉴于此,本文针对采用物体框样本标注的极化SAR图像弱监督分类问题,研究了一种基于CV-CNN样本精选的极化SAR图像弱监督分类方法。基于3幅实测极化SAR图像的实验结果验证了本文方法的有效性。
2 极化SAR数据与复值卷积神经网络
2.1 极化SAR图像数据
对于常规单视极化SAR图像,每个像素可由一个Pauli散射矢量进行表示[1]
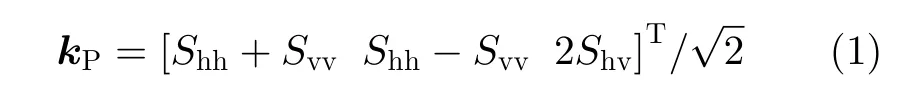
其中,上标 T表 示转置运算,h和v 分别表示水平和垂直极化,Shv表示水平极化发射垂直极化接收的散射分量,Shh和Svv的意义类似。为抑制相干斑噪声或压缩数据,极化SAR图像数据往往采用多视处理[1]。多视极化SAR图像的各像素可由一个极化相干矩阵进行表示[1]
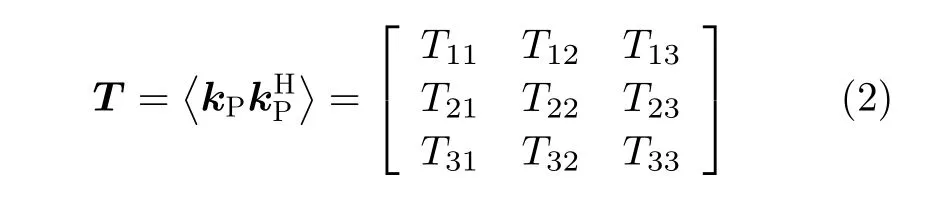
其中<·>表示取集平均运算,上标 H表示共轭转置运算。
2.2 复值卷积神经网络
CNN的结构通常由输入层、卷积层、池化层、全连接层和输出层组成[29]。常规CNN定义于实数域,其网络权重和网络中传递的数据均为实数。实际中很多数据如SAR图像为复数形式,这使得常规CNN不适合用于直接处理这些数据。为充分利用SAR图像中所蕴含的信息,如幅度和相位信息,文献[17]研究了CV-CNN并应用于极化SAR图像的分类。
CV-CNN可视为常规CNN从实数域到复数域的扩展,其网络参数均为复数,也允许网络的输入为复数形式,因此可以直接用于处理如极化SAR图像等复数据,更好地保留原始复数据所蕴含的信息。与常规CNN一样,CV-CNN通常也包括输入层、卷积层、池化层、全连接层和输出层等网络层。对于卷积层,其功能是实现输入复数据的卷积运算。设CV-CNN的第l层为卷积层,其有M(l)个输入特征图和N(l)个输出特征图,记其第m个输入特征图和第n个输出特征图分别为和,则有[17]
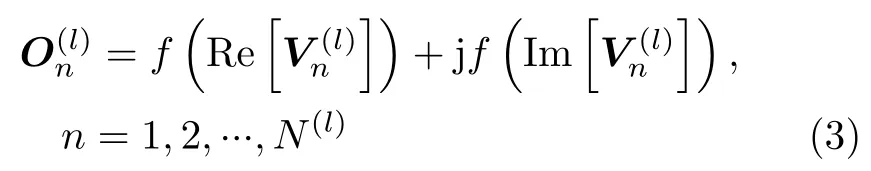
其中,j 为虚数单位,Re[·]和Im[·]分别表示求复数的实部和虚部,f(·)为一个非线性激活函数(本文中采用Sigmoid函数[29]),为一个中间量

池化层实现输入数据的降采样处理,其不仅能有效减小数据量,还可以增强特征的泛化能力。目前主要有最大值池化和平均值池化两类典型的池化方法(本文采用平均值池化方法[17,29])。全连接层将输入特征图的每个单元与输出的每个单元进行两两连接。若CV-CNN的第k层为全连接层,其有M(k)个输入单元和N(k)个输出单元,记其第m个输入单元和第n个输出单元的值分别为和,则有
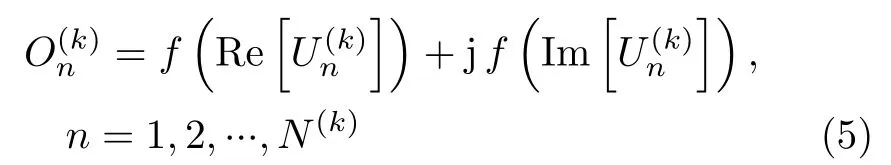
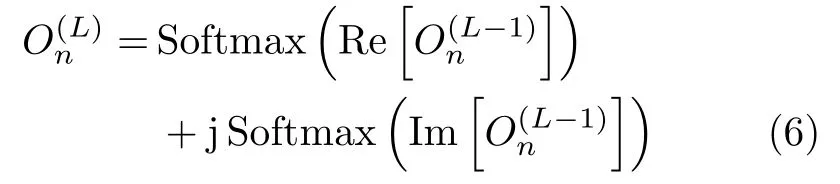
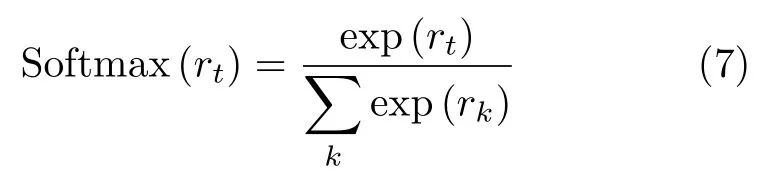
数据的真值向量采用独热编码形式[17]:设总的类别数为C,则第c类的数据是真值向量gc为一个C维复向量,其第c个元素为1+j,其余元素均为0,即
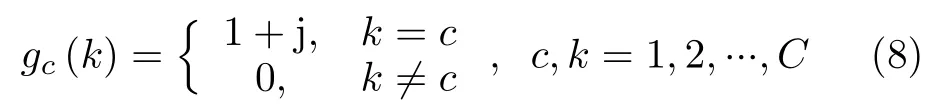
在输出层,通过计算输出向量O(L)与各个类别的真值向量之间的距离,将距离最小所对应的类别作为相应的输出类别
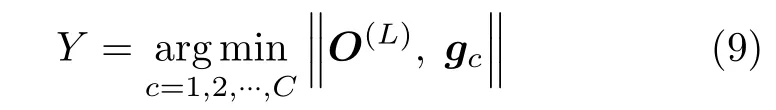

3 物体框样本标注
在传统全监督分类方法中,训练样本采用像素级标注,其精细地勾画出各个类别的分布区域。相比之下,弱监督分类方法只需要对样本数据进行粗略标注,其中典型的标注方法有物体框标注、点标注、简笔画标注和图像级标注等[20,21]。本文主要关注物体框标注的弱监督分类问题。为直观说明,图1给出了某极化SAR数据样本的像素级标注和物体框标注的对比示意图,其中图1(a)为一幅极化SAR数据样本的Pauli-RGB图像,图1(b)和图1(c)分别为该图像的像素级标注和物体框标注。对比可见,像素级标注对各类别的数据类别的空间分布进行了精细标注,而物体框标注对各类别仅框出了一个大致范围(通常为矩形区域),然后将整个区域的数据标记为相应类别。
像素级标注可以充分利用已有数据且信息的可靠性强,但显然,这种精细标注是十分费时费力的。相比之下,物体框标注实现简单,可以显著减少图像标注的时间,有利于快速构建规模较大的标注数据库,具有广泛的应用前景。然而,物体框标注的精度不高,所得标注数据中往往包含大量与标注类别不一致的数据,本文称之为异质成分。若直接将物体框标注样本用于分类器的训练,很可能会严重降低分类器性能,难以获得令人满意的分类结果。
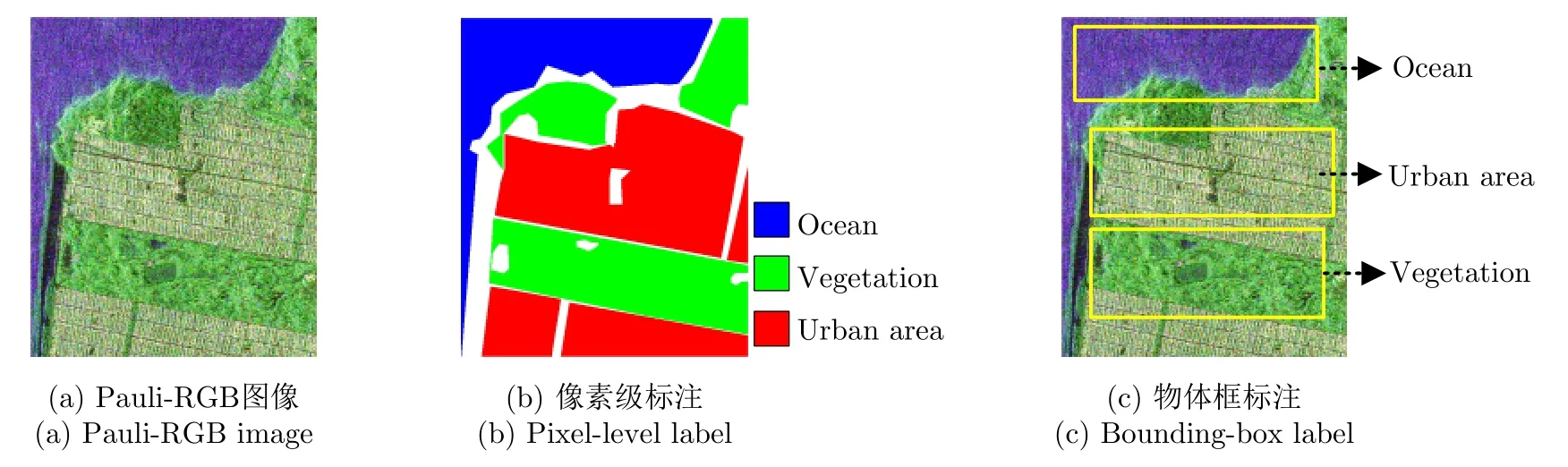
图1 极化SAR数据样本的像素级标注与物体框标注对比示意图Fig.1 Comparison illustration of pixel-level label and bounding-box label for a PolSAR data sample
4 基于样本精选的弱监督分类
针对物体框标注样本标注精度低的问题,本文提出一种基于CV-CNN样本精选的极化SAR图像弱监督分类方法。方法主要分两步,首先通过样本精选方法将物体框标注样本转换为像素级标注样本,然后采用传统全监督方法完成极化SAR图像的分类。
4.1 物体框标注样本精选
为了将物体框标注样本转换为像素级标注样本,本文的基本思路是从给定的物体框标注样本中剔除异质成分。本质而言,该过程是对给定标注样本的再分类,即通过判断给定样本的类别标签的正确性,精选出其中“标注正确”的样本。分析可知,尽管物体框标注比较粗略,但物体框内的样本主体通常具有正确的类标签,异质成分所占比例相对较少。因此,若先以标注的物体框内的像素样本作为像素级标注样本来训练某分类器,再用所得分类器对样本数据进行分类,当分类器性能较优时,有理由相信所得分类结果中包含很多被正确分类的样本数据。若能挑选出这部分数据,将之用于分类器的再训练,将会改善分类器的性能,进而获得更多被正确分类的样本数据。如此迭代反复,将有望剔除大部分异质成分,实现物体框标注样本数据的精选,获得类似于像素级标注的样本。图2给出了该物体框标注样本精选方法的基本流程图。
给定极化SAR图像物体框标注样本数据集,方法首先将各物体框的类别标签赋予到相应框内的每个像素,形成相应的伪像素级标注样本。若样本数据量较大,为提高算法效率,可通过均匀的随机采样来减少训练样本。接着,利用伪像素级标注样本训练给定的分类器,再用训练好的分类器对原始物体框标注样本数据集进行分类。接着采用一定的策略对物体框标注样本进行精选,从中选出“被正确分类”的样本并作为新的训练样本,然后返回训练样本的随机选取步骤。重复上述操作直到满足算法停止条件为止,如分类的迭代次数达到指定值或者分类结果变化率小于给定的阈值。该样本精选方法主要涉及到两方面问题,即分类器的选择以及判断样本被正确分类的策略。
鉴于CV-CNN的优良性能,本文在样本精选中引入该类网络作为分类器。本文采用文献[17]所给的CV-CNN模型,其网络结构如图3所示。该网络包括1个输入层、2个卷积层、1个池化层、1个全连接层和1个输出层。输入层的尺寸为12×12×6,其中12×12表示输入极化SAR图像区域块的大小,6表示输入数据的通道数,这里对应极化相干矩阵中的6个元素[T11T12T13T22T23T33];网络中第1和第2个卷积层所包含的卷积核的数目分别为9和12,各卷积核的大小均为3×3、步长为1;此外,池化层采用2×2的平均值池化,步长为2。
对样本的分类结果的正确性判断,本文通过对比样本原始标注的类别标签和分类器所得的类别标签来完成。对于某样本数据,若这两种标签一致,则认为其“被正确分类”而保留该样本,否则舍弃。显然,利用该方法所保留的样本中依然可能包含异质成分,但通过采用迭代精选的方式有望逐渐减小其所占比例。需要指出的是,通过多次迭代分类和样本精选后,本方法不仅可以将物体框标注样本转换为像素级标注样本,还同时训练出了一个可直接用于极化SAR图像分类的CV-CNN。
4.2 极化SAR图像弱监督分类流程
本文针对物体框标注样本的极化SAR图像弱监督分类方法的基本步骤如下:
步骤 1 CV-CNN分类器设计。本文直接采用文献[17]给定的CV-CNN作为分类器。
步骤 2 按照4.1节的方式迭代训练分类器并完成物体框标注样本转换为像素级标注样本,同时获得训练好的CV-CNN。
步骤 3 极化SAR图像分类。利用训练好的CV-CNN按照全监督分类方法方式完成极化SAR图像分类。对于待分类的极化SAR图像的各像素,选取以其为中心的邻域数据作为CV-CNN的输入,其中邻域大小与CV-CNN输入数据的尺寸保持一致[16,17]。CV-CNN输出结果即为相应像素的类别标签。
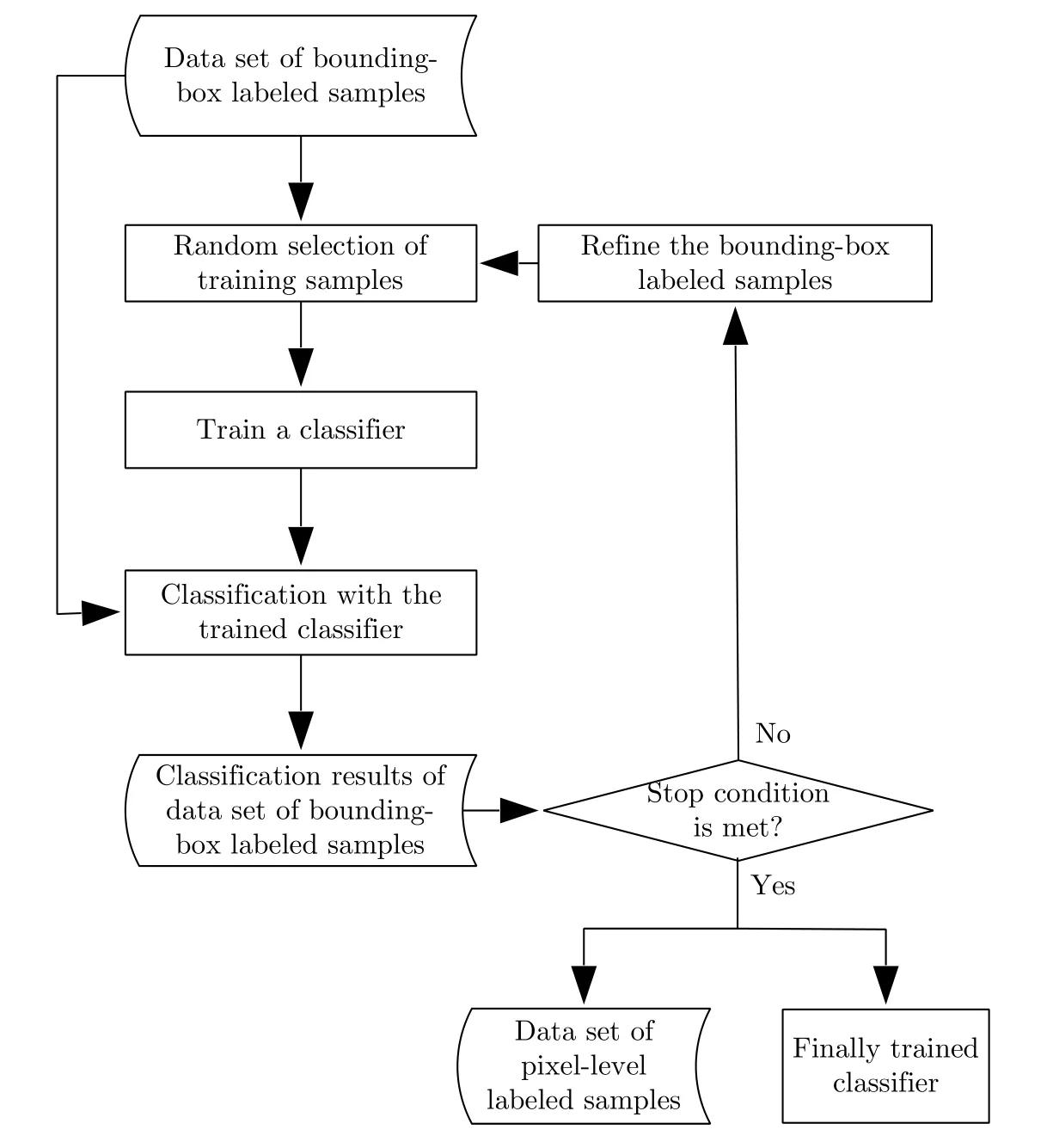
图2 物体框标注样本精选方法流程图Fig.2 Flowchart of refining method for bounding-box labelled samples
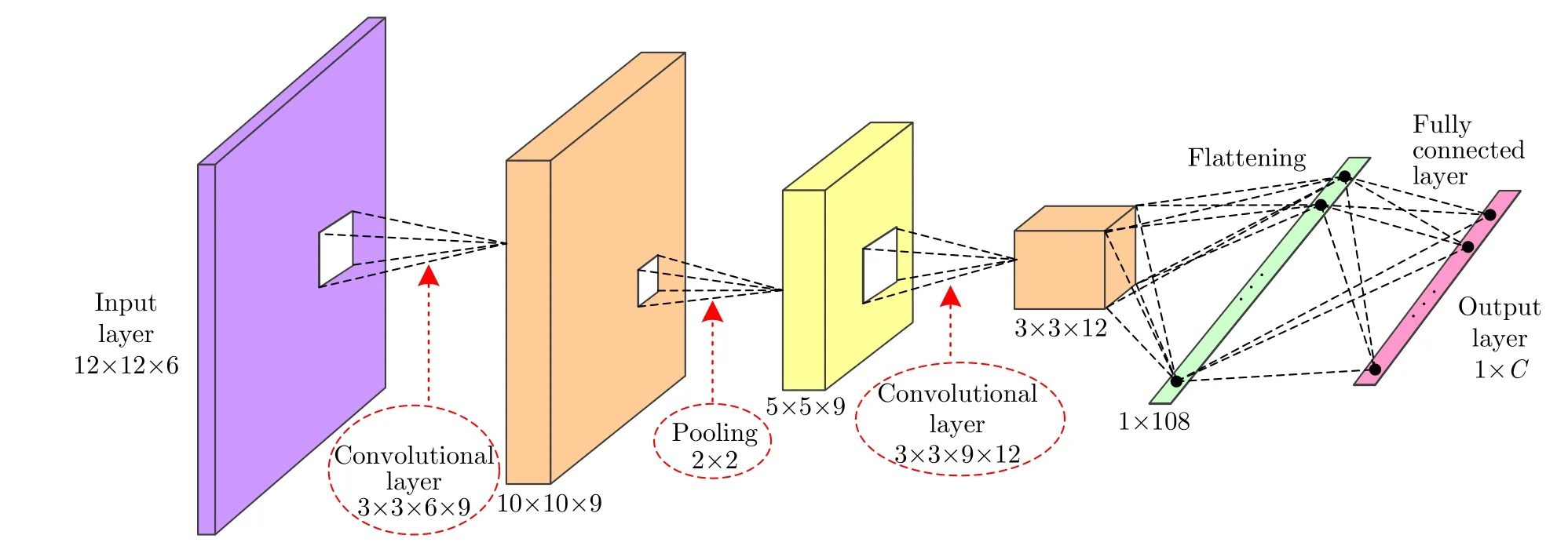
图3 CV-CNN的结构示意图Fig.3 Illustration of architecture of CV-CNN
5 实验结果与分析
5.1 实验数据说明
为验证方法的有效性,本文采用3幅实测极化SAR图像数据进行实验。第1幅实验图像为美国NASA/JPL的AIRSAR系统1990年获取的荷兰Flevoland地区的大小为750×1024像素的极化SAR图像数据,其包含15类典型地物,分别为蚕豆、豌豆、树林、苜蓿、小麦1、甜菜、土豆、裸地、草地、油菜籽、大麦、小麦2、小麦3、水域和建筑区[30]。该图像数据的Pauli-RGB图像和真值图分别如图4(a)和图4(b)所示。第2幅实验图像为美国NASA/JPL的UAVSAR系统2009年获取的美国墨西哥湾某地区的大小为1000×1000像素的极化SAR图像,其包含水域、植被、农田和建筑区四类典型地物。该数据的Pauli-RGB图像、参考光学图像和真值图分别如图5(a)—图5(c)所示。第3幅实验图像为我国高分三号卫星2017年获取的美国旧金山地区的大小为2000×2000像素的极化SAR图像,其包含水域、植被和城区3大类典型地物,其中城区因结构密度和建筑物朝向的不同还可细分为城区A,B和C 3种不同类别。图6(a)—图6(c) 分别给出了该数据的Pauli-RGB图像、参考光学图像以及真值图。需要指出的是,实验数据2和数据3的真值图是综合相应数据的Pauli-RGB图像和参考光学图像后通过手工标注获得,实验数据1因其获取时间较早,目前缺乏相近时间内该数据对应地区的光学图像,但其真值图已在很多文献中给出[30],可以直接用于本文算法性能的评估。
5.2 物体框标注样本精选实验结果与分析
为了验证本文物体框标注样本精选方法的有效性,本节采用上述3幅极化SAR图像进行实验。实验首先设计了一种自动构造物体框标注的弱监督样本的方法。对于每幅极化SAR图像,在图像中随机放置某个给定大小的矩形窗口,则窗口中通常包含一类或多类地物。根据给定的真值图进行判断,若窗口中某种类别的像素所占“数量比”(其像素数与窗口中的总像素之比)处于某个设定的范围,则选择该窗口内的数据作为一个物体框标注样本,其类别标注为窗口中像素数量最多的类别的标签。因此,该方法可以用于模拟标注人员在快速标注数据时获得的具有一定比例异质成分的物体框标注样本。
在本文实验中,矩形窗口尺寸的设置与地物在图中分布范围大小有关,对于实验数据1~3,窗口大小设置分别为30×30 像素、50×50 像素和80×80像素。在设置“数量比”范围时,实验中作如下假设:数据标注人员在获取物体框标注样本时,通过目视判别对某类地物框出一定范围(或指定物体框大小后直接选择中心点)来获得相应的训练样本,并将其标注为框中数量最多的像素对应的类别。本实验将该“数量比”的范围设为[0.5,0.8],其中比例下限值0.5意味着所标注的框内存在某一类别的像素占主体,而比例上限值0.8意味着要求物体框样本错误率不小于20%,从而较好地反映实际中物体框标注样本“信息较弱”的特点。需要说明的是,对于实验数据1的第15类地物即建筑物,因其分布在一个较小区域上而不利于选择满足上述条件的样本,故对该类别将数量比范围放宽到[0.3,0.8]。对于各实验数据,各类别选取了5个物体框标注样本,进而构建出各实验数据的物体框标注样本集。图7(a)、图8(a)和图9(a)分别给出这3幅极化SAR图像的所选样本集拼接而成的Pauli-RGB图像,图7(b)、图8(b)和图9(b)分别给出了相应的伪像素级标签图。可以看到,所选取的各类训练样本不同程度地包含了一些异质成分。以实验数据3为例,所选水域样本中包含了一些陆地区域,所选植被样本中包含了部分城区,所选城区内也包含部分植被区。因此,所选择的这些样本符合物体框标注样本的特点,可以用于评价本文的弱监督分类方法的性能。

图4 实验图像数据1Fig.4 Experimental image data 1
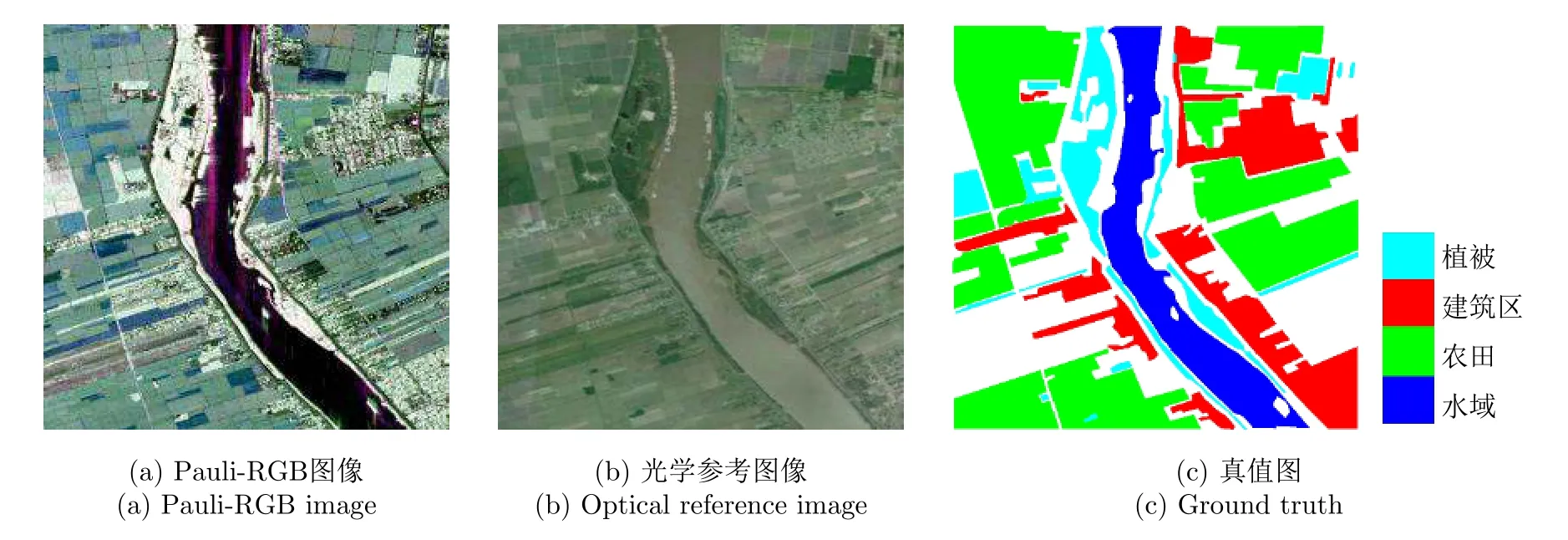
图5 实验图像数据2Fig.5 Experimental image data 2
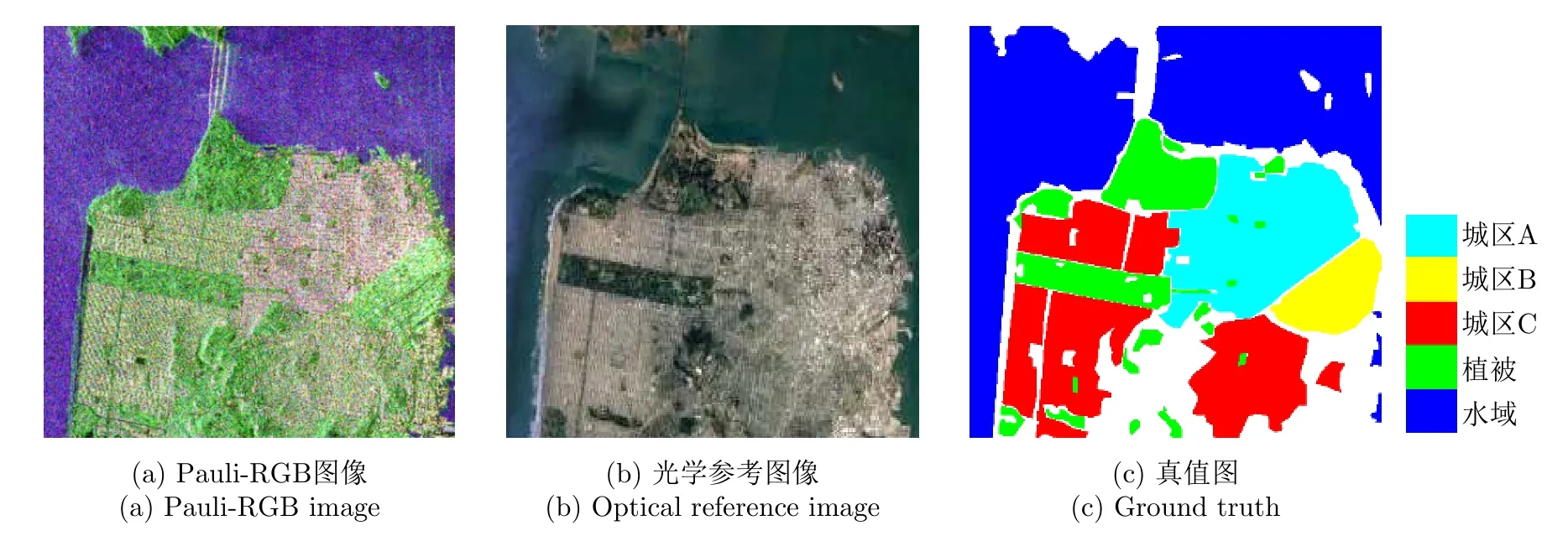
图6 实验图像数据3Fig.6 Experimental image data 3

图7 实验数据1的物体框标注样本集的Pauli-RGB图像及3种方法所得分类结果和精选像素级标签Fig.7 Pauli-RGB image of the bounding-box labelled sample set of experimental data 1 and its classification results and refined pixel-level labels with three methods
接着对各极化SAR图像数据依次训练CV-CNN模型。为提高算法效率,首先从给定样本集中对每类随机选取300个样本用于训练CV-CNN。训练采用随机梯度下降法[17,29]进行,其中训练的超参数设置如下:学习率为0.5,样本批量大小batchsize为100,训练迭代数epoch为50。此外,算法的停止条件包含2个参数,即最大分类迭代次数和分类结果变化率阈值。通常,随着迭代次数的增加,样本精选中分类结果逐渐趋于稳定。本实验中根据经验将该最大迭代次数设为10,在样本精选结果基本趋于稳定的同时,可避免算法过多的运算以及算法不收敛时带来的死循环问题。另外,实验中分类结果变化率阈值设为0.01,即当相邻两次迭代中的分类结果的变化率小于1%时,认为样本精选结果已经足够稳定,则停止算法迭代。最后,采用本文样本精选方法即可获得各样本集的分类结果和相应的像素级标签图像。图7(c)给出了采用CV-CNN获得的实验数据1样本集的最终分类结果,图7(d)给出了相应的精选样本像素级标签,其中白色区域表示未标注区域,对应被剔除的样本,其他颜色对应不同的类别。类似地,图8(c)和图9(c)分别给出了采用CV-CNN获得的实验数据2和数据3的样本集的最终分类结果,图8(d)和图9(d)分别给出了相应的精选样本像素级标签图像。
此外,为了分析本文样本精选方法中采用CV-CNN的性能,实验中还采用了经典的Wishart分类器和支持矢量机(Support Vector Machine,SVM)进行比较,即在相同的框架中分别用这两种分类器替换CV-CNN进行样本精选。Wishart分类器先利用训练样本计算各类别的类心,然后根据最小Wishart距离[1]准则实现极化SAR图像各像素的分类;SVM基于LibSVM软件[31]完成,其中模型参数采用该软件分类模块的默认参数,极化SAR图像各像素由极化相干矩阵的6个元素构成的矢量表示F=[T11T12T13T22T23T33]。采用这两种分类器的样本精选方法对3幅实验图像的物体框标注样本进行处理,所得的最终分类结果和精选后的像素级标签图分别如图7(e)—图7(h)、图8(e)—图8(h)和图9(e)—图9(h)所示。

图8 实验数据2的物体框标注样本集的Pauli-RGB图像及3种方法所得分类结果和精选像素级标签Fig.8 Pauli-RGB image of the bounding-box labelled sample set of experimental data 2 and its classification results and refined pixel-level labels with three methods

图9 实验数据3的物体框标注样本集的Pauli-RGB图像及3种方法所得分类结果和精选像素级标签Fig.9 Pauli-RGB image of the bounding-box labelled sample set of experimental data 3 and its classification results and refined pixel-level labels with three methods
对比图7—图9中各样本集的Pauli-RGB图像与精选的像素级标签图可见,3种采用不同分类器的样本精选方法能不同程度地剔除异质成分,获得相对可靠的像素级标注样本。分析可知,Wishart分类器采用最小Wishart距离准则,其性能与各类别的类心估计准确度密切相关,故相应的样本精选方法对异质成分较为敏感。例如数据2的样本集中,水域样本包含部分数值较大的异质成分(如图8(a)第3列的白色区域所示),使得该类别的类心估计值发生了明显偏离,进而使得大部分水域样本被错分为农田(如图8(c)所示),相应精选的样本则明显不可靠(如图8(d)所示)。与该方法相比,采用SVM的样本精选方法性能略优,但对部分样本精选结果不佳,例如将数据1的草地(类别9)几乎错分。此外,这两种对比方法受相干斑噪声影响明显,并对自身起伏较大的类别(如城区)难以得到较好的分类结果和样本精选结果。相比之下,CV-CNN具有较优的分类性能,基于该网络的样本精选方法能够更有效地剔除异质成分,对自身起伏较大的类别依然可以得到可靠性高的像素级标注样本。
此外,以实验数据1训练样本集的样本精选为例,图10给出了基于前述3种不同分类器的样本精选方法所得分类结果的变化率关于迭代次数的变化曲线。可以看到,对于该数据而言,3种基于不同分类器的算法在前5次迭代时所得样本分类结果的变化率较大,随后渐趋于稳定。由于这些分类结果变化率均大于所设定的阈值0.01,因此这些算法均在迭代次数达到设定的最大值时才停止。实际中可以根据具体应用需求对算法停止条件参数进行调整,如更侧重于算法的分类性能而非效率时,可以设置较大的最大迭代次数和较小的分类结果变化率阈值;反之则可减小最大迭代次数和分类变化率阈值。
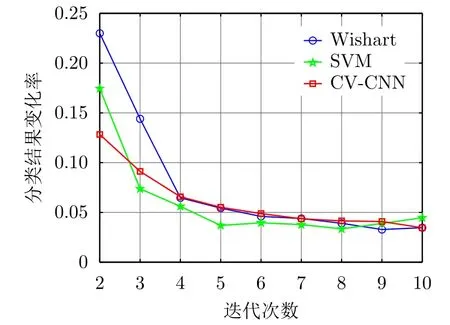
图10 实验数据1训练样本集的分类结果变化率曲线Fig.10 Curves of change rate of classification results on training set of experimental data 1
5.3 极化SAR图像分类结果与分析
为了分析给定物体框标注样本条件下本文的弱监督分类方法的性能,本节采用全监督分类方法进行对比实验。为公平比较,全监督方法与弱监督方法采用同一个分类器,它们的唯一区别在于全监督方法在训练分类器时所用训练样本为原始物体框标注对应的伪像素级标注样本,而弱监督方法采用经过本文样本精选方法获得的像素级标注样本。为了分析其中分类器的影响,实验中采用了CV-CNN、Wishart分类器和SVM 3种不同分类器进行对比。
图11给出了相同物体框标注样本条件下,基于不同分类器的全监督和弱监督方法对实验数据1的分类结果,其中图11(a)—图11(c)分别为采用CV-CNN、Wishart分类器和SVM的全监督方法对实验数据1的分类结果,图11(d)—图11(f)分别为相应的弱监督方法对该数据的分类结果。类似地,图12和图13分别给出了各分类方法对实验数据2和数据3的分类结果。为了定量评估分类结果,表1—表3分别给出了采用不同方法所得的3幅实验图像各类别的分类精度,总体精度和Kappa系数[32]的值,其值越大,通常表明相应的分类结果越好。

图11 实验数据1的全监督和弱监督分类结果Fig.11 Classification results of experimental data 1 by fully-supervised and proposed weakly-supervised methods

图12 实验数据2的全监督和弱监督分类结果Fig.12 Classification results of experimental data 2 by fully-supervised and proposed weakly-supervised methods

图13 实验数据3的全监督和弱监督分类结果Fig.13 Classification results of experimental data 3 by fully-supervised and proposed weakly-supervised methods
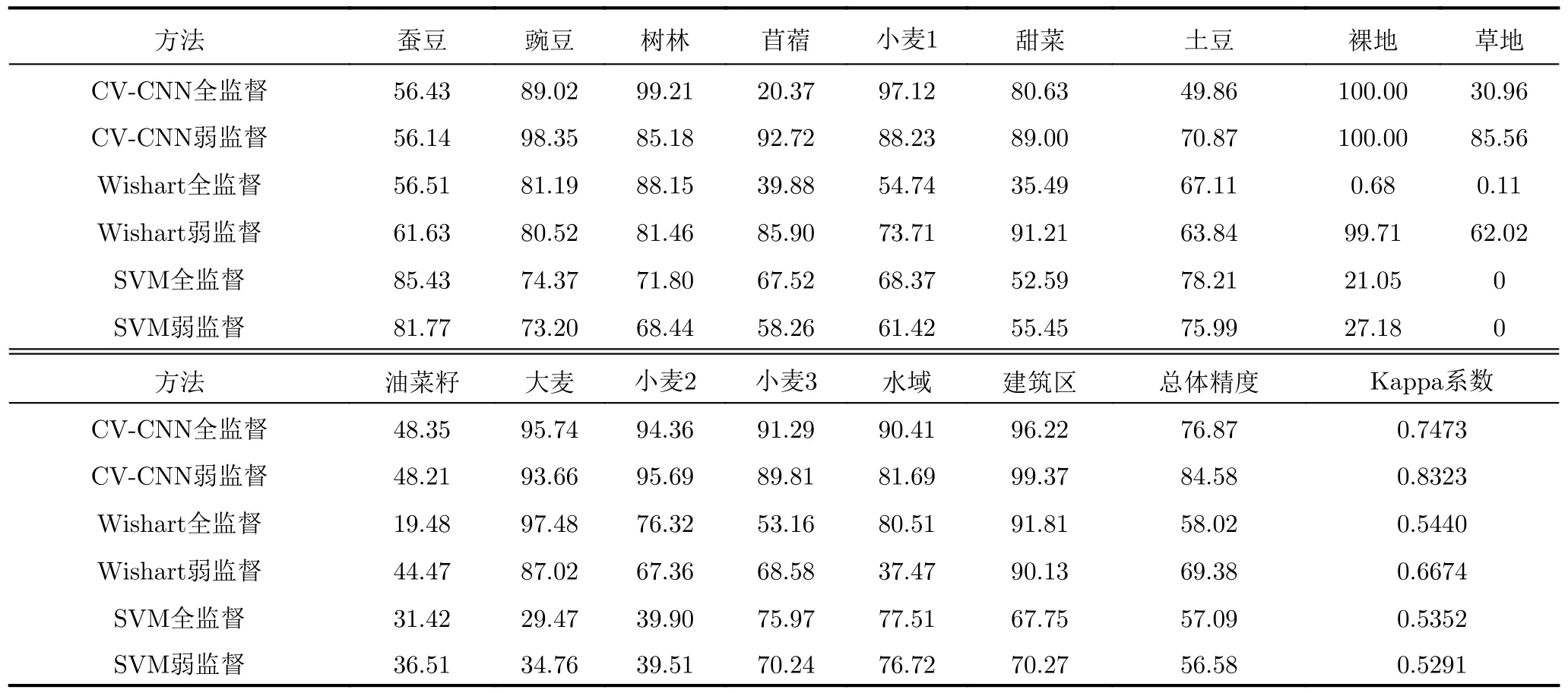
表1 实验数据1的分类精度(%)、总体精度(%)和Kappa系数Tab.1 Classification accuracy (%),overall accuracy (%) and Kappa coefficient for experimental data 1
由图11—图13和表1—表3可见,本文提出的极化SAR图像弱监督分类方法与所用分类器的性能密切相关。在相同的分类方法框架下,采用CV-CNN所得分类结果明显优于采用Wishart分类器和SVM的方法所得分类结果,总体分类精度和Kappa系数的值均明显增大。这是由于CV-CNN本身具有更优的分类性能,可以更好地精选训练样本,并更优地对极化SAR图像数据分类。值得注意的是,当分类器性能不佳,将使得样本精选不可靠时,采用本文的弱监督方法所得结果甚至可能不及直接采用物体框标注样本的全监督分类方法所得结果,例如对于数据2,采用Wishart分类器的弱监督分类方法的总体分类精度仅为34.54%,小于相应全监督方法所得的36.36%。对于该数据,采用SVM也有类似结果。
详细分析采用CV-CNN的方法所得结果可见,对于实验数据1的一些类别,直接应用物体框标注样本的全监督方法出现了比较明显错分,如苜蓿类和草地类的分类精度仅为20.37%和30.96%,分类的总体精度和Kappa系数分别仅为76.87%和0.7473。相比之下,采用本文精选样本的弱监督分类方法所得结果得到了较明显的改善,如苜蓿类和草地类的分类精度分别提高为92.72%和85.56%。整体分类结果与真值图更为接近,总体精度和Kappa系数值分别提升为84.58%和0.8323。此外,从图12、图13和表2、表3中可以看到,对实验数据2和数据3的分类也有类似的结果。例如,对于实验数据2,全监督方法对植被和水域的分类精度较高,均超过90%,但对农田尤其是建筑区的分类结果较差,建筑区的分类精度仅为64.91%。相比之下,本文弱监督方法对植被和水域的分类精度与全监督分类方法所得结果相当,但对农田的分类精度由82.42%提升到93.34%,对建筑区的分类精度由64.91%提升到75.88%,均提升10%左右。整体而言,分类的总体精度约提升了8%,Kappa系数提高超过0.1。对于实验数据3,全监督方法对水域、植被和城区B和城区C的分类结果较好,但不能有效区分城区A和城区C,将大部分城区A像素错分为城区C像素。城区A的分类精度仅为7.55%,而总体分类精度和Kappa系数分别仅为74.56%和0.6466。相比之下,本文弱监督方法能够有效地区分不同类别,所得分类结果与真值图较为接近,所得各类别的分类精度均超过80%,总体精度达到了91.05%,Kappa系数为0.8731,明显高于全监督方法所得的结果。上述实验结果表明,物体框标注样本中的异质成分严重影响了全监督分类方法的性能,而本文弱监督分类方法通过样本精选有效地减小了异质成分的不良影响,能够获得明显更优的分类结果。
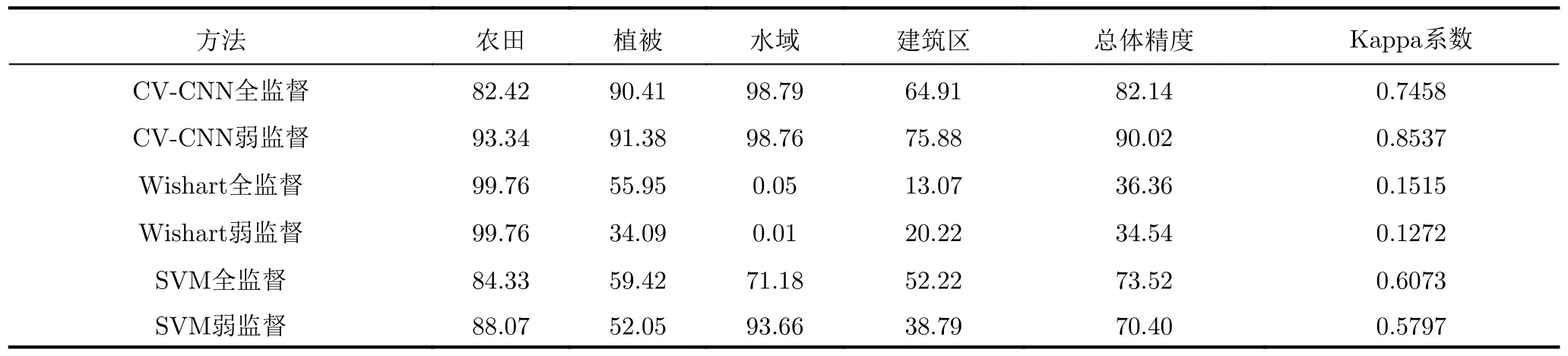
表2 实验数据2的分类精度(%)、总体精度(%)和Kappa系数Tab.2 Classification accuracy (%),overall accuracy (%) and Kappa coefficient for experimental data 2
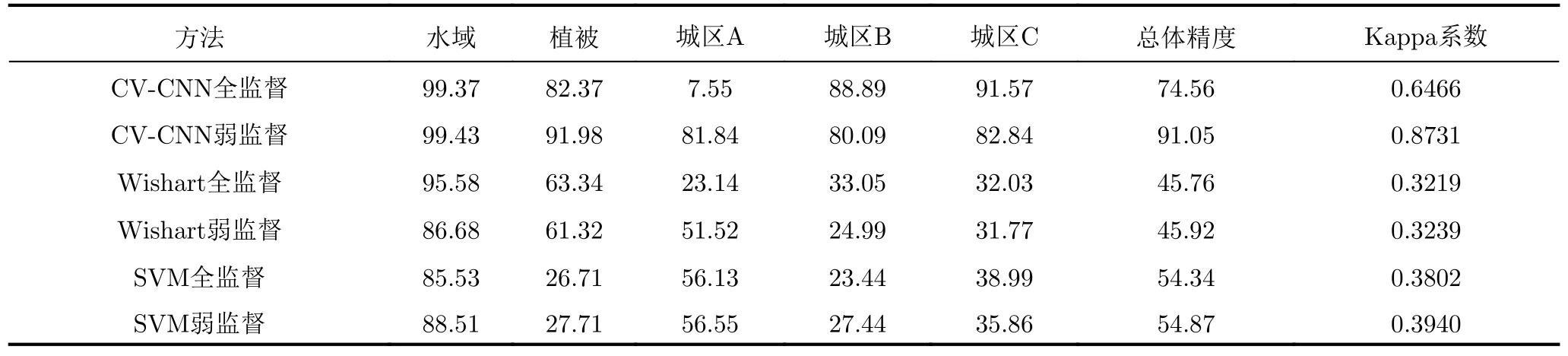
表3 实验数据3的分类精度(%)、总体精度(%)和Kappa系数Tab.3 Classification accuracy (%),overall accuracy (%) and Kappa coefficient for experimental data 3
6 结束语
针对物体框标注样本包含异质成分而影响监督分类方法性能的问题,本文提出了一种基于CV-CNN样本精选的极化SAR图像弱监督分类方法。首先基于CV-CNN迭代分类策略剔除原始物体框标注样本中的异质成分,并同时训练出可用于分类的CV-CNN,然后所得CV-CNN完成极化SAR图像分类。通过3幅实测极化SAR图像进行实验,结果表明,本文方法能够有效剔除样本中的异质成分,所得结果明显优于采用原始样本训练的CV-CNN所得结果。此外,在样本精选中采用CV-CNN方法性能明显优于采用经典的Wishart分类器和SVM。后续工作可考虑进一步优化CV-CNN或采用性能更优的其他分类器来代替CV-CNN。
