基于Spark Streaming实时推荐系统的研究与设计∗
2020-07-13宇周
刘 宇周 虎
(1.南京烽火星空通信发展有限公司 南京 210000)(2.武汉邮电科学研究院 武汉 430074)
1 引言
随着电子商务的高速发展和普及应用,个性化推荐的推荐系统已成为一个重要研究领域。个性化推荐算法是推荐系统中最核心的技术,在很大程度上决定了电子商务推荐系统性能的优劣,决定着是否能够推荐用户真正感兴趣的信息,而面对用户不断提升的需求,推荐系统不仅需要正确的推荐,还要实时地根据用户的行为进行分析并推荐最新的结果。实时推荐系统的任务就是为每个用户实时地、精准地推送个性化的服务,甚至到达让用户体会到推荐系统比他们更了解自己的感觉。
2 现状
推荐系统要处理的数据量是巨大的。为了快速满足用户对消息的需求,推荐系统必须有大数据处理能力。第一代大数据处理框架Hadoop以前一直被国内外推荐系统作为解决方案,但是随着推荐算法的进步,Hadoop的Map Reduce计算模型已经难以满足性能要求。大数据下基于Hadoop平台构建的推荐系统存在着计算缓慢,不能快速地处理数据,不适合实时计算、多次迭代训练协同过滤算法模型,无法根据用户实时行为作出推荐的问题[6]。针对以上问题,本文设计和实现基于Spark平台的实时推荐系统。
3 系统架构
本文采用Kafka作为消息的订阅-发布,用Spark Streaming做实时计算,不断从Kafka消费数据,训练模型,做出推荐,推荐的结果存放在HDFS中。其次在统一数据源的基础上,采用基于Spark的矩阵分解推荐模型进行离线训练,提升离线推荐训练的效率;进而在离线推荐的基础上,提出一种使用Spark Streaming实时流技术对数据进行处理,并将离线推荐结果与实时推荐结果通过统一介质融合的方案,实现对用户隐式行为进行实时推荐反馈的功能[7]。 系统架构图1。

图1 系统设计流程图
4 Spark Streaming内存分配不均问题分析及解决
Spark基于内存计算,适合迭代,计算速度快,但是其数据量大的时候经常存在数据倾斜、任务卡住的问题。Spark Shuffle数据混洗、网络间数据传输较慢,是影响大数据集群性能的重要指标[8]。
Spark静态内存管理机制下,储存内存、Shuffle内存和Unroll内存三部分,储存内存和执行内存共享一块空间,可以动态占用对方的空闲区域,但用户可以在应用程序启动前进行配置[15],为了避免内存溢出一般只使用90%,通过Spark.storage.safety Fraction控制[9]。Spark将要处理的数据储存在Stor⁃age部分,这个部分占Safe的60%,通过Spark.stor⁃age.memory Fraction控制。Shuffle可用的内存大小占Safe的20%,由spark.shuffle.menory控制,Unroll menory用作数据的序列化和反序列化,由spark.storage.unroll Fraction控制,占Safe得的20%[10]。内存分配如图2。

图2 Spark内存分配
Spark自身的Shuffle内存分配算法试图为内存池中每一个Stage中的每一个Task平均分配内存,但是在实验中发现,由于各Stage中Task大小不一样对于内存需求的不同导致了内存的不足和浪费,使Spark集群运行效率较低、卡顿、卡住等问题。针对上述问题,根据应用中的实际情况,本文采用了一种根据Task大小和内存溢出情况,分多级应用来拆分一个应用,尽量使任务大小相近的在一个应用中,这样有效地避免内存分配不足和浪费的情况[14]。
5 基于矩阵分解的协同过滤算法-ALS
基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
对于一个users-products-rating的评分数据集,ALS会建立一个userproduct的mn的矩阵(其中,m为users的数量,n为products的数量)[2],如图3。

图3 评分数据集
这个矩阵的每一行代表一个用户(u1,u2,…,u9)、每一列代表一个产品(v1,v2,…,v9)。用户隔天产品的打分在1~9之间。但是在这个数据集中,并不是每个用户都对每个产品进行过评分,所以这个矩阵往往是稀疏的[3],用户i对产品j的评分往往是空的。ALS所做的事情就是将这个稀疏矩阵通过一定的规律填满,这样就可以从矩阵中得到任意一个user对任意一个product的评分,ALS填充的评分项也称为用户i对产品j的预测得分。
ALS算法的核心就是将稀疏评分矩阵分解为用户特征向量矩阵和产品特征向量矩阵的乘积交替使用最小二乘法逐步计算用户/产品特征向量[13],使得差平方和最小,通过用户/产品特征向量的矩阵来预测某个用户对某个产品的评分[11]。
最小交替二乘法确定特征值原理如下:
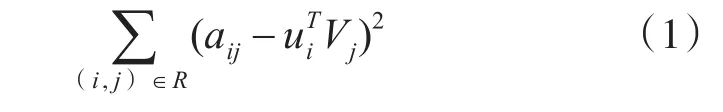
在式(1)中,a表示评分数据集中用户i对产品j的真实评分,另外一部分表示用户i的特征向量(转置)产品j的特征向量(这里可以得到预测的i对j的评分)用真实评分减去预测评分然后求平方,对下一个用户,下一个产品进行相同的计算,将所有结果累加起来[4]。
但是这里之前问题还是存在,就是用户和产品的特征向量都是未知的,这个式子存在两个未知变量,解决的办法是交替的最小二乘法。首先对于上面的公式,定义为式(2):
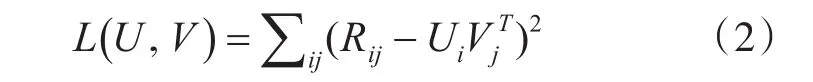
为了防止过度拟合,加上正则化参数:
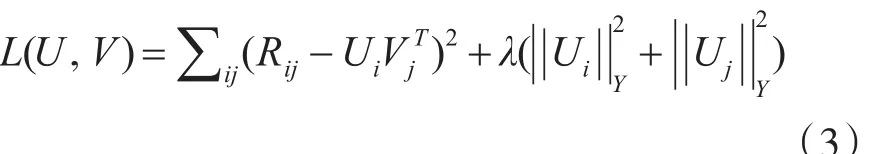

式中I表示一个d*d的单位矩阵[12]。
首先用一个小于1的随机数初始化V根据式(4)求U,此时就可以得到初始的UV矩阵了,计算上面说过的差平方和根据计算得到的U和式(5),重新计算并覆盖V,计算差平方和,反复进行以上两步的计算,直到差平方和小于一个预设的数,或者迭代次数满足要求则停止,取得最新的UV矩阵,则原本的稀疏矩阵R就可以用R=U(V)T来表示了[5]。
6 环境部署
本文中搭建的实时推荐系统采用三台Linux服务器,其中一个Master节点和两个Worker节点,系统为Centos6.5,具体参数如图4。

图4 环境参数
7 实验结果
本实验采用的是Movie Lens数据集(数据集含有来自6000名用户对4000部电影的100万条评分数据)。
测试部分:测试最佳的参数,如隐性因子个数,正则等,测试在Spark Streaming框架上算法的可用性。将整个数据集上传至HDFS中,在spark程序中读取ratings.dat文件,并随机划出80%作为训练数据集,20%作为测试数据集,置隐性因子、正则式参数列表(由于物理机配置不好,集群能够支持的最大迭代次数只有7次,再多就会内存溢出,所以这里直接将迭代次数设置为7),对参数列表的全排列分别进行模型训练,并计算MSE、RMSE,结果如图5。

图5 Spark实时推荐结果
从Kafka消费数据,实时训练协同过滤模型,实时的进行推荐结果如图6。

图6 实时推荐的MSE的值
实验验证:根据表1实验推荐结果可以得出本Spark实时推荐系统可以正确地进行推荐,准确率MSE提升0.025(与参考文献[12]相比),根据图5可以得出结论随着实时推荐的进行,实时训练批次增加,准确率提升。
8 结语
本文研究基于Spark Streaming实时推荐系统的设计与实现和协同过滤算法,Spark基于内存计算,适合迭代可以满足实时性要求,在Spark Streaming框架中加入协同过滤推荐算法,可以完成实时、动态的推荐。但是基于Spark的实时推荐还有很多工作要做:1)优化Spark内存分配策略,使内存可以按照需求动态分配等。2)找到一种能自动选择最优参数的方式。3)优化Spark数据倾斜问题。
