基于深度学习的多目标识别在移动智能体中的应用∗
2020-07-13陈浩刘镇
陈浩 刘镇
(江苏科技大学计算机学院 镇江 212000)
1 引言
在计算机视觉研究领域中多目标识别技术一直是一个热门研究方向。在现有的目标检测技术方面如人脸检测、行人检测等已经有了非常成熟的应用方案。传统的基于卷积神经网络的目标检测技术都会使用到滑动窗口,例如R-CNN、Fast-RCNN、Faster-RCNN方法[1~3]。但这些方法难以满足基于视频的移动智能体的多目标实时检测。由于滑动窗口弱实时性的缺点,研究者又提出了基于感兴趣区域(Region of Interesting)的区域提名算法[4]。并且由于CNN在困难的识别任务中表现出的卓越性能,因此常被应用在检测任务的FE和CV阶段。虽然相比于滑动窗口法,基于该方法的视频实时检测速度大幅度提升。但目前性能最好的Faster R-CNN算法的检测速度也仅达到5f/s,仍然不能够满足移动智能体的实时性需求。
直到 YOLO、SSD[5~7]的提出从另一个思维角度解决了候选区域选择的问题,从此目标检测的精确度和速度进入一个新的不同高度的研究领域。本文根据卷积神经网络在计算机视觉领域的研究,对部署在轻量级移动智能体上的YOLO网络结构进行优化,在实施环境中对该优化方法进行真实测试,测验结果表明优化后的YOLO网络结构在移动智能体多目标识别方面能够提供较高的检测准确度且检测计算速度保证了在轻量级移动智能体端的实时性要求。
移动智能体的目标识别对准确率和实时性都有较高要求。而现有检测方法大多数都是基于图片的目标检测,虽然能够保证准确率,但检测速度达不到视频检测的需求。由于YOLO算法具有强实时性和高准确率,因此运YOLO算法能够解决实时性问题[8]。
2 识别方法
基于YOLO网络的检测方法将候选框提取、特征提取、目标分类、目标定位统一于一个神经网络中。神经网络[9]直接从图像中提取候选区域,通过整幅图像特征来预测行人位置和概率。将行人检测问题转化为回归问题,真正实现端到端的检测。
本文中的多目标识别主要是对移动智能体运动过程中采集的实时视频,首先进行候选框提取,判断其中是否包含障碍物,若有则给出目标位置。实际上,大部分的初始候选框中并不包含障碍物,如果对每个初始候选框都直接预测目标的概率,会大大增加网络学习的难度。在本文的识别方法中,将多目标识别分为3个过程,即初始候选框的提取、待测目标检测、目标障碍物检测与定位。在待测目标检测的过程中,将部分无障碍物体预测框的置信度置为0,以降低网络学习的难度。
2.1 初始候选框的提取
将输入的图像划分为N×N个单元格,每个单元格给定M个不同规格的初始候选框,预测候选框经由卷积层网络提取出来,每幅图像候选框数量为N×N×M 。
2.2 待测目标检测
首先对候选框进行目标检测,如式(1),预测每个候选框的中存在待判别目标的置信度Conf(target),将不存在目标物的候选框置信度置为0。
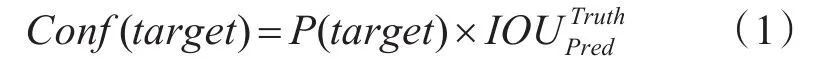
P(target)表示是否有目标物落入候选框对应的单元格中。如式(2),若有目标,则单元格对应的候选框的目标置信度为Conf(target)=;否则,认定候选框中没有目标障碍物,即Conf(target)=0。


2.3 目标障碍物检测与定位
对存在目标障碍物的候选框进行目标判别,设预测目标物是某一类障碍物的条件概率为P(class|target),则候选框中包含该类障碍物的置信度Conf 如式(4):

对每个候选框预测其中包含该类障碍物的概率以及边框的位置,则每个候选框的预测值如式(5):

其中X、Y为预测框中心相对于单元格边界的偏移,W、H为预测框宽高相对于整幅图像之比。实际训练过程中,W和H的值使用图像的宽度和高度进行归一化到[0,1]区间内。对于输入的每幅图片,最终网络输出为向量如式(6):
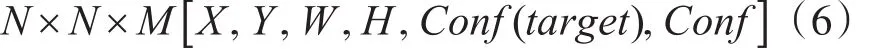
3 改进网络架构
3.1 架构改进分析
由于考虑到实际移动智能体的拍摄角度以及应用场景,经过分析与观察,横向的小目标的精确识别至关重要,需要确保不能漏检,否则会出现行动判断错误的风险。在经典的YOLO检测方法中,图像被分成S×S的等密度单元格。候选框在横向和纵向上同等密度分布,对横向小目标进行检测时,漏检率较高。实际上,在移动过程中对障碍物的检测一定要对横向可能存在的障碍物进行准确检测,而且具有横向类别分布密度大,但纵向类别分布密度小的特征。
针对这一问题,本文网络以YOLO网络为原型,经过改进去掉全连接层,采用卷积层来预测目标框的偏移和置信度。对特征图中的每个位置预测这些偏移和置信度,以得到目标的概率和位置。并且提出在网络中增加一个Recombine层,重组特征图,为提高对小目标的检测,融合多级特征图,让不同细粒度的特征参与目标检测。并在原有网络架构基础上增加候选框在横向的密度,同时也减少了纵向候选框密度,构成改进后的YOLO网络(如图1所示)。
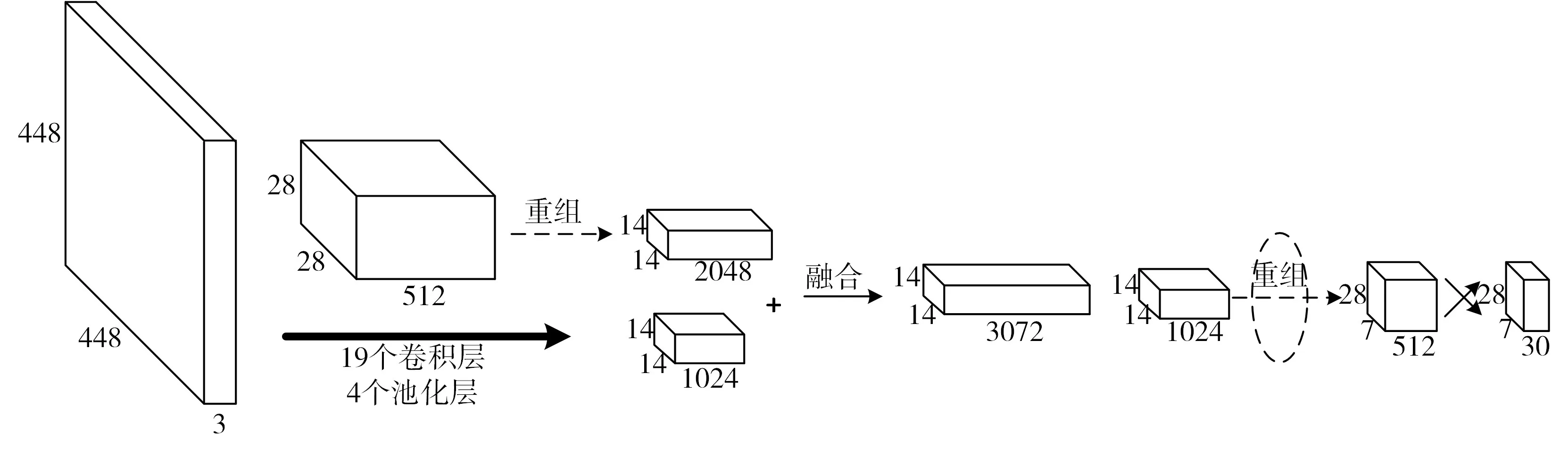
图1 改进后的网络架构图
3.2 最优初始候选框
由于在训练网络时,需要对初始候选框的初始规格及数量进行预设。随着迭代次数的不断增加,网络学习到目标特征,预测框参数不断调整,最终接近真实框。为加快训练收敛速度,提高目标识别的位置精度,本文采用K-means算法进行聚类[10~11],得到与图像中待测目标边界最相近的初始候选框参数。
定义box[i]表示聚类得到的预测框i的规格,Truth[j]表示样本j中目标物定位框规格,如式(7),其中,i为聚类的类别数,j为样本集数量。规格在数值上表示为一组数值(预测框宽/图像宽,预测框高/图像高):
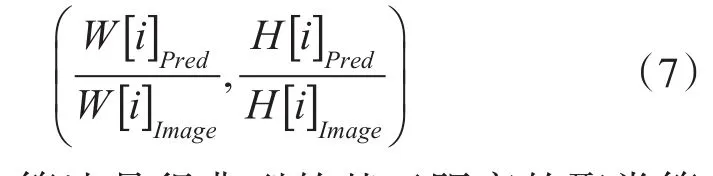
K-means算法是很典型的基于距离的聚类算法,该方法采用欧式距离衡量两点之间的距离。本文对候选框宽高与单元格宽高之比进行聚类。预测框和真实框的交并比是反映预测框与真实框差异的重要指标,IOU值越大,表明两者差异越小。聚类的目标函数如式(8):

3.3 网络训练
网络训练以神经网络框架 Keras[12~13]为基础,以改进后的YOLO网络结构为模型,训练多目标识别深度学习模型。对于深度学习而言[14~17],在训练过程中,为防止欠拟合,不仅仅需要大量的数据集做支撑,而且也需要保证数据集具有代表性,再经过反复训练后求解出合理的网络权重,再经过测试集来验证训练模型的准确度。本文根据实际平台环境以Microsoft-COCO数据集作为训练和测试数据集。Microsoft-COCO是一个大型的、丰富的物体检测数据集,该数据集包含330K图像、80个对象类别、每幅图像有5个标签、25万个关键点。
4 系统节点交互机制
4.1 ROS机器人操作系统
ROS(机器人操作系统)是一种分布式处理框架[18~20]。这使可执行文件能单独设计,并且在运行时松散耦合。这些过程可以封装到数据包和堆栈中,以便于共享和分发。ROS还支持代码库的联合系统。使得协作亦能被分发。这种从文件系统级别到社区一级的设计让独立地决定发展和实施工作成为可能。ROS的运行架构是一种使用ROS通信节点实现节点间P2P的松耦合的网络连接的处理架构,它执行若干种类型的通讯,包括基于服务的同步RPC(远程过程调用)通讯、基于Topic的异步数据流通讯,还有参数服务器上的数据存储。ROS的这种分布式的消息分发架构很好地解决了本文中各个节点模块之间数据交互的问题,不仅达到了模块间的相互通信,而且可以认为监视各个节点的运行状态,可以轻松获得各个节点发布的及时数据,安全性和可改进性大大提高。
4.1.1 Topic机制模型
如图2所示,节点与节点之间的连接是直接的,控制器仅仅提供了查询信息,类似一个DNS服务器。Listener节点订阅一个Topic将会要求建立一个与已发布的Talker节点的连接,并且将会在同意连接协议的基础上建立该连接。

图2 ROS消息发布与订阅模型图
Topic以一种发布/订阅的方式传递,一个节点可以在一个给定的Topic中发布消息,一个节点针对某个Topic关注与订阅特定类型的数据,可能同时有多个节点发布或者订阅同一个Topic的消息,如图3所示,用于实现数据的实时共享。
图3 多节点Topic模型图
4.1.2 Service机制模型
如图4所示,基于Topic的发布/订阅模型是很灵活的通讯模式,但是它广播式的路径规划对于可以简化节点设计的同步传输模式并不适合。在ROS中,还有一种Service通信模型,用一个字符串和一对严格规范的消息定义:一个用于请求,一个用于回应。类似于web服务器。

图4 ROS服务请求与相应模型
4.2 系统节点交互设计
本文中整个移动智能体的通信与数据交互系统采用ROS,如图5所示,系统分为视频采集模块、预处理模块、目标识别与推理模块、综合分析与处理模块、移动控制模块、数据监测模块。各个模块中又分为小的节点,多节点之间需要共享的数据采用ROS-Topic机制进行数据交互,而对于需要进行点对点特殊数据交互的节点之间采用ROS-Service机制进行数据交互。

图5 系统模块节点交互图
视频采集模块:通过移动智能体端搭载的摄像头进行移动过程中的实时视频采集,由于对视频清晰度要求不高,而且为了保证多目标识别的实时性要求,适当对分辨率进行了调整,满足后续处理要求。
孩子的个性不同,所处的年龄阶段不同,对父母的需求不同,良好亲子关系的格式也会有所不同。良好的亲子关系表现为依恋不依赖,理性不冷漠。父母需要很好地回应并引导孩子,使亲子之间和而不同,保持一种有弹性的融洽关系。
预处理模块:该模块主要对采集来的视频帧进行处理,主要为了满足目标识别与推理模块对图像输入尺寸的要求。
目标识别与推理模块:本文中优化后的YOLO网络模型,通过大量数据集的训练,具备识别多种目标障碍物的能力,准确度与识别速度经过测试均达到移动端的实时识别需求。通过与预处理的视频帧输入训练好的网络后,对目标进行识别标注,将视频数据、目标类别、目标位置等信息以Topic发布者方式共享数据。
综合分析与处理模块:首先,该模块以Topic订阅者的方式获取目标类别与位置信息,经过路径算法实时计算分析,以Topic服务者方式给出移动智能体的运动建议数据,数据包含角速度、线速度、传感器数据等。
移动控制模块:通过ROS请求综合分析与处理模块,以角速度、线速度、传感器数据等变量获取对应服务数据,将数据信息转换为移动控制平台个传感器的执行数据,并且由传感器获取的现场数据以及运行数据通过Topic发布,供数据监视模块订阅。
数据监测模块:该模块主要在远程对视频及数据进行监控,该模块可以获取所有节点的数据,对整个系统进行数据记录与分析,对系统性能检测以及改进有重要意义,也可以通过发布Topic命令直接对其他模块节点进行控制。
5 实验结果及分析
5.1 最优初始候选框数量验证
为了选取最优的初始候选框数量,验证其对多目标识别深度学习模型的影响,以Microsoft-COCO数据集作为训练和测试数据,用改进后的网络训练深度学习模型。以Precision-Recall曲线作为最终评估指标,得到最优初始候选框数量。
确保每次实验因素只有初始候选框的数量不同,每组实验均采用改进后的YOLO网络训练识别器,训练测试数据均采用Microsoft-COCO数据集。
聚类类别数量B分别设置为4、5、6、7四种规格。
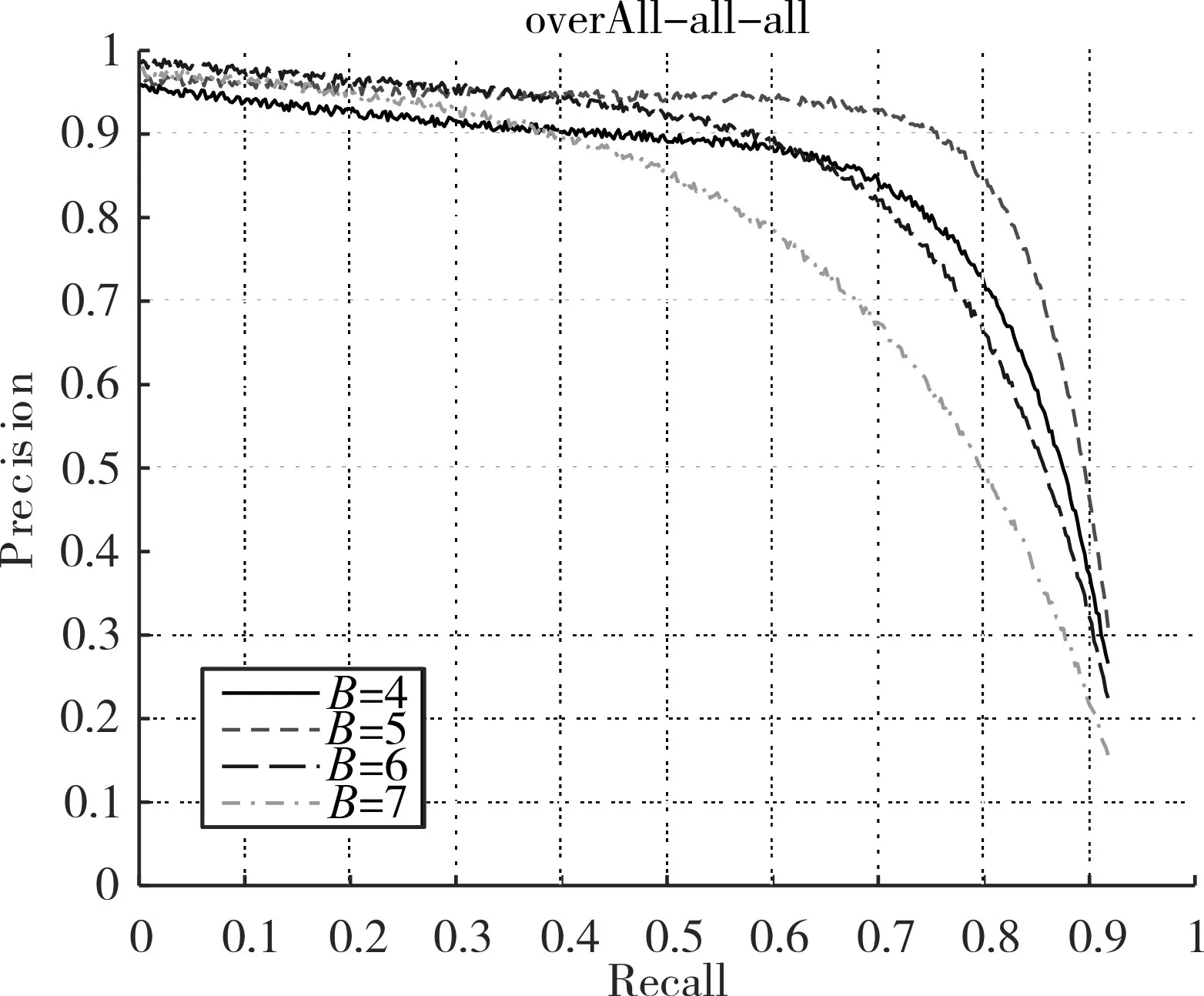
图6 候选框数量Precision-Recall曲线图
测试结果如图所示,以类别平均准确率作为纵坐标,以查全率做为横坐标。评估每组实验的有效性。由图6结果可以看出在Microsoft-COCO数据集的基础上初始候选框B=5时,训练得到的识别器的识别效果最好。
5.2 改进后网络效果验证

图7 改进后的YOLO网络对比
本文中对YOLO网络进行改进,增加了横向候选框密度,为验证其有效性,以Microsoft-COCO数据集为实验数据,对修改前后的网络结构所训练出来的识别模型进行分析比较。由图7得出,改进后的网络在相同数据集条件下训练出的识别器表现出相对较好的效果。
5.3 实验结果
5.3.1 实验平台
硬件平台:
Intel(R)Core(TM)CPU 3.4GHz
NVIDIA Tesla k40c GPU计算卡
NVIDIA Jetson TX1 GPU开发平台
Arduino Mega2560主控开发板
软件环境:
Ubuntu 14.04
CUDA 8.0
OpenCV
TensorFlow
5.3.2 实际效果
由图8看出,在测试和实际应用中均实现了稳定的多目标识别功能,对于小目标识别也有良好的效果。但由于移动端GPU性能的问题,导致处理视频帧率偏低,经过分析,将视频采集模块的摄像头分辨率调低至480*320,并将整个网络的输入图像大小调节为320*320,同样的对于320*320的输入图像尺寸进行针对训练,最终基本满足实时性要求。

图8 测试及实际效果图
6 结语
本文结合实际应用中存在的问题,分析移动智能体在多目标识别方面的需求,对YOLO网络模型进行改进,以确保提高横向小目标的识别率,避免因为小目标的漏检造成后续流程的错误。并且针对开发平台上识别器的效率进行优化,经过实验分析,改进后的整体系统基本达到识别的实时性和精确性要求。
