基于正反残差块的人脸表情识别算法
2020-07-10张青山宋晨阳姜代红
俞 成,姚 瑶,张青山,宋晨阳,姜代红
(徐州工程学院 信电工程学院,江苏 徐州 221018)
0 引言
人的表情包含信息。心理学家A.Mehrabia的研究[1]表明,人类有高兴、生气、吃惊、恐惧、厌恶和悲伤六种基本表情。
人脸表情识别是个困难的问题,光线变换、物体遮挡是普遍的阻碍。传统表情识别领域中的成果很多,但传统方法直接依赖于人工提取的特征,受到成像姿势、物体遮挡、光照变化等因素的影响,算法的鲁棒性和精度仍有升的空间。
近年的深度学习在图像识别方面进展很大。GAN模型[2]有很广阔的前景。牛津视觉几何组的VGG模型[3],将 Top-5错误率降低到 7%的水平。GoogLeNet(Inception)[4]将错误率降低到了4.8%。同时,网络深度的增加使梯度消失、梯度爆炸等问题让人们不得不作出更多改变。
因此,本文提出一个新的算法,该算法融合残差块单元(Residual Block)、反残差块单元(Inverted Residual Block)进行对人脸表情的识别。算法先进行图像增强,缓解数据集规模小的问题,再通过Dropout等技术,尽可能减少过拟合、梯度爆炸和梯度消失等问题,并通过实验对新方法进行有效性验证。
1 数据集与预处理
人脸表情数据库规模较小,使用场景不复杂。人脸数据集仅对笑与不笑标记,而且笑容本身使用的肌肉较多,特征明显。
本文使用Fer2013数据集,同时使用FER+(即FER Plus)[5]数据集标签进行多标签学习。表情识别,其实是多标签分类任务,本质上是从N个标签中选中 n个(n≤N),因为一个人可以既哭又笑。该数据集图片分辨率为 48*48*1,场景比在实验室录入的更加多变,而低分辨率和单通道图像增加识别难度。
Fer2013+数据集标签分为中性,幸福,惊喜,悲伤,愤怒,厌恶,恐惧,轻蔑,未知,NF。其中,NF是指图像非人脸。

图1 Fer2013+多标签样例Fig. 1 Fer2013 + multi-label sample
在图像增强方面,采用旋转0.2,裁剪0.2,允许水平翻转和最近填充的模式扩充数据,而后,将所有图像归一化。
2 残差块单元
传统深层CNN不能将梯度高效传递,而残差网络显著提高网络反向传播的能力,缓解梯度弥散和梯度爆炸问题,阻止深层神经网络的退化,加快收敛,并且能够有效提升更深层的学习能力。它的基本单元是残差块,残差块包含一条捷径,捷径能跨层传递信息,从而提高反向传播的效果。残差块定义:

就是捷径。残差块最终通过压缩——提取特征——扩张来完成特征提取。

若比例系数λ非1,则会出现两种情况:(1)λ>1,越浅层叠得梯度越大,于是梯度爆炸。(2)λ<1,越浅层叠得的梯度越小,随着层数增加,渐趋于 0,这就是残差网络出现前,难以堆叠深层网络的原因:训练太困难了。
综上,比例系数 λ只能为 1,捷径不包含激活层。那么在多层卷积堆叠的位置,激活函数的是否或如何使用的问题,而残差网络原文[6]中通过实验得到了解答。
构建残差网络需要权衡精度和复杂度,本文使用ResNet-50。具体原因见表1。Model top-1 err. top-5 err.
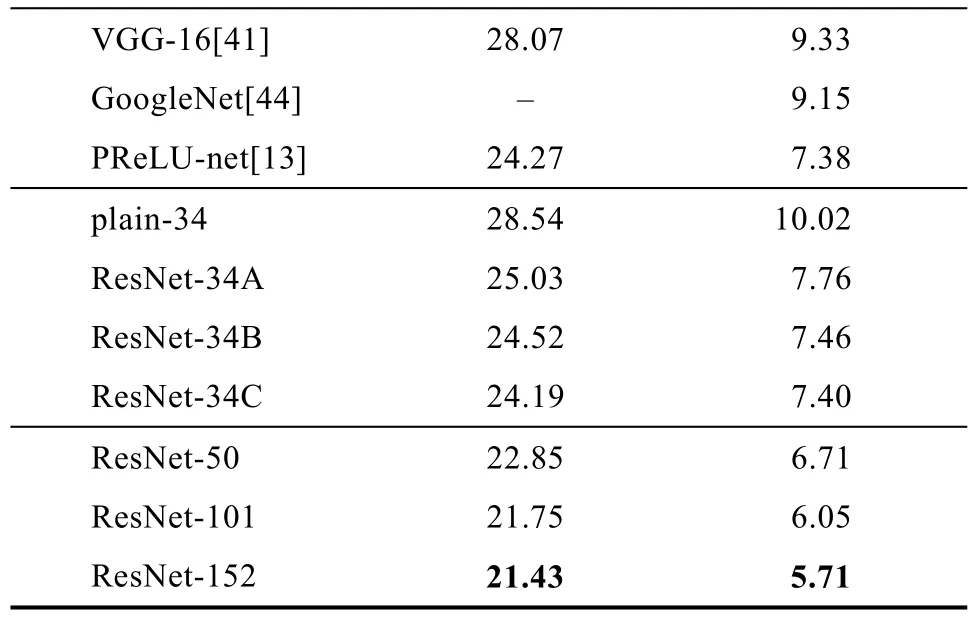
表1 基于ImageNet验证集的错误率Tab.1 Error rate based on ImageNet verification set
ResNet-50实验数据见下图。模型准确率稳定在80%附近,验证集 loss波动约 0.007较稳定,肯定了残差块的作用。但模型有过拟合的迹象。
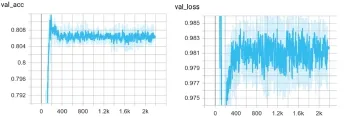
图2 ResNet-50在Fer2013+上的实验结果Fig. 2 Experimental results of ResNet-50 on Fer2013+
3 反残差块单元
标准的卷积层用卷积核 K∈ Rk×k×di×dj对形状为 hi× wi× dj的输入张量卷积,输出形状为hi×wi×dj的向量 Lj,计算量为 hi⋅ wi⋅ di⋅ dj⋅k⋅ k。而深度分离可卷积将一个完整的卷积操作分割成 DW 卷积,和紧接着的 PW 卷积(1×1卷积)层。深度分离可卷积效果与标准卷积几乎一致,而算力耗费却降 至 hi⋅ wi⋅ di( k2+ dj)。
反残差块先升维后降维。其操作由3个步骤组成:F (x ) = [A ◦ N ◦ B] x 。其中,A和B为线性变换,而 N是非线性逐层变换,实际使用中,N=ReLU6◦DW◦ReLU6。
下面,就反残差块能否减轻迁移学习的需求而言,进行 MobileNet[7]上迁移学习和 MobileNetV2[8]上迁移学习的能力比较,图3就这两个差距进行对比,图中橙色为迁移学习MobileNet,蓝色为非迁移学习MobileNet,红色为迁移学习MobileNetV2,绿色为非迁移学习MobileNetV2。可见迁移学习网络学习更快,MobileNet过拟合倾向更严重,并再次肯定了MobileNetV2的表现非常稳定这一结论。非迁移学习让MobileNetV2过拟合得到抑制,却让MobileNet过拟合情况更加严重,这可能是参数数量与数据集规模不匹配,也可能是随机权重初始化的问题。从验证集acc看,Mobile-NetV2对迁移学习需求低于MobileNet,但是需求降低不多,且未能排除随机权重初始化的影响,需要正则化等应对过拟合的调整。
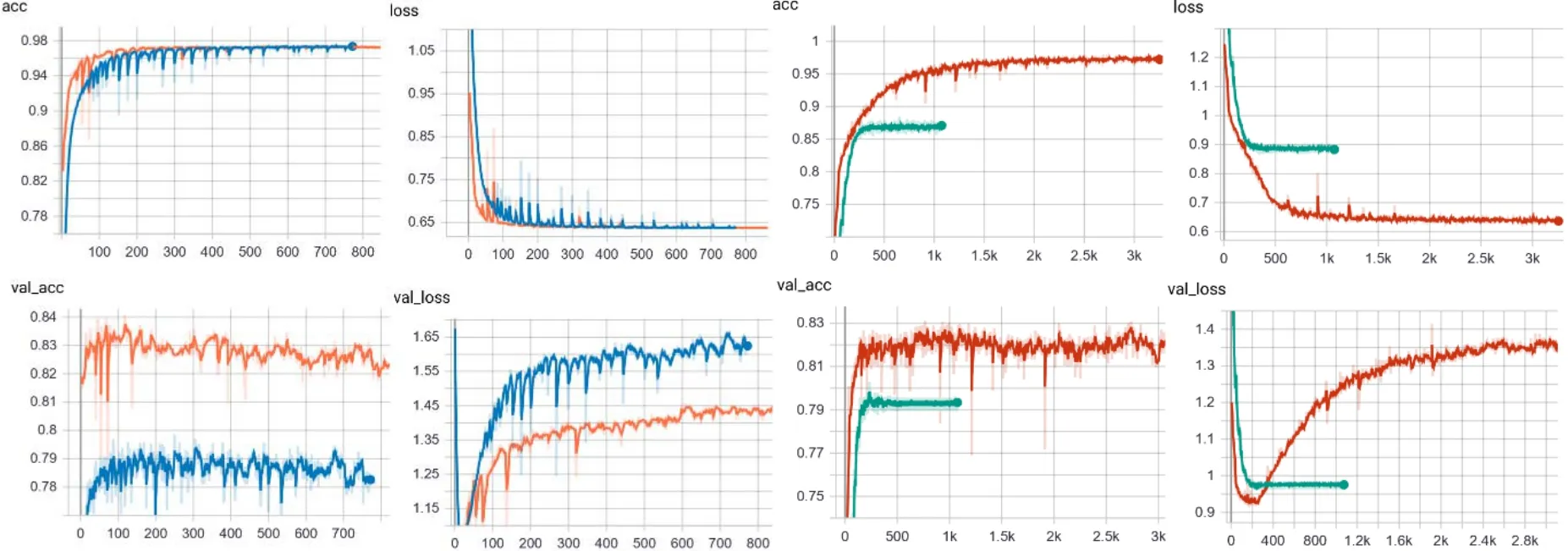
图3 MobileNet迁移学习和MobileNetV2迁移学习差距对比Fig.3 The difference between transfer learning on MobileNet and transfer learning on MobileNetV2
反观 ResNet-50网络对迁移学习的需求,见图4。图中灰色表示迁移学习 ResNet-50,蓝色表示非迁移学习ResNet-50。

图4 ResNet-50迁移学习与否的对比Fig.4 Comparison of ResNet-50 transfer learning
再次验证了迁移学习能加大拟合速度,却也加大了过拟合倾向。从长远角度看,ResNet-50可能完全不需要迁移学习,这反而能够让模型表现更加出色。此外,迁移学习的效果可能与网络结构和学习能力有密切关系。迁移学习可能更加适合使用中等规模的多样化数据集中——数据集规模越大,越不需要迁移学习;迁移学习所用数据集规模越小,过拟合倾向越明显。
4 正反残差网络
基于上面残差块与反残差块的实验结果对比,本文推出了几种正反残差块网络。
正反残差块互相穿插的正反残差网络测试结果见图 5。图中红色为未正则化的穿插式正反残差网络,图中灰色为带双0.3 Dropout层正反残差网络,图中亮蓝色为ResNet-50,图中深蓝色为MobileNet,图中绿色为MobileNetV2。
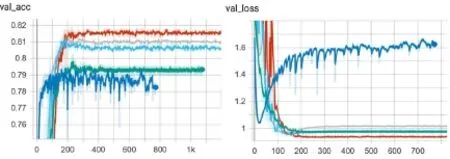
图5 穿插式正反残差网络与其它网络对比图Fig.5 Comparison of overlapping positive and negative residual networks with other networks
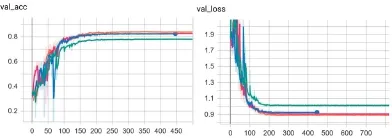
图6 非穿插式正反残差网络对比Fig.6 Contrast of positive and negative residual networks without overlapping
穿插式正反残差网络正确率均优于 ResNet-50网络,但是,使用双0.3 Dropout层的网络却略过拟合,且正确率低于未使用 Dropout层的网络。可能Dropout在穿插网络中生成的噪音干扰了反残差块的低维信息留传。不过,表现都略优于已有模型。
基此,将正反残差块的相对位置重新设计了:MR正反残差网络数据先流入多反残差块,再流入多残差块;RM正反残差网络数据先流入多残差块,再流入多反残差块。实验见图 6。图中橙色为使用双0.3 Dropout层的RM正反残差网络,蓝色为使用双0.3 Dropout层的MR正反残差网络,粉色为无正则化RM正反残差网络,绿色为无正则化MR正反残差网络。
即使不使用迁移学习,非穿插式正反残差网络其拟合需要的轮数也基本维持在 ResNet-50和MobileNetV2水平,在200-250个epoch时,模型基本拟合到位。其次,MR和RM网络都展示出继承而来的过拟合抑制特性,且显露出了类似 ResNet的准确度更高的特性,保持了训练和测试的稳定性。其中,使用双Dropout层的RM正反残差网络拟合所需轮数,准确性最佳,loss最低。RM正反残差网络结构如表2所示。
5 实验结果
实际上,验证集上表现好,不代表真实水平,最后在测试集上的表现,才能反映出模型算法的真实水平,见表3。

表3 不同网络在测试集上的准确度与损失比较Tab.3 Comparison of ACC and loss of different networks on test sets
带双Dropout层RM正反残差网络拟合所需轮数,准确性最佳,loss最低,获得了验证集准确率接近84%的优秀成绩。
6 结束语
本文介绍了国内外人脸表情识别研究现状,提出基于正反残差块的人脸表情识别算法。实验结果表明,该算法同时继承ResNet和MobileNetV2的优秀特性,准确率高,抑过拟合能力强,识别效果好。后续可以研究迁移学习的RM正反残差网络,和对网络结构的进一步优化。
