基于LSTM的焙烧时序数据的质量预测模型
2020-07-10苏志同王春雷
苏志同,王春雷
(北方工业大学 信息学院,北京 100144)
0 引言
目前,国内焙烧相关的研究包括,赵爽[1]通过大量实验表明焙烧参数对阳极质量有很大的影响。李建元[2]通过调整焙烧升温曲线,在一定程度上解决了焙烧阳极质量较低的问题等等。在焙烧过程中,工艺参数的选择多源于经验,并且焙烧成品率不是很高。将深度学习技术应用到焙烧时序数据的质量预测上,有助于挖掘工艺参数与质量参数之间的关系,有助于提升焙烧的成品率。焙烧过程产生的数据是时间序列数据[3],可以用循环神经网络(RNN),长短时记忆网络(LSTM),门控循环单元网络(GRU)来进行训练和预测[4]。如果将时间序列数据拼接成一维矩阵,还可以使用一维卷积神经网络(CNN)和多层感知机(MLP)来进行训练和预测[5],但数据拉伸后,会丢失原时间序列数据在时间上的依赖关系。因此本文采用LSTM网络来进行焙烧质量的预测。
1 数据预处理
获取到的原始温度数据表的数据结构为[DateTime time, int LSH, int hd1,int hd2, int hd3, int hd4, int hd5, int hd5, int hd7, int hd8, int hd9],其中Datetime为数据抽取的时间,LSH为当前数据所属炉室号,hd1~hd9为每个炉室的 1~9号火道的温度数据。
其数据结构如表1所示,其中t-1表示t-1,LS1表示1号炉室,A1为1号炉室火道1~9火道在t-1时刻温度数据的拼接串。
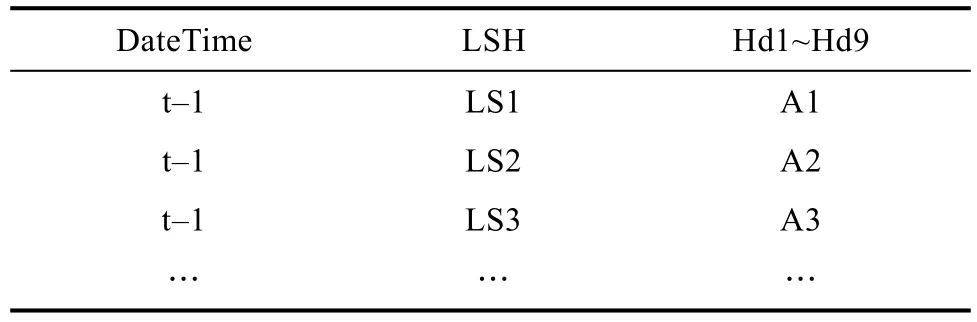
表1 原始工艺参数数据Tab.1 Raw process parameter data
焙烧过程可测量的加热阶段分为1p,4p,5p,6p四个阶段,每个阶段加热时间为32小时,每隔1小时记录一次所有炉室的温度数据情况,所以一条完整的温度曲线应该包含128条数据。将原始数据先按照炉室号分组,然后将每个炉室的1p,4p,5p,6p的记录进行组合,最终形成升温曲线数据,其数据结构如表2所示,其中B1、C1为1号炉室在t、t-1时刻的温度数据的拼接串。得到升温曲线后,将其与阳极的质量参数数据对应,由于每个炉室对应8组阳极,故对该 8组阳极的质量参数取平均值作为该升温曲线所对应的质量参数数据。

表2 原始工艺参数抽取重组后数据Tab.2 Extraction and reconstruction of original process parameters
焙烧块质量参数共有7个评价指标,分别为:HF,TJMD,DZL,ZMD,NYQD,CO2,RPZXS,分别代表灰分,体积密度,电阻率,真密度,耐压强度,二氧化碳反应性,热膨胀系数。由于各评价指标的量纲不同,需要对7个指标的数据进行归一化处理。由于原质量数据表中的C02和RPZXS属性的缺失值较多,因此舍弃这两个属性作为质量评价的指标。部分原始质量参数数据如表3所示。
2 预测模型与结果分析
本文选择 python作为开发语言,应用tensorflow1.12.0框架,建立质量预测模型。
2.1 长短时记忆网络(LSTM)
在传统的前馈神经网络中,网络中的输入层、隐含层以及输出层之间是全连接的,但每层内部的节点之间是无连接的。这种结构导致传统的前馈神经网络无法处理那些输入之间前后有关联的问题[6]。
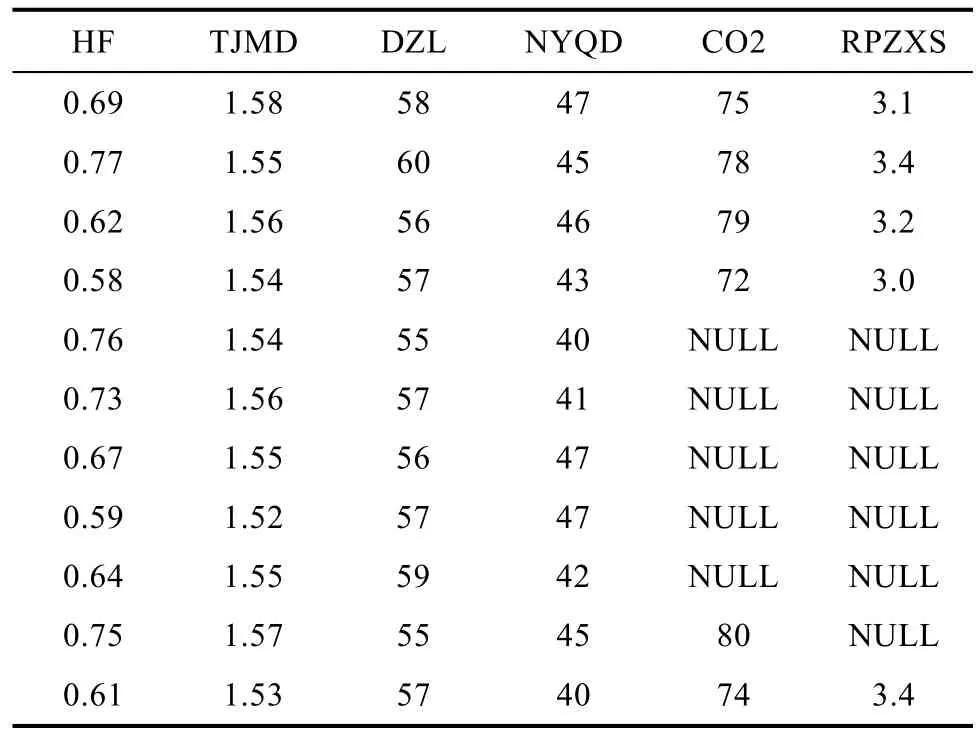
表3 部分原始质量参数数据Tab.3 Partial raw quality parameter data
与传统的前馈神经网络不同,循环神经网络引入了定向循环,此时网络中隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。因此,循环神经网络能够对前面的信息进行记忆并应用于当前输出的计算中。相比于传统的前馈神经网络,循环神经网络考虑了时间因素,能够记忆之前存储的内容[7]。
循环神经网络解决了输入信息前后关联的问题,可以将先前的信息连接到当前的任务上。但是,当先前的信息和当前任务之间的时间间隔不断增大时,循环神经网络会出现梯度消失而丧失连接到如此远的信息的能力。长短期记忆网络(LSTM)[8]较好的解决了这个问题。对于一个给定的输入时间序列 x = ( x1, x2,… ,xT),标准的循环神经网络会通过迭代求解来计算网络隐含层向量 h = ( h1, h2,… ,hT)和输出层向量 y = ( y1, y2,… ,yT)。
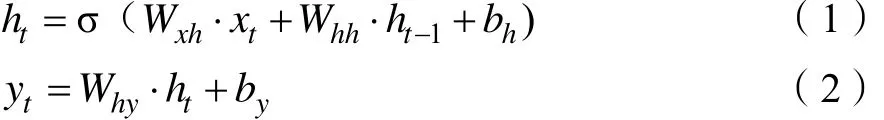
式中:xhW 、hhW 、hyW 分别表示由输入层到隐含层、隐含层内部、隐含层到输出层的网络权重系数;hb、yb分别表示隐含层和输出层的偏差向量;σ表示隐含层神经元的激发函数sigmoid函数。
在标准的循环神经网络中,通常是采用Sigmoid函数作为激发函数[9]。LSTM 则使用一个长短期记忆模块替代了标准循环神经网络中简单的隐含层神经元,因此具备了学习长期信息的能力。
LSTM 是一种特殊类型的循环神经网络,主要依靠经过精心设计的“门”结构来实现去除或者增加信息到细胞状态的功能。门是一种让信息选择式通过的方法,LSTM拥有3个门,来保护和控制细胞状态,分别为:输入门、输出门和忘门。图1给出了一个典型的LSTM长短期记忆单元的结构。

图1 LSTM结构示意图Fig.1 LSTM structure
其用到如下公式计算输出:
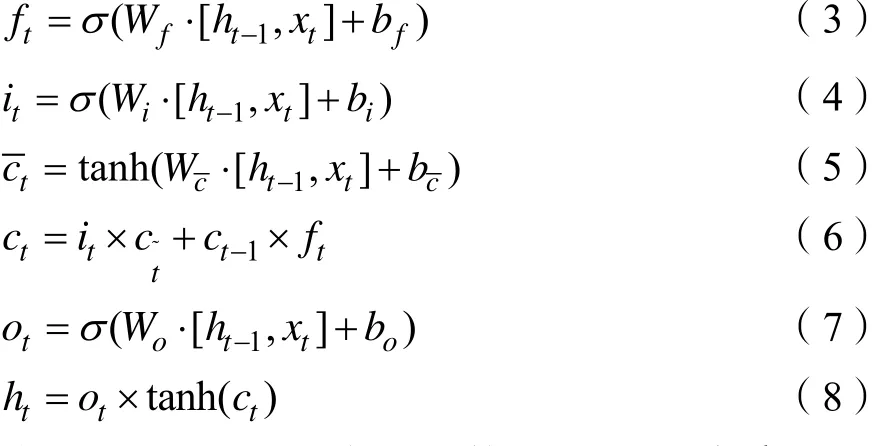
其中σ为sigmoid激活函数,a⋅ b为矩阵乘法运算,a×b为矩阵的点积,即矩阵的对应位元素相乘。ft为遗忘门的输出,其与 ct-1相乘表示对之前得到的信息保存的多少,it×ct构成遗忘门的输出,该结果表示要向历史信息 ct中增加哪些信息, ct表示新的历史信息。ot表示要输出哪些内容,ht表示该lstm单元最终的输出。
2.2 模型建立
本文的数据来自某厂焙烧生产数据,先将原始的工艺数据进行抽取整合归一化,原始的质量数据进行归一化,并将工艺与质量参数映射对应。以工艺数据作为模型的输入,分批次的送入模型进行训练模型中的权重矩阵和偏执矩阵。并将质量参数当作标签,计算模型的损失函数,反向传播,应用Adam[10]优化算法进行参数更新。
本文采用交叉熵损失函数[11],因为其是神经网络中常用的目标函数,能较好衡量预测值与真实值之间的误差。其公式如下:

其中m表示批次的样本数量,n表示分类的类别数, p ( y(i)= j| x(i);θ)表示在网络权值为θ的情况下,第i个样本的标签等于第j类的概率,1 { y(i)=j}表示第i个样本的标签 y(i)如果等于当前类别,则取值为1,否则取值为0。准确率为分类正确的样本数与总样本数的比值。
2.3 实验结果分析
根据图2可知在迭代1200次后综合准确率达到接近90%。

表4 在各个指标上预测的准确率Tab.4 The accuracy of predictions on various indicators
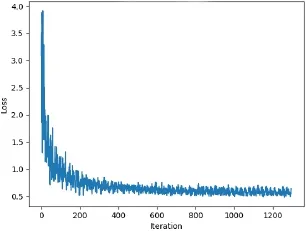
图2 迭代更新下Loss变化Fig.2 Loss under update of iteration
3 结语
本文在焙烧数据上应用lstm预测模型,预测的准确率较高,说明LSTM模型可以应用到焙烧生产数据分析过程中,帮助挖掘工艺与质量参数之间的潜在关系。辅助调整焙烧过程中的参数,改善焙烧块的质量,间接提升铝厂的生产效益。
