基于多尺度卷积网络的路面图像裂缝分割方法
2020-07-10孙梦园范文慧
孙梦园,刘 义,范文慧
(清华大学自动化系,北京 100191)
0 引言
道路检测可以帮助获得路况信息,评估损坏程度,并为道路维护和重建提供重要依据[1]。近年来,随着公路建设的飞速发展,维护管理工作量大大增加,导致对路面检测的需求增加。快速、准确地访问道路状况信息是高速公路维护和修复(M&R)的关键。随着高速公路里程的增加,自动道路检测车辆已成为高速公路机构管理其道路网络的一种广泛使用和必要的手段。路面损坏程度是影响道路决策的重要指标。自21世纪以来,道路检测车辆的发展已逐步得到改善。检测车的结构设计主要包括路面损坏情况拍摄系统、道路平整度和车辙自动检测系统、正面图像检测系统、自动记录绘图系统、GPS定位系统、模块化离线计算和信息管理数据中心系统[2]。由于裂缝是路面破坏的一种常见类型,近年来,路面裂缝自动识别系统在路面管理领域发展迅猛,研究人员进行了旨在有效和高效地检测和分割路面裂缝的研究。
在裂缝分割领域,传统算法研究主要集中在多种多样的裂缝特征的提取上,并提出了基于阈值的[3,4]、基于边缘检测的[5]、基于数学形态学的[6,7]等多种分割算法。Talab等尝试通过使用Sobel滤波器消除残留噪声来检测路面裂缝,并采用Otsu方法检测主要裂缝[8]。邹等开发了一种阴影去除算法以去除路面阴影并保留裂缝,并使用张量投票来构建裂缝的概率图,以增强裂缝片段的接近度和曲线的连续性[9]。Salman等提出了一种基于Gabor滤波器的道路裂缝自动检测方法[10]。
以上算法在一定程度上解决了路面裂缝特征提取的问题,但是当道路裂缝被噪声或其他恶劣条件(例如异质光)包围时,传统方法表现效果不佳[11],图像的噪声成为道路裂缝检测的难点之一[12,13]。此外,在图像采集期间,裂缝样本的不平衡还导致难以确定用于裂缝检测或分割的特征[14]。近年来,用于语义分割的深度学习神经网络在图像分割中比传统方法获得了极大的欢迎、取得了巨大的成功。2014年,全卷积网络提出将全连接层替换为卷积,因此可以接受任何大小的图像输入,相较于全连接网络取得更优的图像分割效果[15]。在此基础上,针对裂缝的分割或检测,U-Net成为流行的体系结构之一,该网络提出了快捷连接的编码-解码结构,前者逐渐减小空间尺寸而后者逐渐恢复空间尺寸和详细信息[16]。KönigJ等人在U-Net上应用编码器和解码器部分之间的残留连接和注意门控机制,从而使仅与目标相关的功能获得更多权重[17]。Escalona等人实现了两个基于U-Net的网络变体,用于自动路面裂缝检测[18]。Fang等人提出了一个ConvNet模型,为每个检测到的目标提供裂缝方向信息。他们开发了一种贝叶斯融合算法,降低检测错误率[19]。
除了全卷积网络,多层特征的融合算法也引起了人们的关注。Y liu等人将FCN和深层网络(DSN)结合在一起,聚合了多尺度和多层次特征,并很好地改善了裂缝分割的性能[20]。Kaddah专注于改进优化的最小路径选择方法,以在灰度路面图像中实现鲁棒而有效的裂缝分割[21]。在本文中,为了消除裂缝周围噪声的干扰、提高裂缝分割的效率和准确性,我们在此提出一种新颖的卷积网络架构。受 U-Net的启发,我们引入了编码-解码器的概念,将不同的层连接起来以完全集成信息功能。同时,为了进一步抑制噪声、充分利用不同层次的特征信息,我们参考了金字塔网络的理念[22]。我们通过更改卷积核的大小、而非金字塔网络池化层,避免了金字塔网络的特征不连续性,这也有助于产生更好的全局的多尺度信息。
这些算法下的路面裂缝自动分割的准确性仍需要提高。当前路面裂缝仍然存在几个主要问题:
(1)包含裂缝的图片数量不多,导致样本不足和不平衡;
(2)受图像采集设备和自然环境的限制,裂缝图像常被多种噪声干扰;
(3)各种尺寸或形状的裂缝也导致分割困难。
考虑到裂缝检测和分割的难点,我们提出了一种具有跳跃连接结合残差块的编码器-解码器网络以充分利用不同层的特征。我们还提出了一个新型的多尺度卷积形式,该模块具有不同尺寸的卷积核,可以有效地检测不同尺寸或者形状的裂缝,同时对抑制噪声有所改进。
1 裂缝分割网络结构
路面的困扰主要包括裂缝、车辙、坑洼、变形、起皱等。其中裂缝情况最为复杂,涉及如横向裂缝、纵向裂缝、龟裂等多种类型。同时,裂缝特征很难精确划定。因此,学术研究人员和工程从业人员都非常重视路面裂缝的检测与分割。为此,本章节将重点研究基于深度学习对裂缝进行检测分割的方法。
1.1 解码-编码深度网络
在编码器-解码器网络中,U-Net最初被医学领域中用于二维图像分割,赢得了ISBI2015细胞跟踪挑战和龋齿检测比赛[11]。与直接依赖于网络最后一层特征的通用神经网络分类器相比,解码器阶段的U-Net结构可以充分组合浅层的简单特征,因此该网络即使对小数据集也能很好地应用。U-Net架构主要由编码器部分和解码器部分组成。编码器具有四个子模块,其中每个子模块包含两个卷积层与一个最大池化层。解码器由四个子模块组成,特征分辨率通过上采样操作连续提高。该网络使用跳跃连接将上采样结果与子模块的输出连接并合并。
在此,我们引入了编码器-解码器层的概念。我们对路面裂缝图像进行3次降采样和升采样,以构建编码器-解码器网络。提出的网络结构如图1所示,左侧为编码器部分,右侧为解码器部分。输入图像时,我们将其调整为256*256的灰度图像,以节省存储空间。然后,图像经过一个多尺度卷积模块与一个最大池化层。
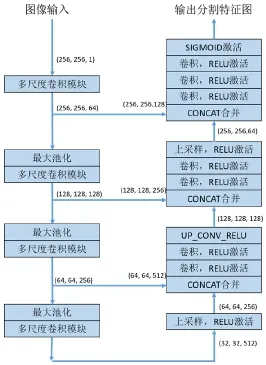
图1 带多尺度卷积模块的深度分割网络Fig.1 Deep network with multi-scale convolutional blocks
在解码器部分中,我们通过依次级联来链接生成的特征图,并紧接着内核大小为3*3的卷积层、Relu激活层与上采样层,如此轮流。在编码器和解码器部分之间,模型使用跳过连接,尽可能避免高级语义特征的丢失,确保上采样后的特征图集成了更多的低层特征和不同尺度的特征,从而可以进行多尺度的预测和更深层的监控。
1.2 多尺度卷积模块
在图像分割中,不同尺寸的物体总是导致分割困难:一些小规模的对象容易被遗漏,而大型对象可能会超出感知域并导致不连续的预测,分割效果往往不尽如人意。为了提高不同尺寸分割的性能,空洞卷积在标准旋转图中注入了孔,以扩大感知域。空洞卷积包含一个称为除数率的超参数,它是指内核中的间隔数[17]。PSPNet被提出,该网络更加关注包含不显眼事物的子区域,因为错误部分与不同接受域的上下文和全局信息有关[18]。网络将原始特征图与经过不同大小的池化层,再进行卷积,最终将卷积和上采样后的结果连接起来。由于金字塔结构并行考虑多个感知域下的目标特征,因此对于大尺寸或小尺寸的目标具有更好的识别效果。
因此,具有适当全局场景级别先验的深层网络可以大大提高场景分析的性能,有必要考虑不同接受场下的上下文信息。我们设计了一个多尺度卷积块,以结合三个不同感知域的特征。在多尺度卷积块中,设计的卷积核的大小分别为1*1、3*3和5*5,并且通道的数量随特征深度的不同而变化。为了合理地保持全局特征的权重,我们使用BN层(Batch Normalization)在卷积之后进行级联。然后,我们从不同级别获取全局特征图信息。在图2中,我们介绍了多尺度卷积核的具体结构,并给出了靠近输入图像的第一个块的主要参数。如图2所示,在第一个多尺度卷积模块中,卷积内核的通道为64,左中右通道的卷积核大小分别为1、3、5。第二、三、四个卷积模块的结构与图2相同,通道数目分别为128、256和512。因此,针对裂缝图像噪声干扰和裂缝尺寸各不相同的主要问题,我们构建了多尺度卷积块,构建编码器-解码器全卷积网络。
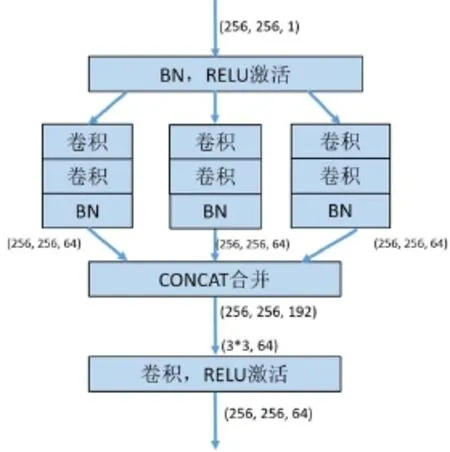
图2 多尺度卷积模块(通道数目已标出)Fig.2 Multi-scale convolutional block(Numbers of channels are denoted.)
2 裂缝分割结果与分析
2.1 裂缝分割优化目标
考虑到裂缝分割实际上是二分类问题,我们引入二分类交叉熵BCE(Binary Cross Entropy)作为损失函数的一部分。但是在裂缝图像中,背景和前景在比例上存在显着差异,这意味着正样本和负样本非常不平衡,因此需要考虑更多细节以适当优化损失函数。
图像分割模型的性能评估有几种常见的指标,分别为分类精确性(Acc)、正确性(PA)、召回率(Recall),表达如下:
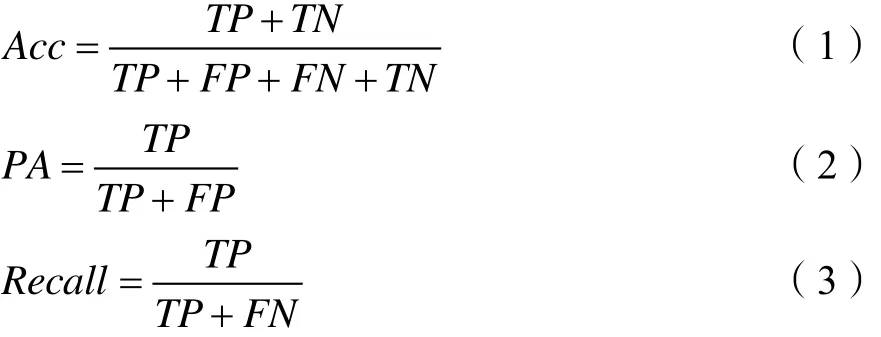
其中FN,FP,TN,TP分别表示为假阴性、假阳性、真阴性和真阳性。对于图像分割,涉及正负样本的不平衡时,精确性、正确性、召回率的不足便显示出来,不能很好地衡量分类效果。因此研究人员提出了交并比IOU和DICE系数,分别表示真值(GT)和预测结果(Predict)的交集和并集之比以及交集面积之比占总面积值。对于一张图像,它们的计算如下:

因此,我们的损失函数由BCE作为衡量,并在数据集合上进行训练,验证模型的分割精度、召回率、DICE等性能。
2.2 实验与结果分析
我们将提出的模型应用于公开的裂缝数据集CFD(CrackForest-dataset)和AigleRN上,将这两个数据集进行交叉混合,80%的图像用于训练,而20%的图像用于评估。在训练过程中,学习率设置为1e-4,模型训练了 150个周期(epoch),随着训练周期的延长损失函数最终会随着时间的增加而趋于收敛。
为了验证模型的优越性,我们将模型与 Canny算法、VGG16、U-Net进行了比较,其中Canny算法代表传统的图像分割方法,VGG16与U-Net为深度学习方法。
从表1中,我们可以看到Canny算法用于图像分割的性能并不令人满意,尤其是对于精度和DICE系数而言,这显示了传统方法在裂缝分割方面的缺陷;最高的精度由VGG中获得,U-Net给出了最优的召回率,我们的模型显示了最好的DICE,而该系数可以真正衡量图像分割的性能。

表1 在裂缝数据集AigleRN与CFD上Canny算子、VGG16、U-Net与提出模型性能对比Tab.1 Comparison among our proposed model and other algorithms
然而,本文所提出的模型在精度和召回率上不如其他模型优秀,我们推测有两个主要原因:首先,为了提高训练和检测的效率,我们降低了模型的深度,深度不足可能会导致特征图信息的丢失。其次,与U-Net相比,我们的模型使用残差块抑制了噪声、通过多尺度卷积核改变了感知域,从而在抗干扰方面显示出优势,但是漏检率也增加了,即会存在裂缝被漏检为噪声的情况,分割效果如图3所示。
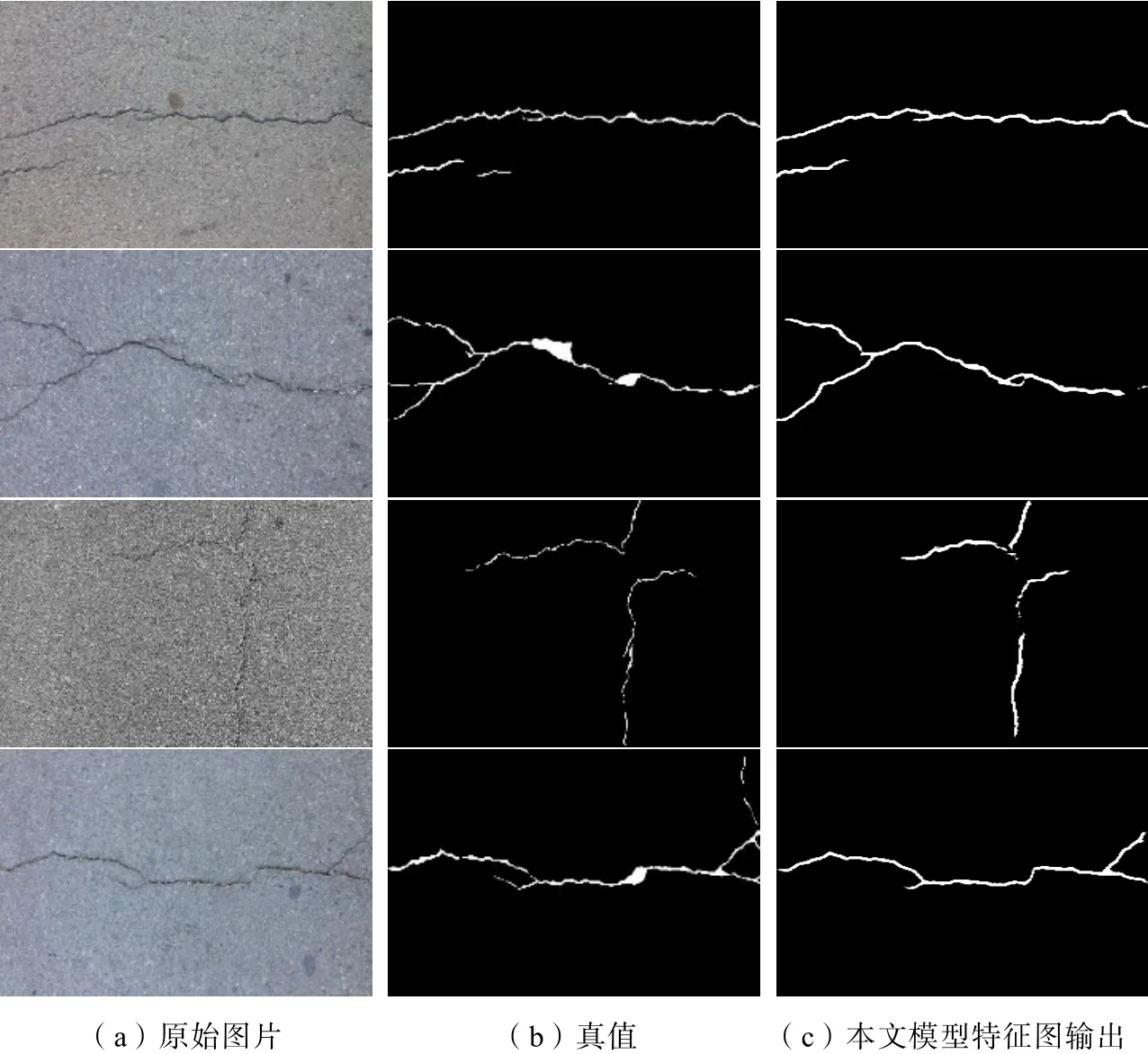
图3 裂缝图像、真值图与特征图输出Fig.3 Original cracks, ground truth and output of feature maps
3 结论
在裂缝图像中在公路养护和修复过程中,裂缝是路面评估和养护决策中最关键的问题之一。针对路面图像存在多噪声、裂缝尺寸形状各异、裂缝样品不平衡的特点,本文重点研究了路面裂缝的分割、提高裂缝分割的效率和准确性,并对裂缝尺寸特征进行提取。我们的贡献主要包括:
(1)我们采用具有跳跃连接的编码-解码全卷积网络,以充分利用来自不同层的特征图。同时引入了残差网络来抑制噪声、增加了网络深度,减少了梯度消除的情况;
(2)考虑到裂缝的形状、尺寸各不相同,我们提出了一种由不同大小的卷积核集成组合的多尺度卷积块,以增加裂缝检测的感知域;
我们设计的网络在裂缝分割方面表现出色的性能,解决了裂缝图像样本数量少且噪声较多的问题;同时,我们设计了一种裂缝尺寸特征提取的方式和可视化的效果。在研究的下一阶段,我们计划调整、进一步优化裂缝分割网络。实验结果表明,与其他模型相比,我们的模型在DICE系数方面表现出色,但在精度和裂缝分割召回率方面仍需要改进。解决样本不足的突破点。我们还将继续计算提取的裂缝形状参数,以获得高速公路的评价指标。
