对遮挡人脸修复识别的改进与应用
2020-07-10武文杰王红蕾
武文杰,王红蕾
(贵州大学电气工程学院,贵州 贵阳 550000)
0 引言
人脸识别技术是当前社会重点研究问题,它作为生物识别技术的一种,具有非接触性,非强制性等优点,具有广阔的应用前景。但是,要进行识别的人脸若不是完整的,有遮挡的,特征并不完全,则传统的人脸识别方法效果较差,因此出现一些关于特征不完整的人脸识别方法。关于该主题的最早工作之一是Savvides等人的工作[1]。在这项研究中,他们在各个面部区域进行了测试,以建立具有判别能力的量词。基于灰度图像的核相关滤波器被用来减少图像的维数和特征提取。随后,他们利用支持向量机(SVM)来区分各种面部特征。他们测试了眼睛,鼻子和嘴巴,结果表明眼睛区域的验证率更高。He等人[2]以类似的方式引入了一种称为动态特征匹配(DFM)的技术,用于部分人脸识别。 他们的研究基于全卷积网络(FCN)和稀疏表示的组合,FCN的目的是提取图像的特征图,他们工作的核心是利用VGG-Face模型将特征转移到FCN,此方法产生了良好的分类精度。本文也是针对特征不完整人脸识别进行的实验与研究。创新之处有:(1)使用对抗生成网络进行人脸的修复补全,再对补全人脸的进行识别。将遮挡的部分补全进行识别,提高了识别率;(2)使用WGAN-GP网络进行人脸修复,并且加入跳跃连接;(3)实验比较使用了余弦相似度作为分类器进行识别。
1 相关内容
1.1 生成对抗网络
生成对抗网络(GAN)是 Goodfellow等人在2014年从自博弈论中的“二人零和博弈”中受到启发而提出的[3]。如下图所示,生成器G和判别器D这两部分构成了生成对抗网络。其中,生成器是用来获取训练数据分布并且不断地生成与真实图像相似的图像;判别器是判断输入的数据是真实数据还是来自生成器的生成数据,结果还将反馈回生成器。输出结果概率越接近50%,生成数据越逼真。
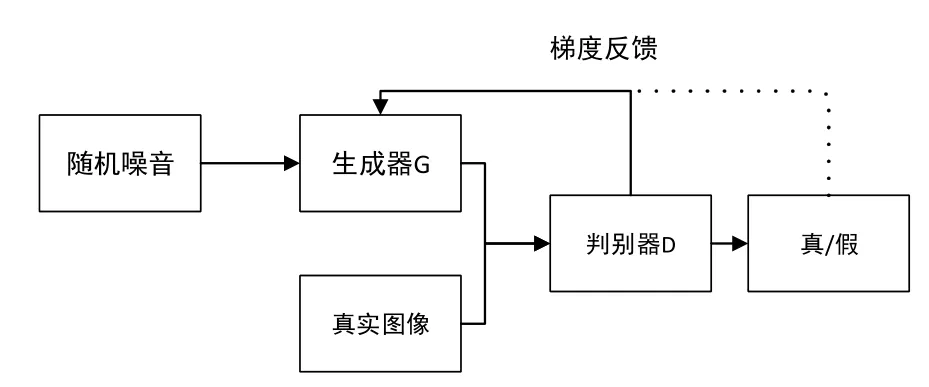
图1 生成对抗网络工作原理Fig.1 Principle of generating countermeasure network
1.2 WGAN-GP
WGAN-GP是 WGAN的改进版[4],WGAN和DCGAN相比是用连续的 Wasserstein距离代替 KL散度、JS散度度量两个分布的远近,效果更加优秀。WGAN-GP对WGAN改进之处在连续性限制的条件方面,给WGAN加一个外罚,使用梯度惩罚(gradient penalty)的方法来满足 lipschitz连续性条件。使用Wasserstein距离去衡量生成数据分布和真实数据分布之间的距离,理论上解决了训练不稳定的问题;解决了模式崩溃的(collapse mode)问题,生成结果多样性更丰富;提出了一种新的lipschitz连续性限制手法—梯度惩罚,解决了训练梯度消失梯度爆炸的问题;拥有更快的收敛速度,并能生成更高质量的样本。
1.3 卷积神经网络
近年来,机器学习最流行的方法之一是基于深度学习的机器学习,包括卷积神经网络(CNN),其在视觉计算领域的使用已经引起轰动。CNN是受监督的机器学习技术,可以通过基于样本的严格训练从数据集中提取深层知识。CNN已经成功应用于特征提取,面部识别,分类和分割等功能。如今,基于 CNN架构的最先进的深度学习模型已在几乎所有与视觉计算相关的领域中使用,包括图像感知,识别,分类和信息检索。
通常,有三种部署CNN的方式。包括在从头开始训练网络,微调现有模型或使用现成的 CNN功能。后两种方法称为迁移学习。从头开始训练CNN需要大量数据,这通常是一项艰巨而艰巨的任务。微调涉及将从基础网络学到的前几层的权重转移到目标网络。然后可以使用新的数据集训练目标网络。
对于使用CNN的面部识别,有几种预训练的模型可以轻松用于特征提取,例如VGGF,VGG16,VGG19等。在本文中,对于特征提取,本文利用了VGGF预训练模型,将在下面进行讨论。因此,本文在这里采用的方法使用预先训练好的VGGF模型进行特征提取,然后使用CS[5]等分类器进行分类。
2 网络结构模型
2.1 生成对抗网络模型
生成对抗网络模型如图2所示由生成器模型G和判别器模型D组成。其中conv指卷积层,deconv代表解卷积层,卷积核的大小为5*5。
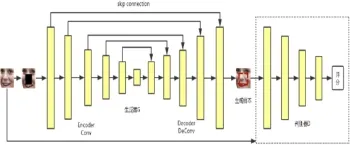
图2 本文生成对抗网络模型Fig.2 Model of countermeasure network generated in the paper
生成器中,生成器分为编码器和解码器两部分,是由下采样的卷积层与上采样的解卷积层组成,同时通过跳跃连接将低级别的特征传到高层特征上。激活函数的使用借鉴wgan,下采样层使用激活函数Leaky-ReLU[6],防止梯度稀疏;上采样层使用ReLU[6],最后一层使用Tanh激活函数[6]。
判别器是通过不断与生成器对抗学习,进而提高自己识别真假图像的准确率。图中判别器模型是由卷积神经网络构成,输入包括真实图像和生成图像。因为使用的是Wasserstein距离衡量去两个分布间的距离,所以判别器要单独对每一样本进行梯度惩罚。为了防止同一 batch不同样本相互依赖,判别器各层不用Batch Normalization[7]。
2.1.1 生成器损失函数
传统的生成对抗网络的生成器损失函数只有生成对抗损失,为了生成器能够生成与真实图像更加相似的图像,本文在传统生成器的损失函数上增加了内容损失。对抗损失为破损图像生成与真实的差别,内容损失为有内容的区域(未破损区域)生成与真实的差别。
对抗损失将破损图像当作条件加入到生成器输入中,此时对抗损失为
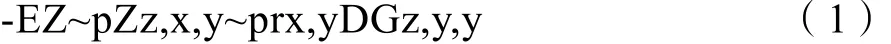
内容损失使用 L1距离来判断生成器生成样本的未破损区域与真实样本的未破损区域的差别。假设M为图像掩膜,其与输入图像具有同样大小的尺寸,其中破损像素点用 0表示,完好的像素点用 1来表示,则内容损失为如下
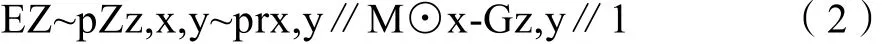
其中,符号⊙代表两个矩阵的对应元素相乘。
最终,结合以上两部分损失函数,生成器的损失函数的形式为:
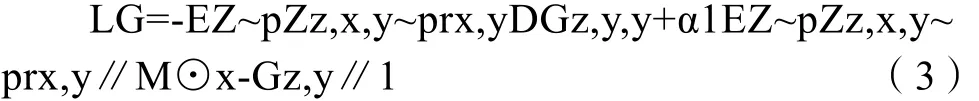
其中,α1为权重系数。
2.1.2 判别器损失函数
在很多不同结构的对抗网络中,判别器的损失函数基本一致。本文希望判别器能够识别出真实样本,给真实样本高的评分并给生成样本低分,因此,EX~PrDx足够大且 Ex~PgDx足够小。同时使用Wasserstein距离代替KL散度、JS散度来衡量真实样本与生成样本的差异,并且加入梯度惩罚Ex~px[∥ ∇x D x∥ p-1]2对判别器进行 Lipschitz限制。所以判别器的损失函数为
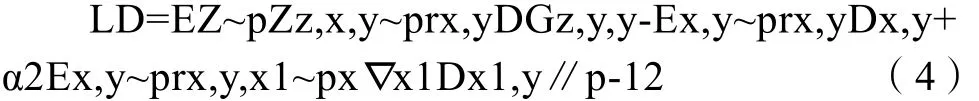
此外,文献[4]指出没有必要在整个空间施加Lipschitz限制,只要重点抓住生成样本集中区域、真实样本集中区域以及夹在他们中间的区域就可以。
2.2 卷积神经网络模型
2.2.1 VGGF模型
有几种针对CNN的预训练模型,最流行和广泛用于人脸识别的模型之一是VGGF模型由牛津大学VGG小组开发。该模型在庞大的数据集上进行了训练,该数据集包含 2.6K个人的 2.6M 面部图像。VGGF的体系结构由38层组成,从输入层到输出层。输入应该是大小为224×224的彩色图像,并且作为预处理步骤,通常会从输入图像中计算平均值[8]。VGGF包含13个卷积层,每个层具有一组特殊的混合参数。每组卷积层包含5个最大池化层,并且还有15个激活函数单元(ReLU)。在这些层之后,有三个完全连接的层,即FC6,FC7和 FC8。前两个具有4096个通道,而具有1000个通道的FC8用于对1000个标识进行分类。最后一层是分类器,它是一个 softmax层,用于对单个面部类别所属的图像进行分类。

图3 VGGF网络模型Fig.3 VGGF network model
2.2.2 特征提取
CNN在训练阶段学习特征,然后使用这些特征对图像进行分类。每个卷积(conv)层学习不同的功能。例如,一层可以了解诸如图像的边缘和颜色之类的实体,而在更深的层中可以了解更多的复杂特征。在VGGF中,共有37层,其中13层是卷积,其余各层在 ReLU,池化,完全连接层之间混合,最后一层是softmax。但是,将最后一个卷积图层应用于输入图像后,该输入图像具有512个3×3大小的滤镜,可以出于分类目的提取特征[9]。
为了在VGGF模型中确定要用于面部特征提取的最佳图层,通常必须进行多次试验和错误实验。在这种情况下,文献[7]测试了第 34层到第37层,最好的结果来自第34层。值得注意的是,该层是完全连接的层,位于第34层的末端。一个神经网络,意味着提取的特征代表整个面部,在训练和测试中都使用了正面的全脸,获得了100%的识别率。
2.2.3 分类器的选择
监督机器学习中的分类是一种功能,用于分配一组目标类别或类别所属的新观察项。本文采取的分类器是余弦相似度,为了验证本文所选分类器效果的优越性,本文选择了 softmax、余弦相似度(CS)、线性SVM分类器和稀疏表示[12]四个分类器进行实验比较。
余弦相似度(CS)是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦值越接近 1,就表明夹角越接近 0度,也就是两个向量越相似。欧氏点积公式如公式(1)可用于计算余弦相似度,从而

其中,A和 B是两个向量,θ是它们之间的夹角。
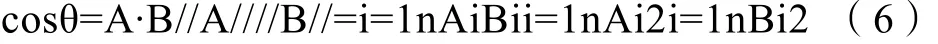
为了进行分类,在实验中,都使用等式计算CS以找到测试图像与训练图像之间的最小距离。
SVM是一种监督型机器学习算法,可用于二进制分类和多分类问题。SVM致力于通过超平面识别边距,以将数据分为几类。 通过在分离的超平面之间创建最大可能的距离,使余量最大化可减少预期泛化误差的上限。显然,SVM可以解决二进制分类问题。 在实验中,使用线性支持向量机来解决基于一对一方法的多类分类问题。至于支持向量机的类型(介于线性核和非线性核之间),根据文献[7]的实验表明,线性SVM总体识别效果要好且计算效率更高。因此该文选择线性SVM。
信号稀疏分解[12]的基本思想是:使用超完备的冗余函数字典作为基函数,字典的选择尽可能地符合被逼近信号的结构,字典中的元素被称为原子。利用贪婪算法或者自适应追踪算法,从字典中找到具有最佳线性组合的很少的几项原子来表示一个信号,也称作高度非线性逼近。本文主要利用字典的冗余特性可以更好地捕捉信号本质特征这一特点,提出分类算法SRC作为分类器[10]。
3 图像修复识别的对比实验
3.1 实验过程
实验过程如图4所示。

图4 方法流程Fig.4 Method flow
文中将遮挡人脸首先通过WGAN进行修复,得到完整的人脸,然后将完整的人脸输入到VGGF网络中提取特征,最后通过分类器进行身份识别。
使用CelebA数据集作为训练集与测试集,数据集包含202599张人脸图片像,尺寸均为178*218,对图像进行预处理。先将图像裁剪成128*128大小,在对抗生成网络中进行训练。实验中选取处理完的15万张图片作为训练集来进行训练,其余作为测试集。同时将CelebA数据集resize成224*224尺寸大小,在VGG16网络中进行训练。进行识别实验时,如图5所示将测试图像遮住一只眼睛、鼻子、两只眼睛、嘴巴、右半边脸以及下半边脸。对其进行修复,修复后的图像通过 resize操作,将尺寸转变为224*224,输入到VGG网络进行识别。

图5 不同遮挡部位Fig.5 Different occluded parts
3.2 实验结果分析
如图6所示,分别是被遮挡图片与修复后图片。我们将被遮挡的人脸图像和修复后的人脸图像分别进行人脸识别,并且使用不同的方法(不同分类器)进行人脸识别,得到的结果如图7和图8所示。

图6 遮挡与修复人脸图像Fig.6 Occluding and restoring face image

图7 不同方法修复前识别Fig.7 Recognition before different restore methods
从图中可以看出,不同部位不同大小遮挡对识别效果都有影响,下半部脸的遮挡对识别效果的影响最大。修复后进行识别的效果要比修复前进行识别的效果好,说明先修复再识别方法可以提高人脸识别的精度。四种方法中使用余弦相似度的效果最好,识别精度最高,说明本文的方法最好。
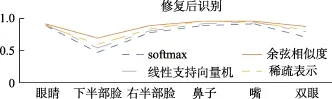
图8 不同方法修复后识别Fig.8 Recognition after different restore methods
综上所述,本文采取先修复再识别的方法,用带有跳跃连接的 WGAN-GP进行人脸修复,用VGG16进行人脸特征提取并采用余弦相似度作为分类器进行识别,所得的效果最优。
4 结论
本文提出了一种新的针对遮挡人脸识别的改进方法,对不同部位遮挡和不同大小遮挡识别率均有提升。这对于刑侦破案、身份验证等方面都有应用价值。采用WGAN-GP来对遮挡人脸图像进行修复,同时在生成器中加上跳跃连接,加强了网络自主学习能力,使生成的人脸图像更加接近真实的人脸图像;然后将生成的完整人脸图片输入到改进的VGG16网络里进行识别,最终得到比较好的识别结果。
