一种结合改进Z-S细化算法的书法字双层检索方法
2020-07-09邵荣堂李婕巩朋成张正文
邵荣堂 李婕 巩朋成 张正文
摘 要:为了高效地识别利用数字化书法作品,文章提出一种改进的Z-S书法字细化算法,结合全局特征与局部特征进行双层索引。首先,利用这种改进的Z-S算法提取单像素无毛刺的书法字图像骨架信息,然后对书法字骨架的GIST全局特征进行初步筛选排序,结合书法字图片局部特征进行二次索引排序,将两种排序结果进行加权计算,得到检索结果。所有的特征数据均使用自学习哈希算法进行二进制编码,索引的过程采用加权海明距离计算的方法。试验结果表明,该方法所需的检索时间相较于骨架相似性检索方法所需时间减少了约50%,相对于自适应书法字图像匹配与检索算法,在查全率和查准率上提升了近10%,提高了大数据量书法字检索的效率。
关键词:细化算法;全局特征;局部特征;自学习哈希;二进制编码;加权海明距离
中图分类号:TP391.43 文献标识码:A 文章编号:2096-4706(2020)02-0007-04
Abstract:In order to effectively recognize and utilize digital calligraphy works,this paper proposes an improved Z-S calligraphy word refinement algorithm,which combines global features and local features for double-layer index. First of all,the improved Z-S algorithm is used to extract the skeleton information of a single pixel and burr free calligraphy image,then the GIST global features of the calligraphy skeleton are preliminarily selected and sorted,combined with the local features of the calligraphy image,the secondary index sorting is carried out,and the two sorting results are weighted to get the retrieval results. All feature data are binary coded by self-learning hash algorithm,and the process of index is calculated by weighted Hamming distance. The experimental results show that the retrieval time of this method is about 50% less than that of the skeleton similarity retrieval method. Compared with the adaptive calligraphy image matching and retrieval algorithm,the recall and precision of this method are improved by nearly 10%,and the efficiency of large amount of data calligraphy character retrieval is improved.
Keywords:thinning algorithm;global feature;local feature;self-learning hash;binary encoding;weighted Hamming distance
0 引 言
書法是极富中华文化的一种文字美的艺术表现形式,然而书法字因其多样的“造型”而难以通过OCR识别[1],其难点在于,书法字主要通过运用笔画的扭曲来营造美感,由此导致笔画变形、不平不直,不同书写风格的笔画连接方式也与印刷体完全不同。
本文提出了一种改进的书法字双层检索方法,首先,采用一种改进的Z-S书法字细化算法,能够快速获得笔画更加平滑、毛刺更少的书法字骨架;提取训练集书法字骨架图像的全局特征与训练集原始书法字图像局部特征,将特征值通过哈希算法进行二进制处理,将这些二进制数值存储为特征数据库;其次,采用由粗到精的检索方式,与原始书法字图像的局部特征与书法字骨架图像的全局特征进行索引,提高识别的准确率;最后,采用自学习哈希算法,将得到的全局和局部特征值转换为二进制编码,加权自学习哈希算法可以在将特征进行二进制处理的同时进行加权计算特征之间的海明距离,使返回的结果更加准确,并提高检索的速度,增强书法字检索的可用性。[2]
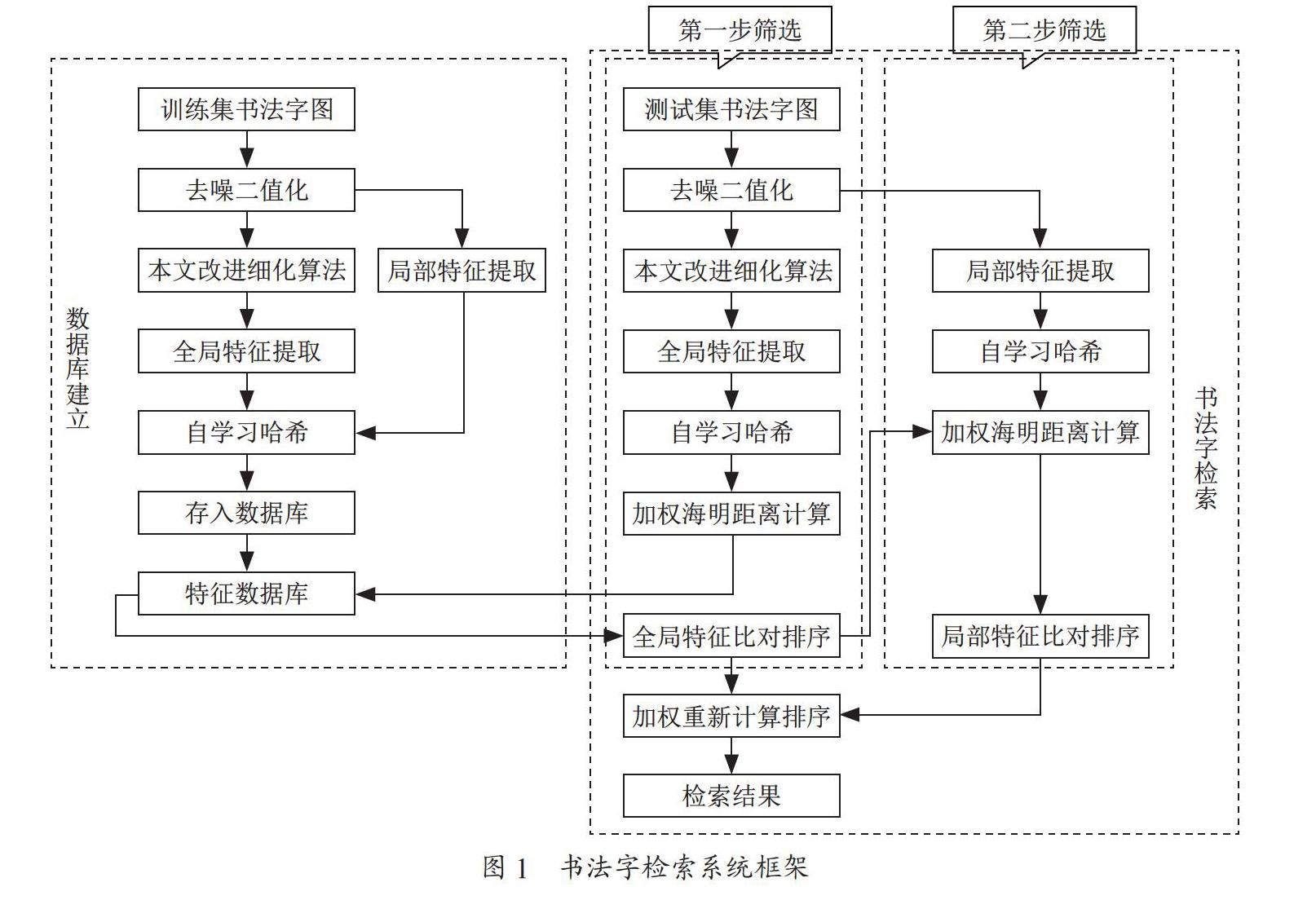
1 系统框架
本文提出的整个系统框架如图1所示,主要分为两步,第一步是建立完备的特征数据库,第二步是构建完整的书法字检索流程。
特征数据库的建立首先将训练集的书法字图像进行归一化去噪二值化等预处理,本文利用一种改进的书法字细化算法对训练集书法字进行处理,将得到的细化图像进行全局特征的提取,然后利用自学习哈希算法对得到的数据进行二进制编码并储存,最后将预处理后的图像进行局部特征的提取,并将得到的数据同样进行二进制编码并储存。最终将两种特征的数据组合储存为本文提出的特征数据库。
书法字检索部分采用由粗到精的方法,首先将测试集书法字图像进行与测试集相同的预处理,利用一种改进的书法字细化算法对预处理后的图片进行处理,并提取出细化图像的全局特征和预处理后图像的局部特征,并将得到的特征进行二进制编码,并与特征数据库进行索引。由于特征向量之间的海明距离可以用来表示数据的相近程度,所以首先通过加权海明距离计算得到全局特征的比对排序结果,并将得到的结果与测试集局部特征再进行一次加权海明距离计算,得到局部特征的比对排序结果,将两种特征的检索结果进行重新加权计算,得到最终检索结果。
2 一种改进的Z-S书法字细化算法
2.1 传统的Z-S快速并行细化算法
传统的Z-S快速并行细化算法,为了去除图像的边界点并保留骨架的关键点,对二值化图像进行运算处理,第一次运算中被删除的点是位于东南边界的像素点和西北角的像素点,第二次运算中删除的点是位于西北边界的像素点和东南角的像素点,不断重复两次运算过程,直到图像中的像素点不再发生变化,即视为处理完毕。
传统Z-S快速并行细化算法处理之后,从上往下并从左往右检测像素点,当检测到像素点之后,将该像素点记为P1,并构建P1的八邻域,点P1的八邻域图中Pi(i=2,3,…,9)表示的8个邻域像素点,像素点的值为0或1。[3]
2.2 基于Z-S算法改进的单像素化处理算法
传统的Z-S快速并行细化算法普遍存在的问题是,笔画在端点与交叉点附近会出现大量的毛刺,影响识别效果,所以在此基础上,本文提出了一种改进的书法字细化算法。首先检测图像像素点的分布情况,当检测到像素点时,建立目标像素点八邻域像素的邻接矩阵,通过判定中心像素点的删除是否影响骨架的连通性,来删除不会破坏骨架连通性的像素点,从而实现单像素化处理,经过这样的处理之后会将交叉点附近与端点附近的毛刺减少。
定义1:检测八邻域垂直方向的像素点,若满足以下四个条件中的任意一种,则删除中心像素点P1:
(a)P2+P8=2,P7=0或1
(b)P4+P6=2,P3=0或1
(c)P8+P6=2,P9=0或1
(d)P2+P4=2,P5=0或1
定义2:检测八邻域水平方向的像素点,若满足以下四个条件中的任意一种,则删除中心像素点P1:
(a′)P2+P4=2,P9=0或1
(b′)P8+P6=2,P5=0或1
(c′)P8+P2=2,P3=0或1
(d′)P6+P4=2,P7=0或1
算法1:删除垂直方向冗余像素点
输入:通过Z-S快速并行算法得到的骨架图像,遍历图像中的每一个像素点,每个像素点的八邻域点记为Pi(i=2,3,…,9);
输出:delete or retain
步骤:
(1)对每一个像素点都建立八邻域,并将中心像素点记为P1;
(2)判断像素点P1及其临近的八邻域像素点是否满足定义1中任一条件:
如果假,返回保留;
如果真,则删除相应的中心像素点P1。
算法2:删除水平方向冗余像素点
输入:通过算法1处理后的图像,遍历所有像素点,每个像素点的八邻域点记为Pi(i=2,3,…,9);
输出:delete or retain
步骤:
(1)对每一个像素点都建立八邻域,并将中心像素点记为P1;
(2)判断像素点P1及其临近的八邻域像素点是否满足定义2中任一条件:
如果假,返回保留;
如果真,则删除相应的中心像素点P1。
在交叉点处被删除的像素点经过改进处理之后,能够在保持骨架的连通性的同时,使交叉处多余的像素点被删除。本文提出的改进后的Z-S算法可以在一定程度上减少细化图像的形变以及毛刺,使细化得出的图像“形态”更贴近于毛笔字的原图。[4]
3 书法字图像特征的提取与检索
3.1 基于GIST算法的全局特征
本文选取GIST特征算法作为书法字全局特征提取的算法,GIST特征是对Gabor特征的改进与拓展,通过多方向尺度的Gabor滤波器滤波后进行级联,该特征特点是可以将一张图片中的信息用低维度的特征向量进行替代。
本文利用一組空间分辨率和方向不同的Gabor滤波器对图像进行滤波(8个尺度,3个方向),然后分割成3×3的网格块来表示滤波之后的图像,对每个网格块进行取均值,构成维度是3×8×3×3=216维的GIST向量。
3.2 基于SIFT算法的局部特征
对于每张图像来说,检测的局部特征点是不同的,单纯利用局部特征进行图像识别会非常耗时,本文先采用全局特征进行识别,然后采用局部特征来进行汉字特征提取。
本文利用SIFT特征算法来进行局部特征的提取,该特征可以依据少量的物体产生大量的特征向量,对于大数据量的特征库而言,该算法的引入可以提高检索结果的准确率。[5]
该算法构造DoG尺度空间,使用不同参数的高斯模糊表示不同的尺度空间,检测在不同尺度空间下都存在的特征点。在每个候选的位置上,通过尺度空间DoG函数进行曲线拟合寻找极值点。基于局部的梯度方向,分配给每个关键点位置一个或者多个方向,后续所有的操作都是对于关键点的方向、尺度和位置进行变换,以特征点为中心、以3×1.5σ为半径的领域内计算各个像素点的梯度的幅角和幅值。在每个特征点周围的邻域内,在选定的尺度上测量图像的局部梯度,得到图像的SIFT特征点。
3.3 加权自学习哈希高维数据索引算法
特征提取后,本文采用了一种加权自学习哈希算法进行索引,算法采用自学习哈希算法框架将原始数据转化为二进制编码并学习得到哈希函数。自学习哈希算法包含两个学习阶段,无监督学习为第一个阶段,主要目的在于把原始空间中的高维数据转成相对较短的二进制编码。有监督学习为第二阶段,把第一阶段获取的所有数据二进制编码视为标签,通过机器学习法训练出多个分类器,查询数据到来时,通过训练出来的分类器将查询数据转化为二进制编码。
在检索方面,因为海明距离可以用来直接计算特征向量之间的距离,用距离的大小表示数据的相近程度,但直接进行海明距离的计算会导致计算距离与真实距离无法明确区分,例如二进制编码“101”与“001”“111”的海明距离都是1,这样直接使用海明距离计算来进行检索就可能出现错误的检索结果。
4 實验结果与分析
本文改进的Z-S书法字细化算法相较于其他传统的骨架提取拥有更少的毛刺和更好的连通性,最大程度上保留了书法字的“形”。在图像特征方面,选取GIST特征与SIFT特征来分别提取骨架图像与原始图像的全局特征与局部特征,在基于GIST特征的全局特征提取时,需提取汉字图片的骨架信息,这样在骨架的基础上进行全局特征提取时,可以避免笔画大面积粘连带来的误操作。本文采用自学习哈希算法对所有特征值进行二进制编码,该算法可以在简化数据的同时仍然保留其原始数据的特征,极大程度上减少了特征库的数据容量大小,加快识别检索的速度,并在检索的时候进行加权海明距离计算,并利用得到的距离大小进行排序,最终将基于两种特征得到的排序结果相结合,重新进行加权计算处理,得到最终索引结果。
4.1 本文书法字检索流程
书法字检索的主要流程分为以下几点:
步骤1:对测试集样本进行归一化去噪二值化等预处理;
步骤2:用本文提出的改进的Z-S书法字细化算法求取骨架;
步骤3:对测试样本进行特征提取,形成特征库;
步骤4:求取测试集样本骨架图像的全局特征,并求取测试集样本图像局部特征;
步骤5:采用自学习哈希算法将步骤4中求得特征值进行二进制处理;
步骤6:用全局特征与特征数据库进行加权海明距离计算,从数据库中查询候选字集合,按距离由小到大进行排序;
步骤7:将步骤6求得的数据集合与测试集进行局部特征的加权海明距离计算,得到排序;
步骤8:将步骤6与步骤7中求得的排序进行重新加权运算,得到最终排序后输出。
4.1.1 特征数据库的建立
本文使用CSDNtinymind数据作为训练集,对每一个书法字图像进行归一化去噪二值化等预处理,并利用改进的Z-S书法字细化算法提取书法字骨架。求取骨架图像的全局特征与原始图片的局部特征。并将求取得到的特征进行二进制编码后存入特征数据库。通过切分大量数字化手写书法字作品,得到3300个书法字单字的图片,并将这些图片进行相同操作存储作为测试集使用。
4.1.2 检索结果
将本文方法检索结果与骨架相似性算法检索结果进行对比,本文采取书法字双层检索的方法,将全局特征索引得到的结果与局部特征索引得到结果进行加权计算,得到最终的索引排序结果。在经过两次筛选之后,会使错误的信息得到删除,使识别准确率得到进一步的提升。
4.2 实验结果分析
本实验采用Visual C作为开发平台,PC配置Intel Core i5-7300HQ四核处理器,16 GB DDR4内存,GTX1050TI独立显卡,Windows 10操作系统。
本实验的主要目的是检测本文方法的检索速度,本文利用自学习哈希算法将所有训练集提取出的特征进行了二值化处理,简化数据库的数据容量大小并加快检索的速率,并在海明距离计算的同时进行加权处理,提高了识别的准确率。
5 结 论
试验结果表明,本文方法在保证检索效率的同时,明显提高了识别的准确性,使书法字检索更具有实用性。本文提出的识别方法在识别速率与准确度上较现有方法有一定程度上的提升,但仍有不足之处,样本中未包含行书与草书等比较难以识别的字体,草书以及行书等样本笔画粘连严重并且不易识别,还需在识别阶段进行新的探索,在实验仪器升级的情况下还可考虑增加更多样本来提高识别的准确率。
参考文献:
[1] 周一枫,张华熊.抗倾斜的中文文本图像文件识别技术 [J].计算机系统应用,2019,28(1):32-37.
[2] 吴媛,杨扬,颉斌,等.基于数学形态学的脱机手写体汉字识别方法 [J].计算机应用,2006(3):622-623+626.
[3] 俞凯,吴江琴,庄越挺.基于骨架相似性的书法字检索 [J].计算机辅助设计与图形学学报,2009,21(6):746-751.
[4] 俞凯,吴江琴.书法字快速多层检索方法 [J].计算机辅助设计与图形学学报,2011,23(8):1415-1419.
[5] 章夏芬,张龙海,韩德志,等.自适应书法字图像匹配和检索 [J].浙江大学学报(工学版),2016,50(4):766-776.
作者简介:邵荣堂(1995-),男,汉族,湖北黄石人,硕士研究生,主要研究方向:模式识别、图像处理;李婕(1984-),女,汉族,湖北宜昌人,博士,讲师,主要研究方向:计算机视觉;巩朋成(1982-),男,汉族,湖北宜昌人,讲师,博士,硕士生导师,主要研究方向:MIMO雷达、频控阵列信号处理以及波形设计等;张正文(1965-),男,汉族,湖北团风人,硕士,副教授,硕士生导师,研究方向:阵列信号处理及其应用。
