基于Neon指令的人脸比对的算法优化方法
2020-07-08朱明李志国
朱明 李志国
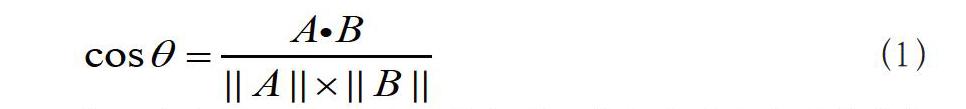

摘 要:对智慧社区建设中占重要地位的安防体系建设进行了深入研究,给出了一种基于Neon指令技术的人脸比对算法优化方法。利用Neon指令集的并行处理优势,在嵌入式ARM平台下,对人脸比对算法进行了效率优化,实现了前端摄像机中人脸识别过程的实时性。采用海思平台Hi3519进行测试验证,结果表明该方法是一种行之有效的方法,有效地提升了人脸比对算法的性能。
关键词:人脸识别;NEON;神经网络
中图分类号:TP391 文献标识码:A 文章编号:1671-2064(2020)06-0055-02
0 引言
智慧社区作为智慧城市建设的一部分,近年来日益受到市场和行业的关注。在智慧社区建设中,安防体系建设又是重中之重。门禁作为社区安防第一线,其重要性不言而喻。回顾门禁系统的发展历程中,比门禁卡更便利的是指纹识别,而比指纹识别更智能的当属刷脸门禁了。而且人脸识别具有唯一性和不易复制性,相比门禁卡和指纹识别,它的造假成本要高出许多,具有更好的安全性。人脸识别就是将待识别的人脸特征与已得到的人脸特征模板进行比较,根据相似程度对人脸的身份信息进行判断。这一过程又分为两类:一类是确认,是一对一进行图像比较的过程,另一类是辨认,是一对多进行图像匹配对比的过程。人脸识别门禁系统就属于辨认过程,比如社区3000人进行了注册,则刷脸过程就是1∶3000的图片匹配对比的辨认过程。因此想要在应用中注册的人脸身份更多,必须保证单次匹配对比过程的速度足够快。然而嵌入式ARM平台下的硬件资源一般有限,提升单次匹配对比过程的效率也就显得十分重要。因此针对嵌入式ARM平台进行图像算法优化研究非常有意义。本文就给出了一种基于Neon指令技术的人脸比对算法优化方法[1]。
1人脸比对算法
“人脸比对(Face Compare)”是衡量两个人脸之间相似度的算法。人脸比对算法的输入是两个人脸特征,即通过算法对人脸图像进行的特征提取,一般是转化的一串固定长度的数值。人脸比对算法的输出是两个特征之间的相似度,一般为余弦距离或欧氏距离的相似度。通过相似度值与设定阈值的比较就可以实现人脸识别,包括一对一的人脸验证和一对多人脸识别[2]。
1.1余弦相似度
余弦相似度用向量空间中两个向量夹角的余弦值作為衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫“余弦相似性”。我们知道,对于两个向量,如果他们之间的夹角越小,那么我们认为这两个向量是越相似的。余弦相似性就是利用了这个理论思想。它通过计算两个向量的夹角的余弦值来衡量向量之间的相似度值。余弦相似度计算公式如下:
分子为向量A与向量B的点乘,分母为所有向量维度值的平方相加后开方的叉乘。余弦相似度的取值为[0,1],值越大表示越相似。如果再将分母进行归一化处理为1,则余弦相似度就可以认为是向量A与向量B的点乘结果。
1.2余弦相似度的函数实现
在实际项目中,利用余弦相似度的分值即可进行人脸识别比对,其函数主要实现如下:
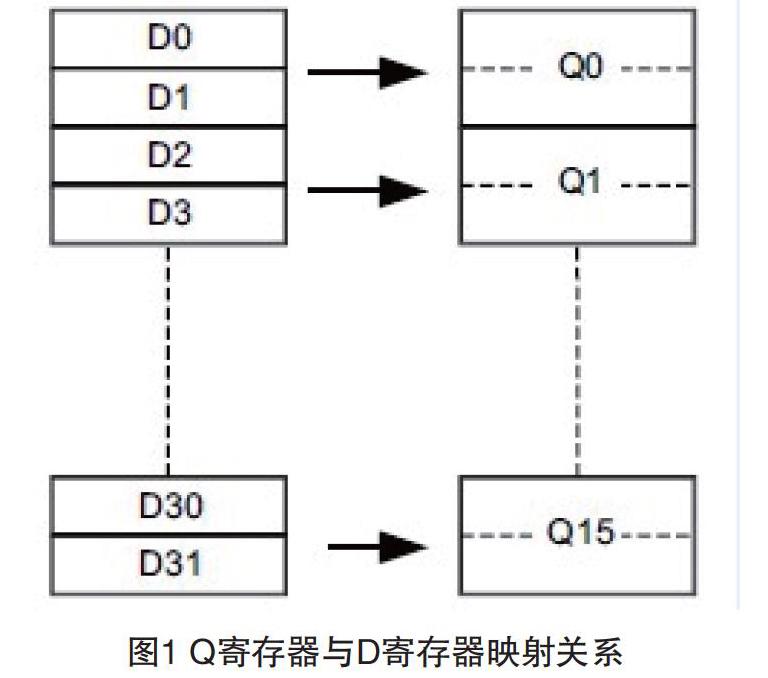
for(inti=0;i { fcos_dist+=pf1[i]*pf2[i]; } 其中fcos_dist变量即为计算得到的余弦相似度分值,pf1和pf2是指向两个特征向量的指针,N为特征向量的长度,在实际项目应用中,一般取N=512。 2 ARM NEON技术 图1 Q寄存器与D寄存器映射关系 ARM NEON就是一种基于SIMD思想的ARM技术,从ARMv7开始被采用,相比于ARMv6或之前的架构,NEON结合了64-bit和128-bit的SIMD指令集,提供128-bit宽的向量运算(vector operations)。NEON的寄存器与VFP是共享的,而且还具有自己独立的执行流水线。 2.1 NEON寄存器 NEON寄存器共有16个128位的向量寄存器构成。而32个双精度浮点寄存器共享了这16个寄存器,32个单精度浮点寄存器共享了前8个寄存器。其中,单精度寄存器用S0~S31表示,双精度寄存器用D0~D31来表示,而128位的SIMD寄存器则用Q0~Q15来表示。图1列举了Q寄存器与D寄存器的映射关系。 2.2 NEON指令集 NEON指令按照操作数类型可以分为正常指令、宽指令、窄指令、饱和指令、长指令。 正常指令:生成大小相同且类型通常与操作数向量相同的结果向量,如VADD指令。 长指令:对双字向量操作数执行运算,生产四字向量结果。L标记,如VMOVL。 宽指令:一个双字向量操作数和一个四字向量操作数执行运算,生成四字向量结果。W标记,如VADDW。 窄指令:四字向量操作数执行运算,并生成双字向量结果。N标记,如VMOVN。 饱和指令:当超过数据类型指定到范围则自动限制在该范围内。Q标记,如VQSHRUN。 NEON指令按照作用可以分为:加载数据、存储数据、加减乘除运算、逻辑AND/OR/XOR运算、比较大小运算等。 2.3 NEON编程基础 在NEON硬件寄存器及其指令集基础上,通过NEON编程的熟练应用,能够对算法代码进行性能优化,从而实现性能的大幅提升,通常使用NEON主要有四种方法:NEON优化库、向量化编译器、NEON内联函数、NEON汇编指令。 根据优化程度需求不同,第4种最为底层,若熟练掌握效果最佳,一般也会配合第3种一起使用。分别简单介绍如下: 第1种方法NEON优化库可以在程序中直接使用,一般OpenMax DL和Ne10优化库中包含很多算法函数的优化实现,供优化人员选用。 第2种方法主要是编译器的向量优化选项,通常在GCC编译器选项中加入向量化表示,有利于C代码生成NEON代码,如-ftree-vectorize。 第3种方法提供了一个连接NEON操作的C函数接口,编译器会自动生成相关的NEON指令。 第4种方法包括两种写法,如纯汇编文件(assembly文件,后缀为“.s”或“.S”)和内联汇编(即在C代码中嵌入汇编,调用简单,无需手动存储寄存器)。 本文针对人脸比对算法的优化,主要采用第3种方法。 2.4 NEON优化技巧 掌握ARM NEON寄存器及其指令集以后,就可以进行算法代码的性能优化了,一般情况下,通过细致的优化,能够获得几倍甚至十几倍以上的性能提升。当然这也需要一定的经验积累,下面简单介绍几点技巧[3]。 (1)要去除数据依赖,不要将当前指令的目的寄存器作为下一条指令的源寄存器。因为ARM架构采用的是多级流水线技术,如果下一条指令的源寄存器是当前指令的目的寄存器,就需要当前指令执行完之后,下一条指令才能取指执行,这样会产生很大的延迟,影响性能。 (2)要减少分支跳转,ARM处理器中广泛使用分支预测技术。但是一旦分支预测失败,性能就会损失很大。 (3)要尽量使用预载指令PLD,它允许处理器告知内存系统在不久的将来会从指定地址读取数据,若数据提取加载到cache中,将会提高cache命中率,从而提升性能。 (4)要关注指令周期延迟,比如对于乘法指令,指令周期比较长,尽量不要立即使用指令计算结果,否则会等待耗时。 (5)要保证数据运算尽量在NEON寄存器中,避免在ARM寄存器和NEON寄存器之间的运算。 2.5 人脸比对函数的NEON优化 本文主要涉及ARM NEON技术的优化内容是人脸识别算法中的人脸比对函数,由前面介绍内容可知,我们所使用的人脸比对函数的核心实现为余弦相似度计算,主要为乘加求和计算[4]。根据余弦相似的函数实现,可以进行打包存取和打包计算,同时利用ARM NEON并行指令,实现算法并行加速,主要代码如下: for(inti=0;i { float32x4_t pf1_t=vld1q_f32(pf1); float32x4_t pf2_t=vld1q_f32(pf2); float32x4_t pf1n_t=vld1q_f32(pf1+4); float32x4_t pf2n_t=vld1q_f32(pf2+4); fcos_dist_t=vmlaq_f32(fcos_dist_t,pf1_t,pf2_t); fcos_dist_t=vmlaq_f32(fcos_dist_t,pf1n_t,pf2n_t); pf1+=8; pf2+=8; } float32x2_t sum_t=vpadd_f32(vget_low_f32(fcos_dist_t),vget_high_f32(fcos_dist_t)); sum_t=vpadd_f32(sum_t,sum_t); fcos_dist+=vget_lane_f32(sum_t,0); 其中,float32x4_t数据类型是一个包含四条向量线的向量,每条向量线包含一个32位浮点数。 vld1q_f32指令(float32x4_t vld1q_f32(_transfersize(4) float32_t const*ptr))是加载并存储4个32位浮点数元素的单个向量。 vmlaq_f32指令(float32x4_t vmlaq_f32(float32x4_t a, float32x4_t b,float32x4_t c))是两个向量元素相乘并将结果进行累加(即Vres[i]=Va[i]+Vb[i]*Vc[i] )。 vget_low_f32指令和vget_high_f32指令是将一个128 位向量拆分为2个64位向量。 vpadd_f32指令是两个向量元素分别按对相加运算。 vget_lane_f32指令(float32_t vget_lane_f32(float32x2_t vec,_constrange(0,1) int lane))是从向量中提取单个元素。 综合上述指令并按上述函数流程,可以实现人脸比对函数的并行优化,大幅提升了算法效率,提升人脸识别相关产品的性能指标及客户体验。 3 测试结果分析 本文算法优化评测的嵌入式ARM平台是海思Hi3519V100,该芯片处理器内核包括A7@800MHz和A17@1.2GHz,支持NEON加速引擎,集成FPU处理单元。 本文在算法优化评测中,所用的特征向量长度为512维,主要验证人脸比对函数在嵌入式ARM平台下优化前后的效率情况,其单位为毫秒(ms)。具体测试数据如表1所示。 结果表明,应用该方法可以有效的提升ARM平台下人脸比对函数的效率,即近3倍左右的提升。此方法适用于各种维度的人脸特征向量的人脸比对过程,特征向量越长,其优越性表现的越明显。 4 结论 本文针对人脸识别算法在嵌入式ARM平臺的应用,研究了基于NEON指令的人脸比对函数的优化方法,利用NEON技术进行并行存取及并行计算,对人脸比对函数的计算过程进行了深入优化,并以海思平台Hi3519为例进行验证,测试结果表明该方法是一种行之有效的方法,较好地解决了人脸识别算法在嵌入式ARM平台中遇到的性能困难,有效地提升了人脸比对函数的性能,及时完成人脸对比功能,特别是注册人脸数N较大的时候,即需要进行N次人脸比对时,效果更加明显,从而实现了人脸识别算法在嵌入式ARM平台应用的实时性。 参考文献 [1] 詹森,D.巴克斯.ARM嵌入式系统编程与优化[M].北京:机械工业出版社,2017. [2] 王文峰.人脸识别原理与实践[M].北京:电子工业出版社,2018. [3] 王天庆.Python人脸识别:从入门到工程实践[M].北京:机械工业出版社,2019. [4] 周立功.ARM嵌入式系统基础教程(第2版)[M].北京:北京航空航天大学出版社,2019.
