基于KPCA和改进K-means的电力负荷曲线聚类方法
2020-07-08梁京章黄星舒吴丽娟熊小萍
梁京章 黄星舒 吴丽娟 熊小萍
(1.广西大学电气工程学院,广西南宁530004;2.广西大学信息网络中心,广西南宁530004)
电力大数据是能源变革中电力工业技术的核心之一,涉及电力系统在大数据时代下管理体制、技术路线和发展规划等方面的重大变革,是新一代智能化电力系统的基石[1]。随着现代电力网络向着规模化、智能化发展,电力负荷数据呈指数级增长的同时也向着高维化发展,如何从海量、高维的电力负荷数据中提取有价值的信息是目前电力系统面临的重要难题[2]。因此,研究科学、有效的电力负荷数据处理技术具有重要意义。
电力负荷曲线聚类是配用电数据挖掘的基础,在供需侧能效管理、异常用户检测、用电客户精细分类等多方面具有重要作用[3]。聚类算法主要包括划分聚类算法、层次聚类算法以及基于密度、基于模型、基于网格的聚类算法等[4]。由于基于模型的聚类算法需要对数据大范围迭代求解,对大规模数据处理速度缓慢,基于网格的聚类算法常用于空间数据处理,对电力负荷曲线这种时间序列数据不适用[5],因此本文主要研究划分聚类、层次聚类以及基于密度聚类这3种算法,其代表性算法分别为 K-means、BIRCH 和 DBSCAN[6]。降维算法分为线性降维算法和非线性降维算法,线性降维算法以主成分分析 (PCA)为代表,非线性降维算法主要包括局部线性嵌入 (LLE)、多维尺度变换(MDS)、等距映射 (ISOMAP)、核主成分分析(KPCA)等[7]。目前,国内外已有许多专家、学者开展了电力负荷数据降维聚类相关方面的研究。文献 [8]提出一种基于改进K-means算法的电力负荷聚类方法,可实现对大量用户负荷数据进行有效分析,但没有结合降维技术进行探究;文献[3]提出结合降维技术的电力负荷曲线集成聚类算法,有效结合降维技术减少聚类运算的时、空复杂度,但选用的降维算法PCA适用于线性降维,而电力负荷曲线主要呈非线性;文献 [9]提出分别采用KPCA和Kernel K-means对用户负荷数据进行降维和聚类,该方法有效提高了负荷曲线聚类的准确性,但缺少对降维、聚类算法性能的对比分析。
针对以往研究多疏于探究降维和聚类方法相结合以提升电力负荷曲线聚类效果的问题,同时考虑到电力负荷曲线主要呈非线性的特点,本文提出聚类精度更高的DK-means(融合密度思想的 K-means)算法,结合非线性降维算法中降维速度较快的KPCA算法,在保证计算效率的基础上实现更加准确的电力负荷曲线聚类工作。
1 DK-means和KPCA算法
1.1 K-means算法及DK-means算法
1.1.1 K-means算法
K-means聚类算法可以阐述为:先从样本集中随机选取K个样本作为类簇中心,计算所有样本与这K个类簇中心的距离,并将其划分到与它们距离最近的类簇中心所在的类别中,所有数据分完算一个迭代步骤完成,随后将每个类簇均值作为新的类簇中心循环上述步骤,直至划分结果不变或达到最大迭代次数为止[10-11]。
1.1.2 DK-means算法
传统划分聚类算法K-means的缺点如下:①聚类超参数K难以确定;②对噪声和异常点敏感;③对非凸数据集的聚类效果不佳;④算法易受数据分布影响,稳定性不强;⑤依赖初始聚类中心的选取,算法易收敛到局部最优解等。针对以上问题,本文在K-means算法基础上引入密度聚类算法思想,提出融合密度思想的 K-means算法 (DK-means算法)。DK-means算法首先通过对比分析聚类有效性评价指标来确定全局最佳聚类数K′,以解决缺点①。
其次,DK-means算法采用式 (1)作为数据间距离的计算公式:

式中,D(i)和D(j)分别表示中心点xi(i=1,2,…,n)及xj(j=1,2,…,n)和最邻近N个数据点距离的平均值。D(i)和参数N在DK-means中近似邻域样本阈值参数MinPts和邻域距离阈值参数∈在密度聚类算法中的思想,用于衡量中心点周围的密度条件,中心点邻近距离参数N根据算法环境调整。式 (1)针对上述缺点②和③,在距离度量时充分考虑中心点周边密度情况,汲取密度聚类算法对噪声点不敏感以及能对任意形状数据集聚类的优点,让DK-means加强对异常点的抗干扰能力,同时增加对非凸数据集的处理能力;针对缺点④,式 (1)将稠密区域的样本点间距增大,将稀疏区域的样本点间距减小,使数据整体分布趋于均匀化,降低数据分布对聚类效果的影响,以此提高整体聚类精度。
针对传统K-means算法在聚类数目确定后,随机选取初始聚类中心进入迭代,易导致聚类划分结果不稳定、迭代步长波动较大、算法陷入局部最优解等问题,即上述缺点⑤,DK-means算法设定初始聚类中心选取规则:首先选取全局密度最大的数据点G,即在N值范围内D(G)最小的点,作为首个初始聚类中心点,之后选取距离已定聚类中心累积距离最远并且满足密度条件的数据点成为后续初始聚类中心点。
DK-means算法初始聚类中心的选取步骤如下。
设数据为X={xii=1,2,…,n},K为聚类数,G点 (全局密度最大的数据点)为首个初始聚类中心点,C={Ckk=1,2,…,K-1},为后续初始聚类中心,S为迭代中按顺序选取的聚类中心候选点,D为每次迭代的计算距离,M为累积距离。α、β为参数值,本文设α=0.25,β=0.33。后续初始聚类中心选取步骤描述如下:
(1)设C=∅,S=∅,M= [],计算所有样本X和G点的距离:D=d(X,G);
(2)定义邻域样本数:Qmin=αn/K,指定最大距离取值点:Dmax=argmax(D),设定邻域Rd=βDmax;
(3)令h=1,开始记录初始聚类中心迭代次数;
(4)令M=M+D;
(5)选择A=xargmax(M)作为第h+1个聚类中心候选点,令S=S∪A;
(6)将D更新为所有样本X和A之间的距离,令M(A)=0,设P为满足D≤Rd的数据点数;
(7)假如P<Qmin,则该候选点不符合密度条件,返回步骤 (5)重新选取聚类中心候选点;假如P≥Qmin,则令D(S)=0,转入步骤 (8);
(8)令C=C∪A,h=h+1;
(9)假如h≤K-1,则返回步骤 (4);否则迭代结束,输出C。
1.2 KPCA算法
核主成分分析算法KPCA[12]是一种非线性主成分评价模型,广泛应用于数据降维研究中[13]。假设原始低维空间 L中有 n个样本 X={x1,x2,…,xn},经Φ:L→F完成向更高维度F空间的投射,设F空间映射数据满足中心化要求,则特征空间F中的数据协方差矩阵可以表示为

对CF做特征向量分析,设其特征值为、特征向量为ν,则有:ν=CFν。因为特征向量ν位于φ(x1),φ(x2)…,φ(xn)张成的空间,所以在CF向量分析式等号两边同时左乘φ(xi)构成新的等价式:
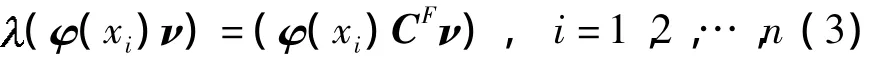
存在系数 αj(j=1,2,…,n),使得代入式 (3)得到:

定义n×n维的矩阵 [Kij]n×n使其可通过核函数来计算:Kij=(φ(xi)φ(xj)),将矩阵K代入式 (4),化简为

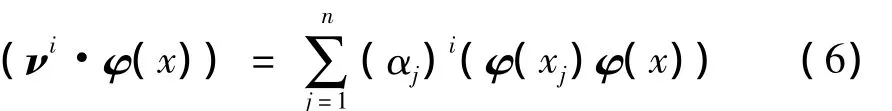
将核函数进行内积替换,有:

以上分析是基于F空间的映射数据满足中心化的情况下,但通常这一情况难以成立。如若不成立,需将核函数K进行如下变换,产生聚集度更高的核函数¯K以满足条件:
式中,In是n×n维的矩阵,同时
2 聚类有效性评价指标
聚类有效性评价指标是评价数据聚类能力的一种测量标准[14],典型的聚类有效性评价指标有误差平方和 (SSE)、Calinski-Harabasz指标CHI、戴维森堡丁指数 (DBI)等[15]。
误差平方和用所有子类点到所在类别聚类中心的距离平方和ISSE表示:
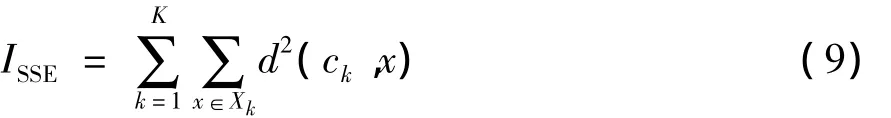
式中:x表示样本数据;ck代表类簇Xk的聚类中心;d(ck,x)为样本数据和聚类中心间的欧式距离。ISSE越小代表聚类效果越好。
CHI(ICHI)以类间离散度 (B)和类内密集度 (W)的比值形式来综合度量聚类质量,其公式为ICHI越大表明数据类间离散度越高,类内密集性越强,聚类效果越好。其中:

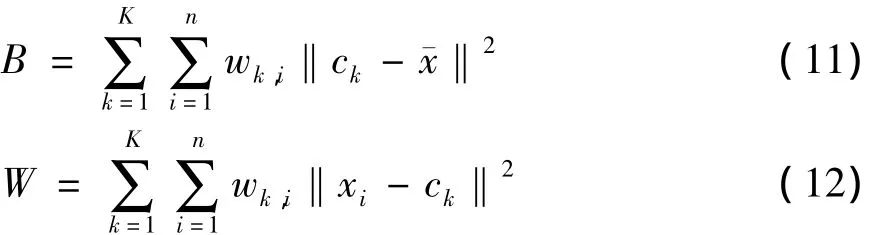
式中:¯x代表所有数据的均值;wk,i代表第i个数据点对第k个类簇的从属关系,可以表示为

DBI指标IDBI综合考虑不同类别间的分散性和同一类别内的紧凑性,计算公式为

式中,
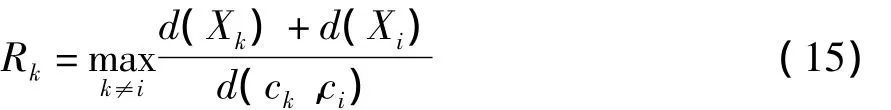
其中,d(Xk)和d(Xi)分别表示Xk和Xi两个类别类内数据到所在类簇中心的平均距离;d(ck,ci)为类别间聚类中心距离,IDBI越小表示聚类效果越好。
3 电力负荷曲线降维聚类算例分析
3.1 实验数据的获取
实验数据取自美国开放能源信息网站 (OpenEI),本文选取美国东部某城市2010年居民住宅用户1768条年度电力负荷曲线建立原始数据库。经数据清洗,保留1701条有效负荷曲线,每条负荷曲线维度为12,建立实验数据集,归一化后的电力负荷曲线总体情况如图1所示。

图1 电力负荷曲线总体分布情况Fig.1 Overall distribution of power load profiles
由图1可知,实验数据集中的电力负荷曲线基本呈非线性,且无明显规律。
3.2 聚类指标选取
对实验数据集做聚类评价指标分析,DBI和CHI两种聚类评价指标和聚类数的关系如图2所示。

图2 聚类评价指标和聚类数的关系Fig.2 Relationship between clustering evaluation indexes andclustering numbers
由图2可知,聚类数K=2时DBI取得极小值、CHI取得极大值,因此确定K′=2为本实验数据集的最佳聚类数。同时,由图2可以观察到DBI指标相较于CHI变化范围更小、数据敏感度更高,因此DBI比CHI更适于作为本实验数据集的聚类评价指标。
分析DK-means算法中心点邻近距离参数N,用DK-means算法将实验数据集聚类至最佳聚类数K′=2输出,N值对聚类效果的影响如图3所示,图中每组数据均为算法运行10次的平均值。

图3 参数N对聚类效果的影响Fig.3 Influence of parameter N on clustering effect
由图3可知,N值变化时SSE基本保持稳定,这说明:①DK-means算法具有较强的稳定性;②算法结果处于最优状态 (结合图2分析可知处于全局最优状态)。当N=8时,平均迭代步长和SSE均取得极小值,此时实验数据集取得最佳聚类效果,确定DK-means算法的参数N在本实验集上最佳取值为N′=8。同等条件下,SSE指标值远大于DBI,数据波动范围较大,比较不便于应用,结合图2分析确定DBI为本实验数据集有效性聚类的主要评价指标。
3.3 聚类效果对比分析
本文选取划分聚类代表算法K-means、层次聚类代表算法 BIRCH、基于密度聚类代表算法DBSCAN、集成聚类算法 EnsClust[3]以及本文提出的DK-means算法共5种聚类算法,对比分析其在实验数据集上的聚类效果,DBI指标同数据集规模的关系如图4所示。
由图4可知,K-means在实验数据集上表现出了较好的聚类稳定性,DBSCAN则在整体聚类精度上表现更佳,DK-means融合了K-means和DBSCAN的优点,在保持算法稳定的同时拥有较高的聚类精度;同DK-means聚类表现最接近的是EnsClust,相比而言,EnsClust的稳定性更强,而DK-means则是整体聚类精度更高;在不同数据集规模下,DK-means的聚类精度高于K-means,展现出其对不同数据集规模和聚类形状更强的适应能力。

图4 5种聚类算法的DBI指标和数据集规模的关系Fig.4 Relationship between DBI indexes and data set sizes of five clustering algorithms
在运算效率上相比,5种算法中K-means的计算速度最快,DK-means与之存在差距,其主要原因是因为DK-means增加了计算复杂度。
综上分析,DK-means具有较高的聚类精度和稳定性,这对电力负荷曲线精确聚类、准确提取用户用电行为模式具有重要应用价值,但在运算速度上还有待提高。
用DK-means将实验数据集精确聚类至最佳聚类数K′=2,结果如图5所示。
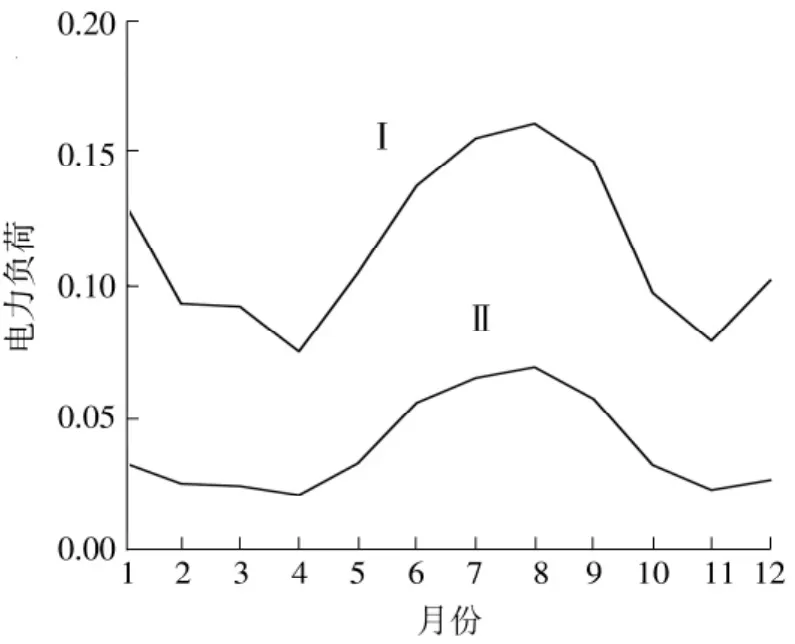
图5 DK-means对实验数据集的聚类结果Fig.5 Clustering result on experimental data set by DK-means
由图5可知,实验数据集聚成的两类用户在用电量上虽相差2~4倍,但在用电行为习惯上相似,都是在6-9月以及1月前后出现用电高峰,属于典型的迎峰度夏、迎峰度冬类型,不过Ⅰ类用户电力负荷曲线波动范围较大,说明其用电行为受季节因素影响较明显。
3.4 降维效果对比分析
当数据规模较大时,采用降维算法不仅可以减少数据的存储空间,而且还能有效提高计算效率。
KPCA算法形式多样,常见的有线性核函数(Linear核函数)、Sigmoid核函数、径向基核函数(RBF核函数)、多项式核函数 (Poly核函数)等。针对电力负荷曲线呈非线性的特点,实验对比上述4种形式核函数的非线性数据处理能力。取3类非线性数据,每类样本1 000个,构成原始数据集。如图6所示,原始数据集展示形式为在空间中相互嵌套的3类球形样本点,图中X′、Y′、Z′构成一组空间直角坐标系。

图6 原始空间中相互嵌套的球形数据Fig.6 Spherical data nested within each other in the original space
分别用Linear、Sigmoid、RBF、Poly 4种KPCA核函数对原始数据集进行降维处理,结果如图7所示,图中 (X′1,Y′1)、 (X′2,Y′2)、 (X′3,Y′3)、(X′4,Y′4)分别代表平面中4组直角坐标系。
从图7可以看出,由Linear核函数降维后的数据在形状和坐标尺寸间隔上都同原始数据相似,因此认定它只是将原始数据做投影;RBF核函数找到合适的投影方向将原始数据从三维降至二维并实现良好聚类,比其他3种算法表现出了更好的降维能力。因此本文选用径向基核函数代表KPCA参与后续实验,其算式为

式中:x和y为空间中任意两点,σ为调整函数径向作用范围的宽度参数。
本文选取KPCA、LLE、MDS、ISOMAP 4种常用非线性降维算法同基础K-means算法结合,在电力负荷曲线实验集上进行降维聚类效果对比分析,在设定聚类数为K′=2的条件下,得到维度和DBI的关系如图8所示。
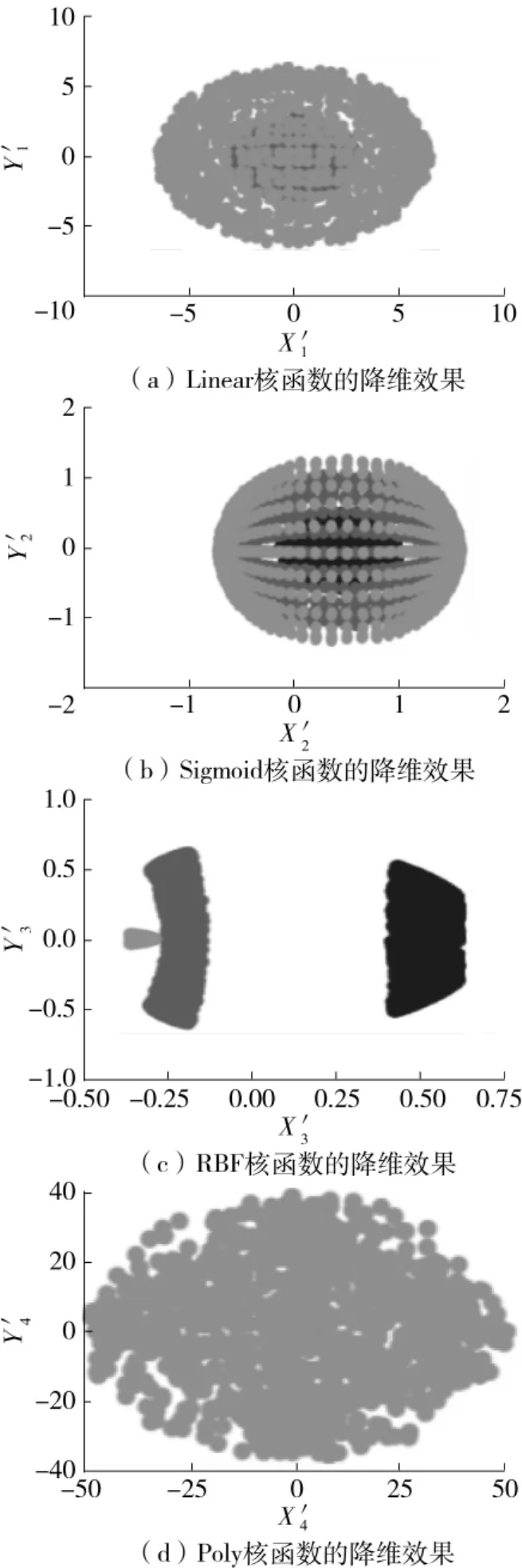
图7 各类型KPCA核函数的降维效果Fig.7 Dimensionality reduction effect of various types of KPCA kernel functions
由图8可以看出,LLE对应的DBI值波动较大,算法稳定性不强。KPCA、MDS和 ISOMAP 3种算法对应的DBI数值较小且曲线稳定,表现出了良好的降维能力;同时,这3种算法在维度为2时DBI都取得极小值,因此确定实验数据集的最佳输出维度为2。
KPCA、LLE、MDS、ISOMAP 4种算法的降维运算时间如表1所示。
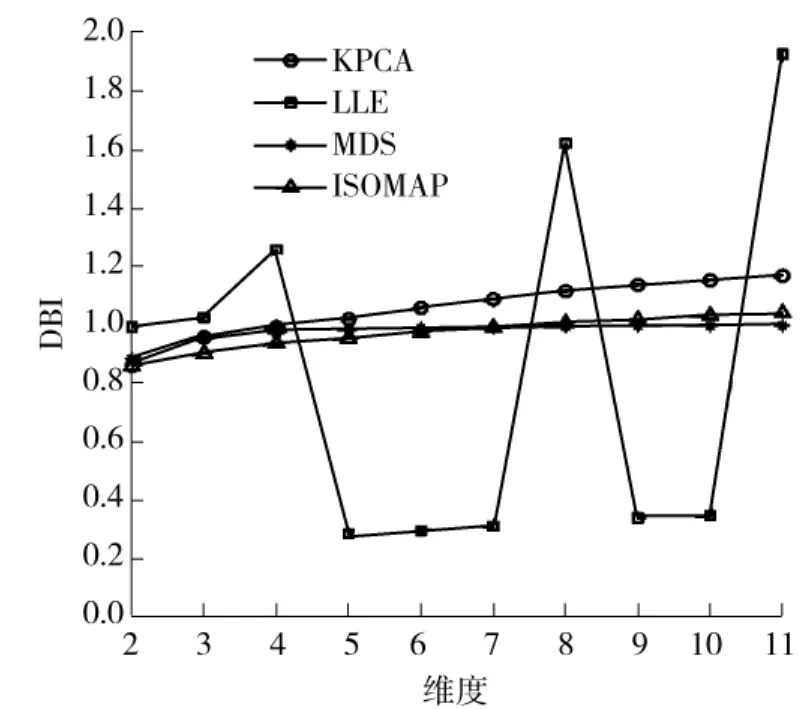
图8 4种降维算法维度和DBI指标的关系Fig.8 Relationship between dimensions and DBI indexes of four dimensionality reduction algorithms
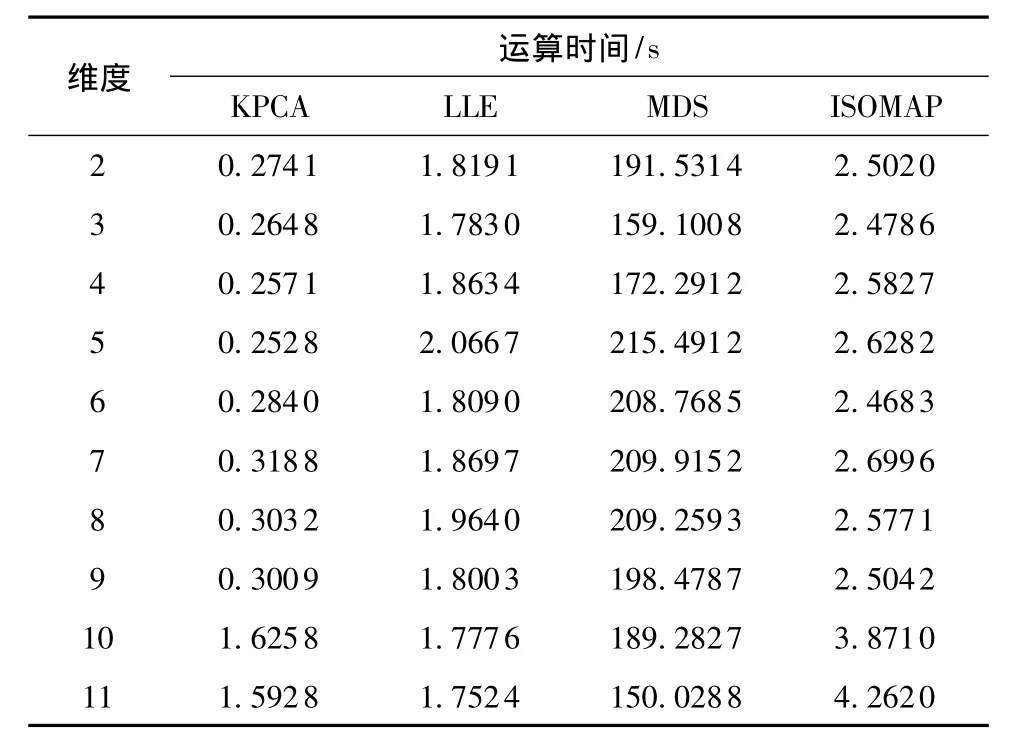
表1 4种降维算法的运算时间Table 1 Computing time of four dimensionality reduction algorithms
由表1可知,KPCA计算速度最快,其平均速度约是ISOMAP的5.2倍,MDS的计算时间远长于其他3种算法。
综上在降维聚类精度和降维速度两方面的对比分析,得出:LLE稳定性不高,MDS计算耗时长,KPCA对实验数据集的综合降维效果较佳。
3.5 降维聚类组合算法效果分析
由3.3和3.4节分析可知,DK-means算法的聚类精度高,KPCA算法的降维速度快,因此先用KPCA将实验数据集降维至最佳输出维度2,此时恰好可以平面可视化,接着用DK-means聚类至最佳聚类数K′=2,结果如图9所示,图中X′和Y′构成平面中一组直角坐标系。
由图9可以看出,实验数据集的二维展示形态为类心形,且为非凸数据集,结合3.3节DK-means在该数据集的聚类精度优于K-means,论证得到DK-means对非凸数据集的处理能力强于K-means。

图9 KPCA+DK-means组合算法的降维聚类结果Fig.9 Dimensional reduction and clustering result of KPCA+DK-means combination algorithm
KPCA+DK-means组合算法和DK-means算法的聚类精度对比如图10所示。
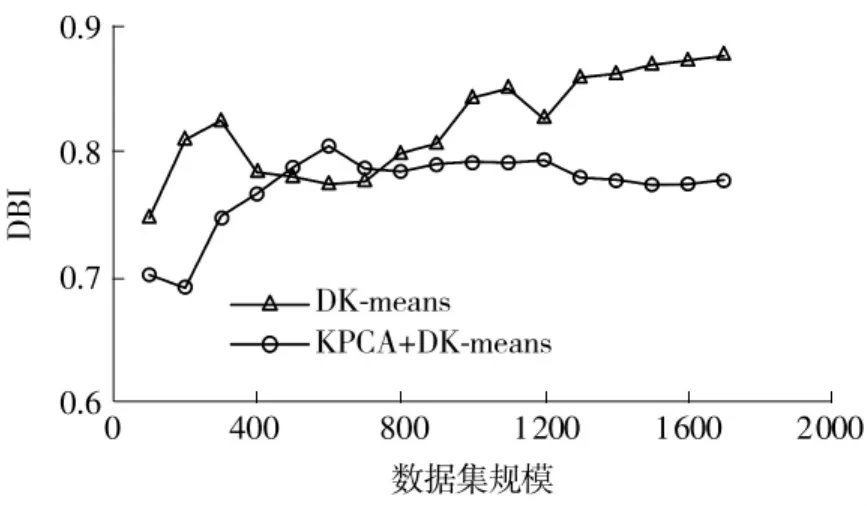
图10 KPCA+DK-means和DK-means算法的聚类精度对比Fig.10 KPCA+DK-means and DK-means clustering accuracy comparison
由图10可知,KPCA+DK-means组合算法的整体聚类精度高于DK-means。同时,在聚类速度对比方面,KPCA+DK-means相较DK-means的聚类效率大幅提升,同KPCA结合在一定程度上弥补了DK-means运算速度不足的缺点。
4 结论
本文针对电力负荷曲线的精确聚类问题,提出基于KPCA和改进K-means的电力负荷曲线聚类方法,通过对比分析得出:
(1)DBI聚类评价能力优于CHI和SSE,并能借助它高效、准确地找出全局最佳聚类数和最佳输出维度。
(2)DK-means在K-means基础上融入密度算法思想,提高了算法聚类精度,聚类精度优于K-means、BIRCH、DBSCAN和EnsClust,同时拓宽了聚类适用范围。
(3)KPCA几种形式中,径向基核函数比线性核函数、多项式核函数、Sigmoid核函数对非线性数据的降维效果好;以径向基核函数 (RBF)为代表的KPCA算法的综合降维能力优于LLE、MDS和ISOMAP。
(4)KPCA+DK-means较DK-means在聚类精度和聚类效率上均有提升。
DK-means算法的复杂度较高、计算时间较长,对DK-means进一步改进和创新将是下一步研究的重点。
