冲突的区间信念结构下基于证据推理规则的群决策方法
2020-07-08张兴贤王应明陈圣群
张兴贤 王应明 陈圣群
(1.福州大学决策科学研究所,福建福州350116;2.福州大学空间数据挖掘与信息共享省部共建教育部重点实验室,福建福州350116;3.铜陵学院建筑工程学院,安徽铜陵244061;4.福建商学院信息工程学院,福建福州350506)
证据理论 (又称 D-S理论),是Dempster在1967年提出的[1],后来由Shafer在1976年对其进一步完善和推广[2],因其能较好地处理决策问题的未知性和不确定性而被广泛应用于专家系统、模式识别、可靠性分析和信息融合等领域[3-6]。证据理论最早用于解决精确值证据组合,这在很大程度上制约了它的发展。在实际决策问题中,由于决策者主观判断的不确定性以及信息的缺乏,决策者很难给出精确的信息表达。例如,某位医生在给病人诊断时,在诊断结果不确定的情况下,他/她很难对病情做出精确判断,在这种情况下,区间信念将是一种理想的信息表达方式。在群决策分析中,不同的决策者 (或专家)提供不同的信念,把决策者不同的信念综合成精确值将不可避免地造成重要信息的丢失,而使用区间信念能够保留决策者的不同观点。因此,区间信念结构下证据理论在信息融合、决策分析中有着广阔的应用前景。
关于区间信念结构 (即区间证据)的组合问题,国内外已有学者进行了深入研究,其研究成果主要分为两类:一类是基于区间算术运算[7-9];另一类则是基于规划模型[10-13]。Lee等[7]首先研究了区间证据组合问题,定义了一类广义的求和和乘法算子;Denoeux[10-11]系统地研究了区间证据的组合和归一化问题,构建了一组二次规范模型;Yager[8]探讨了区间证据的组合和归一化问题,同样也是基于区间算术运算;叶清等[9]提出了与文献[7]类似的区间证据组合方法;Wang等[12]对现有的大多数区间证据组合方法进行分析,指出现有的方法要么忽视归一化,要么将归一化和组合过程分离,从而导致不合理或次优的组合结果,并在此基础上提出一种将归一化和组合过程同时进行的优化方法;此外,为了扩展证据推理方法[14]在多属性决策问题中的应用,Wang等[15]提出了区间证据推理方法,该方法能有效地处理多属性决策问题中不确定的定性和定量信息。由此可见,文献 [12]的方法是当前较为理想的区间证据组合方法。
上述区间证据组合方法适用于无冲突或低冲突的区间证据组合,陈圣群等[13]研究了冲突的区间证据组合问题,指出文献 [12]的方法在组合高度冲突或完全冲突的区间证据时会出现反直觉现象,并提出一种新的区间证据组合方法,通过相对权重来修正原始区间证据,使之符合Dempster组合规则的适用范围,然后组合修正后的区间证据。尽管文献 [13]的方法解决了冲突区间证据组合存在的悖论问题,但是,他们的方法实质上是一种在证据理论框架下的折扣方法,而且在区间证据组合过程中会改变证据的特异性。因为证据理论将剩余支持事先分配给识别框架,这是不合理的[16],因此,有必要进一步研究区间证据组合问题。
基于以上分析,目前国内外学者主要关注无冲突的区间证据组合问题,关于冲突的区间证据组合问题较少研究,特别是在群体决策环境下专家意见冲突的证据组合问题是迫切需要解决的问题。而且,现有的区间证据组合方法[12-13,15]主要是基于证据理论框架或证据推理框架,这些方法都不能真正完全解决区间证据组合问题。为了克服现有研究方法的不足,本文考虑区间信念结构下专家意见冲突的群决策问题,首先由管理者选择专家组成决策小组,依据专家对备选方案的评价信息,形成群体决策问题,将专家对方案的评价信息 (观点)作为证据,检查评价信息的有效性并进行归一化处理;然后依据证据支持度确定专家权重向量,进而运用证据推理规则融合所有专家的评价信息;最后运用最小最大后悔值法[15]选出最优方案。
1 预备知识
1.1 证据理论
设识别框架Θ为N个收集完备并相互排斥的命题或假设所组成的有限完备集,可表示为Θ={H1,H2…,HN},Θ的所有子集用幂集2Θ或P(Θ)表示,P(Θ)=2Θ={∅, {H1},…, {HN},{H1,H2},…, {H1,HN},…,Θ}。若集函数m:2Θ→[0,1],满足:①m(∅)=0,②m(A)=1,则称m为基本概率分配 (BPA)(也称信念结构或基本信念分配),其中,∅为空集,A为Θ中的任意子集,m(A)表示证据对命题A的支持程度,若m(A)>0,则称A为焦元。证据理论的核心是Dempster组合规则,假设m1、m2为Θ上的两个信念结构,则利用Dempster组合规则融合的结果仍是1个信念结构,公式如下:

式中:⊕表示正交和算子;[ m1⊕m2](θ)为基本概率分配;为冲突系数,表示两个证据之间的冲突程度,B、C为识别框架Θ中的子集。
由于Dempster组合规则在组合高度冲突或完全冲突的证据时会出现反直觉结果,为了解决这一问题,Shafer[2]提出证据折扣方法,Smets 等[17]从理论上分析了该方法的合理性。
定义1[16]假设对于识别框架Θ上的基本概率分配m,α(0≤α≤1)为折扣因子,可表示为证据的可靠性或重要性,则折扣后的基本概率分配m′为
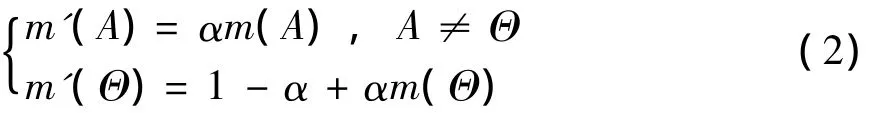
由式 (2)可知Shafer折扣方法将剩余支持1-α分配给了Θ,然后运用Dempster组合规则对折扣后的证据进行组合。
1.2 证据推理
针对多属性决策分析问题,Yang等[14,18]在证据理论和决策理论的基础上,提出了证据推理(ER)方法,ER方法本质上是一种非线性聚合方法。Wang等[15]在证据推理递归算法的基础上进一步给出等价的证据推理解析算法。这里我们简要介绍ER解析算法。
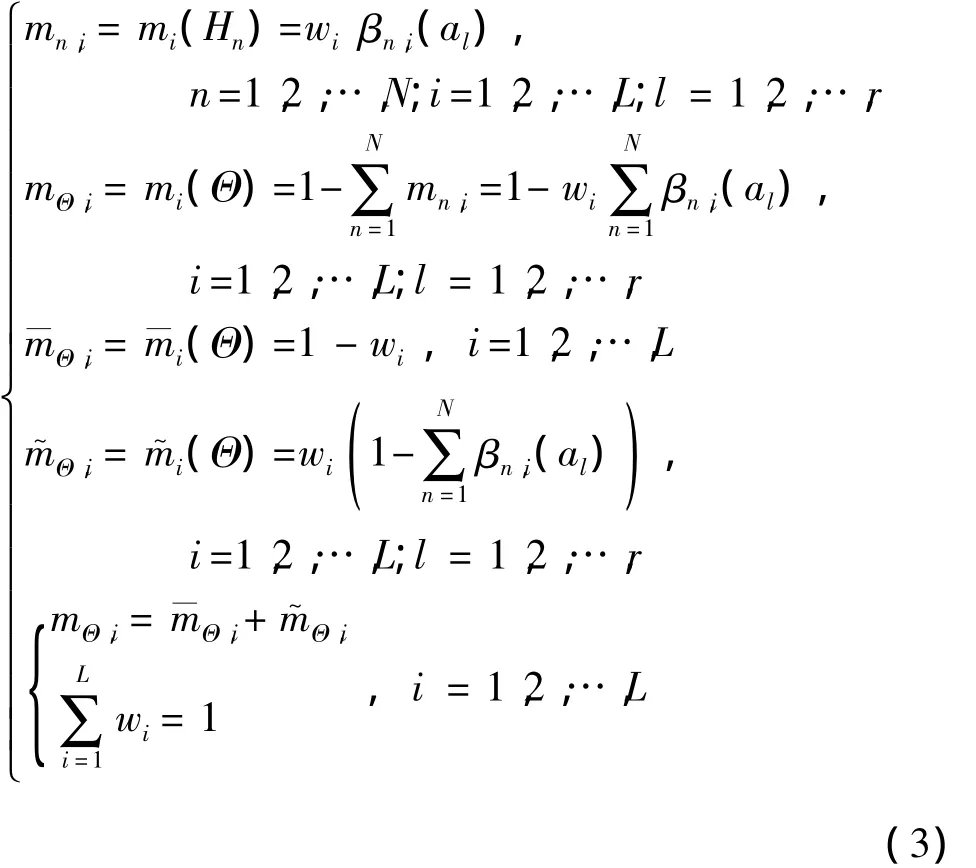
ER解析算法首先将相对权重与信念结合,利用如下公式将原始信念转化为基本概率mass函数:式中,βn,i(al)表示方案al的第i个属性评估到等级n的信念,wi为第i个属性的相对重要性权重,mΘ,i没有分配给任何单个命题,而是分为 m—Θ,i和m~Θ,i两部分,其中 m—Θ,i是由属性 i的相对重要性引起,m~Θ,i是由于方案al在属性i上的评价不完全引起的。
然后,利用下列解析公式将L个基本属性上的基本概率mass函数组合成一个集结的基本概率分配:
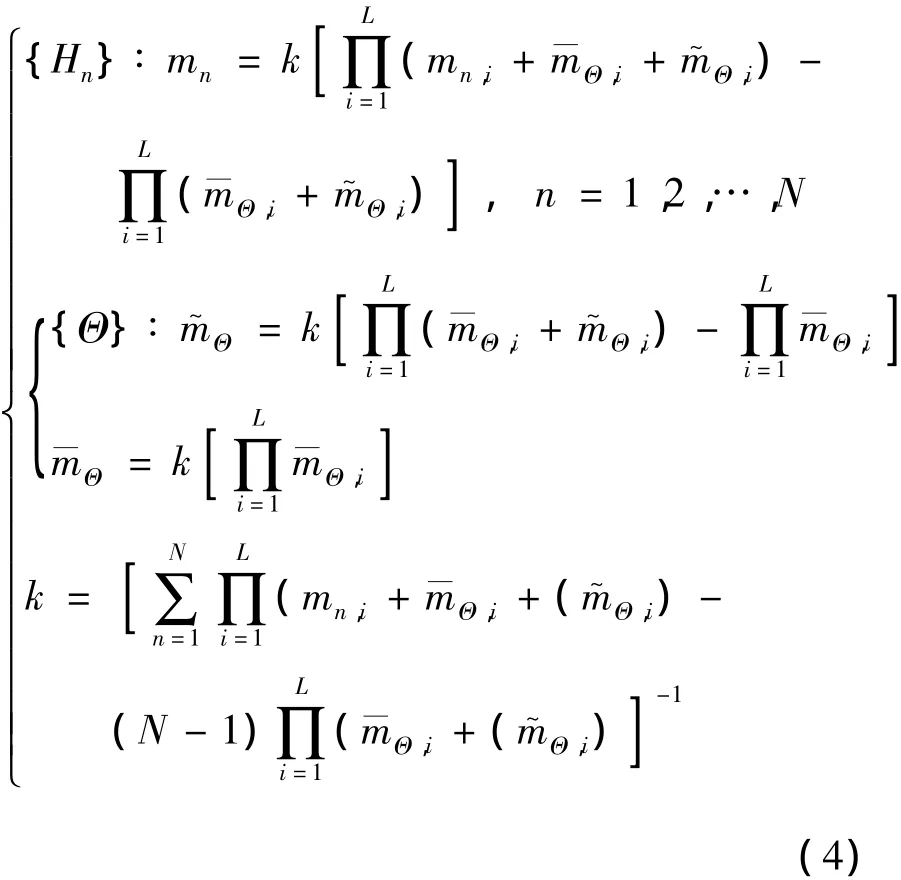
最后,利用以下公式将集结的概率分配归一化为总体信念:

其中,βn和βΘ分别代表评价等级n和识别框架Θ集结评估的总体信念。上述式 (4)、(5)共同构成1个完整的ER解析算法。与Dempster组合规则相比,ER解析算法至少具有以下3点优势[15]:①考虑了证据的相对重要性;②能够清晰地对无知进行建模,将未分配的概率mass函数mΘ,i分解成
m—Θ,i和 m~Θ,i两部分,并区别对待;③在多个冲突证据的组合过程中得出合理结论。
1.3 ER规则
在ER解析算法中,信念分布只考虑了全局无知,而ER规则更具有一般性,一般来说,在ER规则中证据ei的信念分布可表示为

其中,(θ,pθ,i)是ei的一个元素,表示证据指向命题 θ的信念为 pθ,i。如果 pθ,i> 0,则 (θ,pθ,i)称为ei的一个焦元。在式 (6)中,信念分布同时考虑了局部无知和全局无知。
ER规则使用一种新的证据预处理方法,即加权信念分布。假设wi(0≤wi≤1)为式 (6)中定义的证据ei的权重,其中wi=0和wi=1分别表示“不重要”和“最重要”,则其加权信念分布定义为

mθ,i称为基本概率mass函数或 ei支持命题 θ的程度。不同于Shafer的折扣方法,在式 (7)中,证据ei的剩余支持 (1-wi)名义上是附加到幂集P(Θ)上而没有被预先分配给Θ的任何特定的命题。剩余支持从而可以分配给所有命题,因为对于任何θ⊆Θ,θ∩P(Θ)=θ。这样可以保证在证据组合过程中能进行真正的合取推理。
假设e1、e2为定义在式 (6)上的两个信念分布,权重分别为w1和w2,运用ER规则对e1和e2进行组合运算,可由下式表示:
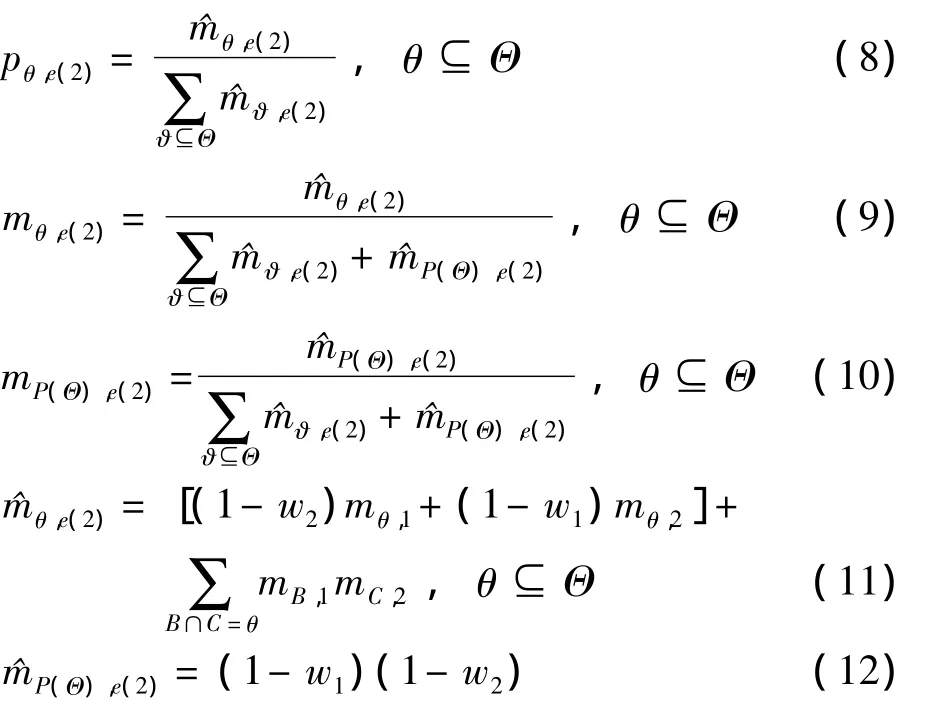
式中,ϑ为识别框架Θ中任意子集,mθ,e(2)表示两个证据e1和e2联合支持命题θ的组合概率mass函数,满足 0≤mθ,e(2)≤1 且 0≤mP(Θ),e(2)≤1。pθ,e(2)为两个证据联合支持命题θ的组合信念。式 (9)和 (11)分别表示两个加权信念分布进行正交和运算后的标准化和非标准化的概率mass函数;式 (10)和 (12)分别表示两个加权信念分布进行正交和运算后的标准化的剩余支持和非标准化的剩余支持。最终两个证据组合的信念由式 (8)计算得到。
1.4 区间信念结构
目前,有关区间信念结构的定义主要基于De-noeux[10]和 Wang 等[12,15]的研究工作。
定义2[10]设Θ={H1,H2,…,HN}为识别框架,F1,F2,…,Fs是Θ上的s个子集,区间值[ut,vt]满足0≤ut≤vt≤1(t=1,2,…,s),则 Θ上的区间信念结构m满足:①ut≤m(Ft)≤vt,其中0 ≤ut≤vt≤1(t=1,2,…,s);②1;③ m(A)=0,∀A ∉ {F1,F2,…,Fs}。
定义3[12,15]设Θ上的区间信念结构m(At)∈[ut,vt](t=1,2,…,s)是有效的,如果对∀t∈{1,2,…,s},ut和vt同时满足和,则区间信念结构m是归一化的。
对于有效但非归一化的区间信念结构m可由下式对其进行归一化处理[12]:
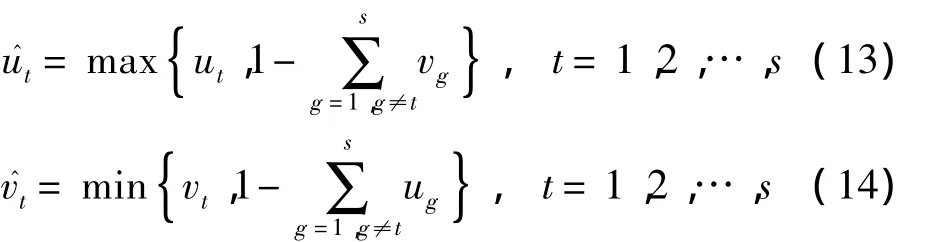
2 决策方法
2.1 问题描述
本文考虑区间信念结构下专家意见冲突的群决策问题,提出一种冲突的区间信念结构下基于证据推理规则的群决策方法。首先,由管理者选择专家组成决策小组,依据决策者 (或专家)对备选方案的评价信息 (观点),形成一个群体决策问题。将专家对方案的评价信息作为证据,检查专家评价信息是否有效并做归一化处理;然后,依据证据支持度确定专家权重向量,并运用证据推理规则融合所有专家对方案的评价信息;最后,运用最小最大后悔值法选出最优方案。
该区间信念结构下群决策问题描述如下:假设r个备选方案al(l=1,2,…,r)构成的方案集X={a1,a2,…,ar},由q个决策者 (或专家)yc(c=1,2,…,q)组成的决策小组对r个方案进行排序或择优。w=(w1,w2,…,wq)T,为决策者 (或专家)的权重向量,满足0≤wc≤1且。文中考虑专家yc对方案al的评价值采用区间信念=[(),()]描述,则专家yc对方案al的决策矩阵Dc=()r×q可表示为
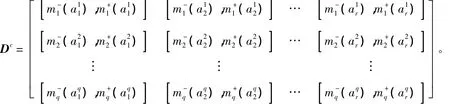
本文要解决的是根据决策矩阵Dc=(),r×q依据mass函数定义,将专家yc对方案al(l=1,2,…,r)的评价值= [),()]作为证据信息,考虑专家的相对重要性权重,运用证据推理规则融合不同专家对方案的评价信息并对方案进行排序或择优。
2.2 专家权重的确定
在现实的群体决策环境中,专家往往存在不同意见,甚至意见差别很大,而且考虑到并不是所有专家的意见都是可靠的[19],因此本文采用证据支持度确定专家权重,其核心思想是:根据不同专家之间意见的差异或冲突程度,赋予不同的权重。冲突程度较小,即综合支持程度较高的专家分配较高的权重;反之,分配较低的权重。对证据冲突程度的度量主要采用证据距离。
Pignistic概率距离是很好的证据距离度量方法[20],它不仅考虑了证据间的关系,而且考虑了焦元之间的相关性。Pignistic概率函数和Pignistic概率距离的定义如下。
定义4[20]设 m是识别框架 Θ上的BPA函数,它的相关Pignistic概率分布函数BetPm:Θ→[0,1]定义为

其中, θ为子集θ的基数,BetPm函数可以扩展到幂集2Θ上,由式 (15)可得

定义5[21]设ma、mb为识别框架Θ上的BPA函数,BetPma、BetPmb为对应的Pignistic转换后的概率函数,则
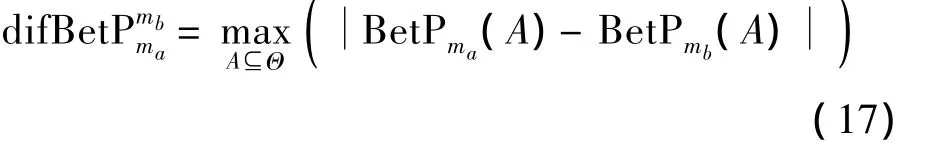
称为ma和mb之间的Pignistic概率距离。
为了便于计算,文献 [22]给出了Pignistic概率距离的等价定义。
定义6[22]设 BetP(θ)为证据 m(a=1,
maja
2,…,h)第j(j=1,2,…, Θ )个单命题焦元θj的Pignistic概率函数值,则ma和mb之间的Pignistic概率距离为
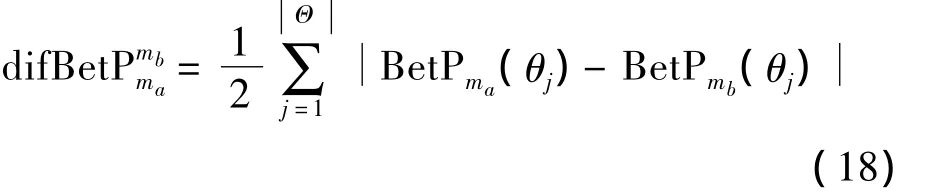
推论1 若证据ma和mb为精确值证据,则ma和mb之间的Pignistic概率距离为

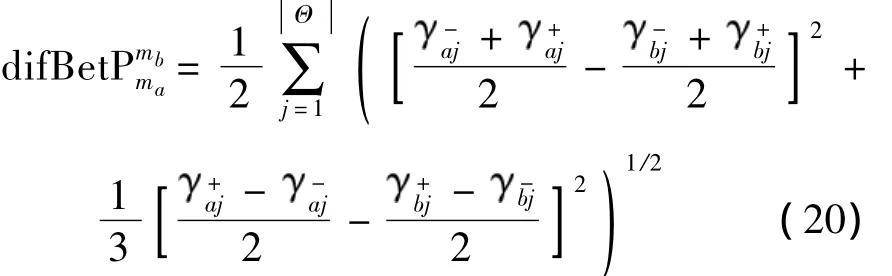
定义7 设ma、mb为识别框架Θ上的区间信念结构,difBet为 ma和mb之间的Pignistic概率距离,则ma和mb之间的相似度为

定义8 设h个定义在识别框架Θ上的区间信念结构,Sim(ma,mb)为ma和mb之间的相似度,则区间证据ma的支持度为
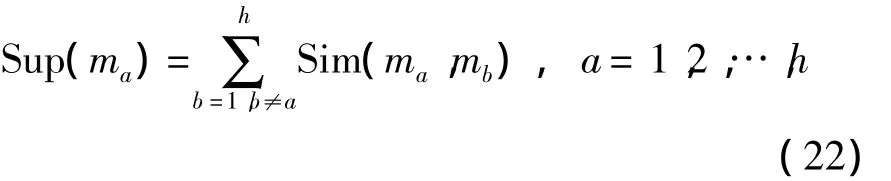
定义9 设h个定义在识别框架Θ上的区间信念结构,Sup(ma)为区间证据ma的支持度,则区间证据ma的可靠度为
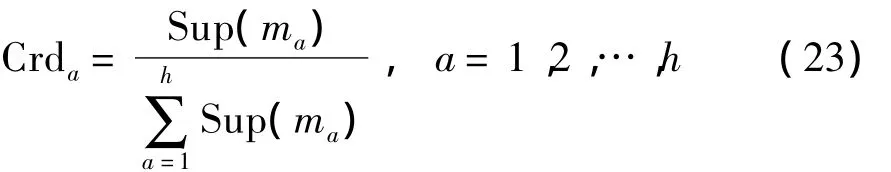
由定义9可知,区间证据的可靠度实际上就是区间证据的相对重要性权重,即
2.3 区间证据组合优化模型
为了克服现有区间证据组合方法的不足,提出一种基于ER规则的区间证据组合优化模型,定义如下。
定义10 设m1,m2,…,mh为h个定义在识别框架 Θ 上的区间信念结构,且≤mθj,i≤(i=1,2,…,h;j=1,2,…,hi),其中 hi为命题个数,mθj,i表示第 i个区间信念结构的第 j个焦元的概率mass函数,则组合后m1⊕m2⊕…⊕mh的结果仍然是1个区间信念结构:

其中 (m1⊕m2⊕…⊕mh)-(θj)和 (m1⊕m2⊕…⊕mh)+(θj)分别为如下优化模型的最小值和最大值:


式中,pθj,e(i)表示前i个区间证据组合后的信念,wi(1,2,…,h)表示第i个区间证据的相对重要性权重。需要指出的是,上述优化模型在多个区间证据递归组合过程中同时考虑了区间证据的组合和归一化问题,以便获得每个焦元真正的概率mass区间。同时,模型 (25)中的剩余支持1-wi分配给了识别框架Θ的幂集P(Θ),而不是事先指定分配给某一个命题,这使得组合后的区间信念结构的特异性能够得以保持。此外,模型要求满足0≤
2.4 冲突的区间信念结构下基于证据推理规则的群决策方法步骤
综上,冲突的区间信念结构下基于证据推理规则的群决策方法的具体计算步骤如下。
步骤1 首先由管理者邀请q个专家组成群决策小组,列举出所有的r个备选方案构成识别框架,每位专家分别给出r个备选方案的评价信息(区间信念结构形式表示),以形成一个群体决策问题Dc=(dcl)r×q;
步骤2 将专家对方案的评价信息作为证据,检查评价信息的有效性,并根据式 (13)和 (14)对专家评价信息做归一化处理;
步骤3 运用式 (21)-(23),求出专家的相对权重向量;
步骤4 运用式 (25),求出融合所有专家对方案评价信息的最小值和最大值;
步骤5 运用最小最大后悔值法[15]选出最优方案。
3 实例分析
众所周知,在医学诊断中,处理不确定性是最重要、最困难的任务之一。然而,大多数现有的医学诊断方法不能提供其结果的不确定性或确定性。实际上,在文献 [13]中提出的方法被应用于医疗诊断问题的管理中,特别是那些需要给出不确定性度量的问题,在本节中,本文提出的方法也适用于解决这一问题。分析结果表明,本文提出的方法是一种可行的、有效的新方法,最重要的是,本文提出的方法能够有效融合冲突的专家诊断信息。现在考虑来自文献 [13]中的医疗诊断问题,假设病人的头痛症状仅仅与 {脑膜炎,脑震荡,脑肿瘤}3种病因有关,分别表示成H1=脑膜炎,H2=脑震荡,H3=脑肿瘤。某个常年患头痛的病人咨询了5位专家医生,所获得的诊断结果如表1所示。从表1数据可以看出第2位专家医生与其他4位专家医生的诊断结果存在明显的冲突。现在,最重要的任务是根据诊断结果给病人确诊病因。

表1 诊断结果的信念结构Table 1 Belief structures of diagnosis results
3.1 计算步骤
步骤1 为了给病人确诊病因,将5位专家医生组成决策小组,构建识别框架Θ={H1,H2,H3},依据各个专家医生对病人患病的诊断结果,形成一个群体决策问题;
步骤2 把专家医生的诊断信息作为证据,根据定义2和定义3可知5位专家医生的诊断结果均有效且满足归一化要求;
步骤3 运用式 (21)-(23),求出5位专家医生的相对权重向量为w=(w1,w2,w3,w4,w5)= (0.222 0,0.072 3,0.235 2,0.235 2,0.2352);
步骤4 运用式 (25),求出融合5位专家医生对病人诊断结果的最小值和最大值,见表2;
步骤5 由最小最大后悔值法可知该病人患头痛症最可能的病因是脑膜炎,见表2。
3.2 对比分析
由表2的最终组合结果可以看出,文献 [12]的方法得到的组合结果表明该病人患“脑震荡”和“脑肿瘤”的概率较大,而患“脑膜炎”的概率为 [0,0],然而由表1的原始专家诊断结果可知m1、m3、m4和m5支持病人患“脑膜炎”的概率较大,很显然文献 [12]的方法得到的组合结果是不合理的。文献 [13]的方法得到的组合结果表明该病人患“脑膜炎”的概率最大,这是符合直觉的,虽然文献 [13]的方法能有效克服区间证据组合过程中的反直觉行为,但是,该方法改变了证据的特异性,例如在表2中,证据m1和m2组合后,m12(Θ)= [0.022,0.031],而组合前表1中的原始证据m1和m2没有任何未知,即m1(Θ)=m2(Θ)= [0,0],因此文献 [13]的方法得到的组合结果是不合理的。本文方法由式 (21)-(23)得到5位专家医生的权重向量为w=(0.222 0,0.0723,0.2352,0.2352,0.2352)。其中,第2位专家医生的权重w2=0.0723,这是因为证据m2与其他证据m1、m3、m4和m5之间存在较大冲突,所以得到其他证据的支持较小,因此权重最小,从而降低了它在组合过程中的干扰。同时,从表2中不难看出,运用本文方法在分别组合前两个证据、前3个证据和前4个证据的过程中得到的组合结果与最终的组合结果始终保持一致,即诊断病人患“脑膜炎”的概率最大,这表明本文方法有较好的收敛性,且抗干扰性强,有利于专家决策。

表2 组合结果对比 (专家权重不等)Table 2 Comparison of combined results(unequal weights of experts)
为了进一步验证本文方法的一般性,将基于证据理论、证据推理和证据推理规则3种理论框架下的方法进行比较。不失一般性,假设5位专家医生的权重都相等,即w=(0.2,0.2,0.2,0.2,0.2),组合结果如表3所示,从表3可知,文献 [12]和文献[13]的方法得到的组合结果相同,这是因为文献[13]的方法实质上是一种证据理论框架下的证据折扣方法,当证据权重都相等时,文献 [13]的方法退化为文献 [12]的方法。而文献 [15]的方法和本文方法得到的组合结果是合理且符合直觉的,当证据m1和m2组合时,诊断为“脑震荡”的概率最大。当证据m3被组合时,诊断为“脑膜炎”的概率增长较多,当证据m4被组合时,诊断为“脑膜炎”的概率最大并与最终组合结果保持一致。同时,由表3可知,本文方法与文献 [15]的方法得到的组合结果一致,当证据的相对重要性权重都相等时,本文方法退化为文献 [15]的方法。同时,从表3中不难看出,当专家的权重都相等时,运用本文方法得到的组合结果依然保持较好的收敛性,即在分别组合前两个证据、前3个证据和前4个证据的过程中得到的组合结果与最终的组合结果都诊断病人患“脑膜炎”的概率最大。
基于以上对表2和表3的分析可以看出,在专家意见冲突的情形下,运用本文方法得到的证据组合结果是合理的、收敛的,而且能保持证据的特异性。
4 结论
本文考虑区间信念结构下专家意见冲突的群决策问题,由管理者选择专家组成决策小组,依据专家对备选方案的评价信息,形成群体决策问题,并将专家对方案的评价信息 (观点)作为证据,提出一种证据支持度方法来有效确定专家权重向量,使得融合所有专家评价信息的决策结果更贴近现实;然后提出一种基于ER规则的区间证据组合优化模型融合所有专家的评价信息,并运用最小最大后悔值法选出最优方案;最后将本文提出的方法用于解决医疗诊断问题。案例分析结果表明:本文方法能有效克服反直觉现象,具有较好的收敛性,而且能保持证据的特异性;同时,本文方法更具有一般性,可用于组合识别框架的任意子集。
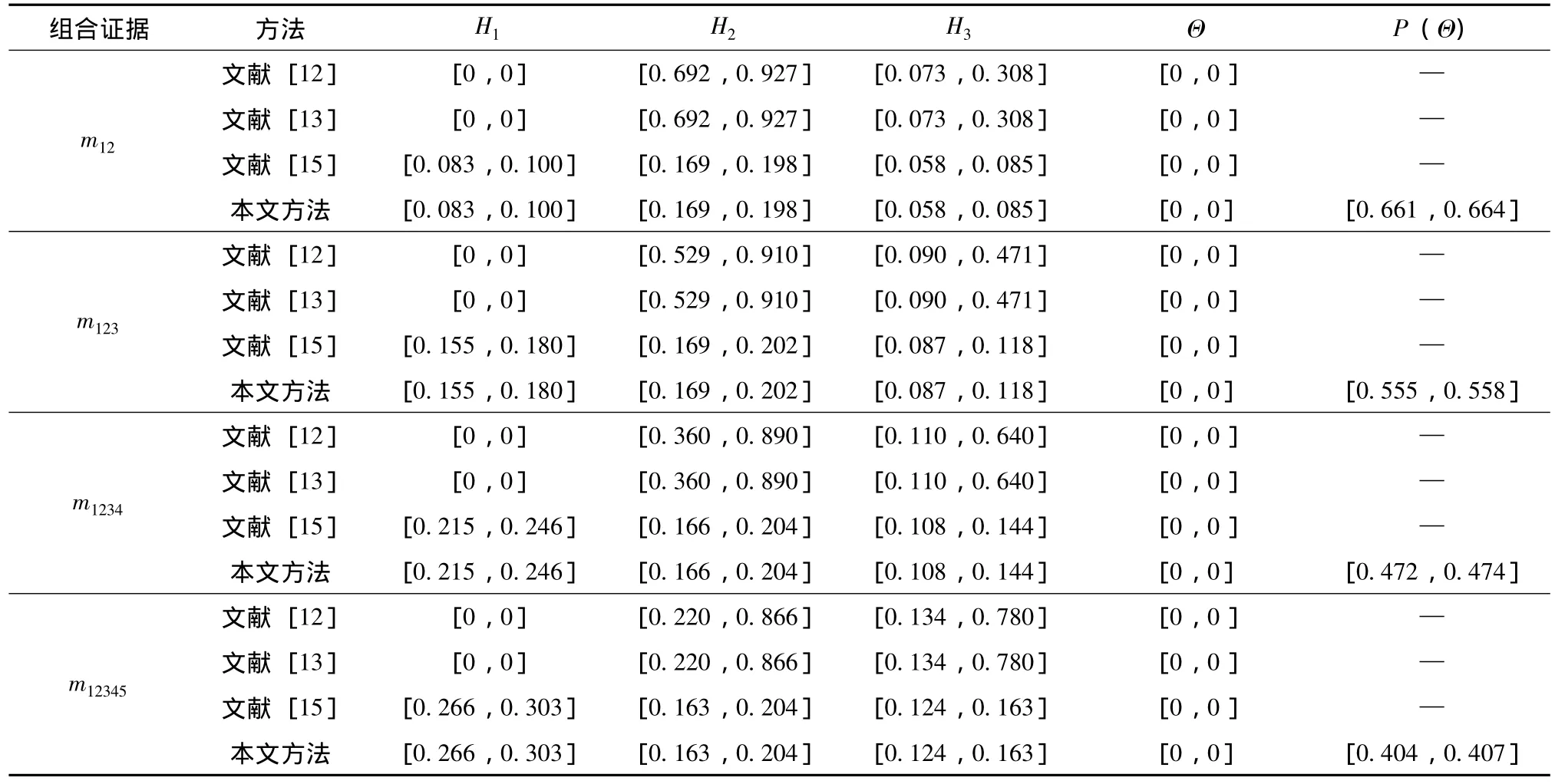
表3 组合结果对比 (专家权重相等)Table 3 Comparison of combined results(equal weight of experts)
