基于足迹图像的FtH-Net预测身高方法
2020-07-08王年樊旭晨张玉明鲁玺龙陈峰
王年 樊旭晨 张玉明 鲁玺龙 陈峰
(1.安徽大学电子信息工程学院,安徽合肥230601;2.公安部物证鉴定中心,北京100038)
足迹识别是指根据足迹信息来确定身高、年龄、性别等身份信息。近年来,足迹识别被广泛运用在刑侦与法医等领域,利用足迹信息快速、准确地得到人员的身份信息对案件的侦破以及法医鉴定有着重大意义[1]。其中身高信息是身份信息中最为重要的,同时基于足迹信息的身高预测也是足迹识别领域的难点。
传统的基于足迹信息预测身高的算法大多是基于足迹图像获取脚长、脚宽等特征信息,之后建立特征信息与身高的回归方程[2-5]。随后,人们以该算法为基准,相继提出了一些新的算法。例如增加特征的种类和数量,文献 [6]提出在脚长、脚宽的基础上增加脚掌区域的面积和拓宽的长度,有效地提升了预测的准确性;文献 [7-8]提出一种基于鞋印预测身高的方法,通过将鞋底类型按照相应公式转化为脚部特征来预测身高,该方法的弊端在于需要依据鞋底类型来确定参数,但是一般情况下根据鞋印图像很难判断出鞋底类型;基于足底压力图像结合CNN(卷积神经网络)、SVM(支持向量机)等方法进行身份识别[9-10],该方法由于足底压力图像获取方式相对复杂且成本高昂,所以实用性有所欠缺。上述方法虽然能在一定程度上基于足迹图像预测出身高,但是由于足迹特征的有效提取依赖于手工标注,并且实验样本较少,所以最终得到的回归方程准确率低、泛化能力弱。
近年来深度学习技术飞速进步,并被广泛应用于回归问题中,诸如人群计数[11-13]、年龄预测[14-16]等。在上述问题中,诸如图像随机缩放的数据增广方法可以提升模型的准确率和泛化能力,但是对于足迹预测身高这一问题,该操作会导致模型无法收敛。本文在总结当前方法所存在问题的基础上提出一种新的算法。该算法首先进行图像的预处理,包括对采集到的5000张足迹图像进行全自动数据清洗、进行有效区域提取以及旋转与中心化;然后根据足迹数据的特性构建FtH-Net框架,结合FtH-Net的训练目的定义了损失函数;最后将数据处理结果按照特定比例划分为训练集和测试集并输入网络参与训练和测试。
1 足迹图像的预处理
1.1 数据来源
本文所使用的采集设备为足迹捺印采集仪,该设备可以采集到类似油墨捺印的足迹图像。样本数据采集自500名成年男性,平均每人左右赤脚共采集10张,共计5000张足迹图像。在数据采集过程中,由于电流干扰、个人站立姿势不同,部分图像存在噪声且足迹位置分布不一致,如图1所示,图1(b)中足迹位置分布有偏移且含有少量噪声。

图1 原始图像示意图Fig.1 Schematic diagram of raw data
1.2 数据清洗
考虑到在录入身份信息的时候可能会存在一些人为错误,本文对初期筛选出的5000张图像进行了数据清洗工作。首先剔除身高异常数据 (身高低于140cm或大于190cm的样本),剔除异常数据后样本集的身高-密度分布曲线如图2所示,可知样本集的身高-密度分布曲线近似服从正态分布,同时证明了样本选择以及数据采集的有效性。需要说明的是,本文针对1.1节得到的图像,在数据清洗阶段进行了滤噪操作并统一去除了图像左侧的标尺。

图2 身高-密度分布曲线Fig.2 Curve of height-density distribution
1.3 图像的中心化以及旋转
本文所使用的采集系统在进行数据采集的过程中,由于被采集人员的姿态差异等因素,导致采集的脚印在每张图像中的分布位置与倾斜角度不统一。该信息差异与身高无直接关联,但是会被CNN作为特征进行提取并参与训练,最终会影响模型的性能。针对该问题,本文对图像中的有效像素区域进行中心化平移并旋转,该操作能够将图像中脚印的有效区域统一变换到图像中心并且保持竖直,使得CNN能够在较小的固定区域内提取出有效的特征,以提高模型训练的效果。
中心化是将图像中脚印的有效区域变换到图像的中心位置,算法大致分为3步:首先通过统计图像灰度值的变化来找到脚印上、下、左、右最外缘的4个点,以此为基准确定图像中脚印的有效区域,如图3所示 (图中E、F、G、H分别对应脚印上、下、左、右最外缘的4个点,矩形框为脚印的等效区域);其次,计算出等效矩形框区域的中心点与图像中心点之间的坐标偏移;最后根据该坐标偏移对脚印区域进行移动进而达到了中心化的效果,如图4所示。
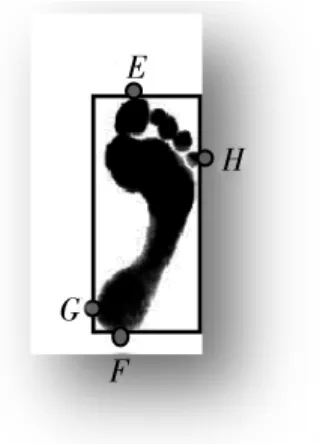
图3 等效矩形示意图Fig.3 Schematic diagram of equivalent rectangle

图4 中心化示意图Fig.4 Schematic diagram of centralization
旋转操作的目的是让所有图像中的脚印区域都呈竖直状态,以消除因脚印倾斜角度不同而导致CNN需要额外学习与倾斜角度相关的信息。该信息会导致训练过程不易收敛。脚印图像旋转算法的核心思想是以脚前掌的中心点与脚后跟的中心点之间的连线为转轴;以脚前掌的中心点为旋转点,以转轴在竖直方向的倾斜角为旋转角度进行旋转。主要实现过程如下:首先将图像中的脚印大致分为4个区域 (脚趾区A、脚掌区B、足弓区C、脚跟区D),如图5所示 (其中a、b、c、d分别是区域A、B、C、D的竖直长度,h是足迹区域最高点与最低点之间的竖直长度)。为了让程序能够自动识别出脚印的A、B、C、D 4个区域,本文采用了统计学的方法进行分析,计算了在200张随机抽样的足迹图像上a、b、c、d所占h的平均比例,并得到式(1)-(4):

根据上述关系,该算法通过计算每张图像中脚印的竖直长度h来确定b与d的长度;其次为了找到区域B与D的中心点,本文采取了与中心化类似的步骤,根据计算出的b与d的长度对区域B和D采用了矩形等效法,如图5所示:用矩形的中心点代替两个区域的中心点,最后以两个中心点的连线为转轴、转轴与竖直方向的夹角为旋转角进行自动旋转。在实际的程序运行过程中,部分图像出现了矩形框中心偏离到了脚印有效像素之外的问题。针对偏离问题,本文采取了对区域矩形进行适当放缩来修正,使区域矩形放缩到对应区域的内部,如图6所示。从图中可以看出,这一方法解决了偏离的问题,以前后脚掌中心点的连线与竖直方向之间的夹角为旋转角度、前掌区矩形中心点作为旋转点进行旋转,最终中心化旋转效果如图7所示,从图中可以看出,经过处理后的脚印分布于图像中心且呈竖直状态。

图5 区域框示意图Fig.5 Schematic diagram of regional frame

图6 区域缩放示意图Fig.6 Schematic diagram of area zoom

图7 旋转示意图Fig.7 Schematic diagram of rotate
2 FtH-Net
2.1 框架介绍
2.1.1 主框架
文献[2]指出,足迹的油墨图像中,与身高有关联的特征一般来自于足迹的外缘轮廓,与图像内部纹理无关。本文所采用的采集设备在采集数据的过程中,由于被采集人员站姿、油墨浓度、采集仪表面贴膜磨损等因素,导致采集出的足迹图像内部灰度值分布不均匀,干扰了CNN对足迹图像有效信息的提取。为消除脚印内部灰度值分布不均匀对预测结果的影响,如图8(a)所示,FtH-Net的第1部分由边缘提取网络构成,该网络能够准确提取足迹的边缘信息,使用BSDS500(包含500张彩图、500张与彩图对应的边缘轮廓图)对边缘提取网络进行训练;第2部分由回归网络构成,如图8(b)所示,通过脚印的边缘数据预测对应的身高信息。
2.1.2 边缘提取
边缘提取部分本质上是一个图到图的网络。已有的图到图网络通常是基于GAN(生成对抗网络)的双向网络,如文献 [17]中提出的一种基于补丁判别器的条件GAN(Pix2pixGAN),其利用补丁结构增强网络对图像细节的关注度;文献[18]提出的一种基于潜在空间的无监督GAN(UNIT),是将不同域的图像转化到同一潜在空间,解决了传统图到图网络需要训练样本成对输入的问题。上述方法大多用于风格迁移,其用复杂的损失函数去关注图像细节之间的联系,生成的图像纹理细节特征明显,但网络训练时间长,且基于GAN的模型易崩溃[19]。人的身高主要依赖于脚印的边缘信息[2],与内部纹理细节特征无关,所以现有的方法无法满足该要求。为克服当前已有方法的不足,本文提出一种基于潜在空间的单向网络去关注图像边缘信息。与文献[18]不同的是,该网络未采用GAN模型,而是以更合适的结构和相应的损失函数去关注图像的边缘信息,并且训练时间短,模型更容易收敛。

图8 FtH-Net示意图Fig.8 Schematic diagram of FtH-Net
本文提出的边缘提取网络分为3个部分。①编码部分,利用编码器对油墨数据编码,编码器由改进的VGG-16[20]构成,具体结构如图9(a)所示。VGG按照对区域取最大值的方式进行降采样,保留数据的纹理信息,与足迹数据的要求不符。本文使用随机池化[21]代替最大值池化,对特征图中的元素按照概率值的大小随机取值进行下采样,减少模型对脚印内部信息的关注度,增加模型的稳定性,为保持特征图信息的空间完整性,编码部分去除了VGG最后的全连接层。②转换部分,如图9(b)所示,由6个残差模块构成,其中每个残差模块包含两个卷积层。该设计可以有效转化不同域图像之间的特征[22],将油墨数据的编码转换成边缘数据。③解码部分,如图9(c)所示,利用解码器将边缘特征编码转化为边缘轮廓图,由于编码部分含有5个下采样层,为保证编解码操作前后尺寸的一致性,解码部分包含5个反卷积层。

图9 边缘提取网络示意图Fig.9 Schematic diagram of extraction network
2.1.3 回归预测
目前的回归模型多用于基于人脸的年龄预测以及人群计数等领域。其中,基于人脸的年龄预测常用较为复杂的网络去提取面部细微的特征,且年龄为整数,可做特殊的分类处理,如文献 [23]中提出一种多分类后再回归的模型 (OR-CNN);而人群计数一般是基于全卷积网络的点到点的回归[24],通过输入人群图像,生成人群密度图,进而得到人群数量。这些方法更关注于图像的细节特征,与本文实验要求有本质的区别。本文提出的回归网络由两个部分 (编码器与全连接层)构成,如图10所示。编码器的结构同图9(a),首先通过编码器对输入的数据进行编码,其次利用全连接层将二维编码展开,每个全连接层末尾使用ReLU(修正线性单元)激活函数进行激活,最终通过回归层输出身高信息。本文在
3.2.1节中采取对比实验的方式,分析不同结构的编码器对预测准确率的影响。

图10 回归网络示意图Fig.10 Schematic diagram of regression network
2.2 损失函数

损失函数包含边缘损失与回归损失,边缘损失的计算如式 (5)、(6)所示:Lpixel为交叉熵函数,计算预测图与标签图对应每一个像素点之间的损失。由于边缘轮廓图的背景部分像素值为0,而边缘部分像素值为255,将像素归一化到0-1之间,规定像素值为1的为正样本区域、为0的为负样本区域,利用交叉熵函数计算对应点之间的分类损失。p(x,y)为归一化后标签图中对应坐标 (x,y)处的像素值;ypx,y为预测图中对应坐标 (x,y)处的像素值。Lprofile为最终的边缘损失,计算预测图与真实图之间所有像素点的Lpixel损失之和。其中i、j分别为输出图像的长与宽。回归损失如式 (7)所示:

式中:n为样本的总量,Hk为样本中第k个图像对应的标签身高;Hpk为网络根据第k个图像预测的身高。本文选用MSE作为FtH-Net的回归损失,计算预测身高与真实身高之间的均方误差。
2.3 训练及测试
本文提出一种分训练、整测试的方法对FtHNet进行训练及测试,具体流程如图11所示。将经过预处理的数据按照8∶2的比例分为训练集与测试集。首先训练边缘提取网络 (如图11中①所示),使用边缘检测数据集BSDS500训练边缘提取网络,得到一个边缘提取模型;其次训练回归网络(如图11中②所示),将训练集数据输入边缘提取模型中得到轮廓数据,使用轮廓数据训练出一个预测身高的回归模型;最后将测试集数据输入训练完成的模型中进行测试 (如图11中③所示),可以得到每张数据对应的轮廓信息 (如图12所示)与身高信息。
3 实验
3.1 实验设备及相关参数
本文有关CNN模型训练的实验均在GPU型号为NVIDIA 1080Ti、CPU型号为Intel i7-8700的机器上进行,每轮训练都包含32个样本,每张图像的尺寸均为256像素×128像素。训练时采用AdamOptimizer优化器,学习率设置初始值为0.001,每训练10轮当前学习率下降1%。

图11 FtH-Net训练及测试流程图Fig.11 Flow chart of FtH-Net training and testing

图12 边缘提取示意图Fig.12 Schematic diagram of edge extraction
3.2 对比实验
3.2.1 边缘提取效果
本文将FtH-Net中的边缘提取网络与Pix2pixGAN和UNIT在BSDS500数据集上进行对比实验,实验效果如图13所示。对比实验表明Pix2pixGAN和UNIT更关注于对细节信息的刻画,而FtH-Net更关注于边缘轮廓信息,与真实标签信息更接近,所以FtH-Net更适用于预测身高时的特征提取。为了更准确地评价对比实验中3种网络的性能,该部分统计了输出图像的SSIM(结构相似性)均值以及训练时间,如表1所示,相比于Pix2pixGAN与UNIT,本文所提出的网络更适用于边缘的提取,并且训练时间短,与2.1.2节论述相符,满足本文实验需求。
3.2.2 不同编码器结构效果对比
本文采取对比实验的方式,探究不同编码器结构对回归网络性能的影响。由于足迹图像均为单通道二值图像,并且像素低、特征少,不宜使用层数过深的网络进行解码,本文选取LeNet-5与VGG-16进行对比实验,将训练集数据分别在不同编码器结构的回归网络上进行训练,训练结果如表2所示 (其中ACC_i表示预测出的身高与真实身高差绝对值≤i cm的概率)。从表中可以看出,针对本文的数据集,VGG-16在准确率与收敛速度方面都要明显优于LeNet-5。

图13 不同网络边缘提取的对比示意图Fig.13 Schematic diagram of edge extraction using different networks

表1 不同网络边缘提取实验结果对比Table 1 Comparison of experimental results of edge extraction using different networks
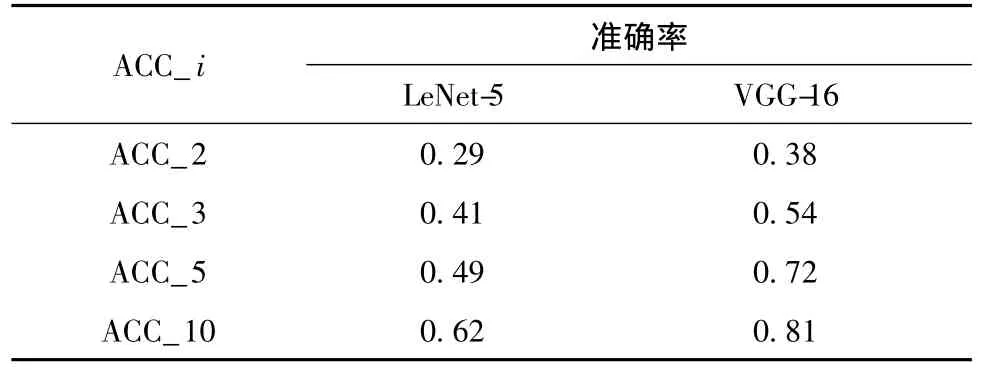
表2 不同编码器实验结果对比Table 2 Comparison of experimental results of different encoders
3.2.3 算法有效性验证
为了验证中心化旋转等预处理算法的有效性,本文利用设置好的FtH-Net分别对已进行以及未进行预处理的数据进行了训练及测试,实验结果如表3所示。为探究FtH-Net边缘提取部分对回归精度的影响,本文仅使用FtH-Net的回归网络对足迹数据进行了训练及测试,实验结果如表3所示。从表中可以看出,每经过一步数据处理,网络对身高的预测准确率便有一定上升,并且经过中心化旋转的数据提升幅度最大。实验结果表明,本文所采用的回归算法有效,并且消除了足迹数据平移、旋转等问题对回归精度的影响。

表3 经过不同处理的数据的回归实验结果Table 3 Regression experimental results of different processed data
3.2.4 左右脚实验差异对比
为探究区分左右脚对身高预测是否存在影响,本文将预处理完成的4000个数据进行左右脚的筛选,最终筛选出2250个左脚数据与1750个右脚数据。分别对左、右脚的数据进行模型的训练以及身高的预测,预测结果如表4所示。从表中可以看出,单独使用左脚或右脚训练的模型预测身高的准确率与未区分左右的准确率接近,此结果表明是否区分左右脚对身高预测没有影响。

表4 左、右脚数据分别在FtH-Net上的实验结果Table 4 Experimental results of left and right feet on FtH-Net
3.2.5 不同回归算法对比
为证明本文方法的有效性和优越性,本文对多种具有代表性的方法进行对比实验,包括线性回归、机器学习领域KNN[25-26]算法以及深度学习领域基于人脸预测年龄的经典回归网络OR-CNN。其中线性回归和KNN算法以脚长和脚宽作为输入特征,OR-CNN和本文提出的FtH-Net网络以足迹图像为输入。为保证对比实验的公平性,所有的输入图像均经过相同的预处理操作。实验结果如表5所示,从表中可以看出,基于深度学习的方法相比于其他方法在实验效果上具有明显的优越性,并且本文提出的FtH-Net相对于OR-CNN在性能上有了更进一步的提升,表明使用图9(a)所示结构的编码器训练模型的效果最优。

表5 不同方法对文中数据集的预测结果Table 5 Prediction results of the data set of this paper obtained by different methods
3.3 实验结果分析
根据3.2节对比实验结果可以得出,利用FtHNet预测身高的方法较现有回归算法更加可靠,并且数据在经过不同的预处理后,模型的回归精度均逐步提升,从而证明了本文预处理算法的有效性。相比于线性回归的方法,FtH-Net网络是非线性模型,能有效地提取边缘特征,更适合于本文的身高预测。为了探究身高与脚部特征之间是否存在非线性关系,本文按照传统方法,以脚长和脚宽为特征,测量并统计了部分足迹图像的脚长和脚宽数据,并分别绘制了脚长-身高、脚宽-身高分布散点图,如图14所示。从图中可以看出,脚长-身高与脚宽-身高的分布不具有明显的线性关系,该结论和常识相符 (现实条件下存在同一脚长或者脚宽对应不同身高的现象),所以导致回归模型预测效果不理想。相比于KNN利用脚长和脚宽为特征进行预测,FtH-Net模型可以提取出诸如脚印轮廓等更多元化的特征。

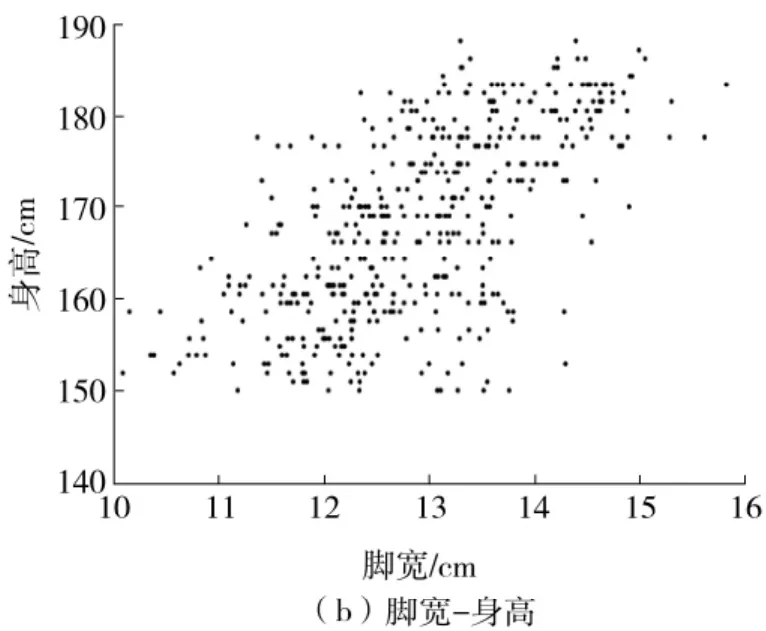
图14 脚长-身高和脚宽-身高分布散点图Fig.14 Scattered point figure of length-height plot and widthheight plot
4 结语
本文提出了一种基于足迹图像,利用深度学习预测身高的算法。在图像处理阶段,本文采用了全自动的方式进行数据清洗、滤噪、旋转中心化,并且提出一种预测身高的回归网络,能够快速地将采集的足迹图像转化为网络的输入数据,进而预测出相应的身高。在实际应用中,该方法能够为刑侦人员提供一种高速处理大规模足迹数据的方式,提高了办案的效率。文中使用CNN训练足迹数据,在传统经验性特征的基础上,还能提取到深层次特征,为后续根据足迹数据的年龄预测以及身份识别奠定了基础。但CNN模型的好坏一定程度上取决于数据量的多少,目前足迹未建立公开数据集并且数据匮乏,所以数据量不足仍是该方面研究需要解决的问题之一。
