基于双层注意力机制的联合深度推荐模型
2020-07-08刘慧婷纪强刘慧敏赵鹏
刘慧婷 纪强 刘慧敏 赵鹏
(安徽大学计算机科学与技术学院,安徽合肥230601)
随着在线购物网站的发展,利用用户的个性偏好进行推荐变得越来越普遍。现有推荐系统可以分为3大类:基于协同过滤 (CF)的推荐、基于内容的推荐和混合推荐。推荐系统大多采用基于CF技术的推荐算法。这些算法的基本思想是:具有相似偏好的用户往往会有类似的选择。简而言之,协同过滤算法直接或间接依赖用户的评级,以进行评级预测或者生成排名推荐。
尽管协同过滤算法在许多应用中表现出了良好的性能,但是该算法有其自身的局限和缺点,稀疏性问题是其面临的重大挑战之一[1]。当用户对商品的评分非常稀疏时,基于用户评级所得到的用户间的相似性可能不准确,会出现稀疏性问题,且该问题存在于许多实际应用中。
协同过滤技术的另一个缺点是可解释性差,其无法很好地解释用户的偏好。此技术只知道用户可能因为某个特定的特征而喜欢某个项目,但不知道这个特征的含义。事实上,用户喜欢某个项目的原因都是可以解释的,例如餐厅的美食风格和价格等。使用评论文本进行推荐是解决上述问题的一种方法。
为了解决稀疏性问题,研究人员还提出了基于内容的推荐系统。这些方法利用项目信息或者用户评论信息了解用户或项目的潜在特征。尽管基于内容的推荐系统可以有效地推荐新项目,但是由于没有足够的有关用户个人信息,这类方法无法生成个性化的预测。
现在越来越多的模型将CF和基于内容的方法结合起来进行推荐[2-6],取得了不错的效果。例如模型sCVR[2]使用评论信息和社交关系来预测项目评分,实现了很好的可解释性。而文献 [3]提出了深度学习框架NRT,该模型可以在预测评分的同时生成摘要性的提示,提高了模型的推荐质量和可解释性。
目前,在大多数电子商务和评论服务网站如亚马逊和Yelp中,用户可以自由编写评论文本以及数字星级评分。评论文本中通常包含有关项目特征(例如质量、材料和颜色)的丰富信息,有时还会包含针对性的建议,这些建议对于那些打算作出购买决策的人来说具有很好的参考价值。但由于并不是所有的评论都是有价值的,所以用户从大量的评论中获取有用的信息是比较困难的。不太有用的评论会给推荐模型带来噪声,影响模型的性能,对用户的帮助也会有限,因此选择有用的评论对于提高模型的性能是非常重要的。
已有相关研究使用评论文本来提高评级预测模型的准确性,例如 CTR[7]、HFT[8]、RBLT[9]等,它们证明了使用评论信息进行推荐的有效性,特别是对于评级较少的用户和项目。但是这些模型利用隐狄利克雷分配模型 (LDA)[10]或非负矩阵分解(NMF)[11]从评论中提取潜在特征,其不足之处是它们使用词袋 (BOW)表示来进行评论文本的处理,而忽略了评论的上下文语义信息。
由于深度神经网络 (例如RNN、CNN(卷积神经网络)等)对序列文本有着强大的建模能力,因而有研究利用深度神经网络提取用户评论中的有用信息来提高基于潜在因子建模的模型性能[12-13]。例如,DeepCoNN模型用CNN来编码评论信息,然后通过因子分解机 (FM)[14]耦合的两个并行部分对用户和项目进行联合建模,以进行评级预测。虽然该模型取得了很好的推荐性能,但它从用户或者项目的评论中无区别地提取信息,不能够很好地区分用户评论的差异性。
对于模型缺乏可解释性的问题,现有模型利用用户评论来提高推荐性能并生成解释[2,15-16],但这些模型也存在一些局限性。首先,对于项目建模它们没有考虑每个评论的贡献程度,也没有区分发表无用评论的用户;其次,它们从评论中简单地提取单词或短语来为模型提供解释,缺乏评论中的上下文信息,这可能会扭曲原来句子的含义。
为了解决上述问题,提取有用的用户或者项目评论信息,本文提出了一种融合双层注意力机制的神经网络模型 (DLALSTM),利用双向长短期记忆网络 (BiLSTM)[17]来学习用户和项目评论信息,以更好地提取评论中每个词的上下文信息;同时利用双层注意力机制分别考虑词和评论的重要性,使得模型具有良好的可解释性。
1 双层注意力深度推荐模型
一个用户对不同的项目可能有多个评论信息,而项目也可能会接收不同用户对它的多个评论信息。一方面,在用户或者项目的多个评论信息中,有些评论信息在整个用户或者项目建模中起着非常重要的作用,而其他一些评论信息可能对于建模用户偏好和项目特征没有那么重要。另一方面,评论中不同单词的语义不同。一些单词能够体现出用户的偏好,而另一些则倾向于表明项目的特征。这意味着评论信息在词级别和评论级别具有不同的潜在语义表示。为了体现这两种信息在推荐模型中不同的作用,本文提出了一个新的框架DLALSTM,来将用户和项目评论信息分别从用户视图和项目视图的角度,通过双层注意力机制并行地引入推荐模型,如图1所示,其中各符号的意义见下文。本文提出的双层注意力模型包含用户视图和项目视图两个并行的部分,分别实现用户建模和项目建模。整个模型由输入层 (词嵌入层)、序列编码层、第1层注意力层、第2层注意力层、全连接层、评分预测层6部分组成。下文将从项目视图角度进行详细介绍,用户视图角度的建模和项目视图相似。
1.1 输入层
模型DLALSTM使用经过预训练的词向量作为输入,这些向量由 Google News[18]中超过1000亿个单词训练得到。将用户的所有评论换为单词向量矩阵,表示为Vu1,Vu2,…,Vuj,其中 Vuy(y=1,2,…,j)为用户u的第 y条评论中的词 uyp(p=1,2,…,m)预训练后所构成的矩阵,j为每个用户最大的评论数。同理,项目i的所有评论也转换成单词向量矩阵,表示为 Vi1,Vi2,…,Vik,Viz(z=1,2,…,k)为项目i的第z条评论中的词izq(q=1,2,…,n)预训练后所构成的矩阵,其中k为每个项目最大的评论数。然后将这些矩阵分别输入到两个并行BiLSTM中。
1.2 序列编码层
为更好地利用上下文信息,常见的方法是采用双向LSTM(长短期记忆网络)来模拟正向和反向的文本语义。例如对于文本序列[x1x2… xT],正向LSTM是从x1到xT读取序列,反向LSTM则是从 xT到 x1读取序列。连接正向隐藏状态h→t(t=1,2,…,T)和反向隐藏状态h←t[19-20],即ht=h→t‖h←t。ht包含了以xt为中心的整个文本序列的信息,因此对于项目评论中的词向量序列[WL1WL2… WLn],本文采用BiLSTM来编码正向和反向的项目评论文本语义:
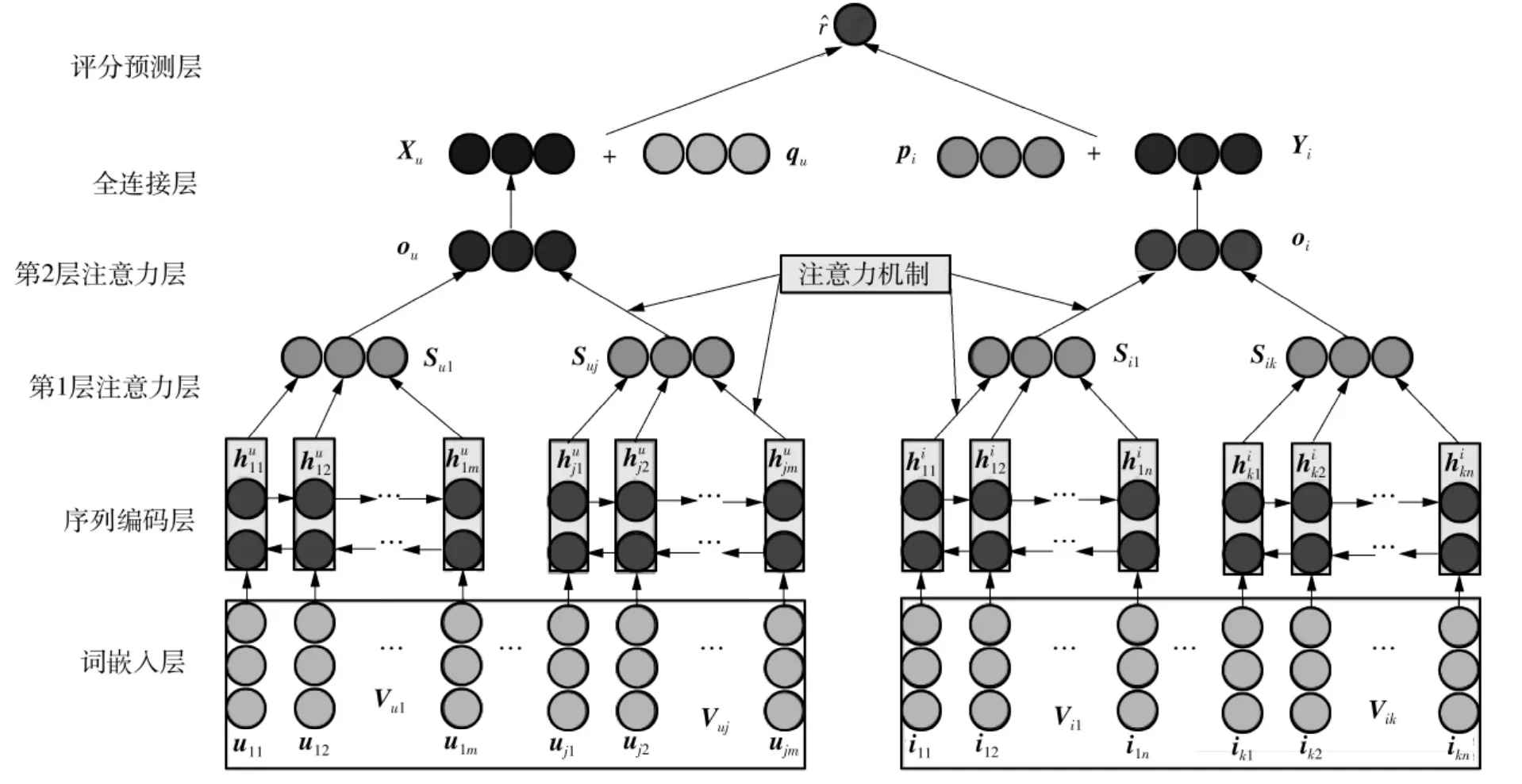
图1 双层注意力推荐框架图Fig.1 Double-layer attention recommendation frame

对于项目评论中第L个评论中的第M个词iLM,首先训练为词向量WLM∈RD。对于词嵌入序列ViL=[WL1WL2… WLn],正向LSTM 从WL1到WLn读取序列,而反向LSTM从WLn到WL1读取序列。连接正向隐藏状态和反向隐藏状态。最终项目视图中的BiLSTM网络生成隐藏状态 {,,…,}。
1.3 第1层注意力层
从项目评论的角度来看,评论中的每个单词在提取项目特征方面的贡献度不同。为了体现这种不同,项目视图模型使用注意力机制来提取评论中对项目特征的提取有重要贡献的信息词,然后,评论则由这些信息词共同表示,即评论表示SiL为项目评论中单词的隐藏状态的加权和:


1.4 第2层注意力层
项目可能有多个评论,而每个评论具有不同的重要程度,为了提取出有代表性的评论中的有用信息,模型引入第2层注意力机制学习每个评论的权重。基于注意力的评论聚合的目标是选择有代表性的评论,然后汇总这些代表性评论的信息来表示这个项目。该层的输入包含评论的特征向量SiL和编写该评论的用户ID嵌入u′iL。添加用户ID嵌入有助于识别发表无用的评论用户。具体来说,第2层注意力网络被定义为

式中:H是权重向量,HT是它的转置;Ws、Wu′分别为SiL、u′iL的权重矩阵;、是偏置项;relu是非线性激活函数。
本文使用softmax函数对上述注意力得分进行归一化来获得评论的最终权重,可以解释为第L个评论对项目i的整个特征的贡献程度:

在获得每个评论的注意力权重之后,项目i的特征向量的计算公式如下:

1.5 全连接层
为了保证由LFM[1]得到的用户偏好和项目特征,与分别通过用户视图和项目视图建模得到的评论级别的用户和项目特征在同一特征空间,本文将第2层注意力层的输出输入到全连接层来获得一个d维向量,则项目i的最终表示为

式中:W0∈Rd×k,是权重矩阵;∈Rd,是偏置项。
对于用户视图中的建模,和项目视图建模相似,并非所有单词都反映用户的偏好。为了解决这个问题,本文使用第1层用户注意力机制来提取对评论含义有重要贡献的用户特定词,同时使用第2层注意力机制提取对用户具有代表性的评论。在用户的视图建模中,用户的一个评论表示Sug和用户评论集合表示ou的计算公式如下:
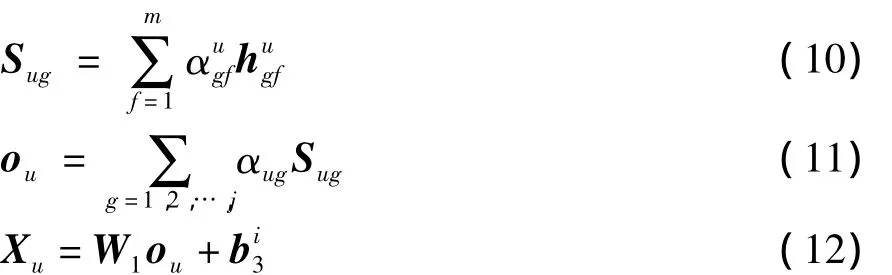
1.6 评分预测层
在评分预测层,本文将LFM模型中的用户偏好分布和项目特征分布分别扩展为两个组件:基于评级的特征和基于评论的特征。具体而言,首先将用户和项目的基于评级的潜在因子映射到共享的隐藏空间,然后引入从评论中学习的基于评论的潜在表示,用户u和项目i之间的交互则被建模为
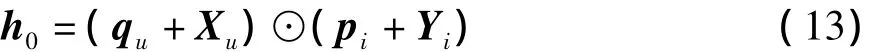
根据式 (13),qu和pi是基于评级的用户偏好和项目特征;Yi则是从评论中学习的基于评论的项目特征;⊙表示向量的元素乘积。
式 (13)的输出是一个d维向量,将其传递给预测层以得到预测评级:

式中:W∈Rd,表示预测层的权重;b2、bu和μi分别表示用户偏差、项目偏差和全局平均偏差。
1.7 模型学习
由于本文关注的任务是评级预测,模型通过Adam优化器最小化以下目标函数来更新网络参数。这实际上是一个回归问题。对于回归,常用的目标函数是平方损失[21]:
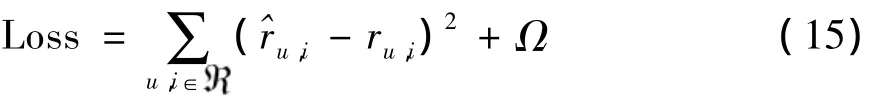
2 实验
为了验证本文所提模型的性能,将在4个真实数据集上对基于双层注意力机制的推荐模型DLALSTM和目前常用的推荐模型进行对比和分析。
2.1 数据集
实验将使用来自不同领域的4个可公开访问的数据集来评估本文的模型。其中3个数据集来自亚马逊,分别为Toys_and_Games、Kindle_Store和Movies_and_TV;另一个数据集来自Yelp。这些数据集涵盖了不同的领域,包含不同个数的用户、项目和评论信息。其中,Movies_and_TV是最大的数据集,它包含超过160万条评论,而Toys_and_Games是较小的数据集,仅包含约16万条评论。数据集的特征统计如表1所示。本文将数据集随机分成训练集 (80%)、验证集 (10%)和测试集(10%),验证集用于调整超参数,测试集则用于最终性能的比较。这些数据集的评分等级为整数1到5。本文对于亚马逊数据集预处理使用文献[22]公开的代码进行处理。由于评论的长度和数量具有长尾效应,本文保留的长度和数量为前p%的用户和项目的评论,对于Toys_and_Games和Kindle_Store,p设置为0.9,而对于Movies_and_TV,p则设置为0.85。Yelp数据集包含来自Yelp Challenge 2018的商户评论。由于原始数据非常庞大且稀疏,因此本文遵循Zhang等[15]对该数据集进行的预处理。具体来说,本文选择位于凤凰城(Phoenix)的商户,并确保所有用户和项目至少有10个评论。
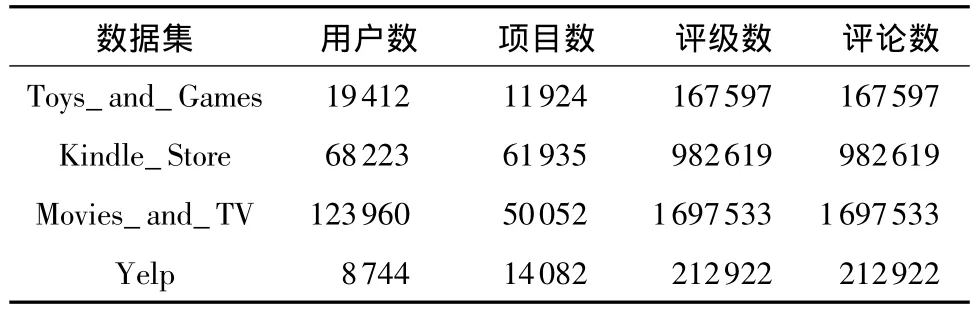
表1 4个实验数据集统计Table 1 Statistics of four datasets
2.2 评价指标
RMSE(均方根误差)是常用的评估协同过滤推荐模型性能的指标,因此本文在实验中利用它来评估各推荐模型的推荐精度,RMSE的值越小,表示预测精度越高。给定预测评级^ru,i和用户u对于项目i的真实评级ru,i,RMSE的计算公式如下:

其中N表示用户和项目之间的评级数目。
2.3 超参数
本文在4个数据集上进行了多组实验,对比方法的参数设置如下:NMF和SVD++设置潜在因子数为10,HFT设置主题数为50。对于模型Deep-CoNN,本文使用了文献 [12]中大多数的超参数设置,其中,卷积层中的神经元数为100,窗口大小为3。在实验过程中,本文模型DLALSTM的隐藏层大小的取值范围为 16、32、50、64、100、128、150。为防止过拟合,本文在全连接层加入dropout方法,将dropout在0.1、0.3、0.5、0.7和0.9中进行最佳参数搜索。批量大小分别取16、32、50、64和 100,潜在因子维数则在 8、16、32、64中选择并进行实验分析。根据实验结果,本文将隐藏层大小设置为128,dropout值设置为0.3,学习率设置为0.001,批量大小设置为64,潜在因子维数设置为32。
2.4 算法性能比较
为了评估模型评级预测的性能,本文将模型DLALSTM与5种目前常用的推荐方法在4个不同领域的数据集上进行性能比较。5种推荐模型分别为PMF[23](引入高斯分布来模拟用户和项目的潜在因子)、NMF[11](仅使用评级矩阵作为输入)、SVD++[24](模型集成了隐式反馈数据,有效地将显式和隐式数据进行结合)、HFT[8](将评论与评级相结合的有效方法)和DeepCoNN[12](利用深度学习技术从评论文本中分别模拟用户和项目)。与其他基于主题建模的方法相比,DeepCoNN模型的推荐性能有了显著改进。本文实现了这个模型,并将优化器由RMSprop更改为Adam,因为该推荐模型使用Adam优化器比使用RMSprop的推荐性能更加有效。DLALSTM与5种对比方法的统计信息比较结果如表2所示。
表2 算法统计信息比较1)Table 2 Comparison of statistical information by approaches
2.5 实验结果与分析
本节将从3个方面对模型的实验结果进行分析:首先,对模型DLALSTM和5个对比方法在4个数据集上的实验结果 (RMSE)进行分析;然后,进一步分析基于深度学习的推荐模型对参数的敏感性;最后,分析双层注意力机制对模型推荐性能的影响以及进行模型的收敛性实验。
2.5.1 算法对比结果分析
本文将6组算法在Toys_and_Games、Kindle_Store、Movies_and_TV和Yelp数据集上进行实验,分析评分预测结果的RMSE的不同,表3给出了各个算法的RMSE的比较结果。
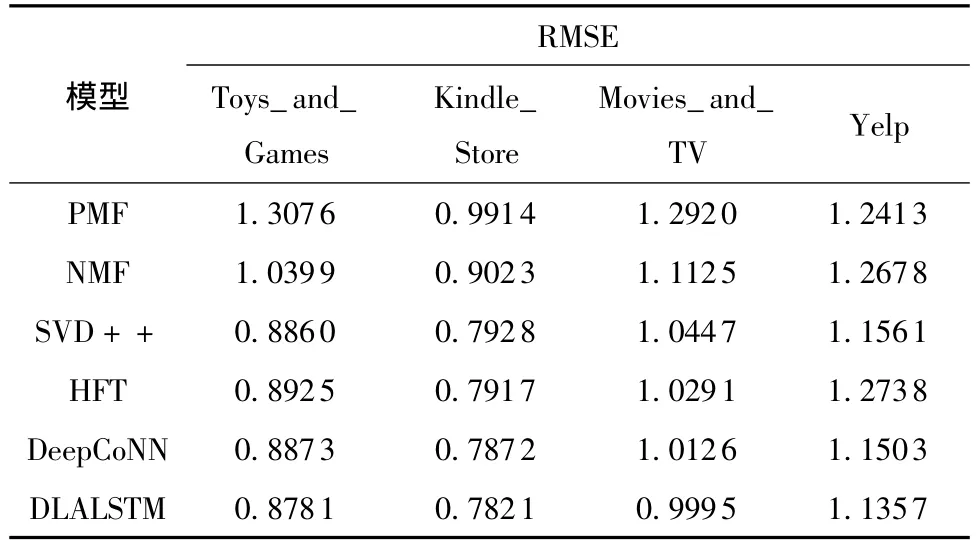
表3 不同推荐算法的RMSE比较Table 3 Comparison of RMSE obtained by different recommendation algorithms
由表3可知,模型DLALSTM在Toys_and_Games、Kindle_Store、Movies_and_TV和Yelp 4个数据集上的推荐性能超过了所有对比方法:
(1)考虑评论的方法 (HFT、DeepCoNN和DLALSTM)通常比仅考虑评级矩阵的协同过滤模型 (例如PMF、NMF和SVD++)表现更好。这是因为评论信息是对评级的补充,它可以缓解协同过滤算法存在的稀疏问题,提高潜在因子模型的推荐性能。高质量的建模则进一步提高了用户偏好和项目特征表示的准确性,从而得到了更好的评级预测结果。
(2)利用深度学习技术 (DeepCoNN和DLALSTM)的方法通常优于传统方法 (包括HFT),尽管HFT也对用户和项目的评论进行建模。这主要是因为:①文献 [25-26]已经表明,像 CNN、RNN这样的神经网络相比基于LDA[10]的主题模型在分析文本信息时可获得更好的性能;②深度学习能够以非线性方式对用户和项目进行建模[27],并且采用一些深度学习策略,如在神经网络中采用dropout来防止过拟合可能会进一步提高模型性能。
(3)DLALSTM始终优于所有对比方法。尽管评论信息在推荐过程中很重要,但评论信息的不同使用方式也会导致不同的推荐结果。本文提出的基于双层注意力的模型利用评论的同时又分别考虑了每个评论的重要性以及每个词的重要性,使得推荐性能得到了进一步的提高。
2.5.2 参数敏感性分析
本节探索了潜在因子数和dropout对模型性能的影响。图2和图3展示了算法在Toys_and_Games和Kindle_Store两个数据集上的实验结果。为了更好地展现DLALSTM模型的性能和改进效果,本文将DeepCoNN的评分预测层更改为表现更好的神经预测层 (参见式 (13)-(14))来扩展DeepCoNN,并 将 其命 名 为 DeepCoNN++[22]。DeepCoNN++将和DeepCoNN以及本文的模型DLALSTM进一步进行性能的比较。

图2 模型在不同潜在因子数上的性能表现Fig.2 Performance of models on different latent factors

图3 dropout对算法性能的影响Fig.3 Effect of dropout ratios on performance of algorithms
首先探索潜在因子数的影响。因为基于MF的模型 (PMF、NMF和SVD++)以及HFT模型在推荐性能上和深度学习方法存在一定的差距,本文只进一步对深度学习的方法进行比较。通过图2实验结果可以看出,本文提出的模型以及对比模型的推荐性能在潜在因子数上的变化比较平稳,在Toys_and_Games和Kindle_Store数据集上,当预测因子数为32时本文提出的模型 (DLALSTM)的RMSE取得了最优值,比DeepCoNN和DeepCoNN++模型的最优RMSE值分别降低了1%和0.13%。
另外,本文还通过实验讨论了dropout在基于深度学习模型上的影响。图3显示了DeepCoNN模型、DeepCoNN++模型以及本文的模型DLALSTM在不同dropout上的性能表现。从图3可以发现,将dropout设置为适当的值时,所有方法的性能都可以得到显著改善,同时本文的模型在大部分情况下超过了所对比的方法,当dropout为0.3时,DLALSTM在Toys_and_Games和Kindle_Store数据集上取得最佳值,超过了DeepCoNN和DeepCoNN++模型的最优值。实验证明,设置适当的dropout能够防止模型过拟合,实现模型更好的性能。实验结果进一步表明,在dropout的比较上,推荐模型性能在数据集Toys_and_Games上的变化比在Kindle_Store数据集上的变化更加明显。这是因为Toys_and_Games数据集相对较小,更容易使模型出现过拟合情况,而在较大的数据集上模型性能相对比较平稳。
2.5.3 注意力机制影响分析
本文分别在Toys_and_Games和Kindle_Store数据集上进行了注意力机制影响的实验,3个模型的RMSE比较如表4所示。在表4中,All代表本文提出的应用了双层注意力机制的模型DLALSTM;First attention代表只使用了第1层注意力机制,第2层用了恒等的权重;Second attention代表在第1层用了恒等的权重,第2层用了注意力机制。从表4可以看出,应用两层注意力机制的评级预测的性能显著地超过了只用1层注意力机制的情况;同时,只用了1层注意力机制的模型无论是在第1层还是第2层使用都表现相当,性能都低于用了双层注意力的模型性能。实验结果证明了本文的假设,即不同的评论对用户偏好和项目特征具有不同的代表性,同时每个词的作用也是不一样的,设定不同的词的权重对用户和项目的建模是非常重要的。基于双层注意力机制的联合深度推荐模型可以很好地学习这种多样性,从而可以提高推荐模型的性能。
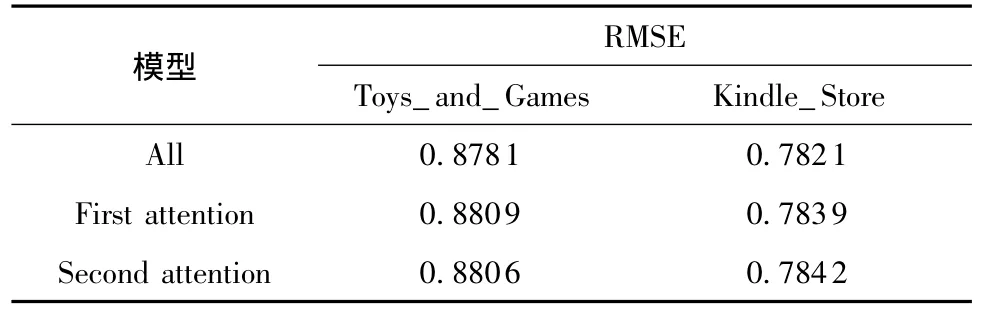
表4 注意力机制的影响Table 4 Effect of attention mechanism
为了验证模型DLALSTM的第1层用户注意力层和第1层项目注意力层的有效性,本文做了注意力可视化实验。表5提供了用户评论及其单词级别注意力可视化的例子,以说明第1层注意力机制对用户偏好和项目特征识别的结果,其中灰色较深的颜色表示单词具有较高的权重。

表5 用户注意力和项目注意力在单词上的可视化Table 5 Visualization of user attention and item attention overwords
从表5可以看到“love”这个单词在用户注意力方面具有最高的注意力权重,而“cool”这个单词在项目注意力方面具有最高的注意力权重。事实上,单词“love”通常表达用户的偏好,而单词“cool”则用于描述项目的特征。本文提出的模型不仅捕获了这些信息,而且还给出了正确的预测。注意力的可视化表明本文提出的模型可以捕获用户的偏好和项目的特征。
为了验证模型DLALSTM的第2层用户注意力层和第2层项目注意力层的有效性,本文做了评论注意力可视化实验。模型选择某个项目中的两个评论文本作为实验例子,同时把这两个评论进行评论级别注意力权重可视化,结果如表6所示。

表6 DLALSTM模型选择的高权重和低权重评论的例子Table 6 Examples of the high-weight and low-weight reviews selected by DLALSTM
从表6中可以看出,具有较高注意力权重的评论通常包含该项目更多的细节信息,可以准确获得该项目的特征,这对用户做出购买决策更有帮助。相比之下,具有较低注意力的评论只包含用户的意见,并没有该项目的细节,这种评论对其他用户做出购买决策不具有说服力。
2.5.4 模型收敛性分析
在Toys_and_Games数据集上对DLALSTM模型进行了收敛性实验,结果如图4所示。从图4可以看出,当训练次数为4后损失趋于稳定,因此可以看出模型DLALSTM是收敛的。

图4 DLALSTM模型在Toys_and_Games数据集上的验证收敛过程Fig.4 Convergence of DLALSTM model validation processes with Toys_and_Games dataset
3 结论
商品评论对用户做出购买决策起着非常重要的作用,但用户很难从大量的评论中找到有用的信息。本文提出了一种基于双层注意力机制的深度推荐模型DLALSTM,其采用基于双层注意力机制的双向LSTM来增强推荐性能,可以通过模型学习选择评论集合中有用的评论以及评论中有用的词。相对于传统的基于评级的协同过滤方法,本文模型利用评论文本可以很大程度上缓解数据稀疏性问题。对来自亚马逊和Yelp 4个真实数据集的实验表明,在推荐性能方面,DLALSTM始终优于所对比的常见推荐方法,因此,本文提出的模型将有助于构建一个更有效和可解释的推荐系统。模型DLALSTM建立在深度网络BiLSTM基础上,由于BiLSTM自身存在的效率较低的问题,利用模型DLALSTM进行推荐时较为耗时。在未来的工作中,我们将在保证推荐准确度的基础上,进一步提高模型运行的时间效率;同时也将继续探索利用基于注意力机制的LSTM来对用户长期的一般兴趣和近期的动态兴趣建模,以实现序列推荐。
