基于多特征因子的路用集料粒径计算神经网络模型
2020-07-08裴莉莉孙朝云户媛姣李伟高尧郝雪丽
裴莉莉 孙朝云 户媛姣 李伟 高尧 郝雪丽
(长安大学信息工程学院,陕西西安710064)
目前,沥青路面已成为大多数道路的主要路面形式。集料是对颗粒状矿物质材料的统称,对沥青混合料骨架的填充起着关键作用[1-2]。通常采用不同规格方孔筛对不同用途的粗细集料颗粒进行筛分,从而得到集料颗粒的粒径和分档[3-4]。由于集料颗粒的形态特征和粒径尺寸对沥青路面的使用性能起着决定性的作用[5-6],因此寻找一种快速而又准确的集料颗粒粒径检测方法极为重要[7]。
根据集料颗粒粒径尺寸不同,可将集料分为不同的档,主要包括2.36mm档、4.75 mm档、9.50 mm档、13.20mm档以及16.00 mm档等,每个档是一个范围量[8]。在国内外研究中,大多是通过图像法[9-11]来提高粒径测量精度[12]。2013 年,王大庆[13]对细集料几何特征参数进行表征,同时还分析了细集料几何特征对沥青混凝土路用性能、力学性能等的影响;同年,Camsizer系统可以自动识别并记录颗粒的形状特征以及尺寸分布,同时该系统还可以计算出集料颗粒表面的垂直投影面积,并对计算结果进行数字化处理[14];2015年,Moon等[15]采集到沥青混凝土的RGB图像,并将其与原始设计的粒径分布进行图形和统计学比较,结果发现该方法可以很好地预测粒径大于4.75mm集料颗粒的分档情况;2016年,任娜娜[16]利用数字图像技术,提出了基于骨架提取的颗粒粒径检测方法,实现了对集料粒径的检测;2016年,Liu等[17]改进了一种用于集料形貌表征的三维高分辨率图像傅里叶变换干涉检测系统,实现了对集料的球性、平整度比、伸长率、棱角等表面形态特征的检测,并利用未压实空隙率验证了该系统的合理性;2017年,Araujo等[18]利用数字图像处理技术,结合分形理论对两种石英砂的颗粒形态和表面纹理进行了定量分析;同年,王翠[19]基于改进图像法,利用等效椭圆模型对集料颗粒粒径进行校正系数计算,矫正后得到的粒径准确度为80.7%,该方法为本文提供了良好的研究思路;2018年,Su等[20]提出一种适用于一般形状颗粒的棱角性检测方法,结合傅里叶级数和基于梯度的方法对粒子的角度进行定量评价。
在以上对集料粒径及特性评价分析的方法中,大多是基于图像法的主动特征提取,使用数据挖掘[21-22]及人工智能分析方法[23-25]进行的研究还很少。这些方法分析效率较低,并且提取到的特征与真实特征偏差较大,尤其是针对9.5 mm以上的粗集料,基于以上单一几何模型的粒径计算和虚拟筛分效果[26-27]并不理想。因此,本文主要针对粗集料颗粒,通过对采集到的图像进行预处理、特征提取、相关性分析以及多层感知机 (MLP)神经网络等实现对集料颗粒粒径的快速计算。
1 集料特征数据集的构建
本节给出集料特征数据集的来源,主要包括集料图像采集、特征提取、特征筛选及归一化处理等工作,为后续集料粒径测定模型的建立提供准确的训练数据。
1.1 集料特征提取
本研究首先利用图像采集设备对集料图像进行采集,之后对原始图像进行中值滤波、图像二值化、去噪和凸包运算等处理,最后得到集料凸包图像,图像采集与处理的过程分别如图1、图2所示。本试验采用Graham算法对集料颗粒图像进行凸包运算,由处理结果可以发现集料颗粒边缘更加平滑,形状也更接近于原始集料颗粒的形状。

图1 集料图像的采集Fig.1 Collection of aggregate image

图2 集料图像的处理Fig.2 Processing of aggregate image
1.2 集料的几何特征提取
对集料图像进行几何特征提取,得到9.5、13.2和16.0 mm档每档200颗集料的32个特征信息作为数据集的输入特征。集料颗粒的尺寸参数包括面积、周长、直径和形状因子等。利用卡尺法分别测量每档200颗集料颗粒的宽度值,作为集料粒径的参考值,最终建立集料的几何特征原始数据集。
计算集料颗粒粒径的模型非常多,如等效圆、等效椭圆、等效矩形、最大内切圆、等效椭圆(Feret)、等效矩形 (Feret)、Feret径[6]等。为便于理解,与Feret定义相关的特征与常规等效椭圆、等效矩形的对比示意图如图3所示。4个不同形状颗粒的其他部分特征因子的提取示意图如图4所示。

图3 集料Feret相关特征提取示意图Fig.3 Schematic diagram of extracting relevant features of aggregate Feret

图4 集料主要几何特征提取示意图Fig.4 Schematic diagram of aggregates main geometric features extraction
提取到集料几何特征数据后,建立集料提取原始数据集,为方便后续表达,数据集中的30个几何特征因子对应下表编号,同时各个集料特征数值的主要描述性分析结果如表1所示。
1.3 集料几何特征的归一化处理及特征筛选
1.3.1 数据归一化处理
由表1中平均值和方差这两列可以看出原始数据分布并不均衡,其中有些特征数值整体偏高,有些特征数据波动很大。因此,为保证最终模型的鲁棒性,需要对数据进行特征筛选及归一化处理。
为了解决数据间的不平衡问题,保证数值较小的数据对颗粒粒径的影响不被弱化,首先需要对数据进行无量纲化处理,将数据归一化到 [0,1]区间上;之后利用方差选择法去掉波动极小的数据,如图像面积。经过筛选及归一化处理后的数据集有30种集料特征参数,处理后的数据值分布在同一量纲 [0,1]之间,这样有利于避免最终模型过拟合现象的发生,从而保证了模型的高度泛化能力,后期再采用反归一化的方法对数据进行还原。图5为特征因子数值分析箱型图,横坐标代表30个特征因子,纵坐标代表归一化后的特征值,从箱型图中可以明显看出归一化后的数据分布均匀,数值均位于 [0,1]之间。
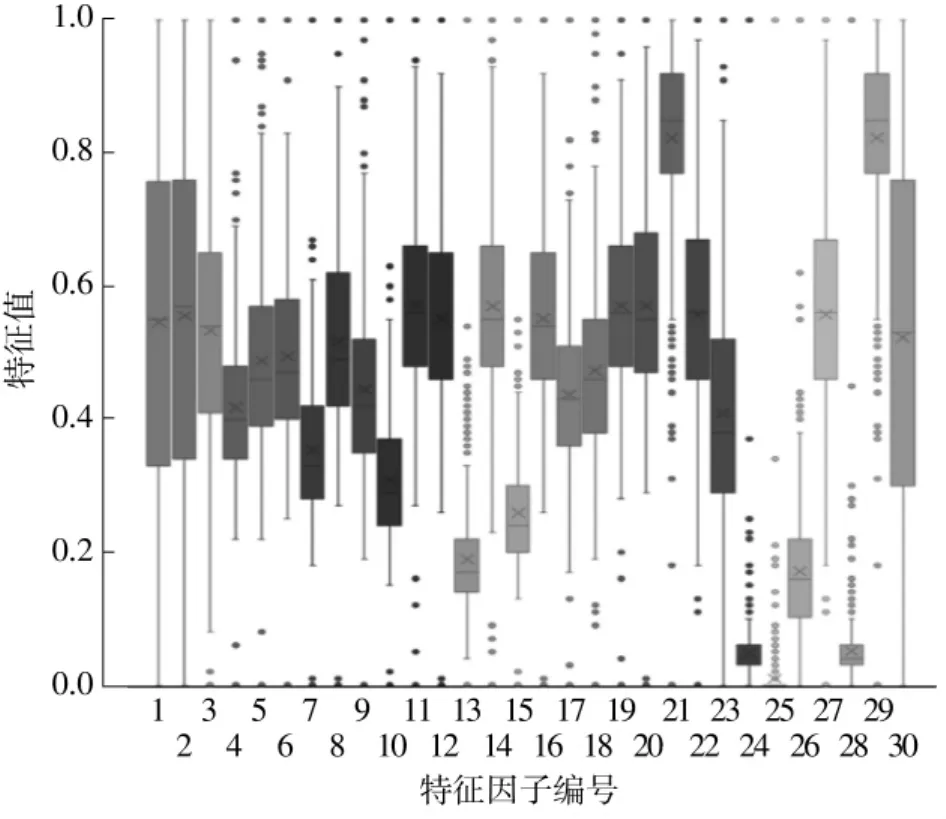
图5 归一化集料特征数据Fig.5 Normalized aggregate features data
1.3.2 基于相关性分析的集料几何特征筛选
在数据特征筛选及归一化处理之后,为了更好地保留与集料粒径相关的特征因子,并去除相关性小的特征因子,需要进行特征筛选。本文基于相关性分析,得到27个特征因子与待测指标 (卡尺-粒径)之间的相关性,从而完成特征筛选工作。
在进行相关性分析时,主要有3类相关性指数,分别是Pearson、Spearman和Kendall指数,由于Pearson、Spearman指数适用于连续数据,而Kendall指数适用于分类变量,因此本研究选取Pearson和Spearman指数作为相关性分析的指数,之后将两者的分析结果进行对比融合,得到相关性强的特征因子来作为神经网络模型的输入。Pearson、Spearman指数相关性分析指标的公式分别如式 (1)和式 (2)所示:

表1 原始集料特征数据集Table 1 Original aggregate characteristic data set
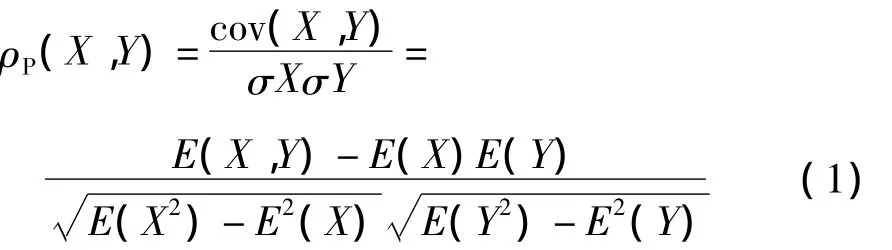
式中:X、Y分别为特征因子数据集;cov(X,Y)为X、Y的协方差;E表示数据集的数学期望。

式中:N为X、Y两变量的样本含量;di为同对等级之差 (i=1,2,…,N)。
经过相关性分析后,集料几何特征因子的相关性排序如图6所示。从图中可以更加直观地看出Spearman指数与Pearson指数得到的分析结果基本一致,特征因子对集料颗粒粒径的相关性变化趋势也一致;其中有19个特征因子与集料粒径相关性较强,另外8个的相关性明显较弱。据经验分析,在集料分筛的过程中,影响集料颗粒通过筛网的大多是集料的宽度,但也有一部分受最长边影响而无法通过筛孔,因此在表征集料粒径时,相关性较弱的几个特征因子大多是与长度相关的特征因子。
根据图6的结果,将相关性极低 (相关指数小于0.2)的8个因子筛去,之后得到特征筛选后的新数据集 (共20个参数),作为神经网络模型训练的输入特征用于集料颗粒粒径的计算。
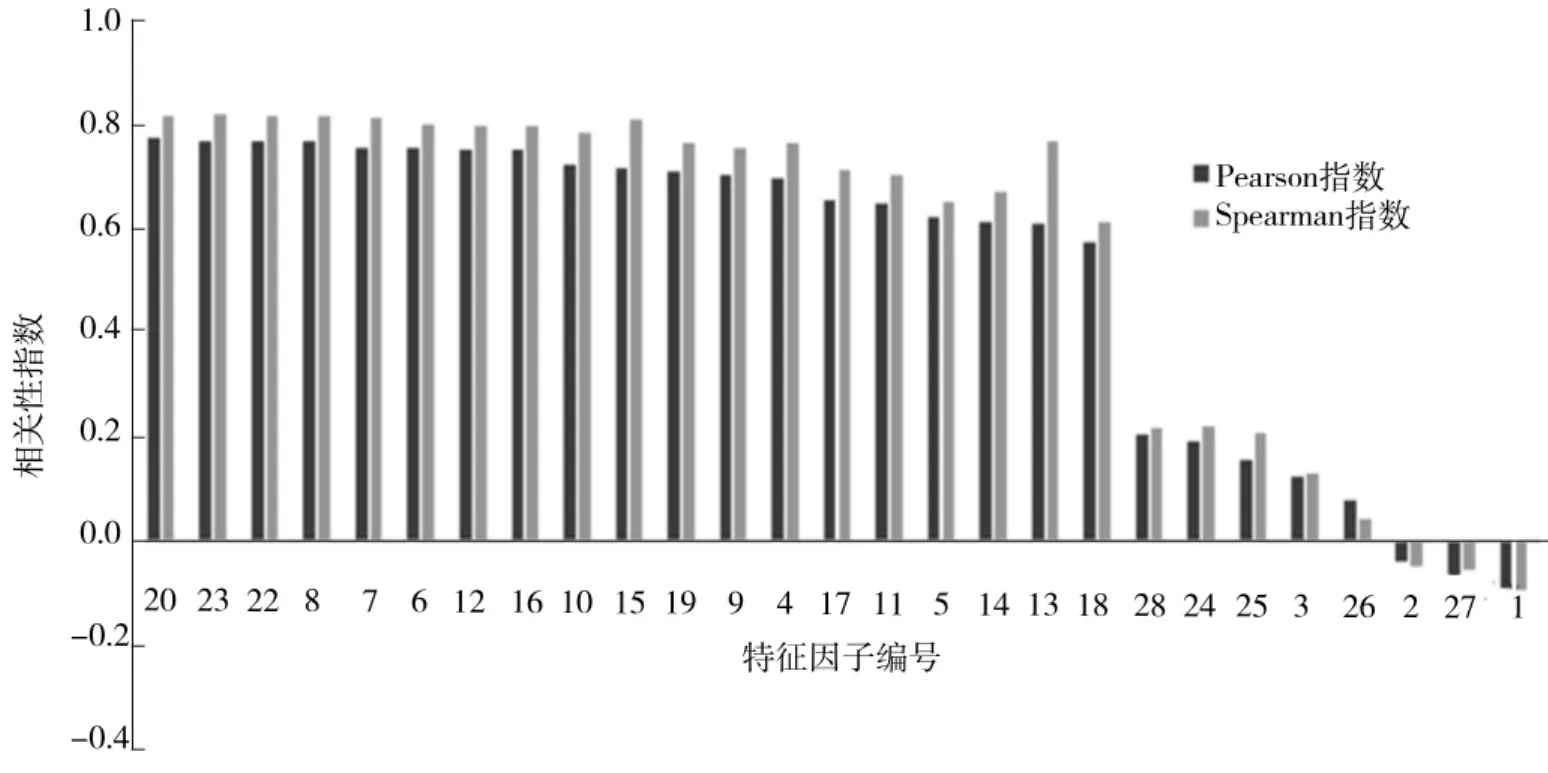
图6 集料几何特征因子与粒径两种相关指数分析结果Fig.6 Analysis results of correlation coefficients between geometric feature factors and particle size of aggregates
2 基于神经网络的集料粒径计算模型的构建
2.1 MLP神经网络
MLP多层感知机是基于反向人工神经网络的一种网络。网络的结构由输入层、隐含层和输出层构成,其结构简单、可塑性强。每层含有多个节点,每层节点与网络的下一层节点完全连接。输入层的节点xi代表输入数据,通过将输入数据与层上节点的权重θi以及偏差b线性组合,同时应用一个激活函数f来得到该层输出y,图7是MLP网络的基本结构,其中:

MLP神经网络最突出的特点是通过误差的反向传播来反复修正权值和阈值,使得误差函数值达到最小,准确度达到预期标准。式 (4)表示了MLP神经网络的误差函数:

式中,yi表示输出节点预测值,ti表示真实值,n为测量值的总个数。
在反向传播的过程中,最常用的误差最小化方法为梯度下降算法,即通过沿着相对误差平方和的最快下降方向,对网络超参数进行调整。在网络训练过程中,通过学习率的设定使得每次反向传播迭代后总体的误差逐渐减小,最终达到系统可以接受的范围,即获得最优权值。以上过程具体实现流程由图8表示。
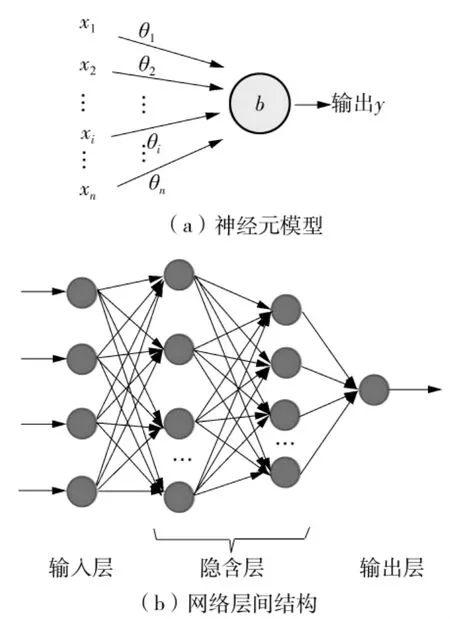
图7 MLP神经网络模型Fig.7 MLP neural network model
2.2 基于MLP神经网络的集料颗粒粒径计算方法
2.2.1 网络设计及训练流程
本文将经过特征筛选和归一化处理及相关性分析处理后的集料几何特征数据作为样本数据集进行模型训练。其输入主要为基于二维图像处理技术可以获得的部分集料形态特征指标,共20个特征因子,输出端为采用卡尺法测得的粒径准确数据,图9为网络架构的设计及训练流程。
2.2.2 网络结构设计
该部分主要是解决网络输入、输出节点数、网络层数、隐含层神经元个数、各层之间的传递函数、训练方法等问题,这里给出神经网络模型的结构设计。

图8 MLP算法模型优化流程Fig.8 Optimization process of MLP algorithm model
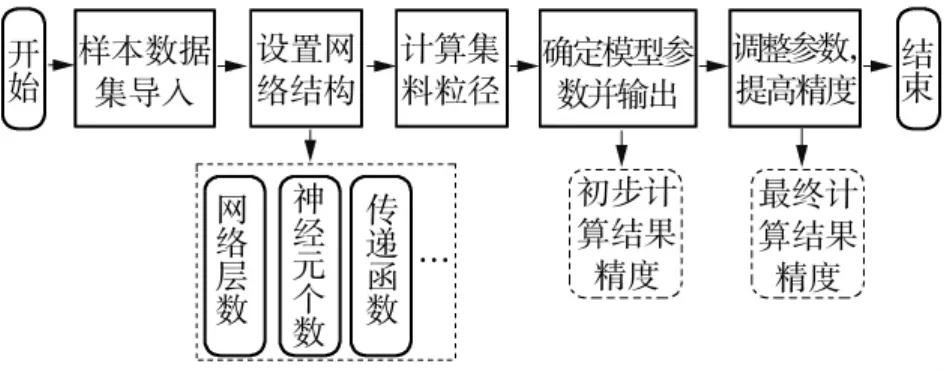
图9 集料粒径计算模型流程Fig.9 Flow of aggregate particle size calculation model
(1)输入、输出节点数
模型初始输入变量为经过特征筛选预处理后的变量,包括待计算指标——集料颗粒粒径,以及由二维集料图像中提取出的集料颗粒特征,共20项。因此,输入层的节点数为19,输出层节点数为1。
(2)网络层数设计
网络层数的选择对最终模型的整体性能具有很大的影响。本项目采用经验值调参测试法对最优网络层数进行筛选。首先选用一个隐含层的MLP网络,若模型计算结果达到精度要求则选用一层的隐含层神经网络;若计算结果准确率未达到要求,则增加网络层数,并同时调节隐含层神经元个数,直到准确度达到满意为止。经过试验测试,本项目对集料颗粒粒径的计算模型选用隐含层为两层的MLP神经网络。
(3)隐含层神经元个数设计
在MLP神经网络中,隐含层神经元个数太多会导致学习的时间过长,也容易造成模型的过拟合;反之则会降低模型的精度。由于集料是三维颗粒,因此在粒径计算方面影响因素复杂多变,采用模型自动参数选择法无法获得最优神经元个数。因此,本项目通过对比实验结果,不断调整隐含层神经元个数,从而确定最优隐含层神经元个数。
(4)激活函数的选择
本文采用 Sigmoid激活函数,其定义见式(5),其中x表示函数自变量,y表示函数因变量。Sigmoid函数的变化曲线如图10所示,也称为S型生长曲线。由图可见其具有单调递增的特性,且该函数可以将输入变量映射到0~1之间。

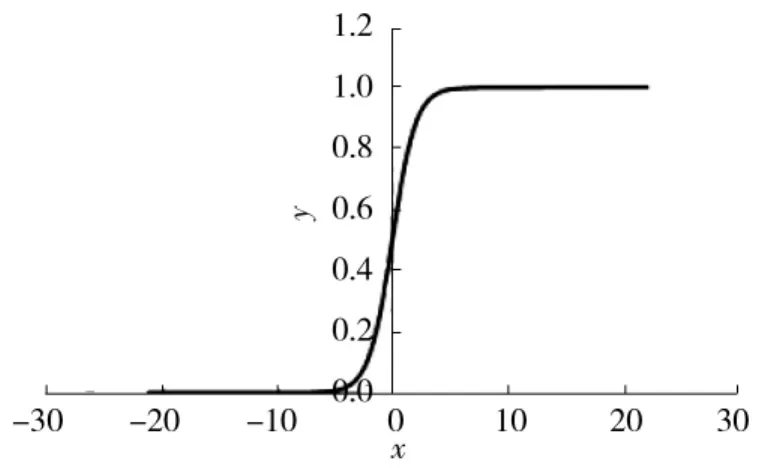
图10 Sigmoid激活函数Fig.10 Sigmoid activation function
(5)网络的训练、验证与测试
现将原始数据集划分为两个部分:70%为训练集,用于初始神经网络模型训练;30%为验证集,用于对模型每一次迭代训练后的网络进行交叉验证,判断模型泛化能力,从而选择最优模型。
(6)模型训练终止条件
为了保证模型的有效性,本项目在模型训练过程中,必须同时达到以下两个标准方可停止训练:①迭代次数达到100;②误差小于0.001。
(7)性能评估指标
本项目采用相关系数 (R2)、平均绝对值误差(MAE)和均方根误差 (RMSE)对预测模型精度进行评价,具体分类评价标准的公式如下:
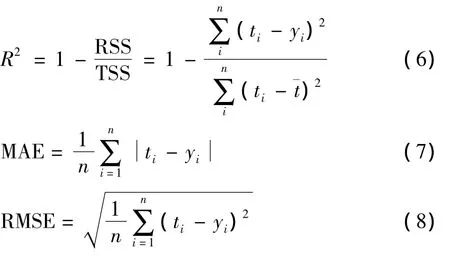
式中:R2表示因变量与自变量之间的线性相关系数,R2越接近1,模型越准确;RSS为残差平方和;TSS为总离差平方和;¯t为真实值的平均值。
MAE和MSE分别表示计算值与真实值之间的平均绝对误差和均方根误差,其值越接近0,模型越准确。
2.3 特征因子权重计算
为了更加准确地得到二维图像中能精确表征集料粒径的特征,需要在计算模型训练完成后对影响的主导因素再次利用模型训练的方式进行分析。本项目采用敏感性分析法,通过影响的权重大小来衡量不同二维图像特征指标对集料真实粒径的表征程度,实现框图如图11所示。
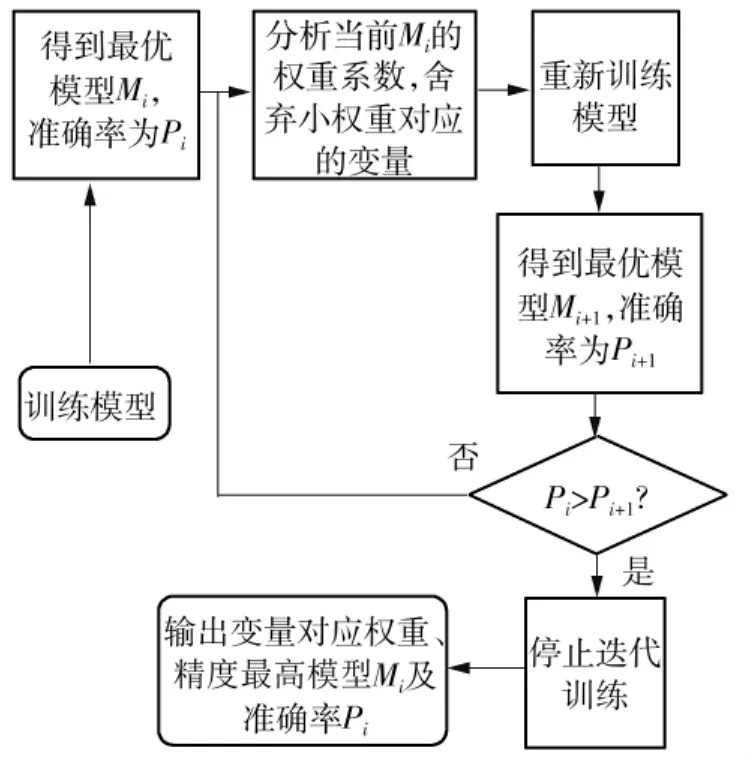
图11 权重系数计算流程Fig.11 Weight coefficient calculation process
图12 为影响因子权值排序图,从图中可以直观地看出来各个特征因子对粒径影响权值的排序对比结果,其中海伍德圆状系数和等效椭圆长短轴比对集料粒径的影响明显小于其他特征因子,并且前18个因子的影响权值分布较为均匀。根据该权值分析结果,可以在后续的分析中着重关注权重大的因子,以此作为特征分析的目标。重要特征排名前10位的特征因子如表2所示。
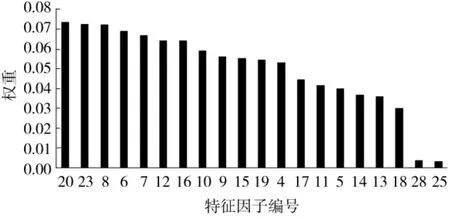
图12 特征因子权值排序Fig.12 Sorting of feature factor weights

表2 重要特征排名前10位的特征因子Table 2 Top ten feature factor for important features
3 结果与分析
通过不断的网络训练和模型参数调整,粒径的计算模型最终隐含层第1层的神经元个数为21,隐含层第2层的神经元个数为7,其他超参数例如初始权重及学习率等均使用默认值。计算准确度结果与分析如图13所示,图中横坐标为卡尺法测量粒径值,纵坐标为MLP模型法计算值,当散点图趋向于y=t这条直线时表明预测结果最好。其中图13(a)、13(b)、13(c)分别为9.5 mm档、13.2mm档和16.0mm档每档200颗集料数据计算模型中得到的训练结果,图13(d)为将全部600颗数据放入模型中训练的结果。具体的评价指标见表3,在训练集上模型的表现明显优于测试集,整体进行训练时,由于样本量多,训练结果明显优于小样本量分档计算的结果,粒径计算值和粒径测量值的线性相关系数可达到0.9116。基于分档的小样本数据量计算时,结果的相关系数也均在0.85以上,可见文中提出的计算结果较为准确。
为了更好地验证模型的有效性,将模型输出的计算结果与已有的粒径计算方法,例如等效椭圆短轴模型、等效圆模型和二阶矩算法模型[16,19]的结果相比,得到的评价指标比较结果如图14所示。从图中可以直观地看出,MLP神经网络的计算值与真实值的线性相关系数最高、误差最小,各个性能指标都明显优于传统的单一基于图像的几何模型计算方法。

图13 粒径计算结果分析Fig.13 Analysis of particle size calculation results
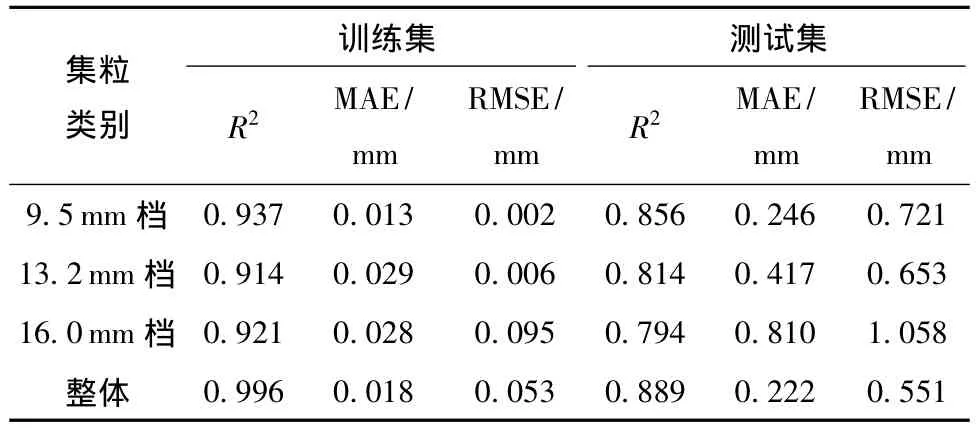
表3 集料粒径计算结果分析Table 3 Analysis of aggregate particle size calculation results
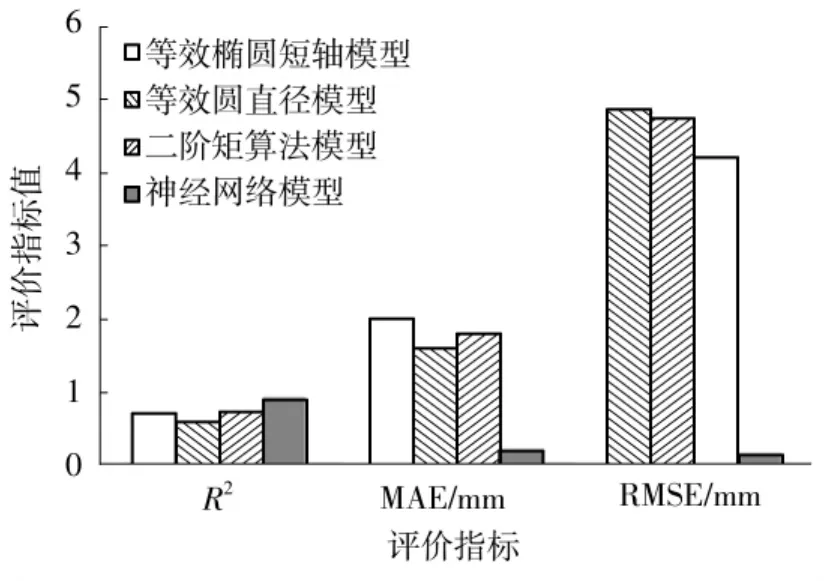
图14 集料粒径计算模型性能评价对比Fig.14 Comparison of performance evaluation of aggregate particle size calculation model
4 结论
本文提出了一种基于多特征因子的路用集料粒径计算神经网络模型。首先对采集到的图像数据进行几何特征参数提取,建立集料样本数据集,然后再对该数据集进行特征筛选和归一化处理以及相关性分析,最终建立MLP神经网络模型对集料颗粒的粒径进行计算。在基于小样本训练数据的情况下,通过与人工卡尺法测量得到的结果进行对比验证,发现两者拟合度较高,计算结果准确 (R2=0.91);同时,本文还给出了与集料粒径相关的重要几何特征。与基于单一几何模型的粒径计算方法相比,本文方法不仅精度明显提高,还可以同时对大量数据进行处理,提高了集料虚拟筛分的效率,表明本文提出的粒径计算方法是准确、有效的,可实现对集料粒径的自动检测和虚拟筛分。
