利用波束形成和神经网络进行语音增强
2020-07-07冯海泓陈友元牟宏宇
龚 杰,冯海泓,陈友元,方 义,2,3,牟宏宇
(1.中国科学院声学研究所东海研究站,上海201815;2.中国科学院声学研究所,北京100190;3.中国科学院大学,北京100049)
0 引 言
目前,智能家居、智能交通、智能医疗等场景中越来越多地将语音端作为一个重要的现实场景信息入口,以实现智能化操作。尽管语音增强领域有着比较长的研究历史,但是由于现实生活中的声学场景非常复杂,如在语音增强领域一直未被解决的鸡尾酒会问题(即当前语音识别技术能以较高精度识别单个人讲话,但是当说话人数为两人或多人时,语音识别率就会极大地降低),在实际生活场景下语音增强工作仍面临着极大挑战。本文致力于在房间存在混响和4个说话人的声学场景下,利用阵列波束形成和神经网络来实现目标语音增强。
用于目标语音分离的其中一类方法是单通道目标语音增强,目前在这一方向上已经有一些效果较好的方法,如谱减法[1]、维纳滤波法[2]、基于统计模型的方法[3]、计算听觉场景分析(Computational Auditory Scene Analysis, CASA)和非负矩阵分解(Non-Negative Matrix Factorization, NMF)方法。近期也出现了一些基于深度学习的单通道语音增强方法,例如基于置换不变性的训练方法(Permutation Invariant Training, PIT)[4]、生成对抗网络(Generative Adversarial Nets, GAN)[5]方法等。但是单通道语音增强的不足在于其实现语音增强的依据为目标语音与干扰声的频谱结构差异,若目标语音与干扰声频谱结构相似,其效果可能较差且单通道没有利用空间信息。
另一类方法是利用空间信息实现多通道语音增强,主要方法是波束形成的方法。但是波束形成大多只利用了空间信息,未利用频谱信息。
本文将接收的多通道信号形成4个方向的超指向波束,得到4个角度的频谱信息,然后利用神经网络与目标纯净语音频谱信息进行映射。在此过程中频谱信息和空间方位信息均得到利用。仿真和实验结果表明,本文采用超指向波束形成结合神经网络以实现目标语音增强的算法取得了较好的效果。
1 算法结构
1.1 本文算法原理
本文算法结构如图1所示。算法流程为待处理的信号在4个方向上进行超指向波束形成;提取每个波束的频谱幅度特征;联合后得到联合特征,根据数据每个维度上特征值的平均值和标准差对联合特征进行标准化;然后进入神经网络预测掩蔽值(Mask);根据掩蔽值得到目标语音频谱进而重构时域信号,得到预测的目标语音。
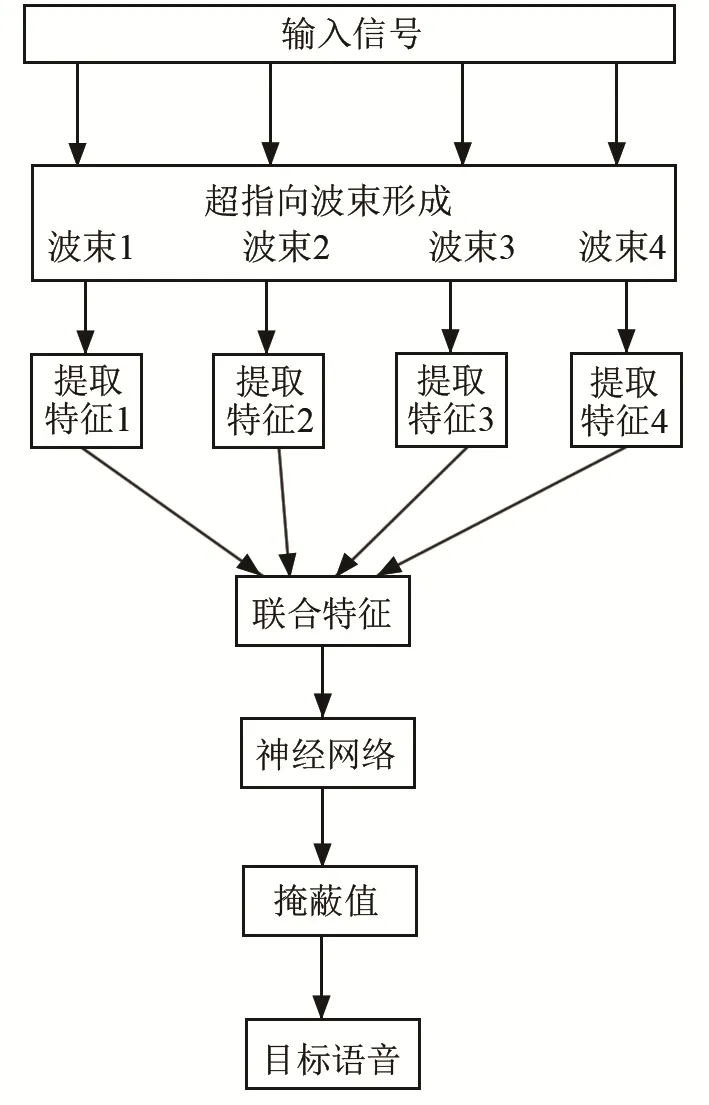
图1 本文算法结构图Fig.1 The structure diagram of the algorithm proposed in this paper
1.2 超指向波束形成得到多个波束的语音特征
延迟相加波束形成是波束形成方法中最基础的一种,其原理是将多个传声器的时延差补齐,使它们与目标方向的传声器一致然后进行累加。此方法应用于非相关的空间白噪声时效果较好,但是其对相干噪声场的抑制效果不理想。超指向波束形成在低频的指向性要强于延迟相加波束形成,因此能够更好地抑制相干噪声场[6],因此本文采用超指向波束形成算法。
假设空间噪声各向同性分布,噪声协方差矩阵的计算公式为[7]

其中:ΓVV为噪声协方差矩阵;J0(⋅)为0阶贝塞尔函数;rmic为圆阵上按逆时针顺序,每个阵元(包括参考阵元)与参考阵元之间的直线距离;f为频率;c为空气中声速,取值为340.29 m·s-1。
利用最小方差无失真响应(Minimum Variance Distortionless Response, MVDR)波束形成器的权重公式可以得出此时的滤波器权重为[8]

其中:d为导向向量。
由于实际环境中存在阵列误差和空间白噪声,因此可通过对角加载来提高超指向波束形成的稳健性,此时滤波器权重为[9]

其中:µ表示对角加载量,I表示单位矩阵。
信号相位谱代表方位信息,由于原始信号来自多个方向,频谱中相位信息和幅度信息相互关联,而神经网络一般都是实数型网络,故频谱中的相位信息不便利用。进行超指向波束形成后,得到4个方向的超指向波束,这时可以只利用频谱幅度信息估计目标语音的掩蔽值,掩蔽值的表达式为

其中:M为目标语音的掩蔽值;λs为目标语音的特征值;λ0为参考波束的特征值。
1.3 神经网络介绍
1.3.1 长短时记忆神经网络
长短时记忆神经网络(Long Short-Term Memory,LSTM)是一种时间递归神经网络,适用于有用信息间隔和延迟相对较长或者间隔有大有小、长短不一的复杂语言场景[10]。本文将一条语音片段信息作为一个时间序列送入LSTM进行训练。
1.3.2 构建神经网络
本文构建的神经网络结构如图2所示。该结构采用4层LSTM网络和1层全连接层网络相结合的形式,每层LSTM层有600个节点,全连接层有600个节点,全连接层的激活函数采用了LeakyReLU函数和sigmoid函数,损失函数采用mean_squared_error函数,损失函数的表达式为[11]
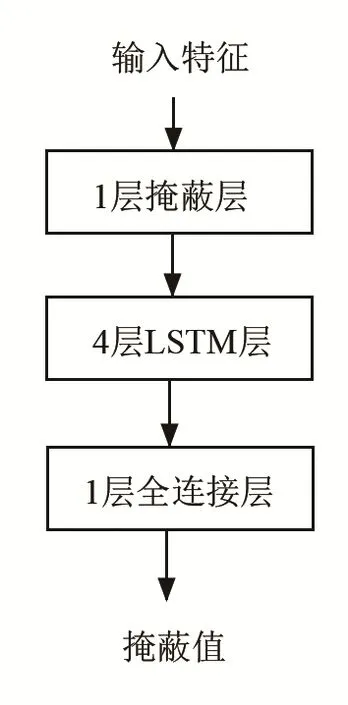
图2 本文所用的神经网络结构Fig.2 The neural network framework used in this paper

其中:yi为训练集数据中的真实值,为神经网络的预测值,ferror为损失函数,损失函数值越小,说明神经网络与训练集的匹配度越高。
2 神经网络训练过程
2.1 构造神经网络训练集数据
2.1.1 利用TIMIT语料库和image method构造神经网络训练集
德州仪器和麻省理工学院(Texas Instruments and Massachu-setts Institute of Technology, TIMIT)语料库,是由上述两家机构和斯坦福国际研究院合作构建的声学-音素连续英语语音语料库。TIMIT语料库的语音采样频率为16 kHz,包含6 300个句子,70%的说话人是男性,大多数说话人是成年白人,630个说话人来自美国8个主要方言地区,每人说出给定的10个句子,所有句子在音素级别上进行了手动分割、标记。
根据房间规格、混响时间T60、传声器位置、说话人位置,利用镜象法(image method)可求得此时每个传声器的混响传递函数[12]。
假设一个房间,如图3所示,4个传声器构成圆阵,圆阵半径为36.25 mm,与智能音箱的半径近似。将圆阵中心置于房间正中央,离地高度设为1.3 m,与现实环境中的智能音箱摆放高度大致相同,所有传声器均位于同一水平面上。然后将从图3中声阵列的圆心到最右侧阵元的连线方向作为0°方向,即目标语音方向,逆时针规划角度,将0°~360°以60°为间隔划分角度,除0°以外,随机挑选3个角度作为说话人方向,4个说话人在距离圆阵中心1~3 m内随机站位,阵列中心与四个说话人的距离均远大于混响半径。混响时间T60在0.3~0.6 s内随机取值,该混响范围对语音的清晰度影响较小[13]。
利用镜象法可求得每个说话人到每个传声器的传递函数。在TIMIT语料库中随机挑选4条纯净语音片段,4个说话人的语言均为英语,男女比例、年龄均随机。将语音片段裁剪成相同时长并对每条语音的幅度进行归一化,再与传递函数进行卷积,然后将每个传声器接收的不同说话人的信号进行累加,之后将0°方向的归一化后的纯净语音代入混响时间T60=0时的传递函数中,可以得到此场景下对应的纯净语音,最后得到一组最终的训练集数据。本研究制作了18 000条数据,总时长约为10 h。
2.1.2 数据预处理
输入信号的采样频率为16 kHz,帧长为512点。在0°、90°、180°、270°这4个方向上对其进行超指向波束形成,每帧加汉宁窗,得到4个波束的频谱幅度特征,联合后得到联合特征和与之对应的目标语音在特定方向的掩蔽值。因0°方向目标语音的频谱成分占超指向波束频谱成分的比例大,避免了掩蔽值过小影响语音增强效果的情况,因此本文采用目标语音在0°方向的掩蔽值。训练集中的联合特征需要在每个维度上进行标准化[14],特征值标准化的公式为

式中,Fnor为标准化后的特征值,F为原始的特征值,为整个训练集数据在某个维度上特征值的平均值,σ为标准差。利用根据式(6)得到的标准化的联合特征和掩蔽值训练神经网络。
2.2 神经网络的训练
通过训练集可得到特征值和掩蔽值,特征值送入神经网络后得到掩蔽值,神经网络具体结构如图2所示,包括1层掩蔽(masking)层,4层LSTM层和1层全连接层。设置好损失函数、优化器、输入、输出,便可训练神经网络。训练集数据在训练过程中共训练25轮,每1轮都需要随机打乱训练集数据的顺序,之后送入神经网络进行训练。训练过程中利用Python语言编写的生成器,用中央处理器(Central Processing Unit, CPU)逐个生成数据批(batch),用图形处理器(Graphics Processing Unit,GPU)训练神经网络,生成器的运行与神经网络的训练两者并行,提高了训练效率。
3 实验与分析
3.1 仿真数据测试与评价
使用英文语料库TIMIT制作本研究中神经网络的训练集,使用中文语料库prime-words_md_218_set1制作神经网络的测试集。
3.1.1 语音分离客观评价
使用源失真比(Signal To Distortion Ratio,SDR)[15]对本文算法进行语音分离效果客观评价,具体公式为

式中:Si表示实际的理想信号,Sp表示经算法处理后的信号;RSD为源失真比。
采用SDR对本文算法与超指向算法、谱减法进行语音分离效果评价,评价结果见表1。从表1可知,本文算法的RSD值大于超指向算法和谱减法,因此本文算法的语音分离效果优于超指向算法和谱减法。

表1 3种算法的RSD值Table 1 The RSD values of three algorithms
3.1.2 混响抑制效果的客观评价
混响抑制效果采用信混噪比(Signal Reverberation Noise Ratio, SRNR)的改善值ΔR进行客观评价,计算每帧语音的ΔR的表达式为
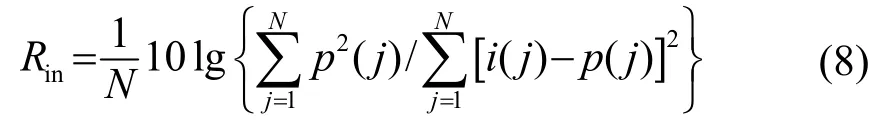
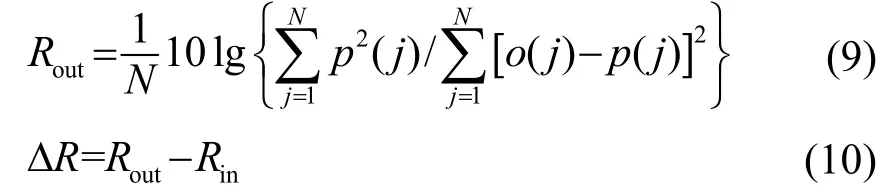
式中:p(j)表示实际的理想信号,i(j)表示原始信号,o(j)表示经算法处理后的信号,N表示当前帧共有N个点,Rin表示原始信号的信混噪比,Rout表示经算法处理后信号的信混噪比。
对所有帧的ΔR求均值,得到最终的ΔR值。本文算法、超指向算法和谱减法的ΔR值见表2。从表2中可知,本文算法的ΔR值大于超指向算法和谱减法,所以本文算法的混响抑制效果优于这两种对比算法。

表2 3种算法的ΔR值Table 2 The ΔR values of three algorithms
3.1.3 语音质量的客观评价
利用感知语音质量评价(Perceptual Evaluation of Speech Quality, PESQ)法对语音质量进行评价,经3种算法处理后的语音的PESQ分数见表3,从表3中可知,本文算法提升语音质量的效果优于其他两种算法。
由以上评价结果可知,本文算法在语音分离、混响抑制和提升语音质量的能力上均优于超指向算法和谱减法。以上分析验证了在房间里存在多说话人场景时,本文算法对目标语音进行增强的有效性。

表3 3种算法的PESQ分数Table 3 The PESQ scores of three algorithms
3.2 实录数据实验
实验采用多通道录音采集卡采集4个说话人的语音数据。实验布设场景和制作训练数据时的场景类似,目标说话人的位置固定,阵元中心与目标说话人的连线方向为0°方向,据此将0°~360°以60°为间隔划分角度,其余说话人的位置从除0°方向以外的剩余5个角度(60°,120°,180°,240°,300°)中随机挑选3个角度,然后录制实验数据。
3.3 实验结果与分析
图4、图5分别是测试集数据的时域信号对比图和语谱对比图。从图4、图5可知,采用测试集数据时,本文算法有明显的语音增强效果。
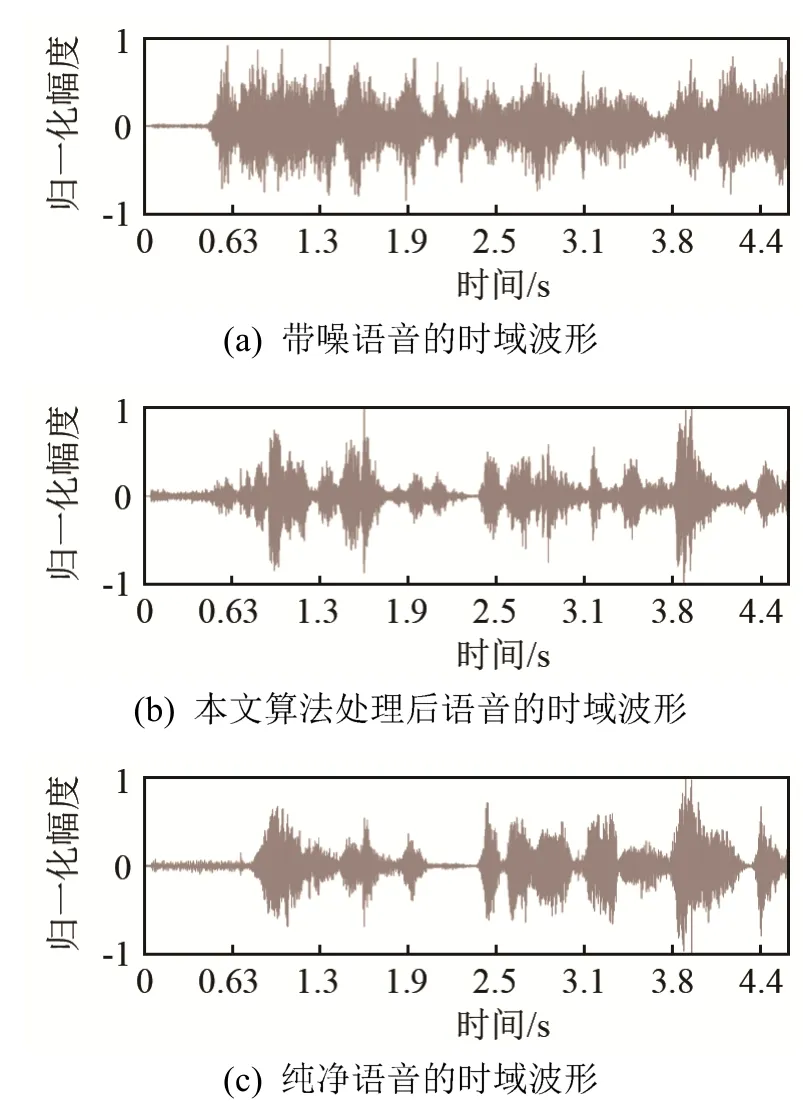
图4 测试集的时域波形对比图Fig.4 Speech waveform diagrams of testing dataset
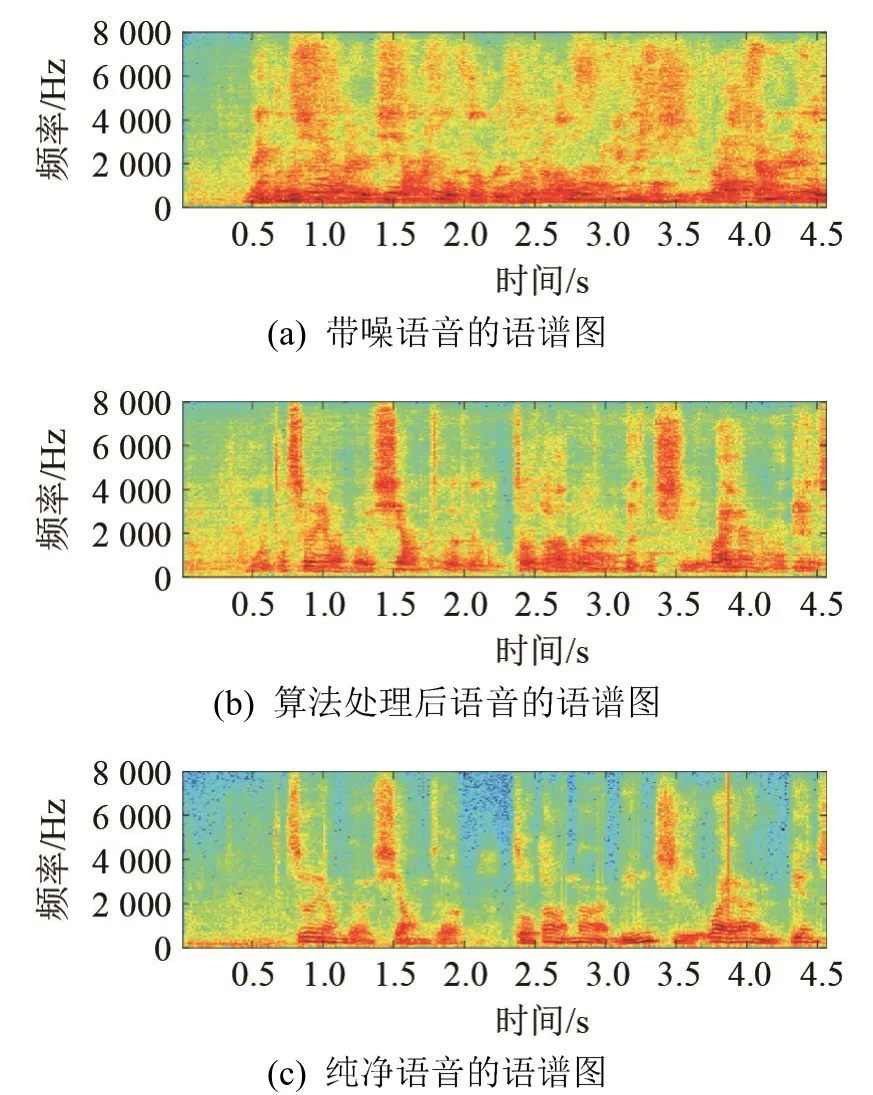
图5 测试集语谱对比图Fig.5 Spectrograms of testing dataset
利用实录实验采集数据,实验场景为有4个说话人的房间,说话人的性别为两男两女,均用普通话朗诵,实录语音的信干比为-0.1 dB。对目标语音进行增强,超指向波束形成算法使实录信号信干比提高了4.59 dB,谱减法使实录信号信干比降低了0.86 dB,本文算法使实录信号信干比提高了12.16 dB。在实际场景下,本文算法语音增强的效果明显优于超指向波束形成算法和谱减法。
本文算法利用4个方向的超指向波束特征与掩蔽值之间的对应关系实现了语音增强,空间信息和频谱信息均得到了利用,而且神经网络将特征值与掩蔽值建立起了非线性映射关系。而超指向波束形成算法为线性滤波,只利用了空间信息,谱减法只利用了频谱信息。基于上述原因,本文算法效果优于超指向波束形成算法和谱减法。目前,“鸡尾酒会”问题的难点为人声在复杂声学场景下的频谱特征,尤其是同性之间的频谱特征相似程度大,方位可能重叠。因此,在该场景下利用频谱信息和空间方位信息分离目标语音困难较大,而神经网络的优势在于能够从大数据中学习到分类特征甚至学习到某些尚未定义的特征。本文算法致力于实现房间场景下的语音增强。
根据实验可知,训练集数据需要达到一定的量级且生成数据的场景种类要丰富,本文训练集数据总时长达到了10 h。具备以上条件的神经网络具有较好的可推广性。神经网络需要训练足够的轮次且每一轮数据的顺序需要随机打乱,使损失函数值降到足够低,此种状况下,神经网络的拟合效果较好。
4 结 论
本文将超指向波束形成算法和神经网络算法相结合,在房间存在多说话人的声学场景下,实现了目标方向语音分离、混响抑制和语音质量的提升。利用仿真数据集训练神经网络,学习此场景下多波束联合特征和目标语音频谱间的复杂关系。通过中文语料库数据的测试评价和实录数据的实验表明,该方法在上述场景中具有明显的语音增强效果。
在实际应用本文算法中的神经网络时,可考虑将若干帧数据联合作为一组输入数据序列,经过神经网络映射得到与之对应的掩蔽值序列,训练和预测均如此处理,可以增强算法的实时性、降低硬件要求。此外,可通过在神经网络的层之间增加过渡层;把神经网络进行分类,与标签分别进行对应;压缩神经网络;先训练大的神经网络,再用大网络训练小网络;也可采用美尔谱、分频带等方法减少计算量。目前国内已经有单位将深度学习的降噪算法运行在高级精简指令集计算器(Advanced Reduced Instruction Set Computer Machine, ARM)上。
