基于电子病历系统的脑血管病专科大数据科研平台设计与应用
2020-07-07林琳王韬甘伟邢玉龙
林琳,王韬,甘伟,邢玉龙
作者单位
1100070 北京首都医科大学附属北京天坛医院信息中心
2北京嘉和海森健康科技有限公司
近年来,脑血管病已成为我国致死率最高的慢性非传染性疾病之一,对人民健康和社会经济造成了巨大危害[1]。与此同时,优质医疗资源总量的不足及其在地区间分布的不平衡,也加剧了医疗服务供给与脑血管病患者需求间的矛盾。为缓解脑血管病医疗资源及诊疗技术水平发展的不均衡,提升对脑血管疑难病、急危重症患者的救治能力,首都医科大学附属北京天坛医院秉承《“健康中国2030”规划纲要》中关于脑血管病防控的精神,基于在神经系统疾病方面的临床积累和科研发展,探索了以脑血管病专科大数据科研平台为支撑,通过临床-科研一体化模式提升医院脑血管病临床诊疗水平和科研能力的新思路、新方法,也为推进区域内医疗卫生协同发展、带动区域整体医疗水平提升提供了重要参考。
脑血管病专科大数据科研平台是以大数据及人工智能技术为依托,通过对院内业务系统海量临床数据以及院外诊疗信息的采集、整理、分析、挖掘,为科研人员提供真实可靠的数据资源和高效便捷的科研工具,提升科研效率和质量,并通过成果转化辅助临床决策、改善诊疗水平。
1 脑血管病专科大数据科研平台架构
脑血管病专科大数据科研平台主要包括数据采集层、数据治理层、数据模型层和数据服务层。平台采用大数据架构,基于Hadoop集群以及相关大数据技术,从临床业务系统、实验室信息系统、生物样本库以及院外随访、电子数据获取系统(electronic data capture system,EDC)中采集各类疾病相关数据,集成、整合后形成科研数据中心;再利用深度学习技术挖掘数据特征,构建多种数据模型;最后,结合大数据处理引擎,提供数据检索与挖掘、数据可视化、数据质量监测、临床决策辅助等数据应用服务,支持医院脑血管病临床研究及诊疗协作。具体如图1所示。
1.1 数据采集层 通过提取-转化-下载(extract-transform-load)工具从医院数据中心及外部EDC系统等抽取、集成患者诊疗相关数据,包括电子病历、检验报告、随访、基因检测等。通过对患者就诊过程的追踪和信息积累,可很好地解决数据稀疏、偏倚等问题,可使数据更加可靠、及时、公正,排除数据分析可能造成的偏差[2]。
1.2 数据治理层 由于原始数据量大且形式多样、结构各异,为正确获取数据价值,还需对采集的数据做进一步治理,包括:数据清洗、量化、自然语言处理及质量控制等,使业务数据变为可直接利用的标准化数据集,即科研数据中心的数据。
1.3 数据模型层 在科研数据中心基础上,利用深度学习技术,建立不同维度的数据分析模型,包括:疾病模型、症状模型等基础模型;知识图谱、时间序列等融合模型;诊断推荐、治疗方案推荐等深度挖掘模型。通过对不同数据间深层次关联关系的分析,为后续的数据服务提供支撑。
1.4 数据服务层 利用上述数据模型,平台搭建了一系列大数据引擎,如:科研知识转化引擎、搜索引擎、数据挖掘引擎、可视化引擎等,最终实现一体化科研服务和临床决策支持、疾病预后智能预测、科研知识库以及真实世界研究等功能应用,提高科研效率和质量的同时,也提升了临床医师的决策精准度。
2 脑血管病专科大数据科研平台的主要功能
2.1 一体化科研服务 所谓“一体化科研服务”,即指临床医师可通过平台一站式完成从问题挖掘、病历招募,到数据挖掘和统计分析的全流程科研工作(图2)。
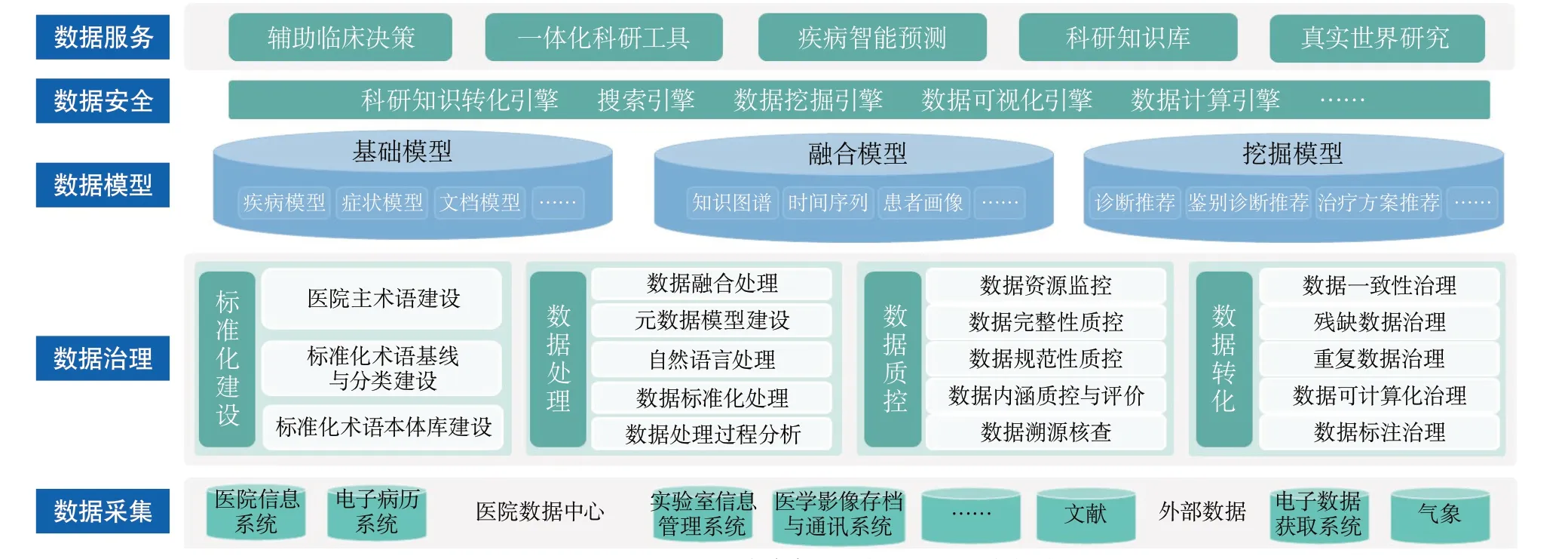
图1 脑血管病专科大数据科研平台架构

图2 一体化科研服务流程示意图
问题挖掘:即基于选定的科研变量,自动进行多维度统计统计,如:患者分布、疾病分布、症状词云等,帮助医师更好地聚焦科研问题。
病例招募:平台可提供基于全样本的病例筛选服务,帮助医师快速建立专病库,并支持数据精确检索、全文检索以及外部数据导入等。
数据质控:针对可能存在的数据缺失、异常值等现象,平台支持对数据进行完整性、规范性等检测;对质量较差的数据,针对不同问题分门别类,给出数据质控报告,使数据问题透明化;同时,还可支持数据溯源原始病历,通过问题反馈促进医师病历书写质量提升。
数据处理:在数据进入统计模型之前,可利用平台自动进行量化和智能转化;同时对于质控发现的问题数据,可通过数据填补、自定义变量等进行有效治理,保证数据的准确性及可靠性。
统计建模:完善的统计学分析工具和灵活的自定义统计模式对于科研人员非常重要[3]。为此,平台基于R语言,集成了多种医学统计模型,操作者可自由定义分析的变量以及分析模式,导出不同形式的统计分析图表,直观地发现数据所体现出来的研究价值。
2.2 疾病预后智能预测 研究者通过疾病数据进行影响因素分析、主成分分析、决策树挖掘等,从中提取出重点疾病特征,继而利用深度学习技术进行模型训练,搭建出疾病智能预测引擎。当临床诊疗过程中触发该规则时,即可实时提醒医师疾病发展进程中出现复发、死亡、伤残或并发症等的概率,从而指导临床治疗,提高决策水平。
2.3 科研知识库 平台通过数据挖掘产生的知识模型,如本体库、语义网络规则语言(semantic web rule language)以及疾病推理机制等,经过沉淀形成科研知识库,将进一步辅助临床,对于优化疾病诊疗标准、提升诊疗服务效率和缩短医师学习曲线等都具有重要意义[4]。
2.4 临床决策支持 科研的最终目的是回归临床、指导实践。通过对大数据的挖掘、分析,如:相似病例分析、治疗有效性分析、疾病相关性分析等[5],可以对临床诊治的疗效、并发症等给予循证医学的证据支持,从而指导临床实践,提高医疗质量。
2.5 真实世界研究 真实世界研究是指在临床真实条件与现实环境下,基于较大样本量(覆盖具有代表性的更广大受试者),比较和选择不同医疗手段的过程及其结局研究。由于其样本数据量较大,单纯依靠手工处理不仅费时费力,质量也难以保证。大数据科研平台对于海量数据的采集、处理、分析优势,使其成为真实世界研究的有力助手。
3 脑血管病专科大数据科研平台应用成效
首都医科大学附属北京天坛医院神经脑血管病专科大数据科研平台自2017年正式部署上线后,应用效果良好。以疾病预测为例,科研人员在日常急诊接诊过程中,持续积累了2012年5月-2019年6月完成前循环脑梗死急诊取栓手术的患者共379例,利用患者ID号经平台查询后,抽取其相关数据,并进行标准化和融合处理,建成“前循环脑梗死急诊取栓专病数据库”。在此基础上,利用平台的智能特征筛选功能,选出包括收缩压、心房颤动、高血糖、脑梗死体积、尿蛋白阳性在内的5个有显著意义变量;再自动匹配多因素Logistic回归模型及ROC曲线,形成取栓后颅内出血发生风险预测模型(Logit=2.172+0.341×收缩压+1.623×心房颤动+1.120×高血糖+1.856×脑梗死面积+0.677×尿蛋白阳性)。结果显示,该模型ROC曲线下面积为0.749,灵敏度为0.751,特异度为0.820,具有较好的预测效能。
4 总结
随着科学技术的发展和循证医学理念的不断加深,如何通过高质量的临床研究,有效进行疾病病因和预防因素的探索,并将疗效和安全性更好的干预措施尽快转化至临床,成为临床研究人员面临的主要问题[6]。
基于此,首都医科大学附属北京天坛医院在医院数据中心基础上建立了脑血管病专科大数据科研平台。该平台打破了传统以单个科室、单个项目独立建设为主的应用模式,形成统一、开放的全新科研体系,不但加快了全院数据的共享、利用,也实现了灵活、自定义的临床科研一体化科研流程,减轻了科研人员的工作负担,提高了数据录入的便利性及利用效率,对提高科研及临床水平都具有重要意义,同时也为推动区域内医疗服务质量的提升起到示范作用。
