中国乘用车工况构建
2020-07-02吴志新李孟良于晗正男贺可勋安晓盼
刘 昱,吴志新,李孟良,于晗正男,汪 洋,贺可勋,安晓盼
(中国汽车技术研究中心有限公司,天津300300)
0 引 言
学者对行驶工况的开发进行了一系列研究:杨延相等[5]以车速和加速度等行驶特征参数为准构建了天津工况.姜平等[6]采用离散小波变换对汽车实际行驶工况数据进行压缩重构消除路面干扰因素的影响,构建合肥市典型工况.王军方等[7]采集北京市多类车型的实际行驶数据,构建北京市典型行驶工况.秦大同[8],彭育辉等[9]分别利用k均值聚类算法构建乘用车城市工况和公交车行驶工况,并进行实验验证.我国在工况开发方面取得了许多重要成果,但依然存在一些问题:现有工况开发研究局限在对城市或区域的调研,我国幅员辽阔,气候和交通状况差异显著,缺乏全国范围的自主行驶工况;现有研究主要根据实验采集数据计算速度区间权重,构建工况受车队组建的主观性影响较大.
2015年,工信部联合五部委共同委托中国汽车技术研究中心开展为期3年的“中国工况”研究和开发,主要包括开发中国汽车行驶工况并修订相关测试标准.本文提出中国工况开发技术路线,从数据采集、数据分析、权重因子开发和工况构建等方面详细介绍中国工况的开发过程.
1 技术路线
技术路线是开发工况的关键,在总结国内外工况开发先进经验的基础上,制定我国乘用车工况开发方法[10-11],如图1所示,主要包括:
(1)数据采集及预处理.
利用自主行驶的方法在典型城市采集车辆运行数据,将其切分短行程;制定包含运行时间、速度范围、加速度范围、最大怠速时长、均速比例和数据缺失率在内的筛选规则,筛选短行程;将筛选后的短片段分为不同速度区间的运动片段库和怠速片段库.
(2)权重因子开发.
当仙灵骨葆胶囊的药物成本在0.62~0.97元/粒变动时,其他参数不变,随之ICER变动范围在21 479.25~48 498.90。当仙灵骨葆胶囊的药物成本选取了最小值0.62时,芪骨胶囊方案和仙灵骨葆胶囊治疗方案所需的总成本分别为1 998.93元和 1 320.44元,有效率为99.72%和98.32%,ICER为48 498.90。当仙灵骨葆胶囊的药物成本选取了最大值0.97时,芪骨胶囊方案和仙灵骨葆胶囊治疗方案所需的总成本分别为1 998.93元和 1 698.44元,有效率为99.72%和98.32%,ICER为21 479.25。
获取典型城市的车辆实际道路GIS 低频交通量大数据,建立速度—流量模型,得到各城市路网上所有行驶车辆的车辆小时数分布;计算不同速度区间的权重,以及同一速度区间不同城市的权重.
(3)统一的速度—加速度分布建立.
计算各城市各速度区间的速度—加速度分布,利用权重因子矩阵进行加权,获取各个速度区间统一的速度—加速度分布.
(4)工况合成.
根据各速度区间的权重和工况曲线的总时长,确定各速度区间的时长;在此基础上,对应速度区间运动片段及怠速片段的平均时长,确定各速度区间运动片段和怠速片段数目;利用卡方检验确定最优的片段组合作为中国轻型乘用车工况(China Light-duty Passenger Car Test Cycle,CLTC).
2 工况开发
2.1 数据采集及预处理
选择全国41 个典型城市,采用自主行驶的方式对约3 300辆车开展数据采集.采集车辆覆盖各种车辆类型(M1、M2 和N1 类车,传统车和新能源车,不同排量),不同的道路类型和行驶条件.
车载终端将采集车辆GPS信号和OBD相关参数信息按照统一的数据协议编排,通过GPRS网络实时发送到中国工况信息化平台服务器,实现数据采集.与传统工况数据采集相比,本文方法保证采集到的数据在时间和空间上具有可比性,适合大规模数据采集.采集周期1年,共计1 600万km;采集参数主要包括时间、车速、发动机转速等.
车辆从起步出发至目的地停车,会经过多次起步、停车.定义车辆从一次停车开始到下一次起步开始为怠速片段,车辆在一次起步到下一次停车为运动片段.据此,车辆一次行程可视为多个短行程(一个运动片段加一个怠速片段)组合,如图2所示.
实验过程中,受采样设备(如GPS 在山区或隧道内丢失信号)或其他不可抗因素影响,一些采集数据不合理或无效,故制定多类处理规则对短行程进行预处理.
对采集数据进行系统分析,借鉴WLTP 规则,制定片段时长规则,运动片段长度需在[10,3 600)s间.我国交通法规规定最高车速不能大于120 km/h,考虑车辆在高速路行驶时会出现一定程度的超速现象,将片段最高车速设置为130 km/h.车辆加速度大于4 m/s2时,相当于车速在1 s 内增加超过14 km/h,正常行驶条件下是不可能发生的,予以删除;同样,当加速度小于-4.5 m/s2时,数据也是不合理的.车辆怠速持续时间超过200 s,属于非正常驾驶情况(如驾驶员停车休息,而GPS 仍在连续记录),此类片段使数据怠速比例偏高,影响最终开发出工况的代表性,对其进行修正.数据采集过程中GPS 车速难免出现丢失,为保证最终数据能代表车辆的实际运行状态,设置筛选条件为数据缺失率小于10%.

图1 工况开发技术路线Fig.1 Technical route of driving cycle development
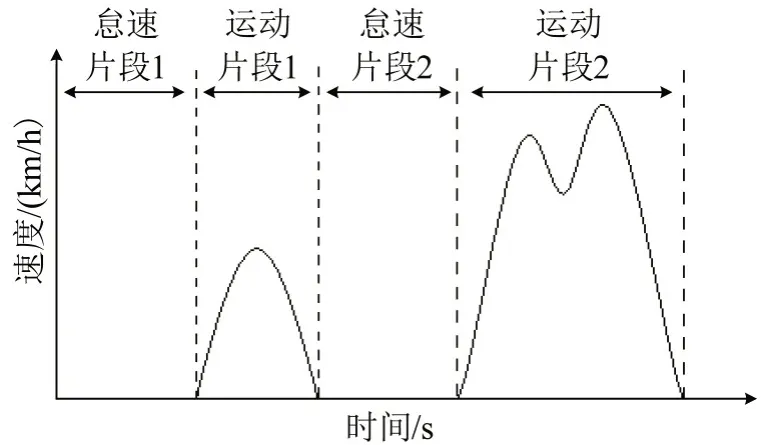
图2 短行程示意图Fig.2 Schematic diagram of short trip
2.2 特征计算及短行程数据库划分
为描述各短片段差异,计算运行时间、平均速度等11 种片段特征,定义参见文献[10].各城市及全国总体平均速度和怠速比例如图3和图4所示.
不同时间、地理位置和道路类型的短片段反映的交通状况可能是一致的,如繁忙的高速公路与拥挤的城市道路片段特征可能一致.将片段类型和交通状况联系起来,分为3 个运动片段库和3个怠速片段库,分别对应低速、中速和高速区间,速度区间阈值分别为60 km/h和80 km/h.
2.3 权重因子开发
传统方法根据实验采集数据计算权重,使构建工况受车队组建的主观性影响较大.为克服传统方法的不足,本文创新性引入百度后台GIS交通量大数据计算权重因子.统计各速度区间交通量,除以总交通量,获得不同速度区间的权重因子,如表1所示.可以看出,我国车辆主要运行在城区(低速)和城郊(中速),在高速区间运行比例较低.

图3 各城市平均速度Fig.3 Average speed of different cities
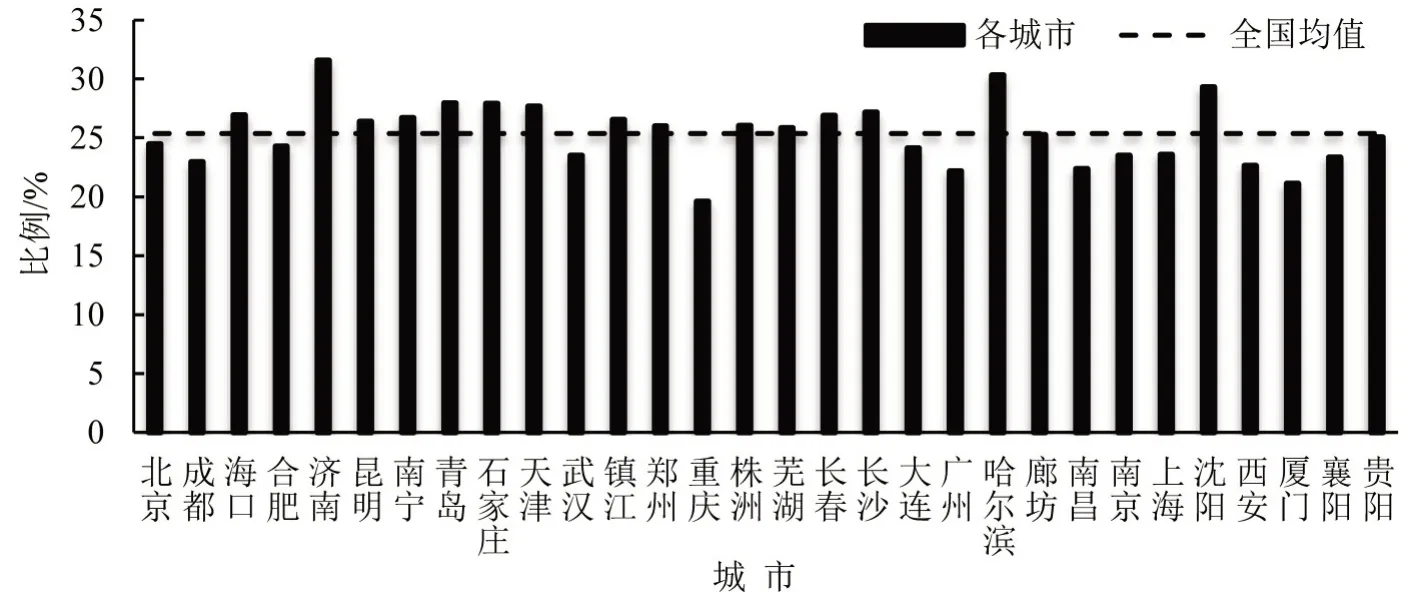
图4 各城市怠速比例Fig.4 Idle ratio of different cities
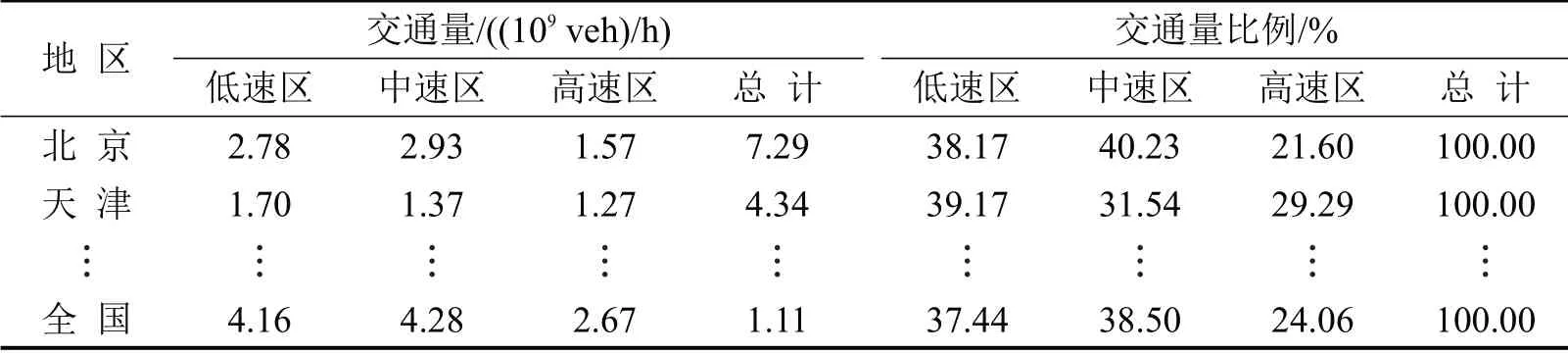
表1 各城市低/中/高/速区间的交通量及加权因子Table 1 Traffic volume and weighting factors of low/medium/high speed phases
2.4 统一的速度—加速度分布建立
低速区间统一的速度—加速度分布建立如图5所示,其中,左侧3个图分别为城市1、城市2和城市n的速度—加速度分布气泡图,气泡越大表示该工况点的分布频率越高,W1,W2和Wn分别为对应城市低速区间的权重.根据低速区间各城市的速度—加速度分布和对应区间的城市权重,加权获得低速区间统一的速度—加速度分布.其他速度区间的加权方案与低速区间相同.
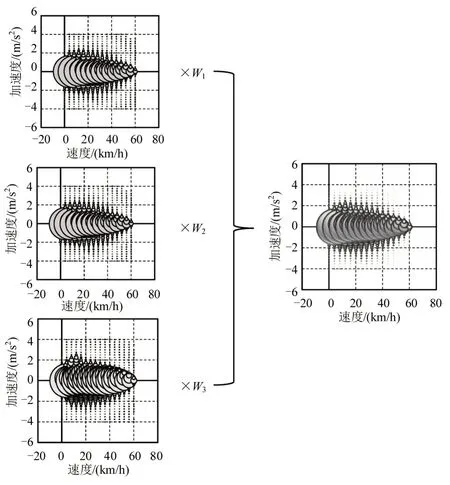
图5 低速区间速度—加速度分布图Fig.5 Velocity-acceleration distribution of low speed phase
2.5 工况构建
与世界轻型车测试工况(Worldwide Harmonized Light-Duty Driving Test Cycle,WLTC)类似,CLTC 工况的持续时间也设置为1 800 s.1 800 s 的持续时间既能满足统计学的代表性,又具备在实验室内进行排放测试和油耗测试的可行性.工况曲线各速度区间时长由1 800 s 乘以其权重得到,低速区间时长674 s;中速区间时长693 s;高速区间时长433 s.
各车速区间运动片段和怠速片段数目为
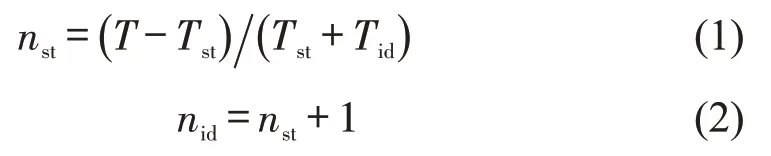
式中:T为时长;Tst为运动片段的平均时间长度;Tid为怠速片段的平均时间长度;nst为运动片段个数;nid为怠速片段个数.各参数取值通过数据分析获得,计算结果圆整后如表2所示.
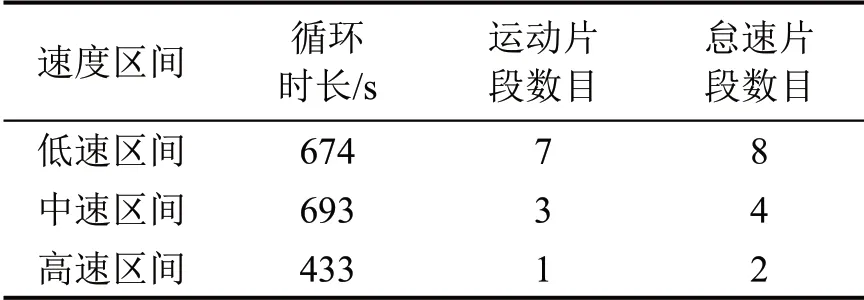
表2 各速度区间运动及怠速片段数目Table 2 Number of motion segments and idle segments in each speed interval
计算运动片段与怠速片段的累计频率分布,低速和中速区间根据各区间短片段个数ni,将累计频率分布均分成ni等份.在每个等分区间找到该区间50%分位累计分布对应的x点,x点时长作为从数据库中选择片段的依据.由于高速区间时长限制,高速区间运动片段和怠速片段时长通过怠速比例计算得到.各速度区间运动片段时长选择结果如图6~图8 所示,怠速片段选择方式同运动片段.
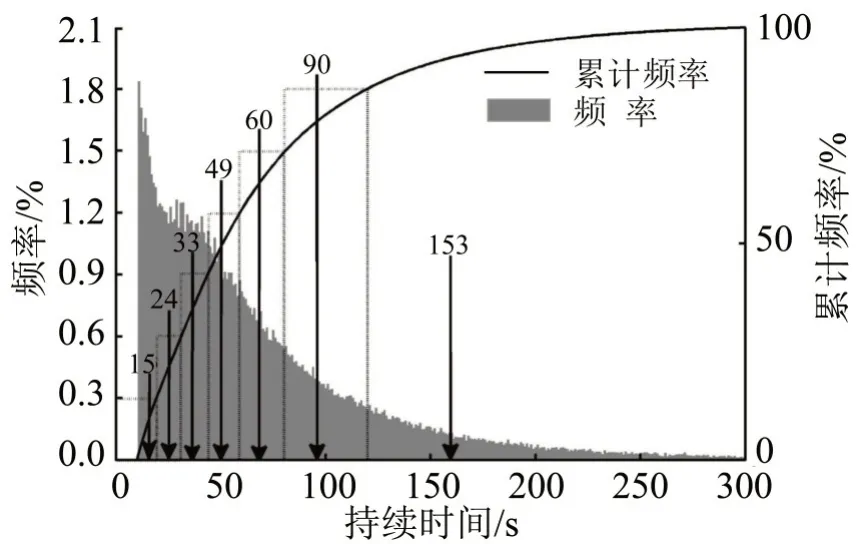
图6 低速区间运动片段时长选择Fig.6 Short trip length selection of low-speed phase
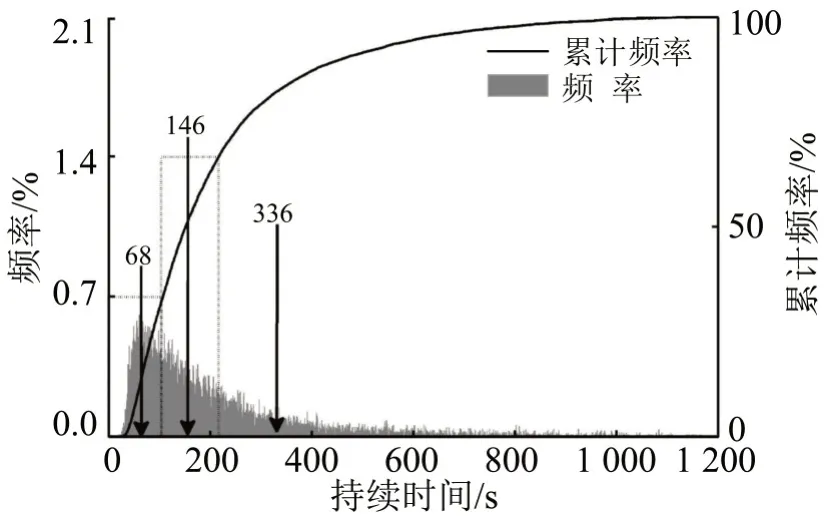
图7 中速区间运动片段时长选择Fig.7 Short trip length selection of the middle-speed phase
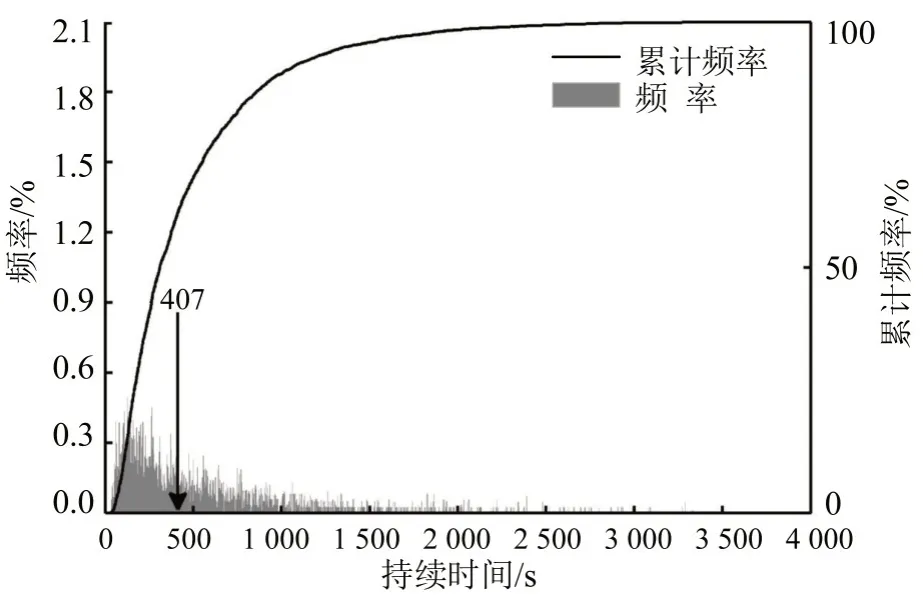
图8 高速区间运动片段时长选择Fig.8 Short trip length selection of high-speed phase
根据片段时长选择候选运动片段,并按照笛卡尔积自由组合.短片段组合数目较多,利用平均速度、相对正加速度等参数对短片段组合进行初步筛选,使计算量和卡方检验次数控制在合理范围内.对满足条件的短片段组合进行卡方检验.选择卡方检验结果较好的,即卡方值p较小的组合作为最优解.
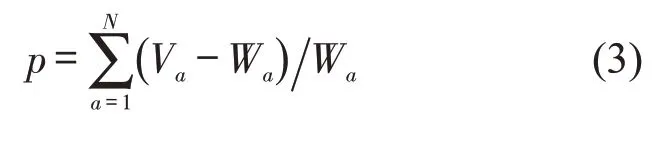
式中:a为速度—加速度分布点;N为分布点总数;Va为选择片段a点的速度—加速度分布值;Wa为对应点的统一的速度加速度分布值.
为确定CLTC 工况中第1 个怠速片段和运动片段,对调研中每天采集的第1个怠速片段和运动片段进行单独统计分析.第1个怠速片段的平均持续时间约17 s,选择与其最接近的时长14 s的怠速片段作为第1个怠速片段.第1个运动片段的平均时长为58 s,平均速度为25 km/h,选择卡方检验获得低速区间运动片段中与之最接近的短片段作为第1 个运动片段.为模拟市区拥堵情况,将CLTC工况低速区间中最大速度最小的3 个运动片段和时长最长的3 个怠速片段进行组合模拟城区道路中交通拥堵的工况.将CLTC工况最后一个怠速片段均设置为10 s,保证采样稳定性.将低速、中速和高速区间依次排列得到最终工况曲线.
CLTC工况共包含11个运动片段和12个怠速片段,运动和怠速片段交替排列,工况时长1 800 s,平均车速29.0 km/h,最大车速114 km/h,怠速比例22.1%,如图9所示.
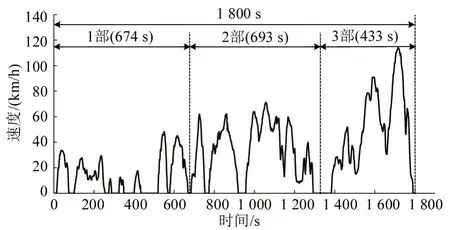
图9 CLTC 工况Fig.9 CLTC cycle
3 CLTC工况与采集数据及其他典型工况对比
为验证所构建工况的有效性,选择平均速度等7 个典型参数对工况曲线特征进行描述.计算CLTC 工况,NEDC 工况,美国联邦轻型车测试工况(Federal Test Procedure,FTP-75),WLTC工况,以及车辆实际采集数据的工况特征,对采集数据进行GIS 加权,结果如表3 所示.为衡量各典型工况与我国车辆实际运行工况的差异,计算各典型法规工况与实际采集数据GIS加权值的差异百分比,结果如表4所示.

表3 各工况与实际采集数据特征Table 3 Driving characteristics of different cycles and actual collected data

表4 各工况与实际采集数据差异Table 4 Comparison of differences between typical cycles and actual collected data
从表3 和表4 可以看出:与其他典型工况相比,CLTC 具有平均速度低,怠速比例高和加减速频繁的特点;在平均速度等典型工况特征方面,CLTC 工况与实际采集数据GIS 加权结果吻合度最高,最大偏差为7.55%,NEDC、FTP75 和WLTC工况与我国实际偏差较大.
4 结 论
依托“中国工况”项目,在全国41 个城市展开全球范围内范围最大、规模最广的一次数据采集,全面了解我国乘用车的实际行驶特征;创新性提出利用GIS数据计算工况各速度区间权重,克服传统工况构建方法宏观权重受主观选择影响的不足;开发了中国乘用车工况CLTC,与其他典型工况相比,中国工况具有低平均速度、高怠速比例和频繁加减速的特点.对比构建的CLTC工况曲线特征参数与其他典型工况曲线及实测数据GIS 加权结果,验证了CLTC工况的有效性.
