Fast-armored target detection based on multi-scale representation and guided anchor
2020-07-02FanjieMengXinqingWangFamingShaoDongWangXiaodongHu
Fan-jie Meng, Xin-qing Wang, Fa-ming Shao, Dong Wang, Xiao-dong Hu
Department of Mechanical Engineering, College of Field Engineering, Army Engineering University of PLA, Nanjing, 210007, China
ABSTRACT Focused on the task of fast and accurate armored target detection in ground battlefield, a detection method based on multi-scale representation network (MS-RN) and shape-fixed Guided Anchor (SF-GA)scheme is proposed. Firstly, considering the large-scale variation and camouflage of armored target, a new MS-RN integrating contextual information in battlefield environment is designed. The MS-RN extracts deep features from templates with different scales and strengthens the detection ability of small targets. Armored targets of different sizes are detected on different representation features. Secondly,aiming at the accuracy and real-time detection requirements, improved shape-fixed Guided Anchor is used on feature maps of different scales to recommend regions of interests(ROIs).Different from sliding or random anchor, the SF-GA can filter out 80% of the regions while still improving the recall. A special detection dataset for armored target, named Armored Target Dataset (ARTD), is constructed, based on which the comparable experiments with state-of-art detection methods are conducted. Experimental results show that the proposed method achieves outstanding performance in detection accuracy and efficiency, especially when small armored targets are involved.
1. Introduction
Armored equipment remains the main force on the ground battlefield [1]. Fast and accurate detection of armored targets is vital to wining. Digital image sensor can be used for a variety of platform, including Unmanned Aerial Vehicles (UAV), Armored Scout Car (ARSV) and armored vehicles. The method based on digital image processing is key to detection of armored targets.Different from the general detection problems, the detection of armored targets in complex battlefield faces greater challenges,which are mainly manifested in the following aspects:
· Smaller target size is common.Armored targets typically attack at a distance of several hundred meters or even more than a kilometer, which demand the detection system to be able to detect armored targets less than 20 pixels in height with 1024 × 768 input image. The armored targets are smaller than most targets in common object detection dataset. In Fig.1, we compare the distribution of target instance sizes in VOC2007,KITTI and ARTD.It can be observed that the average target size of our dataset is significantly smaller than that of others.
· Modern weapons and equipment emphasize the ability to forestall the enemy,which demand the detection system higher detection accuracy and efficiency.
· Complicated background. Armored targets usually appear in battlefield such as the jungle,desert,grassland,which are more complicated than general scenario. Dust caused by the movement of armored targets and muzzle fire and smoke pollute the battlefield images. Moreover, the armor targets adopt camouflage, smoke shielding to avoid exposing, which reduce the distinguishing ability from the background at the feature level.
· There are no ready-made sample images with labels for armored targets.
In general, compared with other detection problems, detection of armored targets with high accuracy and efficiency is more challenging. Fig. 2 presents typical armored target in our ARTD dataset.
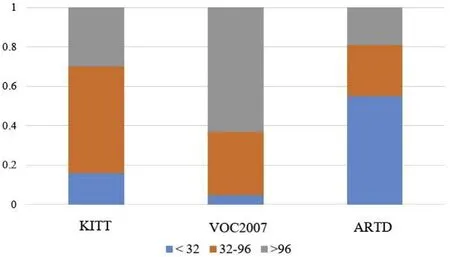
Fig.1. Distribution of target instance sizes in VOC2007, KITTI and ARTD.
Considering all the difficulties mentioned above,we proposed a fast and accurate framework for armored targets detection,including a multi-scale representation network (MS-RN) and shape-fixed Guided Anchor(SF-GA)scheme.Instead of a“one-sizefits-all” approach, we run different super-classes of contextual anchors on different-scale feature maps extracted from MS-RN,which enhance the network ability to detect small armored targets while ensuring the efficiency. Unlike traditional sliding or random anchors,we use shape-fixed Guided Anchor to crop region of interest (ROI). The prior information of armored target sizes is used to design anchor shapes. Compared with sliding or random anchors, the Guided Anchor filters out 80% of the regions without armored targets.Aiming at the challenge 4, we construct a special detection dataset for armored target, named Armored Target Dataset(ARTD).Serval comparable experiments are operated with state-of-the-art detection methods and our method.
Our main contributions are summarized as follows. Firstly, a multi-scale representation network was proposed which can balance the detection efficiency and the ability of detecting small armored target. Secondly, a shape-fixed Guided Anchor (SF-GA)integrating the shape prior information can efficiently filter out regions irrelative to armored targets. More importantly, a special detection dataset ARTD is constructed for armored target.
The rest of our paper is organized as follows: In Section 2, we introduce the related work.In Section 3 we give an overview of the method firstly and present the detail of our armored target detection method.The experimental evaluation is provided in Section 4.Finally,we presented some conclusions and future work in section 5.
2. Related work
2.1. Detection of armored target
Methods of armored target detection mainly include visible image-based methods [1-4] and infrared image-based methods[5-7]. Among them, the method based on infrared image has strong anti-interference ability, but the infrared image has fewer features than visible image and its detection distance is short.Visible image equipment is much cheaper, and its image contains rich features.The most common armored target detection pipeline is based on human-engineering-based features (e.g. Histogram of Oriented Gradient (HOG) [8], Scale-Invariant Feature Transform(SIFT)[9])or shallow-learning-based discriminative classifiers(e.g.Support Vector Machine (SVM) [10]). Shenpei Chen et al. [3]construct a variable target model to identify the local part based on HOG feature and use the latent SVM to find the position of the part and the whole armored target. Congli Wang et al. [5] detect armored target based on morphological wavelet decomposition through calculating a global threshold.However,methods based on handcrafted features need to combine sliding windows to detect armored targets,which means a lot of computational consumption.In addition,such methods are often weak in robustness and poor in detecting small armored targets. In recent years, with the breakthrough of the deep learning algorithms [11,12], several detection methods based on convolutional neural network(CNN) have been proposed. Among them, region convolutional neural network (RCNN) [13] and its variants [14-17] have achieved great success in generic object detection, such as traffic-sign detection [18,19],pedestrian detection [20], and so on. However, recognizing small objects like armored target is notoriously challenging due to their low resolution and noisy representation[21].Some efforts[22-25]have been devoted to dealing with the problems of small object detection and recognition. Increasing the scale of input is a straightforward way but results in heavy time [22]. Some others[23-25] have focused on developing network variants to generate multi-scale features with multiple layers of lower-level features.Sun,H.et al.[1]propose a top-down aggregation(TPA)network in a basic Faster R-CNN[26]framework to detect armored target in the battlefield. Quandong Wang et al. [27] apply faster regionconvolutional neural network (Faster R-CNN) and a coarse image pyramid solve the detection problems of armored target.Compared with methods based on handcrafted features, the CNN-based methods have higher accuracy and stronger robustness. However,methods mentioned above still use sliding or random anchors, or do not enhance the ability to detect small armored target.

Fig. 2. Typical armored targets in battlefield scene of ARTD.
2.2. Guided anchor
Region anchors are the cornerstone of modern object detection techniques.In most detectors like Faster R-CNN,RetinaNet[28]and YOLO[29],anchors are sampled uniformly over the spatial domain with a predefined set of scales and aspect ratios. Such anchors are adopted in many methods [30-32]. However, this scheme may hamper the speed and accuracy, because most of the sliding or random anchors correspond to false candidates that are irrelevant to the object of interests.Wang,J.et al.[33]present an alternative scheme, named Guided Anchoring, which leverages semantic features to guide the anchors.They use an anchor generation module with two branches. The first branch N_L yields a probability map used to predict the anchor location with a predefined threshold ε_L.The second branch N_s yields a two-channel map to predict the anchor shape (w, h) for each location. The Guided Anchoring scheme can filter out most of the regions that do not contain a target while still maintaining the same recall. In our application,armored targets have regular shapes.By integrating the shape prior information into the design of anchors,the detection efficiency can be increased.Hence,we improve Guided Anchor scheme in design of anchor shapes and propose position-predicted and shape-fixed anchor.
3. Proposed method
3.1. Overview of our method
Focused on armored target detection in ground battlefield, we proposed a fast detection method,which is shown in Fig.3.Instead of a “one-size-fits-all” approach, multi-scale representation network is created to fit both small and large armored targets.First,we create a coarse image pyramid including a 2 × interpolation image and a 0.5 × interpolation image. Features of small armored targets are more distinct in 2 × interpolation image and image compression can improve the detection efficiency.Both images are fed into a shared CNNs to predict template responses for both detection and regression. Different super-class of anchors are guided at each resolution respectively. We run A-class Guided Anchors (tuned for larger than 64 px tall armored targets) on 0.5×interpolation image,while run B-class Guided Anchors(tuned for less than 64px tall armored targets)combined with context on 2 × interpolation image. In the end, we apply non-maximum suppression (NMS) at the original resolution to get the final detection results.
3.2. Multi-scale armored representation
“Hypercolumn”features[34]extracted from multiple layers are the cornerstone of most deep learning methods. Detection methods like Faster R-CNN and You Only Look Once (YOLO) use a scale-normalized template and detectors to find objects as shown in Fig.4(a).However,the size of the template is controversial and it is difficult to find a scale-normalized template and detector to fit both small and large armored targets. On the one hand, the highresolution template can magnify local features of smaller objects,while on the other hand,the low-resolution template can improve the efficiency of armored targets detection [21]. As shown in Fig. 4(b), To balance both concerns, we use Multi-Scale Representation Network(MSRN)to fit both small and large armored targets.A-class anchors (tuned for larger than 64px tall armored targets)are operated on low-resolution template(Template3).Accordingly,the B-class anchors are tuned for less than 64px tall armored targets, running on high-resolution template (Template2). Running both small and large anchors on high-resolution images may cause detection inefficiency, or running both anchors on low-resolution images may suffer from a lack of detailed information and poor performance in small armored target detection. Our method balances the detection efficiency and the ability of detecting small armored target.
3.3. Guided anchors for armored targets
Region anchors are the cornerstone of modern object detection techniques. Anchors are regression references and classification candidates to predict proposals (for two-stage detectors) or final bounding boxes(for single-stage detectors).In traditional detectors(e.g.Faster RCNN),anchors are defined as a set of sliding windows with fixed scales and aspect ratios.In order to ensure a sufficiently high recall for proposals,a large number of anchors are used in such methods. Obviously, this scheme is extremely waste-computed because most of anchors are placed in areas that are irrelevant to the object of interests, such as the sky or desert. The scheme leveraging semantic features to guide the anchors seems the only way to resolve this conflict. In Wang, J. et al. [22], Region Proposal by Guided Anchoring was proposed. Inspired by this, we propose improved shape-fixed Guided Anchor for armored target. We integrate the shape prior information into the design of anchor shapes.
3.3.1. Anchor location prediction
There are two general rules for a reasonable anchor design:Firstly, anchor centers should be well aligned with feature map pixels. Secondly, the receptive field and semantic scope should be consistent. Meanwhile, anchors should in a smaller size and number. A smaller number of anchors containing all targets means a decrease in calculations of regression and classification, i.e. an increase in the detection efficiency. Instead of region proposal network(RPN), We take a more efficient scheme.Fig. 5 shows our improved guided anchor generation module.The module uses two branches to predict the anchor location and shape,respectively.The location prediction branch NLyields a probability map P(location)=p(%|FI).p(i,j|FI)corresponds to the location with coordinate,where s is stride of feature map.In sub-network NL,we use a 1×1 convolution on the feature map FIto obtain probability map containing target scores at each position. An elementwise sigmoid function is used to convert the probability map to values. According to the probability values of each position and a global threshold value εL, we determine the active regions where armored targets may possibly exist.This process can filter out 80%of the regions while still maintaining the same recall.
3.3.2. Anchor with fixed shape
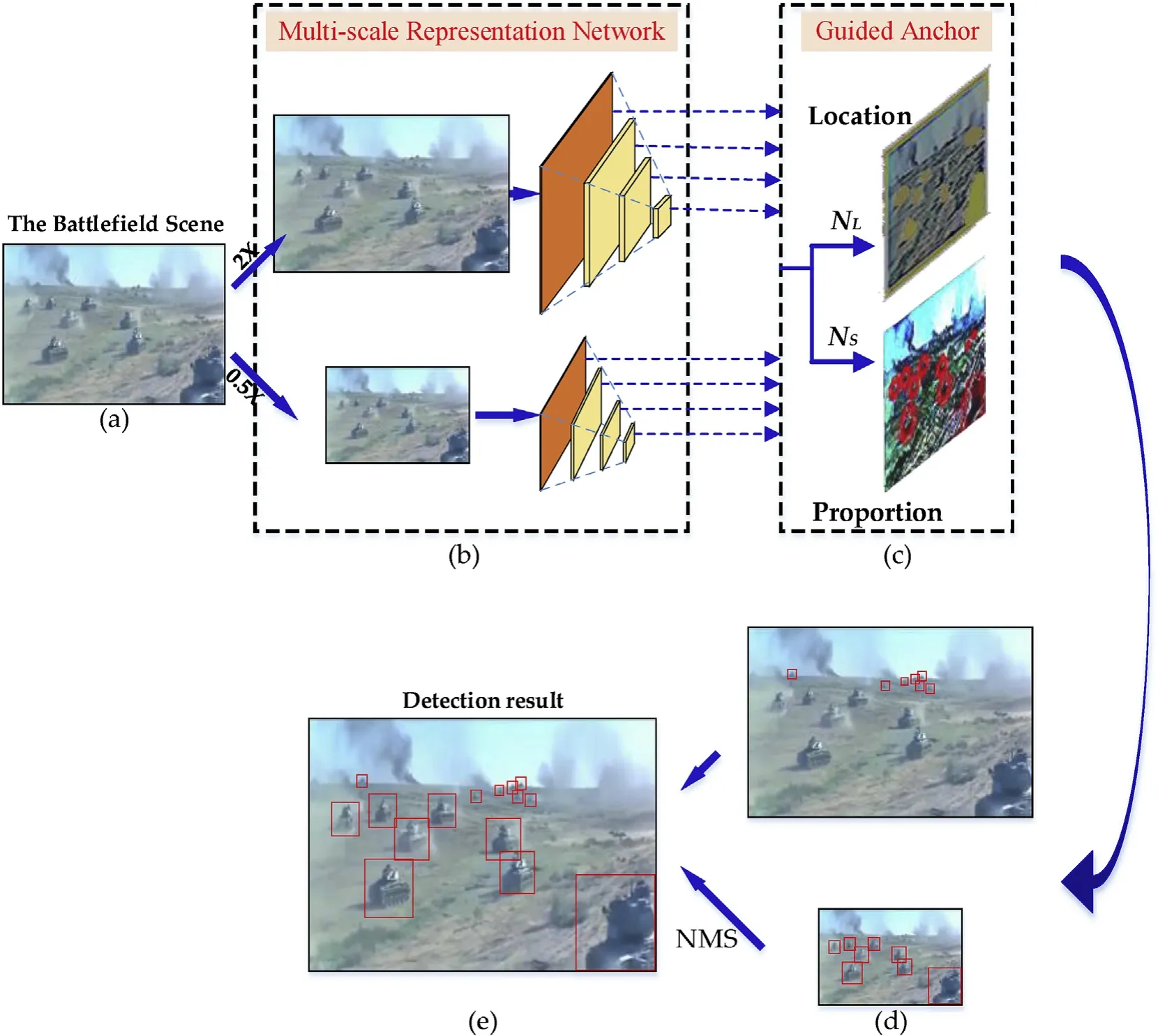
Fig. 3. Overview of our method. (a) Input battlefield scene image; (b) Multi-scale Representation Network; (c) Guided Anchor scheme; (d) Per-resolution detection; (e) Final detection result.
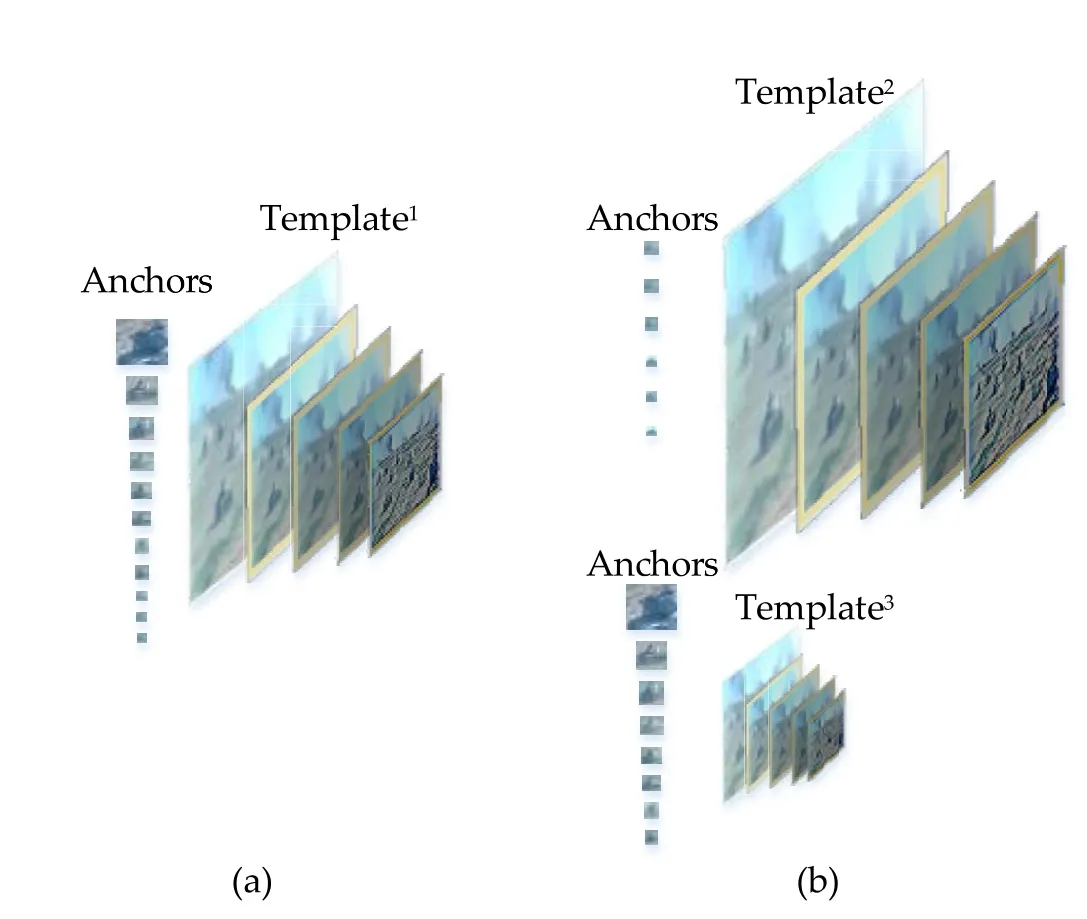
Fig.4. Templates and anchors.(a)Scale-normalized template and anchors in methods like faster R-CNN and YOLO; (b) Multi-scale representation network templates and anchors in our method.
After determining the possible location for armored targets,the next step is to decide the shape of anchors at each location in our improved Guided Anchor.An appropriate anchor should contain an armored target as complete as possible, while contain few backgrounds. In Wang, J. et al. [33], 9 pairs of anchor width (w) and height (h) are sampled to estimate one anchor shape. Different from other objects, armored targets have regular shapes. By integrating the shape prior information into the design of anchors,the detection efficiency can be increased.Fig.6(a)shows the shapes statistics of armored targets in our Armored Target Dataset(ARTD).The x-coordinate represents the sizes of ground truth bounding box and the y-coordinate represents ratio of height to width. The red line in the figure represents the trend line of the ratio. In ARTD,armored target scales range from 10×10 pixels to more than 700×700 pixels, with a wide range of target scales. It is obviously a computation inefficient way to use a large number of fixed anchors to cover our armored target scales. However, the ratio of height to width has a regular:the ratio is distributed along the contour line of 0.5, with the interval of 0.25-2.5. The regular corresponds to the actual size of the armored target.
According to the regular shapes of ground-truth bounding box,we design the following anchor shape:
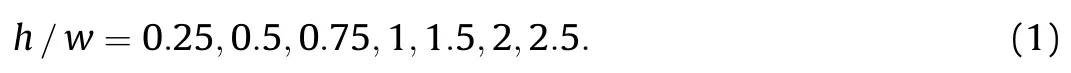
Such anchor shapes enhance the ability of detecting targets whose ratio of height to width is about 0.5.As shown in Fig.5,we use an anchor size prediction branch NSto yields single-channel map P(shape), which contains the response values of dk. In order to get stable predicting,an element-wise layer is adopted to transform the response values of dk to the area response of anchors. The transformation as follows:
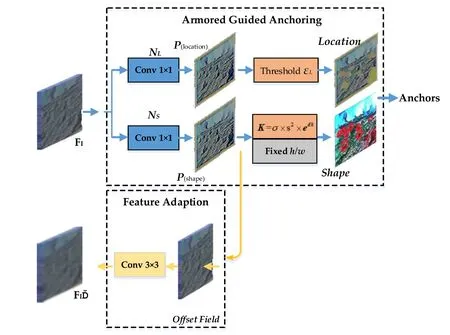
Fig. 5. Improved guided anchor generation module for armored targets.
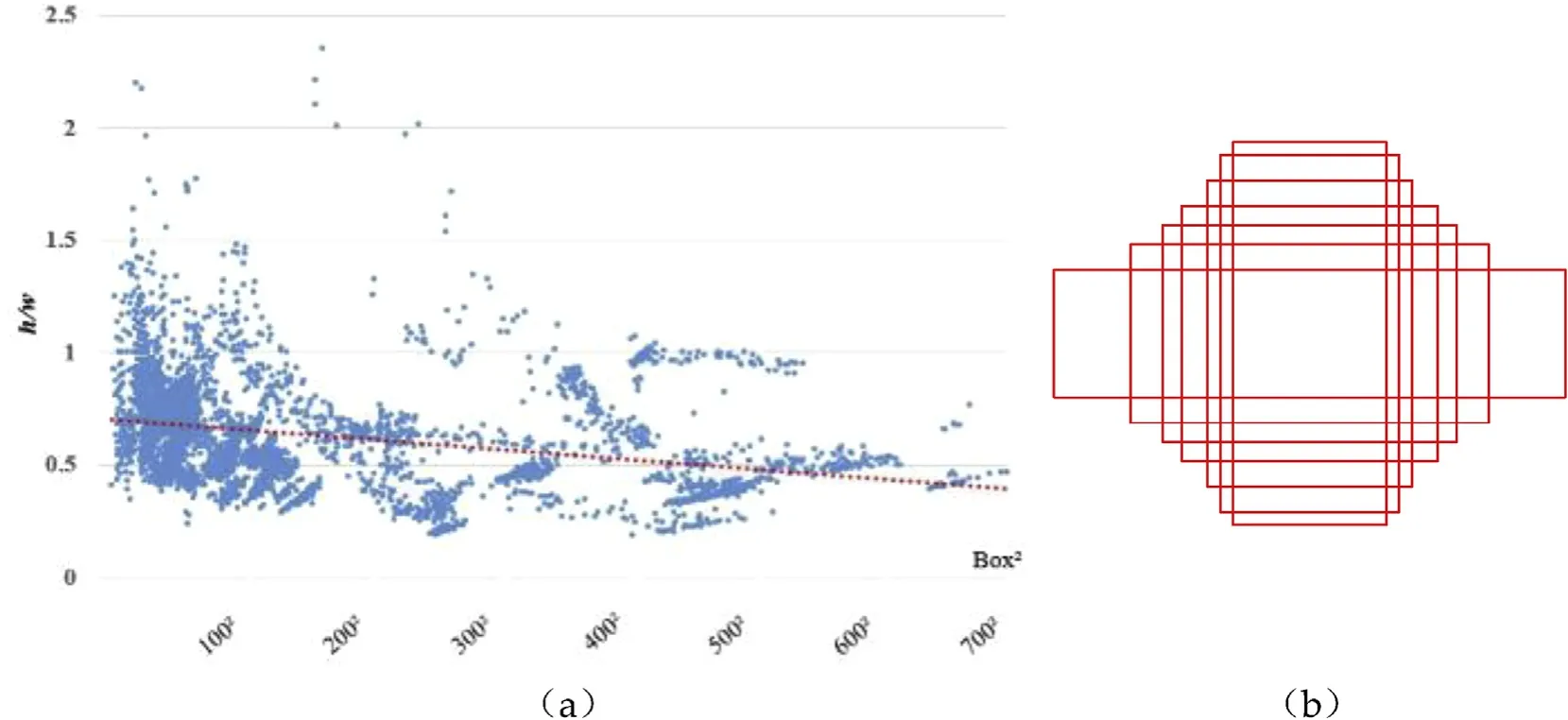
Fig. 6. (a): The shapes statistics of armored targets in our Armored Target Dataset (ARTD); (b): Samples of shape-fixed anchors.

where σ is an empirical scale factor (σ=64 in our experiments)and s is the stride. This nonlinear transformation projects the output space from approximate[0, 10002]to[1, 1],which is more stable. Samples of shape-fixed anchors are shown in Fig. 6(b). We use a 1×1 convolution on the feature map FIto obtain P(location).The shapes of 7 anchors are determined by the area K and the ratio of height to width h/w.Finally,we calculate the IoU for anchor a={(x0,y0,w,h)|w >0,h >0} around the center of the response map and the ground truth bounding boxand use the anchor that produces the maximum value as the prediction.The IoU between a variable anchor and ground truth bounding box is defined as follows:
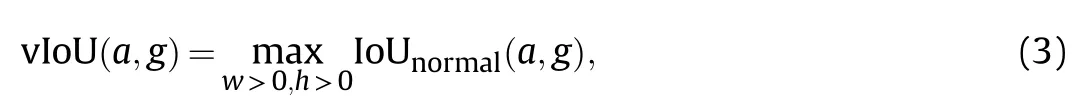
where IoUnormalis the typical definition of IoU.The same as[33],a Feature Adaptation module is used to transform the feature at each individual location based on the underlying anchor shape.
3.4. Context for armored targets

Fig. 7. Examples of armored targets with contextual information.
Context is formulated as image evidence beyond the object extent [34]. Human ability to find small objects is linked to the brain’s inferencing between targets and backgrounds. Inspired by this, contextual information is found to be contributed to small target detection.Fig.7 shows some examples of armored targets in battlefield. In addition to the features of armored target itself,contextual information around armored target may contribute to determine whether it is an armored target or not. Such context includes armored cluster the target belonging to, other armored targets around the target,muzzle fire and smoke of armored targets when firing,and dust brought by armored targets when moving.All of this environment provides extra information to determine that the detected object is indeed an armored target, especially when the object is small.
Distant armored targets in Fig. 1 tend to be less than 32× 32 pixels.The reason why traditional detection methods are difficult to detect these small armored targets is that there are little features included in the objects to exploit. Moreover, when the size of armored target is less than 16 × 16, the spatial resolution of its feature maps may be less than 1×1 after enduring multiple down sampling process, which means that the feature maps are useless for detection and recognition [21]. To address the problem, we focus on leveraging the contextual information to improve the detection of small armored targets.At the same time,large armored targets are easier to be detected with sufficient features,which has been proved in traditional methods.Hence,in order to balance the efficiency and performance on detection, we incorporate contextual information only to small armored target detection,by adding contextual box to B-class anchors. Fig. 8 shows our different strategies for armored targets at different scales.
4. Experiment
4.1. Dataset and implementation for armored target detection
At present, public object detection datasets for general targets and vehicle targets have been published,such VOC[35]and KITTY[36]. However, such datasets do not contain particular armored targets or complex battlefield scene and cannot be used in armored target detection.In this work,we built a dataset dedicated to armor targets,named Armored Target Dataset(ARTD).The ARTD includes 11536 battlefield scene images actual shot, captured by video and game or downloaded from the internet.The ARTD includes various battlefield scenes (such as jungle, desert, grassland and city) and complicated factors (such as armored cluster, muzzle fire and smoke, dust and so on). Each image is normalized to a size of 1024×768 pixels.Armored target scales in ARTD have wide range from 10×10 pixels to more than 700×700 pixels and large number of 30132, with an emphasis on remote small armored targets. The graphical image annotation tool LabelImg [37] is used to annotate battlefield scene images in PASCALVOC format[35].We randomly select 8000 images with 20896 armored targets as the training set and the rest 3536 images with 9236 armored targets are used as testing set.
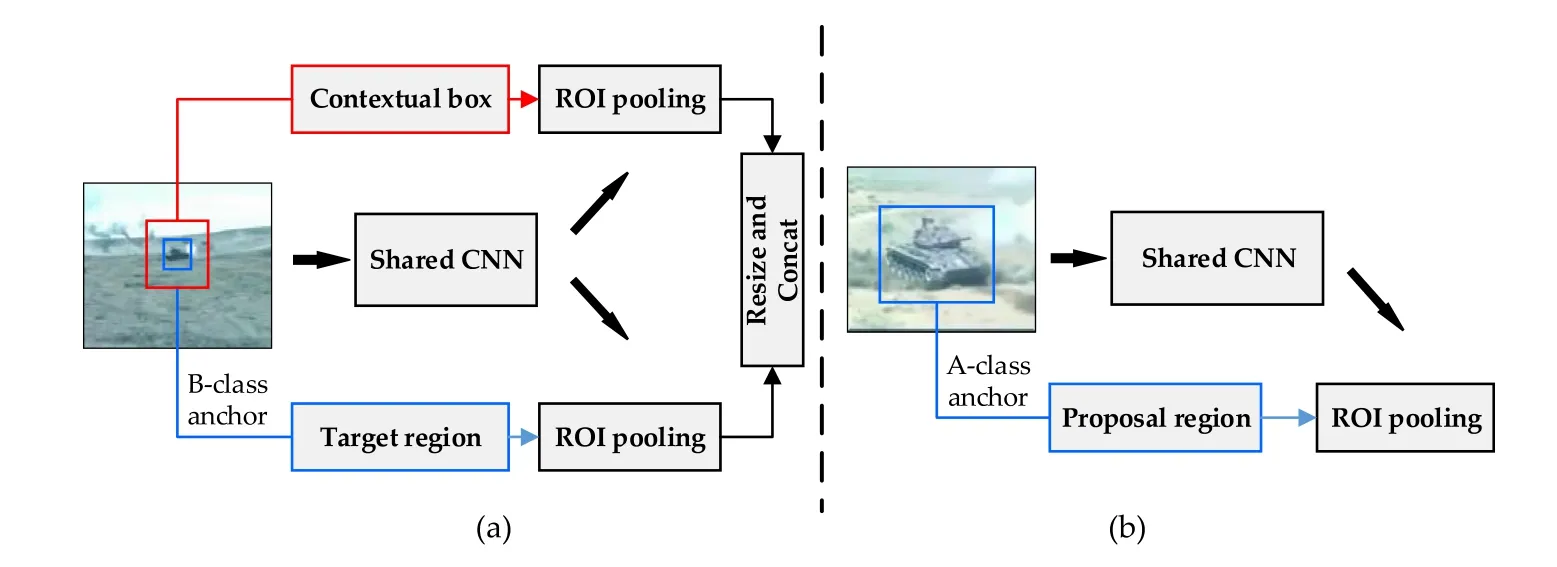
Fig.8. Different strategies for armored targets at different scales.(a)Add contextual boxes to armored targets less than 64px tall;(b)No contextual boxes added to armored targets larger than 64px tall.
In this work, pre-trained Resnet50 model [38] are used as the backbone network. We take the original image size 1024× 768 as input size, without changing the aspect ratio. In design of guided anchors,we set σ = 64. In the multi-task loss function,we simply use λ1 =1; λ2 = 0:1 to balance the location and shape prediction branches. The whole network is trained with Adam, with a momentum of 0.9 and a weight decay of 0.0005,using a single NVIDIA GeForce GTX 2080ti GPU with 11 GB of memory.
4.2. Evaluation metrics
In the experiments using our method,we employ the recall,and detection time to quantitatively evaluate the armored target detection method in this work. Recall means the number of samples that are labeled as positive that are actually predicted by the detector, and is formulated as:

where tp refers to a true positive and fn refers to a false negative.The relationship between tp and fn is shown in Table 1.
4.3. The effect of multi-scale armored representation
Much detection methods use a scale-normalized template and detectors to find objects. However, the size of template often determines the detection result.On the one hand,the high-resolution template can magnify local features of smaller objects,while on the other hand,the low-resolution template can improve the efficiency of armored targets detection.In this work,we propose multi-scale representation network to fit both small and large armored targets.Firstly, a coarse image pyramid is created including a 2× interpolation image and a 0.5× interpolation image. Then, we detect armored targets larger than 64px tall on 0.5×interpolation image,while detect armored targets less than 64px tall on 2× interpolation image.In order to demonstrate the effectiveness of the Multiscale Representation Network (MS-RN), we conducted an experiment where we used anchors with the same ratio as interpolation(e.g. 2-fold interpolation images correspond to 2-fold anchors) in detection. Two scale-normalized templates including a full-size scale-normalized template (S-NT1) and 2-fold scale-normalized template (S-NT2) were used as baseline. To evaluate the methods on different size of target,we divided the ARTD into three different subsets according to the armored target size:small armored targets(size <32×32 pixels),medium armored targets(32×32 pixels <size <96×96 pixels) and large armored targets (size > 96× 96 pixels). The detection results of the models were compared on three subsets.
Table 2 shows the detection recall rate of different models combined and not combined with guided anchors on three subsets.Compared with full-size scale-normalized template (S-NT1), our M-SRN significantly improves the recall rates on small armored targets and medium armored targets. This is because the 2×interpolation image makes up for the deficiency of small armored target features. Interestingly, the recall rate of our MS-RN alsoimproved for large armored target.This result indicates that further magnification of large armored target may blur its local features and make it difficult to distinguish,which are also illustrated by the comparison between S-NT1 and S-NT2. Compared with 2-fold scale-normalized template (S-NT2), our MS-RN perform better on large armored target. Moreover, our M-SRN is more computation efficient than running all the anchors on 2×interpolation image in S-NT2. The reason is that we detect large armored targets on lowresolution images. In conclusion, our Multi-scale Representation Network(MS-RN) is better than scale-normalized methods.

Table 1 The relationship between true positive (tp), false negative (fn), false positive (fp),and true negative (tn).

Table 2 Detection recall rate of different models on ARTD dataset across three subsets.
4.4. The effect of context
In order to further verify the effectiveness of context fusion for armored target detection in our method, we conducted an experiment including a variety of context fusion strategies. In Fig. 9, an analysis of the effect of context is given by the size of the receptive field. It is obviously that adding context to small armored targets can significantly improve recall rate,as shown in the first line of the picture. The reason is that convolutional features at higher layers tend to have larger receptive fields, which means more contextual information around armored target.For small armored targets,the best result is achieved in the scheme Res4+Res3+Res2. The recall rate decreases after adding Res5. We verified that this was due to over-fitting. However, the benefit of context is not obviously for large armored target when it is completely cropped. As shown in the second line of the picture, the recall rate is low when the receptive fields can only cover parts of the larger armored target.Because the entire armored target is invisible with a small receptive field.When the large armored target is fully covered,its recall rate is very high.This proves that large armored targets are easier to be detected with sufficient features. Hence, the strategy of incorporating contextual information only to small armored target detection is reasonable. The scheme Res4+Res3+Res2 is adopted in our work.
4.5. The effect of shape-fixed guided anchor
Region anchors are the cornerstone of modern object detection techniques. In order to ensure a sufficiently high recall for proposals,a large number of anchors are used in traditional detectors.Obviously,this scheme is extremely waste-computed because most of anchors are placed in areas that are irrelevant to the object of interests.In this work,we use a shape-fixed Guided Anchor(SF-GA)as alternative scheme. We evaluate the anchors by comparing the average recall (AR) and number of anchors of SF-GA with the RPN baseline and previous state-of-the-art region proposal methods.Following [39], the RPN baseline uses 1 scale and 3 aspect ratios.Following [33], “RPN+9 anchors” denotes using 3 scales and 3 aspect ratios in each feature level. In order to control variables, no context is added in anchors and the templates are scalenormalized. Table 3 shows the average recall rate of different methods on ARTD dataset across three subsets. Compared with other methods, the shape-fixed Guided Anchors achieve a much higher recall rate on small and medium armored targets. Specifically, it improves AR (small) by 5.6% and AR (medium) 7.0% than RPN baseline respectively. The encouraging results shows that SFGA has better recommendation ability for small and medium armored targets.
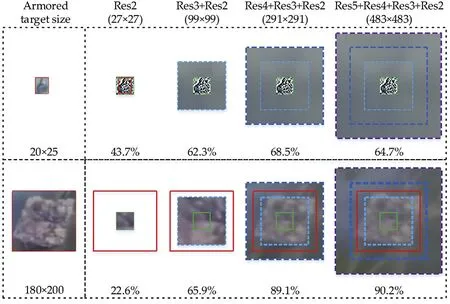
Fig. 9. Analysis of the effect of context. ResN represents receptive fields associated with features from Nth layer in ResNet. E.g. Light green dotted boxes Res2 represent receptive fields associated with features from 2nd layer. Accordingly, the light blue = Res3, dark blue = Res4, purple = Res5. The red box represents the actual armored targets.
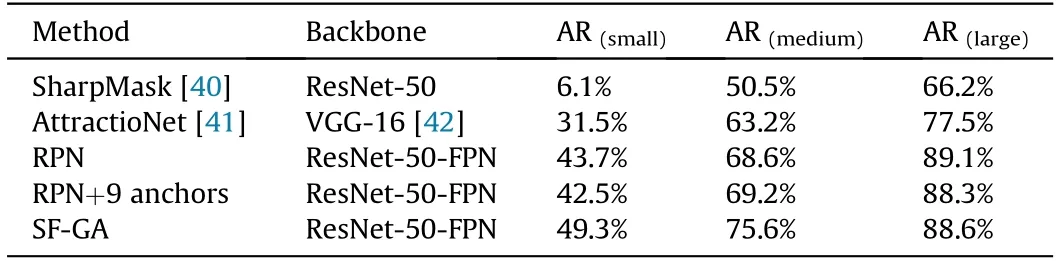
Table 3 Average recall rate of different methods on ARTD dataset across three subsets.
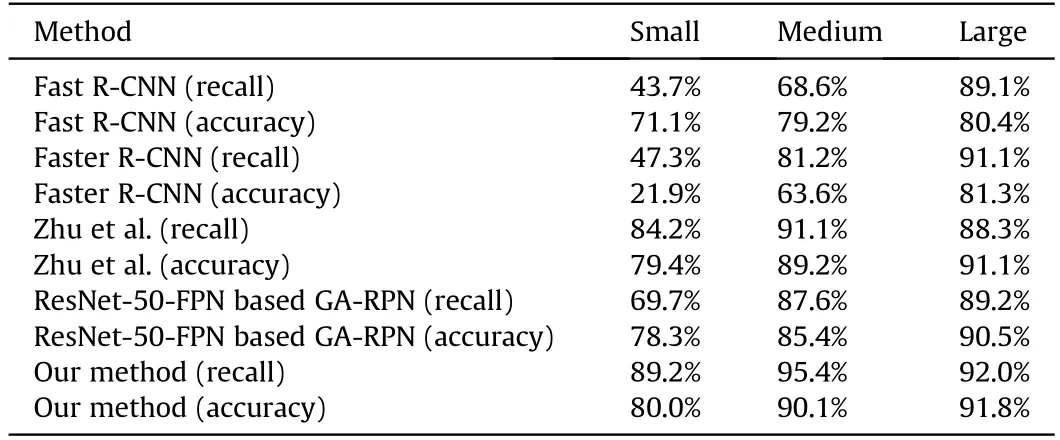
Table 4 Comparison of the performance of our armored target detection method used in this work with other state-of-the-art models.
Fig.10 shows examples of the actual anchor centers in RPN and SF-GA. Images in Fig.10(a) shows the anchor centers in RPN with sliding windows. Images in Fig. 10(b) shows the anchor centers with probability maps.Compared with the RPN baseline,our SF-GA can filter out more than 80% of the regions while still maintaining the same recall. As illustrated, regions like sky and dessert are excluded and anchors concentrate densely around the armored targets.More importantly,the reduction of the number of anchors means that redundant features are reduced in Pooling [45] and Regression [46], which greatly improves the overall accuracy and efficiency of the network.
4.6. Overall performance of our method
In this work,we proposed a fast detection method for armored target in ground battlefield, including a novel multi-scale representation network and a shape-fixed Guided Anchor scheme. In order to prove the superiority of our method,we take the ResNet-50-FPN [39] based GA-RPN [33] as our baseline. We evaluate the performance by comparing the average recall(AR)and accuracy of our method with the baseline and previous state-of-the-art region proposal methods on ARTD dataset across three subsets.The results of this comparison are shown in Table 4.It can be observed that the Fast R-CNN and Faster R-CNN perform well for large armored targets, however their average recall and accuracy for small and medium-sized traffic signs are much lower.Our fast-armored target detection method outperforms the ResNet-50-FPN based GA-RPN by a large margin. Specifically, it improves small armored target recall by 19.5% and medium armored target by 7.8%. The encouraging results attribute to that the high-resolution template magnifies local features of smaller objects. Our method also has improvement on large armored target. This proves that appropriately reducing the scale will help improve the detection for oversized targets. Compared with the model of Zhu et al. [43], our method performs well in terms of average recall; the model returned values of 89.2% (vs. 84.2% for the model of Zhu et al.),95.4% (vs. 91.1%), and 92.0% (vs. 88.3%) for small, medium-sized,and large armored targets, respectively. That is, our method makes a large improvement in average recall over the model of Zhu et al.i.e.,of 5%and 3%for small and medium-sized armored targets,respectively. The experiment results verify the superiority of our method in small and medium-sized armored targets detection.
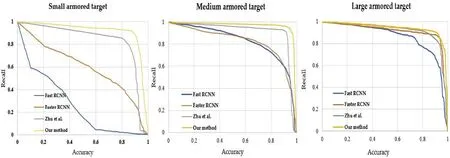
Fig.11. Comparisons of the overall detection performances of various models for small, medium-sized, and large armored targets using the ARTD dataset.

Fig.12. Qualitative examples of test images on the ARTD dataset.
Comparisons of accuracy-recall curves for different models and different sizes of traffic sign are provided in Fig.11.
Fig.12 shows qualitative examples of test images on the ARTD dataset with the proposed method. The detection of armored targets in the examples face complicated background and large-scale variation. It can be observed that the proposed method has successfully detected most of the armored targets in ARTD dataset,despite the large observation distance.
5. Conclusions
Detection of armored targets ground battlefield faces the problem of complicated background, smaller target size and high accuracy requirement. Moreover, there is no ready-made sample images with labels for armored targets.In this work,we proposed a fast-armored target detection method and a special detection dataset for armored target,named Armored Target Dataset(ARTD).Aiming the controversy of template, we use multi-scale representation network(MS-RN)to fit both small and large armored targets.Different super class of anchors are operated on different templates respectively. Compared with scale-normalized template, the MSRN significantly improves the recall rates on small armored targets and medium armored targets. The scheme in traditional methods is extremely waste-computed because most of anchors are placed in areas that are irrelevant to the object of interests.We took an alternative shape-fixed Guided Anchor(SF-GA)module for armored targets. The module uses two branches to yield location prediction and the area of armored targets. Meanwhile, the shape prior information is integrated into the design of anchors.Compared with the RPN baseline, our SF-GA can filter out more than 80% of the regions while still maintaining the same recall.Considering the brain’s inferencing between targets and backgrounds, we focused on leveraging the contextual information to improve the detection of small armored targets. Several experiments were conducted on ARTD, and the results verify the superiority of our method in small and medium-sized armored targets detection. In the future, we will test this method in other object detections and consider strengthening the detection by merging visible and infrared images.
Funding
This work was supported by the National Key Research and Development Program of China under grant 2016YFC0802904,National Natural Science Foundation of China under grant 61671470,and the Postdoctoral Science Foundation Funded Project of China under grant 2017M623423.
杂志排行

Defence Technology的其它文章
- Analysis of sliding electric contact characteristics in augmented railgun based on the combination of contact resistance and sliding friction coefficient
- Aerodynamics analysis of a hypersonic electromagnetic gun launched projectile
- Synergistic effect of hybrid Himalayan Nettle/Bauhinia-vahlii fibers on physico-mechanical and sliding wear properties of epoxy composites
- Study on dynamic response of multi-degree-of-freedom explosion vessel system under impact load
- An investigation on anti-impact and penetration performance of basalt fiber composites with different weave and lay-up modes
- Modeling and simulation of muzzle flow field of railgun with metal vapor and arc