犹豫模糊熵生成算法及在后勤补给基地选址评估中的应用
2020-07-01袁修久赵学军郑明发
黄 林, 袁修久, 赵学军, 郑明发
(空军工程大学基础部, 西安, 710051)
为了描述事物“亦此亦彼”的模糊性,Zadeh在1965年提出了模糊集的概念[1]。Torra[2]和Narukawa[3]把模糊集推广成了犹豫模糊集,Cheng等[4]又将犹豫模糊集推广为区间值犹豫模糊集,并将其应用于决策分析。
犹豫模糊信息测度包括距离、相似度和熵等,已被广泛应用于各个领域,例如模式识别[5]、医疗诊断、聚类分析[6]、多属性决策[7]以及图像处理等。
一方面,许多研究者提出了不同的距离、相似度和熵的度量方法[8-12]。另一方面,许多学者研究了用一种犹豫模糊信息测度来构造另一种信息测度的方法。Farhadinia[13]研究了犹豫模糊熵与距离之间的关系,提出了基于距离来构造犹豫模糊集熵公式的方法[9,13-14]。此外,许多学者研究了扩展的犹豫模糊集的信息测度。如犹豫模糊语言值集的距离[15],对偶犹豫模糊集的熵[16]和区间值犹豫模糊集的相似度等[17-18]。
现有文献给出了多种犹豫模糊元和区间值犹豫模糊元的熵和相似度的具体表达式,但是应用背景不同对相关公式要求也不同,构造新的犹豫模糊熵和相似度公式常常比较困难。因此,提出犹豫模糊集的熵和相似度的生成算法是值得研究的问题。
本文推广定义了犹豫模糊集和区间值犹豫模糊集的熵和相似度,提出了犹豫模糊集和区间值犹豫模糊集的熵和相似度的一般公式,给出了犹豫模糊集和区间值犹豫模糊集的熵和相似度的生成算法,研究了犹豫模糊集的相似度与熵之间的关系,并给出了构造犹豫模糊集和区间值犹豫模糊集的具体熵的一般方法。
1 犹豫模糊集的概念
定义1.1设X为给定的论域,称A={
若∀x∈X,hA(x)={0},则A为空集∅;若∀x∈X,hA(x)={1},则A为全集X。
论域X上的全体犹豫模糊集构成的集合,记为HF(X)。
定义1.2[14]设X为给定的论域,D[0,1]表示区间[0,1]的所有闭子区间构成的集合。称A={

论域X上的全体区间值犹豫模糊集构成的集合,记为IVHF(X)。
为了方便计算区间值犹豫模糊元的熵和相似度,参照文献[8],本文作以下假设:
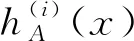
2)两个区间值犹豫模糊元hA(x)和hB(x),若l(hA(x))≠l(hB(x)),记lx=max{l(hA(x)),l(hB(x))},其中l(hA(x))表示区间值犹豫模糊元hA(x)中元素的个数。对于元素较少的区间值犹豫模糊元,重复添加最大的元素直到它的元素个数为lx。
定义1.3设X为论域,设A,B∈IVHF(X),且∀x∈X,l(hA(x))=l(hB(x))=lx,则A包含于B和A与B相等分别定义为:

犹豫模糊集是区间值犹豫模糊集的特例。因此,假设1)与假设2)及定义1.3同样适用于犹豫模糊集。
2 犹豫模糊集的熵和相似度的一般公式
2.1 犹豫模糊集的熵的公理化定义
定义2.1[10]设A为论域X上的犹豫模糊集,hA(x)为A的犹豫模糊元,映射E:HF(X)→[0,1],AE(A),称E(A)是犹豫模糊集A的熵,若E(A)满足:
1)E(A)=0,当且仅当A=∅或A=X;
2)E(A)=1,当且仅当∀x∈X,有:
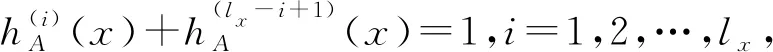
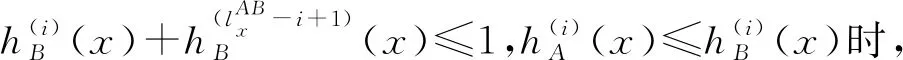
4)E(A)=E(Ac)。
根据给出的犹豫模糊集熵的公理化定义,提出犹豫模糊集的熵的一般公式。
2.2 犹豫模糊集的熵的一般公式
定理2.1设A为论域X={x1,x2,…,xn}上的犹豫模糊集,hA(xj)为A的相应于X的元素xj的犹豫模糊元,映射E:HF(X)→[0,1],A
式中:cj为正实数,fi:[0,1]→[0,+∞)满足:
①∀x∈[0,1],fi(x)=fi(1-x);②fi(0)=0;③fi(x)在[0,1]上严格递增。
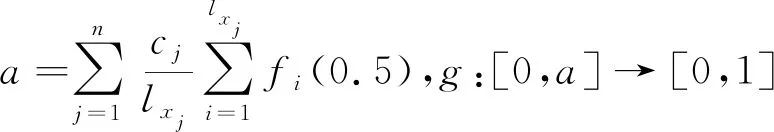
证明
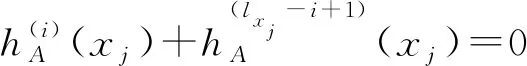
反之,当E(A)=0时,由于g在[0,a]上严格递增,且g(0)=0,有:

反之,当E(A)=1时,由于g在[0,a]上严格递增,且g(a)=1,有:
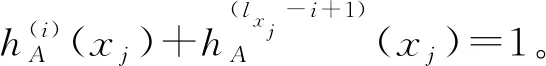
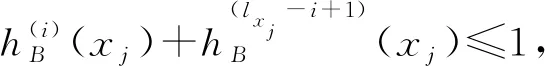
由于fi在[0,0.5]上严格递增,可知:
由于g:[0,a]→[0,1]严格递增,则E(A)≤E(B)。
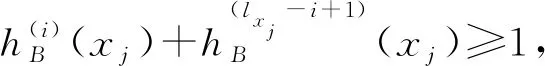
4)
E(Ac)=
可证得E(Ac)=E(A)。证毕。
采用定理2.1可构造出具体的犹豫模糊集的熵公式:
定理2.2设A为论域X={x1,x2,…,xn}上的犹豫模糊集,hA(xj)为A的相应于X的元素xj的犹豫模糊元,映射E:HF(X)→[0,1],
AE(A)=
式中:cj为正实数。fi:[0,1]→[0,+∞)满足:①∀x∈[0,1],fi(x)=fi(1-x);②fi(0)=0;③fi(x)在[0,0.5]上严格递增。
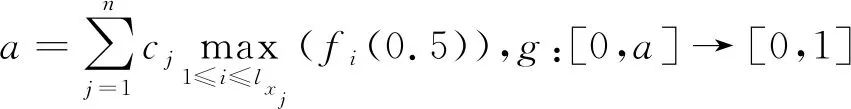
定理2.2的证明过程与定理2.1的证明过程类似。选取不同的函数g与fi,能够构造出多种现有文献没有的具体的犹豫模糊集熵公式。
综上,依据定理2.1、定理2.2可以给出犹豫模糊集的熵的生成算法。
下面给出基于定理2.1的犹豫模糊集熵的生成算法步骤:
1)选取具体的函数fi(x)和g(x);
2)验证fi(x)和g(x)是否满足定理2.1的条件;
3)由定理2.1提出的犹豫模糊集的熵的一般公式,生成具体的犹豫模糊集熵公式。
2.3 犹豫模糊集的相似度的一般公式
2.3.1 犹豫模糊集相似度的公理化定义
定义2.2[10]设A和B为论域X上的2个犹豫模糊集,称S(A,B)为犹豫模糊集A,B的相似度,若S(A,B)满足:
1)S(A,B)=0,当且仅当A=∅,B=X或A=X,B=∅;
2)S(A,B)=1,当且仅当A=B;
3)若A⊆B⊆C,或者A⊇B⊇C,有S(A,C)≤S(A,B),S(A,C)≤S(B,C);
4)S(A,B)=S(B,A)。
2.3.2 犹豫模糊集的相似度的一般公式
定理2.3设A和B为论域X={x1,x2,…,xn}上的2个犹豫模糊集,其中hA(xj),hB(xj)分别为A和B的相应于X的元素xj的犹豫模糊元,设:
式中:cj为正实数。fi:[-1,1]→[0,1]满足:①∀x∈[-1,1],fi(x)=fi(-x);②fi(0)=0,fi(1)=1;③fi(x)在[0,1]上严格递增。
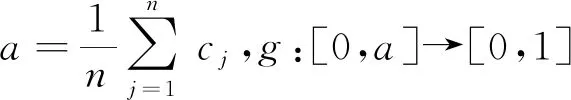
证明
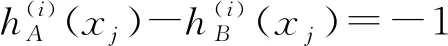
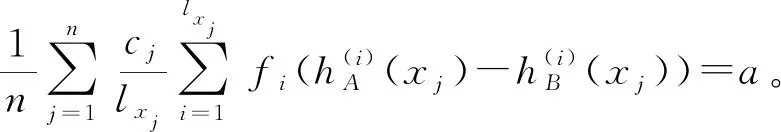
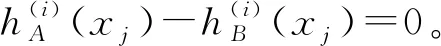
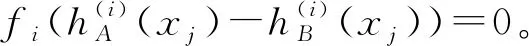
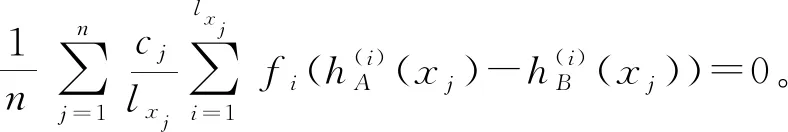

由于fi(x)在[0,1]上严格递增,fi(-x)=fi(x),以及g:[0,a]→[0,1]严格递增,可证得:
S(A,C)≤S(A,B),S(A,C)≤S(B,C)。

可得S(A,B)=S(B,A)。证毕。
选取不同的函数fi和g,可以构造出具体的犹豫模糊集相似度公式。
定理2.4设A和B为论域X={x1,x2,…,xn}上的2个犹豫模糊集,其中hA(xj),hB(xj)分别为A和B的相应于X的元素xj的犹豫模糊元,设
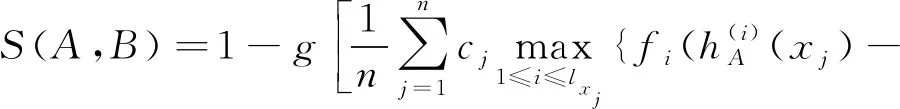
式中:cj为正实数。fi:[-1,1]→[0,1]满足:①∀x∈[-1,1],fi(x)=fi(-x);②fi(0)=0,fi(1)=1;③fi(x)在[0,1]上严格递增。
定理2.4的证明过程与定理2.3的证明过程类似。函数g与fi选取不同的函数,可以构造出具体的犹豫模糊集的相似度公式。如:

式中:cj为正实数。fi:[-1,1]→[0,1]满足:①∀x∈[-1,1],fi(x)=fi(-x);②fi(0)=0,fi(1)=1;③fi(x)在[0,1]上严格递增。
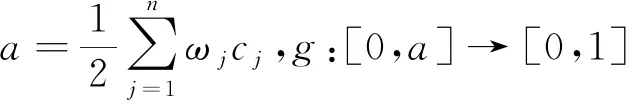
定理2.5的证明过程与定理2.3类似。选取具体函数g和fi,可以生成具体的犹豫模糊集的混合加权相似度公式。如:
此外,在定理2.3和定理2.4中考虑各犹豫模糊元的权重时,可生成犹豫模糊集的加权相似度公式。
综上,依据定理2.3、定理2.4及定理2.5可以给出犹豫模糊集的相似度的生成算法。
下面给出基于定理2.3的犹豫模糊集相似度的生成算法步骤:
1)选取具体的函数fi(x)和g(x);
2)验证fi(x)和g(x)是否满足定理2.3的条件;
3)由定理2.3提出的犹豫模糊集的相似度的一般公式,生成具体的犹豫模糊集相似度公式。
2.4 犹豫模糊集的相似度与熵的关系
定理2.6[10]设X为论域,A为犹豫模糊集,则E(A)=S(A,Ac)为犹豫模糊集A的熵。
由定理2.3和定理2.6不难得到定理2.7。
定理2.7设A为论域X={x1,x2,…,xn}上的犹豫模糊集,hA(xj)为A的相应于X的元素xj的犹豫模糊元,映射E:HF(X)→[0,1],
A
式中:cj为正实数。fi:[-1,1]→[0,1]满足:①∀x∈[-1,1],fi(x)=fi(-x);②fi(0)=0,fi(1)=1;③fi(x)在[0,1]上严格递增。
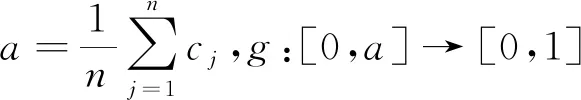
E8(A)=1-
E9(A)=1-
3 区间值犹豫模糊集熵和相似度的一般公式
3.1 区间值犹豫模糊集的熵的一般公式
定理3.1设A为论域X={x1,x2,…,xn}上的区间值犹豫模糊集,hA(xj)为A的相应于X的元素xj的区间值犹豫模糊元,映射E:IVHF(X)→[0,1],
AE(A)=
式中:cj为正实数。fi:[0,1]→[0,+∞)满足:①∀x∈[0,1],fi(x)=fi(1-x);②fi(0)=0;③fi(x)在[0,0.5]上严格递增。
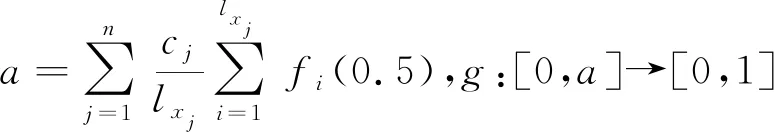
定理3.1的证明过程与定理2.1的证明过程类似。类似于犹豫模糊集,通过熵的生成算法可以生成具体的区间值犹豫模糊熵公式。如:
3.2 区间值犹豫模糊集的相似度的一般公式
定理3.2设A和B为论域X={x1,x2,…,xn}上的2个区间值犹豫模糊集,其中hA(xj),hB(xj)分别为A和B的相应于X的元素xj的区间值犹豫模糊元,设:
式中:cj为正实数。fi:[-1,1]×[-1,1]→[0,+∞)满足:①∀x∈[-1,1],y∈[-1,1],有fi(-x,-y)=fi(x,y),fi(y,x)=fi(x,y);②fi(0,0)=0;③fi(x,y)分别关于x,y在[0,1]上严格递增。

定理3.2的证明过程与定理2.3的证明过程类似。类似于犹豫模糊集,通过相似度生成算法可生成具体的区间值犹豫模糊集相似度公式。如:
3.3 区间值犹豫模糊集的相似度与熵的关系
定理3.3[14]设X为论域,A为区间值犹豫模糊集,则E(A)=S(A,Ac)为区间值犹豫模糊集A的熵。
由定理3.2和定理3.3不难得到定理3.4。
定理3.4设A为论域X={x1,x2,…,xn}上的区间值犹豫模糊集,hA(xj)为A的相应于X的元素xj的区间值犹豫模糊元,设
式中:cj为正实数。fi:[-1,1]×[-1,1]→[0,+∞)满足:①∀x∈[-1,1],y∈[-1,1],有fi(-x,-y)=fi(x,y),fi(y,x)=fi(x,y);②fi(0,0)=0;③fi(x,y)分别关于x,y在[0,1]上严格递增。
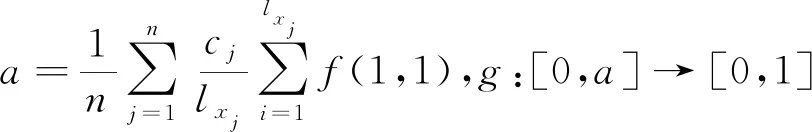
4 后勤补给基地的选址评估分析
某联勤保障中心计划新建一个后勤补给基地,现有4个候选地址Ai(i=1,2,3,4)可供选择,为了评估这些候选地址,选取4个主要评价指标:地理因素C1,作战因素C2,交通因素C3,成本因素C4[19-20]。为了便于专家准确全面的评价,其中每个因素又可通过一些详细的指标来衡量[21]。构建补给基地选址的评价指标体系见图1。
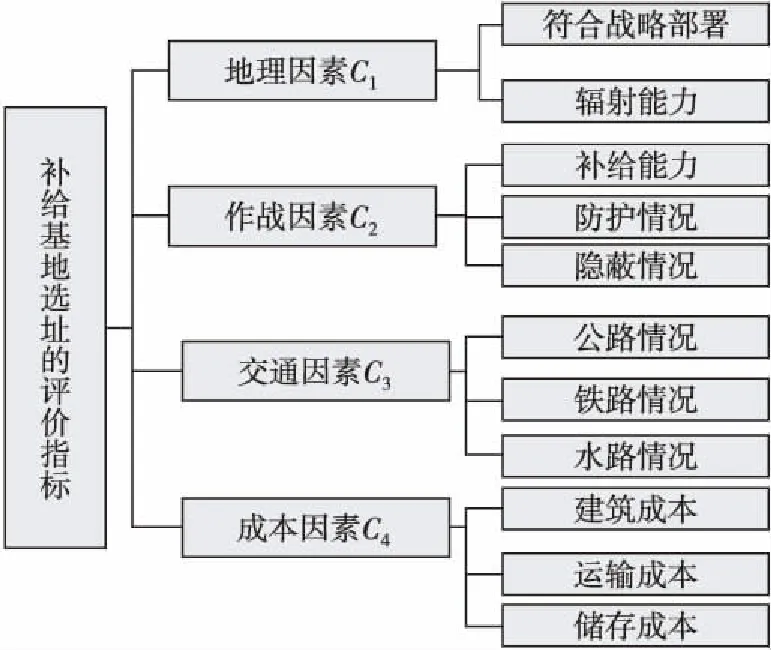
图1 补给基地选址的评价指标体系
联勤保障中心邀请了相关领域的具有丰富专业背景、经验以及知识水平的专家对候选地址进行评估。为了全面准确的评价,采用犹豫模糊集来反映专家的评估信息。决策信息见表1。

表1 犹豫模糊决策信息
参照文献[12],采用犹豫模糊集的多属性决策模型处理后勤补给基地的选址评估问题。
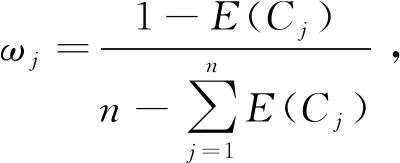
其次,考虑到评选对象的属性C1,C2,C3为利益型,属性C4为成本型,算得正理想解和负理想解分别为A+=(0.7,0.9,0.9,0.2),A-=(0.2,0.1,0.2,0.8)。

各个方案Ai(i=1,2,3,4)的贴近度排序结果为A2≻A4≻A3≻A1。可知A2为最优的补给基地的选址。
犹豫模糊集熵公式E4中的参数p取不同的值时,计算各方案与理想解间的贴近度,结果见图2。

图2 不同的p值对应的各方案的贴近度
从图2可以看出,犹豫模糊熵公式E4中的参数p取不同的值,方案A2总是最优的方案。
当熵公式发生改变后,各属性的权重可能会发生改变,为了确定决策结果是否具有一定的可靠性,下面将选取不同类型的犹豫模糊熵,对得到的决策结果进行对比分析。
选取不同类型的犹豫模糊集的熵公式E2,E3,E4,E5,E7,E9和相似度公式S8计算各方案与理想解间的贴近度,结果如图3所示。从图3可以看出,尽管我们采用不同类型的熵公式,方案A2总是最优的方案。
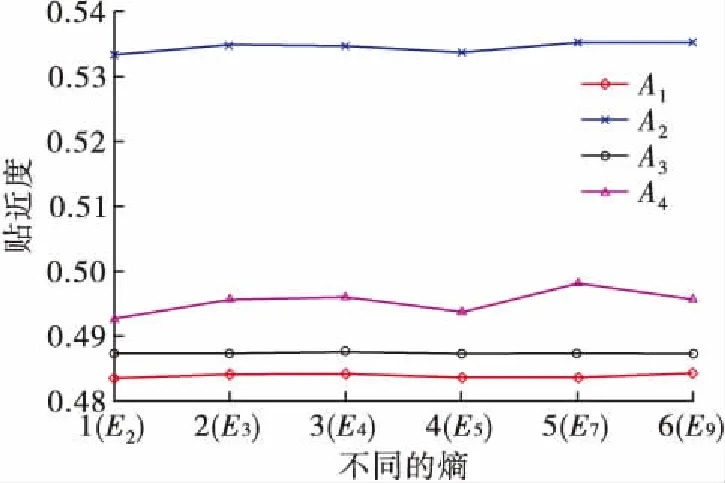
图3 选S8时不同的熵对应的各方案的贴近度
决策者根据自身偏好采用不同的相似度公式时,利用决策模型得到的决策结果也有可能会发生变化。选取犹豫模糊集的相似度公式S10和熵公式E2,E3,E4,E5,E7,E9计算各方案与理想解间的贴近度,结果如图4所示。
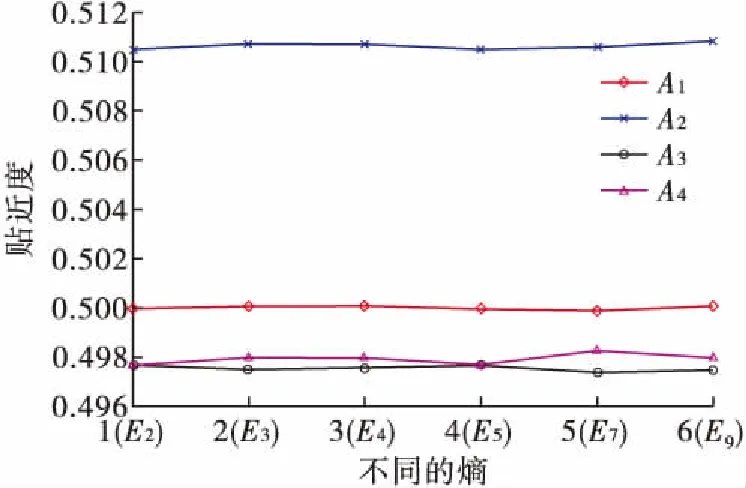
图4 选S10时不同的熵对应的各方案的贴近度
对比图3和图4,尽管采用不同的相似度公式,出现了方案的排序不一致的情况,但方案A2始终是最优的方案。
此外,选取本文提出的犹豫模糊集的混合加权相似度公式S7来计算各方案与理想解间的贴近度,结果如图5所示,方案A2仍然是最优的方案。
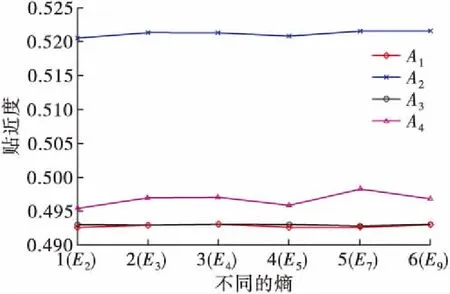
图5 选S7时不同的熵对应的各方案的贴近度
综合对比上述结果,可以看出:用不同类型的熵和相似度公式计算得出的贴近度的排序中,尽管方案的排序情况不一致,但方案A2始终是最优的方案。说明最终决策有一定可靠性。因此,选择地址A2作为新建的后勤补给基地的地址。
5 结语
本文推广定义了犹豫模糊集和区间值犹豫模糊集的熵与相似度,提出了犹豫模糊集的熵和相似度的一般公式,给出了犹豫模糊集熵和相似度的生成算法。并研究了犹豫模糊集的熵和相似度间的关系,提出了基于相似度构造熵的一般公式,把犹豫模糊集的熵和相似度间关系的有关结论及各自的一般化公式和生成算法推广到了区间值犹豫模糊集,从而为多属性决策中灵活地选择熵和相似度奠定了理论基础。下一步可以对犹豫模糊语言值集和对偶犹豫模糊集的信息测度及其应用进行研究与讨论。
