基于云计算资源分配与调度优化的改进蚁群算法研究
2020-06-29王玲
王玲
摘 要:针对云计算环境下节点数量巨大,单个节点资源配置低,难以实现及时的资源调度有效性,为此提出了一种基于云计算环境下资源调度分配的改进遗传算法策略。通过在算法中添加查找表作为一个中间层,给不同的任务推荐匹配的节点,根据不同的节点类型或者成功率因子来进行节点选择,采用节点强度对任务查找进行优先级划分,并根据概率参数来查看查找表信息。仿真结果表明:提出的算法相较于传统的RR算法,显著降低了任务执行耗时,从而能然用户任务更快的完成。
关键词:云计算;资源分配;调度优化;蚁群算法
Abstract:Because of the large scale of nodes in cloud computing environment and the low resource allocation of a single node, this paper proposes an improved genetic algorithm (GA) strategy based on resource scheduling and allocation in cloud computing environment. By adding the lookup table as an intermediate layer in the algorithm, the matching nodes are recommended to different tasks, and the nodes are selected according to different node types or success rate factors. The node strength is used to prioritize the task search, and the lookup table information is viewed according to the probability parameters. The simulation results show that the proposed algorithm is significantly lower than the traditional RR algorithm. The execution of the transaction is time-consuming so that the user task can be completed more quickly.
Key words:cloud computing;resource allocation;scheduling optimization;ant colony algorithm
0 引言
云計算采用服务方式为用户提供虚拟化资源池,实现分布式资源的合理调度余分配,并根据需求进行存储空间、计算能力的提升[1-4]。当前云计算资源管理方面主要以提高系统效率为目标的资源管理和调度研究[5-8]。如文献[9]基于遗传算法来实现云计算任务调度的负载均衡,有效提升资源分配效率和计算稳定性;文献[10-13]中基于动态趋势的蚁群算法,解决资源调度过程中空间占用率较多及响应时间过程问题,提升响应速度和计算精确度;文献[14-16]中针对云计算环境下资源调度性能进行策略优化,通过引入一种双适应度动态遗传策略来提升大规模数据响应效率,并寻找到资源调度的最优路径。
综上所述,本文在云计算资源调度方面,通过对传统蚁群资源调度算法的改良来提升云计算资源调度效率,同时降低运算成本。
1 基于蚁群的云资源调度分析
蚁群算法(ACA)是一种通过模拟蚂蚁行进过程留下的信息素来进行信息传递,通过信息素来寻找最优路径[17]。在云计算的资源调度中,设任务集合
T=(T1,T2,T3,…,Tm),整个任务集合中存在m个子任务,系统中布设了有n个处理机的虚拟机节点资源N=(N1,N2,N3,…,Nn)。通过资源的优化调度即在最小的消耗时间下将m个任务集合快速有效的分配到n个处理机,从而改善系统运行效率。
2 改进的蚁群算法
2.1 查找表
云计算中存在不同类型、不同属性的资源,对于某一种类型任务,只有连接到与之相匹配的计算机资源节点才能得到快速处理,而这个连接过程中,可通过建立相应的查找表来实现[18]。查找表作为一个中间层,将任务和资源建立对接关系,实现任务推荐匹配到对应的节点,并按照不同的节点强度对任务查找进行优先级划分,强度高的节点能够得到有效寻找。
蚁群算法根据搜索方向的不同主要有前向蚂蚁和后向蚂蚁。根据查找表中建立的连接关系,前向蚂蚁对节点进行搜索查找,若节点不为空,则将寻找到的最大强度节点作为搜索的初节点,将该节点所携带的相关信息置入查找表中,同时节点强度加1。当搜索到的节点为空,则前向蚂蚁将随
机选择节点作为初始节点开始下一跳搜寻,并将查找表中次节点强度减1,直到0为止。后向蚂蚁则将受到到的节点信息返回。查找表推介节点规模设为n,当n=0时,查找失败,当n≥1,查找表发挥作用。
查找表不仅可放在资源、任务间,也可放在节点处,称为节点查找表[19]。节点查找表存放在相邻的两个节点之间的下一跳节点。根据节点类型和成功率因子来选择,并形成一个后向节点,后向节点携带该节点的信息沿着原路返回,并将节点信息置入路经的节点,同时整个查找表得到更新。若查找表中未包含该节点,且存在强度为0节点,则删除0节点,并将该节点加入表中,同时节点强度设置为1。若查找表中已包含该节点,则节点强度加1。为避免查找表不断递增而使得规模过大[20],设置一个计时器
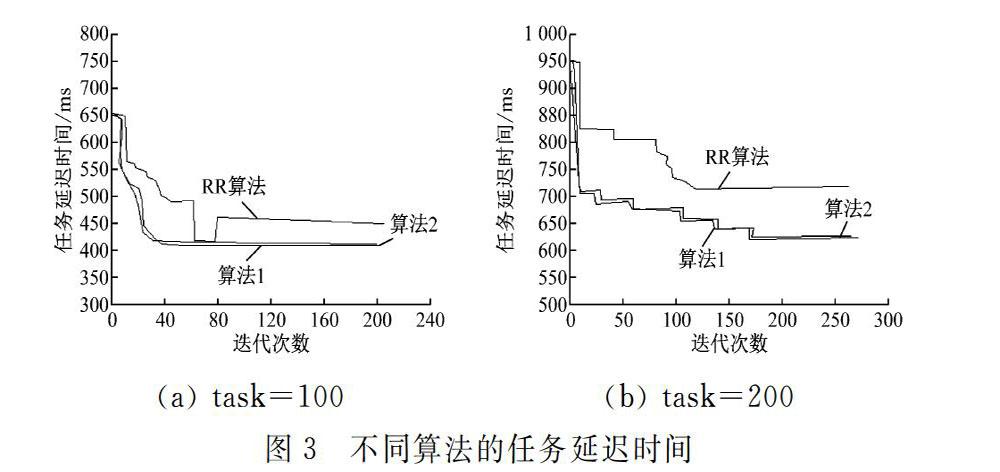
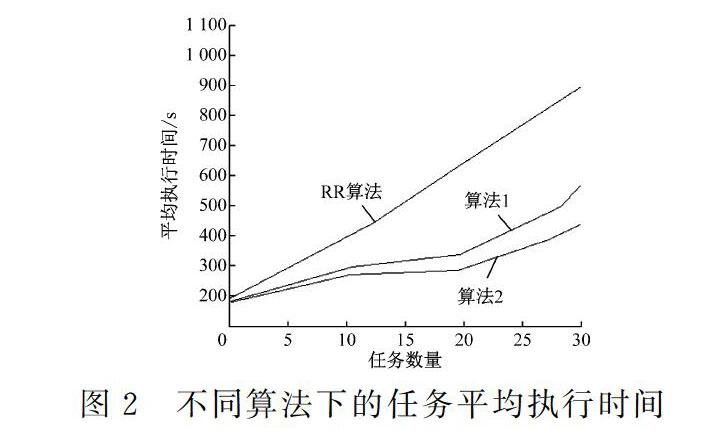
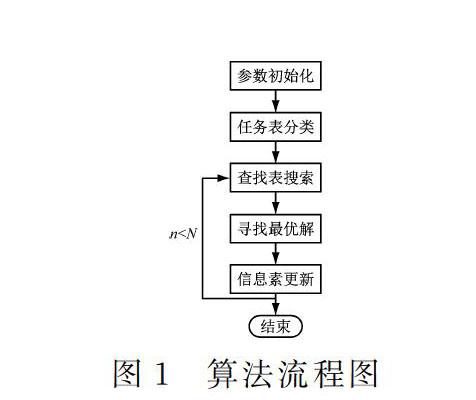
t0,当t0逐渐降低到0时,则节点强度为0,删除该节点信息。在选择下一节点时,首先确定该节点信息是否已被删除,同时设定一个查看查找表的概率参数p0(0 采用成功率因子来选择节点查找表存放位置时,将成功率最高的2个节点放入查找表,后期选择查找表放入节点时,有限选择成功率因子最高的节点,在下一条时,根据概率优先来选定查找表节点位置。 2.2 信息素定义 资源信息素主要包括资源处理能力、负载均衡能力、节点间通讯能力等直接影响到硬件资源的相关因子[21]。当资源加入资源列表后,采集存储容量、通信宽带等信息,确定该节点的初始信息素τi(0),如式(1)所示。 其中τi(t1)为t1时刻节点信息素大小,λ0为调节因子,当节点分配调节成功,则0<λ0≤1,當分配调节失败时,则存在有-1≤λ0<0。在Δt时间内,当该节点为有效值,则成功值加1,失败减1。 定义成功率因子f,即Δt时间内,若节点为有效节点,则成功值加1,否则减1。f则是Δt时间内,节点成功值与被选中次数比值。若Δt时间内节点选中的次数较多,则f上升。 2.3 下一跳选择 设定蚂蚁数量n,节点数量m。当n只蚂蚁随机分配到m个节点,则定义节点i中第k只蚂蚁在t时刻选择下一节点j的概率,如式(4)所示。 2.4 算法步骤 构建系统的整体查找表时来实现资源调度,如图1所示。 (1) 首先初始化各节点信息素值,并进行查找表的初始化,设定最大迭代N作为接受条件。 (2) 任务列表分类 (3) 采用蚂蚁算法搜索查找表,当不为空,则节点生成m个前向蚂蚁,通过概率公式让蚂蚁继续搜索下一节点j,并将搜素的j点置入禁忌表。若查找表位空,则前向蚂蚁随机选定一节点计算,并通过概率计算确定下一节点。 (4) 若j点为有效节点,则j点生产后向蚂蚁,并携带信息返回,将信息保存在路过的各节点,按照式(2)和(3)更新信息素,若寻找到最优解,填入查找表 。 (5) 后向蚂蚁原路径返回过程中的携带信息来更新查找表信息。 (6) 执行最大迭代次数,设定最大迭代次数N,当迭代此时n=N时,任务分配完成,进入下个任务,否则转至步骤(3),清空禁忌表。前向蚂蚁以概率p0选择查看节点查找表,并根据后向蚂蚁的返回信息来更新节点查找表。 3 算法仿真分析 为验证本文算法的有消息,采用CloudSim进行算法仿真分析,采用MyEclipse算法工具。实验过程中,设置初始条件值:α=0.5,β=0.5,资源重要度均为0.25,任务数由10-200范围递增,范围在[5,20]随机选择,资源节点数5,为降低算法仿真误差,设每个算法运行10次,取算法的平均值,图中算法1为是在传统蚁群算法下载资源列表和任务列表间插入了查找表,并考虑了成功率因子。算法2是在算法1基础上插入了节点查找表。在相同条件下比较算法1、算法2和传统RR算法的任务完成效率,资源参数表,如表1所示。 图2中可以看出,在相同的任务数量下,算法1和算法2较传统的RR算法任务用时短。同时,随着任务数量的增加,这种任务执行时间越短,即执行效率进一步提高。这主要是由于任务数的不断上升,任务分配占用时间比例下降,有效提升了对资源的调度和任务的完成效率[23-24]。比较算法1和算法2的任务按时时间可以看出,算法2的平均完成时间更多,即采用节点查找表的方式相对于资源类表和任务列表能够加快算法的收敛,具有更高的任务完成效率。 同时比较算法在相同任务数条件下的任务延迟时间对比,如图3所示。 设调度任务为100时,比较三种算法的任务延迟时间可以看出,采用算法2的收敛速度较快,且任务任吃时间相较于RR算法少了40 ms,当任务量增加到200时,两种算法的任务延迟时间差距增加到210 ms,可以看出,随着调度数量增加,采用本文设计的调查表插入法进行任务调度具有更小的任务延时效果,能够有效提升任务调度效率。 4 总结 本文提出了一种基于云计算环境下资源调度分配的改进遗传算法策略。通过在算法中添加查找表作为一个中间层,给不同的任务推荐匹配的节点,根据不同的节点类型或者成功率因子来进行节点选择,采用节点强度对任务查找进行优先级划分,并根据概率参数来查看查找表信息。采用CludSim对算法进行仿真表明,采用本文提供的算法降低了任务执行耗时和任务延迟时间,提高了节点搜索效率。 参考文献 [1] 杨建华,郑杰.基于改进蚁群算法的云计算任务调度方法研究[J].中国新通信,2019,21(6):54-57. [2] 杨苏影,陈世平.基于包簇框架平衡蚁群算法的资源分配策略[J].软件,2018,39(6):4-8. [3] 陈暄,徐见炜,龙丹.基于蚁群优化-蛙跳算法的云计算资源调度算法[J].计算机应用,2018,38(6):1670-1674. [4] 王文东,刘继梅.基于蚁群算法的云计算资源调度研究综述[J].电脑知识与技术,2017,13(23):161-163. [5] 单好民.基于改进蚁群算法和粒子群算法的云计算资源调度[J].计算机系统应用,2017,26(6):187-192. [6] 徐浙君,陈善雄.基于膜计算和蚁群算法的融合算法在云计算资源调度中的研究[J].计算机测量与控制,2017,25(1):127-130. [7] 崔丽梅.云计算中的基于ACA-GA的资源调度的研究[J].科技通报,2016,32(9):149-153. [8] 李媛祯,杨群,赖尚琦,等.一种Hadoop Yarn的资源调度方法研究[J].电子学报,2016,44(5):1017-1024. [9] 姜栋瀚,林海涛.云计算环境下的资源分配关键技术研究综述[J].中国电子科学研究院学报,2018,13(3):308-314. [10] 王岩,汪晋宽,宋欣.云计算资源纳什均衡优化分配方法改进[J].计算机工程,2017,43(12):17-24. [11] 陈钦荣,刘顺来,林锡彬.一种混合优化的云计算资源调度算法[J].韩山师范学院学报,2016,37(6):15-23+61. [12] 王煜炜,刘敏,房秉毅,等.面向网络性能优化的虚拟计算资源调度机制研究[J].通信学报,2016,37(8):105-118. [13] 任琼,常君明.基于任务分类思维的云计算海量资源改进调度[J].科学技术与工程,2016,16(12):101-105. [14] 赵宏伟,申德荣,田力威.云计算环境下资源需求预测与调度方法的研究[J].小型微型计算机系统,2016,37(4):659-663. [15] 朱海,王洪峰,廖貅武.云环境下能耗优化的任务调度模型及虚拟机部署算法[J].系统工程理论与实践,2016,36(3):768-778. [16] 林伟伟,朱朝悦.面向大规模云资源调度的可扩展分布式调度方法[J].计算机工程与科学,2015,37(11):1997-2005. [17] 趙宏伟,李圣普.基于粒子群算法和RBF神经网络的云计算资源调度方法研究[J].计算机科学,2016,43(3):113-117+150. [18] 王金海,黄传河,王晶,等.异构云计算体系结构及其多资源联合公平分配策略[J].计算机研究与发展,2015,52(6):1288-1302. [19] 张燕,顾才东.一种求解云计算资源优化的改进蝙蝠算法[J].科技通报,2014,30(11):117-121. [20] 刘运,程家兴,林京.基于高斯变异的人工萤火虫算法在云计算资源调度中的研究[J].计算机应用研究,2015,32(3):834-837. [21] 李菁.改进快速稀疏算法的云计算资源负载均衡[J].微型电脑应用,2019,35(10):36-38. [22] 刘梓璇,周建涛.负载均衡的主导资源公平分配算法[J].计算机工程与科学,2019,41(9):1574-1580. [23] 赵莉.基于支持向量机的云计算资源负载预测模型[J].南京理工大学学报,2018,42(6):687-692. [24] 王虎,雷建军,万润泽.基于改进的粒子群优化的云计算资源调度模型[J].华中师范大学学报(自然科学版),2018,52(6):788-791. (收稿日期:2019.09.12)
