基于多层全连接神经网络的白洋淀水质预测
2020-06-29刘世存王欢欢赵彦伟朱晓磊
刘世存,杨 薇,田 凯,王欢欢,赵彦伟*,朱晓磊
(1.水环境模拟国家重点实验室,北京师范大学环境学院,北京 100875;2.中国雄安集团生态建设投资有限公司,河北 保定071700)
白洋淀是华北平原最大的天然湖泊湿地,被誉为“华北明珠”,具有缓洪滞沥、调节气候、蓄水兴利、渔苇生产等多种功能[1],在维持华北地区生态平衡和生物多样性方面发挥生态安全屏障作用[2]。20世纪70年代至今,随着流域及淀区人口数量的增长和经济的发展,白洋淀入淀水量减少,水质呈下降趋势[3],淀区内的南刘庄、端村站水质下降到Ⅴ类,总氮(TN)、总磷(TP)和化学需氧量(COD)超标较为严重。同时,白洋淀又处于雄安新区腹心位置,是雄安新区的重要生态依托,其水质状况直接关系到雄安新区未来的整体环保形象,因此,对其进行水质预测,可为白洋淀综合治理提供依据,对于推进雄安新区的水生态环境建设也具有重要意义。
由于影响水质的因素较多,各因素对水质的作用呈现复杂的非线性关系,传统的数据处理方法不能很好地解决这一问题[4]。20世纪80年代迅速发展起来的人工神经网络(ANN)为这种非线性复杂系统过程的模拟和评判提供了一条有效途径[5]。ANN是一种非线性数据建模工具,常用来对输入与输出间复杂的关系进行建模,具有独特的分布并行处理、非线性映射和自适应学习能力等特征[6],在水环境模拟与预测中被广泛应用[7-9]。但传统神经网络方法只包括一个输入层、一个输出层和一个隐藏层,存在学习速度慢、拟合精度不高、易陷入局部极小值等问题[10],使应用受限。而基于深度学习(DL)算法实现的全连接神经网络(FCN)包含5~6个隐藏层,可实现无监督学习,从而以更少的模型参数、更快的收敛速度和更高的拟合精度来逼近现实[11],在大气污染预测[12]、能源消费量预测[13]、河流流量预测[14]、降雨预测[15]、水方案监测系统设计[16]和废水污染去除效率评价[17-18]等领域得到较多应用,但其在水环境质量预测领域的研究较少。
本文利用1996—2015年白洋淀内南刘庄、圈头和烧车淀监测点位的水质数据,建立全连接神经网络水质预测模型,对白洋淀水质进行预测,为白洋淀水质管理与雄安新区水环境保护提供决策依据。
1 研究区概况与数据来源
1.1 研究区概况
白洋淀位于海河流域大清河水系中游,地理位置为115°38′~116°09′E,38°43′~39°01′N(图1)。淀区由保定市、沧州市交界143个相互联系的大小淀泊和3 700多条沟壕组成,总面积366 km2,四周以堤坝为界。白洋淀多年平均气温7.3~12.7℃,年平均降水量563.9 mm,年平均蒸发量1 369.0 mm[19]。目前,白洋淀各水质监测站点全年平均水质类别为Ⅳ类至Ⅴ类,主要污染物为COD、TN、TP等。
1.2 数据来源
本研究在模型的训练、率定和校验时,分别利用了白洋淀南刘庄、圈头和烧车淀监测点1996—2015年、2016年和2017—2018年水质监测数据。其中,2013年和2018年数据是通过现场采样监测获取,2016—2017年数据来自安新县环保局,2009—2012年和2014—2015年数据来自相关文献[20-22],1996—2008年数据来源于保定市环境质量公报。

图1 白洋淀地理位置Figure 1 Location of Baiyangdian
2 全连接神经网络模型的构建
2.1 数据处理与参数设置
2.1.1 数据预处理
为使神经网络有更高的训练效率和预测精度,提高训练灵敏性,需要对原始数据进行归一化预处理。为方便结果的对比,还需对模型预测值进行反预处理。本研究选择较为常用的最大值最小值处理法,但由于传统的方法会出现0值,极易对结果产生较大影响,因此参考郭庆春等[23]改进的最大值最小值归一化方法,对水质原始数据进行预处理,对模型预测值进行反预处理。数据预处理方法的计算公式为:
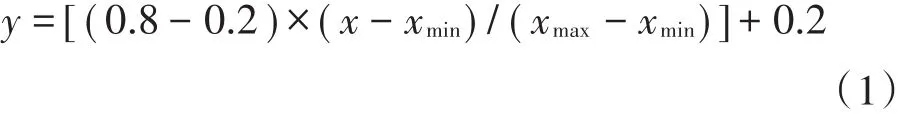
反预处理方法的计算公式为:
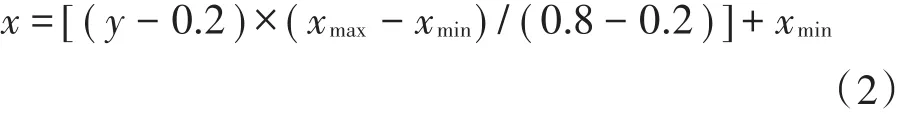
式中:x是水质原始数据;y是预处理后的数据;xmin和xmax分别是原始数据的最小值和最大值。
2.1.2 模型边界设定
本研究以白洋淀四周的堤坝边界为模型空间边界,以1996—2022年为模型的时间边界。其中,1996—2015年为历史统计数据年,2020—2022年为模型预测年,为减少时间步长带来的误差,确定模型模拟的时间间隔为1个月。
由于实训项目的开展贴近行业实践,校企合作刚好为学生提供了参与企业实际项目的机会,并受到来自企业技术人员的专业指导,增强了课程内容的专业化水平。另一方面,企业也可以从学生参与项目的过程中,考量和挖掘人才。在实践教学的有力助推下,生命科学学院获批教育部“产教融合、协同育人”项目1项,填补了学院在该类项目上的空白,也为校企合作的纵深发展奠定了良好基础。
2.1.3 模型变量和参数设置
(1)输入变量与输出变量确定
将1996—2015年南刘庄、圈头和烧车淀监测点位的生化需氧量(BOD)、COD、TN和TP等4项水质指标数据用作模型的训练,2016年数据用作模型率定,2017—2018年数据用作模型校验。模型的输入变量是BOD、COD、TN和TP的监测值,模型的输出变量是BOD、COD、TN和TP的预测值。
(2)网络层数和隐藏层确定
神经网络模型的主要结构包括输入层、隐藏层和输出层。相比于传统神经网络模型,全连接神经网络更强调模型的深度,通常有5层或6层甚至更多的隐藏层。本研究构建了含一个输入层和一个输出层的神经网络,由于选定的水质指标是4项,因此输入层和输出层的神经元个数均是4。根据Komogorov定理和Hecht-Nielsen理论,采用试错法确定隐藏层层数和隐藏层的节点数量,最终确定的隐藏层层数为6,节点个数分别为32、64、128、64、32、8,神经网络拓扑结构最终确定为 4∶32∶64∶128∶64∶32∶8∶4(图2)。
(3)模型主要参数设置
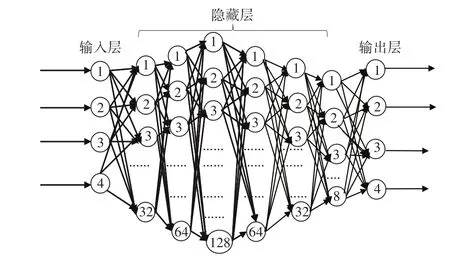
图2 白洋淀多层全连接神经网络水质预测模型结构Figure 2 Multi-layer fully connected neural network water quality prediction model structure of Baiyangdian
2.2 模型参数率定
选择2016年烧车淀监测站点的BOD、COD 2项指标,对模型参数进行率定。将神经网络学习步长由10 000调增为15 000,再调增为20 000,将每次送入网络中训练的数据个数由55调增为65,再调增为88。模型参数率定前后水质指标的拟合效果对比见图3(a、c为率定前效果,b、d为率定后效果)。由图可见,模型参数率定后,拟合优度判断系数R2均在0.99以上,说明拟合效果较好。
同时利用平均绝对误差(MAE)检验率定结果。MAE是模型运行生成的损失函数,计算公式为:
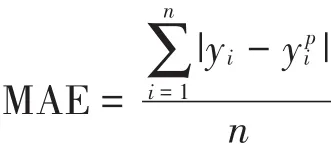
式中:yi为实际值,mg·L-1;为模型的预测值,mg·L-1;n为数据的个数。经过参数率定,随着训练步数的增加,模型模拟的MAE值大幅度减小。由表1可见,训练结束时,MAE平均值由参数率定前的2.45下降到0.05,误差在可接受范围内。
2.3 模型校验
利用2017年和2018年白洋淀烧车淀、南刘庄、圈头3点位及其平均水质数据,对率定后的模型进行校验。各项水质指标实际值和预测值的拟合情况如图4~图7,模型校验误差见表2。
由图可见,各项水质指标的模型拟合优度判断系数R2均在0.85以上,模型整体拟合效果较好。其中,烧车淀的BOD、COD、TN、TP,南刘庄的BOD、COD,圈头的BOD、COD、TN、TP和淀区BOD、COD、TP平均值的拟合优度判断系数R2均超过0.90,模型对各项水质指标拟合的MAE在0.011~0.214之间(表2)。构建的模型校验结果理想,模型可用。
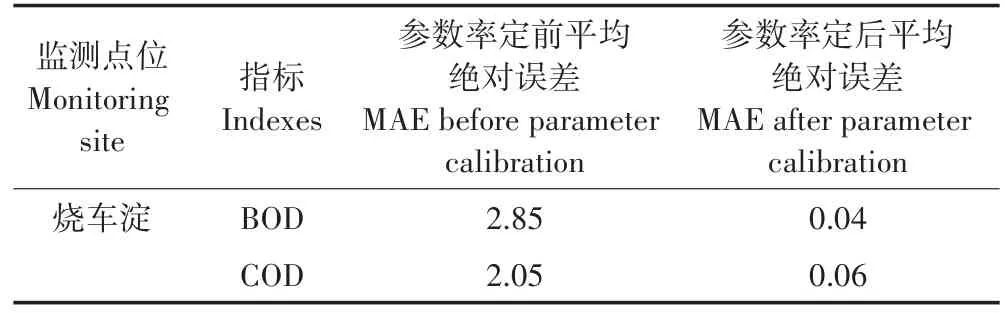
表1 模型参数率定前后误差对比Table 1 Error comparison before and after model parameter calibration
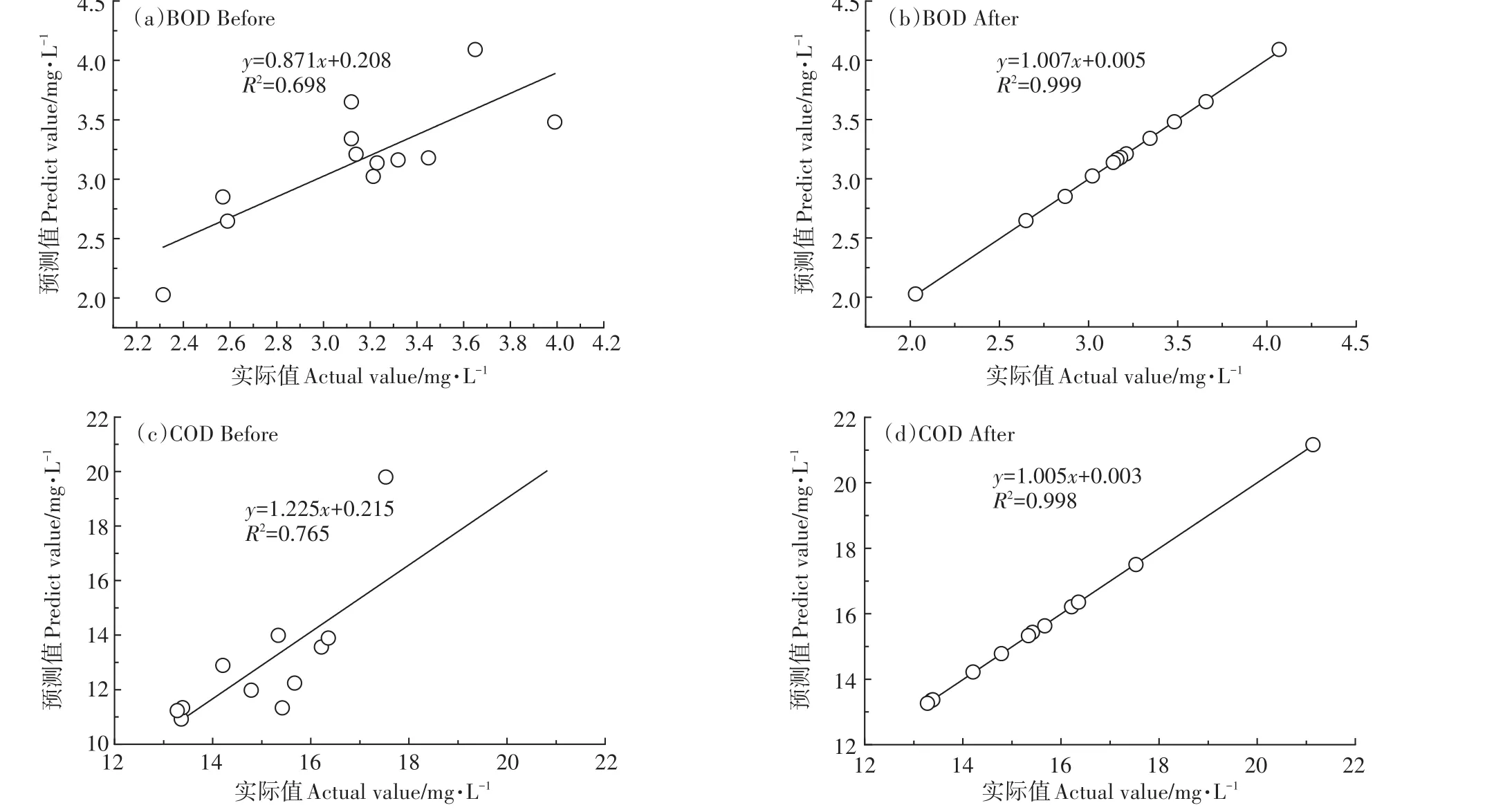
图3 模型参数率定前后拟合效果对比Figure 3 Comparison of fitting effect before and after model parameter calibration
3 结果与讨论
3.1 模型预测结果
采用本研究构建的全连接神经网络模型,对白洋淀2020年3月—2022年11月南刘庄、圈头、烧车淀及3点位的平均水质进行预测,结果见图8。由图可见,各点位BOD、COD、TN和TP浓度均呈下降趋势。其中,烧车淀水质改善最为明显,各项水质指标均达到地表水Ⅳ类标准;圈头水质改善情况一般,TN没有达标;南刘庄水质改善最少,TN和TP没有达标;3点位预测平均值TN没有达标。各项指标中:BOD浓度依次为圈头>南刘庄>3点平均>烧车淀;COD浓度依次为圈头>3点平均>烧车淀>南刘庄;TN浓度依次为南刘庄>3点平均>圈头>烧车淀;TP浓度依次为南刘庄>3点平均>圈头>烧车淀。整体来说,未来3 a白洋淀烧车淀的水质相对较好,南刘庄的水质相对较差,圈头的水质一般。总体上,未来3 a各点位水质均有所改善,但仍面临部分点位TN、TP富营养化指标不达标的问题。

表2 模型校验误差Table 2 Model validation error
3.2 讨论
为进一步评估预测结果的可靠性,采用灰色模型GM(1,1)和曲线估计方法对未来3 a白洋淀平均水质进行预测。采用灰色模型GM(1,1)时,分别用最小二乘法计算得到不同水质指标数据对应的参数估计值,建立模型对应的白化方程及时间响应式,得到未来水质指标预测值。采用曲线估计方法时,以水质指标数据作因变量,时间作变量,选择拟合效果最好的方程作为曲线估计方程进行预测。3种方法预测结果的对比见图9。由图可见,3种模型预测的水质指标变化趋势基本一致,BOD、COD、TN和TP浓度均有所降低。相比于本文构建的全连接神经网络模型,灰色GM(1,1)模型预测结果数值偏低,曲线估计方法预测结果数值偏高,但预测结果均没有较大差异。可见,经过多次训练,本文构建的全连接神经网络模型预测结果和其他模型结果差异较小,预测结果可靠。
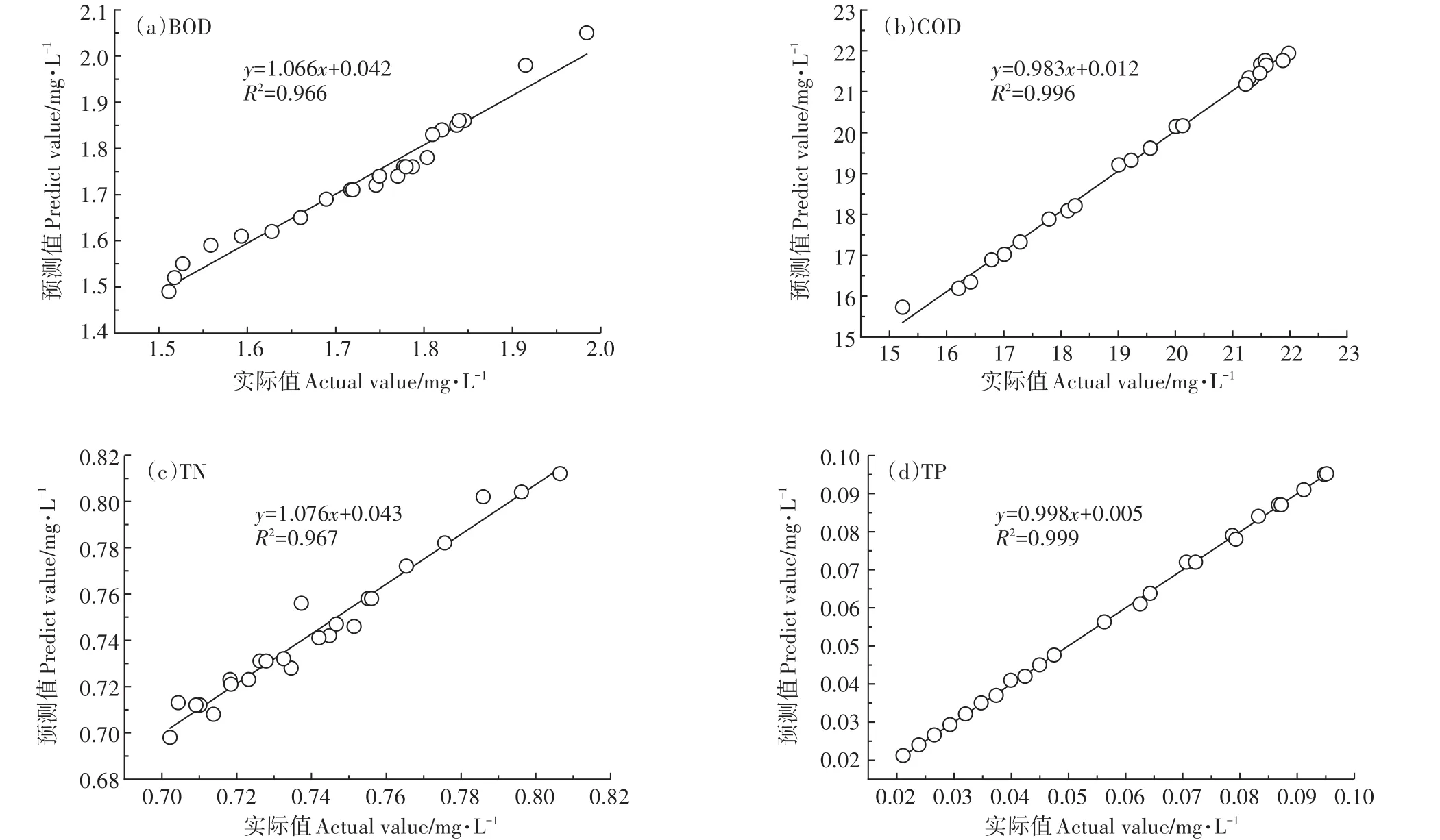
图4 烧车淀各项水质指标模型拟合结果Figure 4 Model fitting results of various water quality indexes in Shaochediana
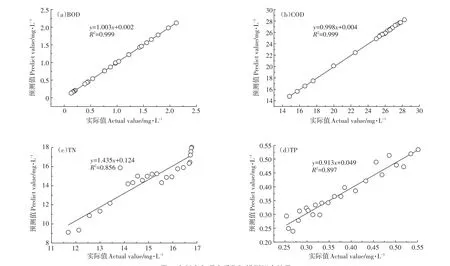
图5 南刘庄各项水质指标模型拟合结果Figure 5 Model fitting results of variouswater quality indexes in Nanliuzhuang
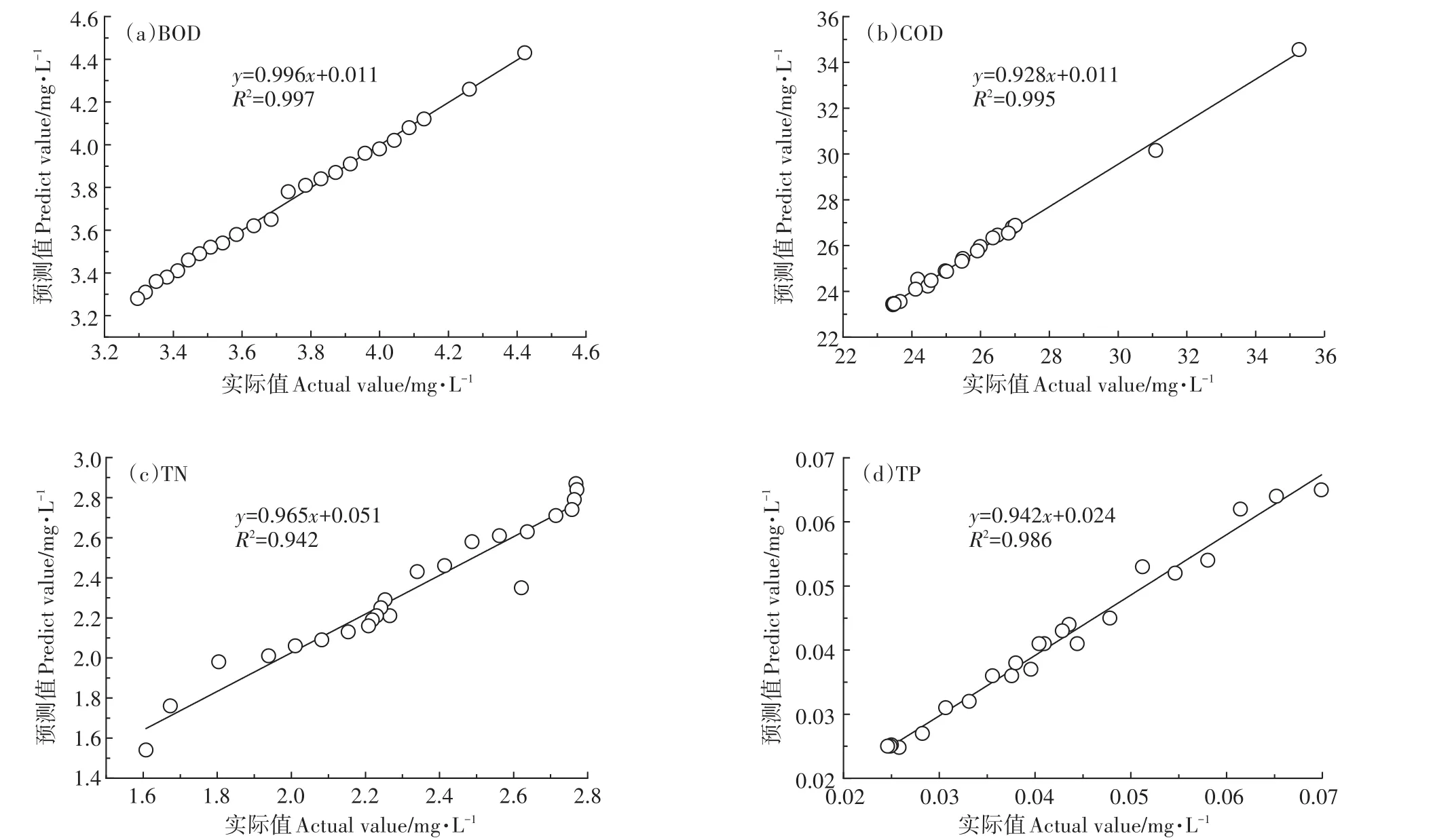
图6 圈头各项水质指标模型拟合结果Figure 6 Model fitting results of various water quality indexes in Quantou
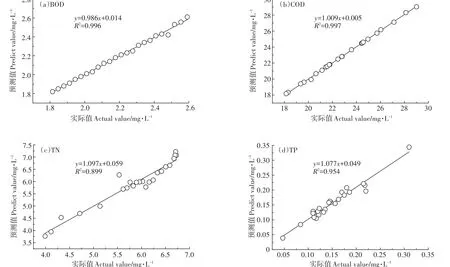
图7 平均水质各项指标模型拟合结果Figure 7 Model fitting results of variouswater quality indexes in average water quality
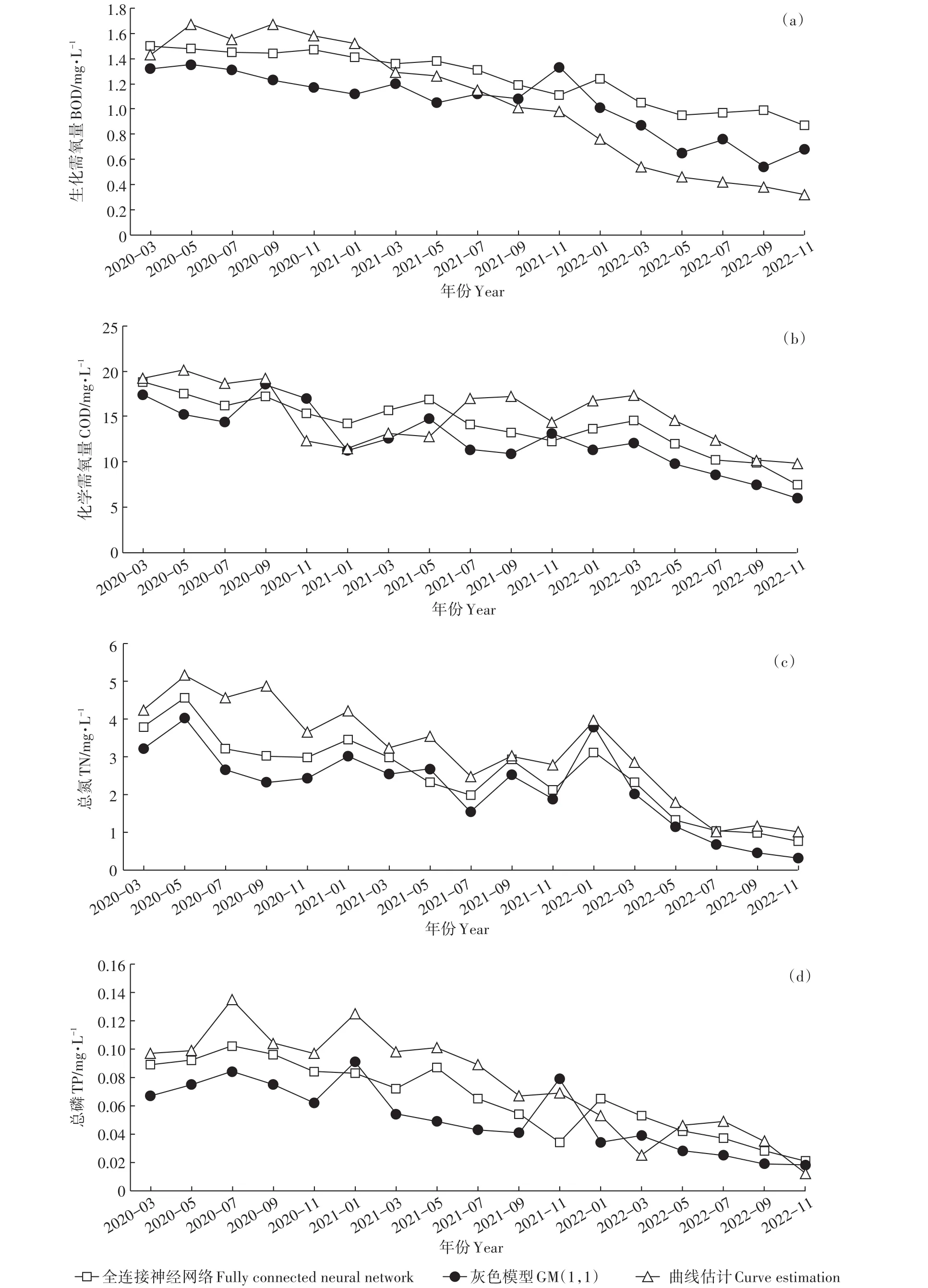
图9 3种模型预测结果对比Figure 9 Comparation of the prediction results of three models
由预测结果可见,未来3 a白洋淀仍面临部分水质指标不达标的问题,尤其是南刘庄的TN和TP等富营养化指标超标。这可能是因为南刘庄位于府河入淀口附近,接受大量府河入淀的市政污水,污染负荷巨大。圈头的TN预测结果也略有超标,这可能是由附近淀中村和纯水村的生活污水排放所致。同时,湖泊底泥和沉积物营养物释放与围堤围埝众多导致的水系连通性变差,可能也是富营养化指标预测结果超标的一个原因。未来的治理中,应坚持“控源、补水、连通”相结合的治理思路,协调保定市加强市政污水的治理,加强水村和淀中村的生态移民与生活污染治理,并结合雄安新区的发展,科学实施城镇地表径流与种植业化肥过施导致的非点源污染控制;还要结合“南水北调”和“引黄济淀”的工程,多路径实施生态补水,抬高生态水位,提升环境容量;同时,应实施淀区水动力条件的模拟与分析,在不影响底泥污染释放的前提下,拆除围堤围埝等阻水建筑,实现白洋淀沟渠水系连通,改善水动力条件,促进污染扩散与降解。
相比于传统的单隐藏层BP神经网络,本文构建的全连接神经网络含6个隐藏层,网络训练时的计算量增加,模型模拟的 MAE 值为 0.011~0.214,R2在0.856~0.999之间,模型率定与校验结果比较理想。邹志红等[24]计算了BP神经网络在河流水质预测中的误差,模型MAE值为0.178~0.628。陈鹏飞等[25]构建了BP神经网络用于清河水库水质的预测,模型MAE值为0.438~1.568。相比之下,本文构建的全连接神经网络模型预测精度有一定提高,但该模型也存在网络训练时间相对较长、模型辅助参数较多等不足,以后可通过优化实现程序等方式改进。
4 结论
本文利用1996—2015年白洋淀南刘庄、圈头和烧车淀3个监测站点的水质数据,通过模型率定与校验,构建了白洋淀全连接神经网络水质预测模型,对白洋淀水质变化趋势进行预测。结果表明,未来3 a白洋淀水质呈现好转趋势,BOD、COD、TN和TP浓度均有所下降,但仍有部分点位TN和TP超标,应加强入淀河流与淀中村污染控制,强化生态补水与水系连通,进一步改善白洋淀水环境质量。
