车内综合烦躁度评价的时序平滑激励级谱CNN模型*
2020-06-29冯天培孙跃东王岩松张博强刘宁宁
冯天培,孙跃东,王岩松,张博强,刘宁宁,,郭 辉
(1.上海理工大学机械工程学院,上海 200093; 2.上海工程技术大学机械与汽车工程学院,上海 201620;3.河南工业大学机电工程学院,郑州 450007)
前言
深度学习网络模拟人类神经系统及其非线性层次化特性,逐层对信息进行非线性特征抽取并综合处理,适用于建立车辆声品质评价模型[1-2]。梁凯等[1]利用能够直接处理二维面板信号的卷积神经网络(convolution neural network,CNN),构建内燃机噪声的听觉时频谱声特征与烦躁度全局主观评价结果之间的映射关系,结果表明整体烦躁度CNN评价模型的预测性能高于前馈神经网络模型。
非平稳噪声声品质的瞬时主观评价研究发现,时变声品质主观评价时间序列是平滑的,而提取的A计权声压级与响度等声特征序列是波动的[3-4]。利用波动的声特征时间序列建立时变声品质评价模型,导致预测曲线呈现波动性,降低了对非平稳噪声平滑性时变声品质的评价效果。对于车辆噪声整体综合烦躁度CNN评价模型,时域波动听觉谱的直接使用会限制模型预测性能。对听觉谱进行时域平滑预处理,获取时序平滑听觉谱声特征,可改善模型预测性能。
本文中对采集的汽车匀速和加速车内噪声进行综合烦躁度全局主观评价试验,使用Savitzky-Golay滤波器时间序列平滑法(SG滤波器)对噪声样本激励级谱进行时域平滑预处理,分别以激励级谱与时序平滑谱为声特征,利用CNN构建噪声样本的声特征与整体综合烦躁度主观评价结果之间的映射关系,研究方法如图1所示,分析听觉时频谱的时域平滑预处理对车内噪声整体综合烦躁度CNN评价模型性能的改进效果。
1 车辆声品质评价基础理论
1.1 人类声品质评价系统

图1 车内噪声整体综合烦躁度评价的激励级谱与时序平滑谱CNN模型
人类声品质评价系统包括耳朵、听觉神经系统与大脑,涵盖了声音信息的收集、传递、处理与主观判断。其中,耳蜗将中耳传来的声振信号进行听觉频带解析处理并转换为电化学信号,通过刺激听神经向听觉神经系统传递电脉冲信息。听觉中枢对携带频带声信息的生物电信号进行非线性层次化处理,综合形成对声事件的听觉感知。大脑结合听觉感知与个人主观因素如心理活动、社会经历、偏好与性格等,形成对声音声品质的判断与评价结果。声信号的耳蜗听觉频带滤波与听觉神经系统的非线性层次化信息处理是声品质形成的重要过程。
1.2 心理声学客观参量
心理声学客观参量包括响度、尖锐度与粗糙度等,常用于测量与评价车辆声品质。粗糙度反映听觉系统对声音在时域上幅值快速变化的一种感觉。Aures粗糙度模型[5]是典型的粗糙度计算方法,利用24个听觉频带广义调制系数计算粗糙度。尖锐度感觉被声音频谱包络影响,反映声音的刺耳程度。响度表征声音强弱的主观感觉。Zwicker响度模型[6]已被国际标准 ISO 532B采用[7],是最常用的响度提取算法。其利用1/3倍频程滤波器组模拟耳蜗,对声音信号的功率谱密度进行带通滤波,计算听觉特征频带激励级与沿临界频带率分布的特征响度,积分获得响度值,具体流程如图2所示。考虑加权因子的Zwicker尖锐度模型是常用的尖锐度提取方法,如图2所示,并被德国标准DIN 45692所采用[8]。综上可知,常用心理声学客观参量的计算方法充分考虑了听觉频带滤波特性,所以频带声信息如激励级时频谱,可作为声特征建立车辆声品质评价模型[2]。
1.3 车辆声品质评价体系
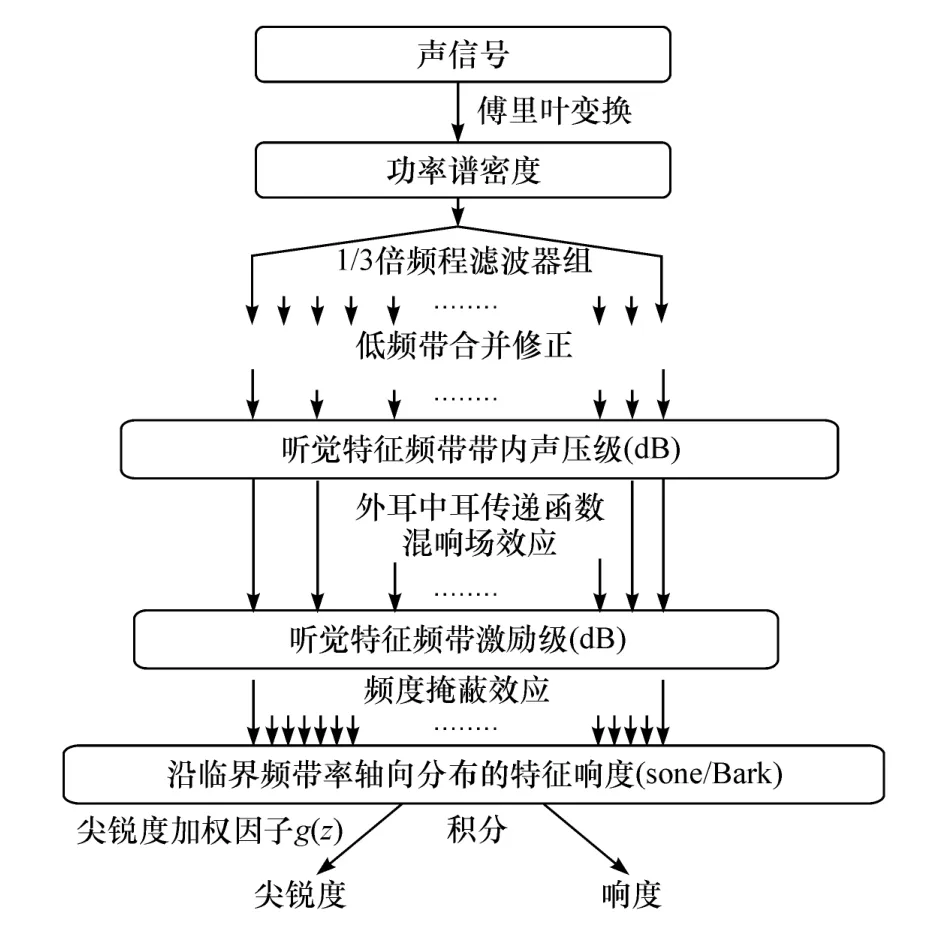
图2 Zwicker响度与尖锐度计算方法
车辆声品质评价分为全局评价(global evaluation)与瞬时评价(instantaneous evaluation)[9]、主观评价与客观评价两个维度,如图3所示。

图3 车辆声品质评价体系
主观评价研究以人为主体,采用听音评价试验的方式进行[10]。在车辆噪声声品质主观评价试验中,选定评价指标与评价方法,组织评审团对车辆噪声样本进行听音评价,统计并分析声品质评价结果。其中,常用的主观评价指标包括响度、尖锐度、粗糙度等单维度指标和综合烦躁度、偏好性与运动感等多维度综合性评价指标。主观评价数据的典型统计量,如平均评价值,能够反映出评审团对车辆噪声直观全面的听觉感受,代表了车辆噪声的真实声品质水平,所以主观评价是车辆声品质评价的基本研究方法。
客观评价研究分为传统客观评价与智能评价。传统客观评价以心理声学客观参量计算模型为典型代表,采用仪器测得的声学客观量来进行声品质评判。传统评价模型的算法过程复杂,对心理因素的计算模拟存在较大难度,所以在更靠近心理活动的综合性评价指标的客观评价计算上存在不足。智能客观评价利用机器学习方法构建噪声特征与主观评价结果之间的映射关系,建立车辆噪声声品质客观评价模型[11-13],将对心理活动的模拟融入模型中,可对声品质进行较为精确的量化估计,是常用的对综合性声品质评价指标的客观评价方法。其中多元线性回归[14]、人工神经网络[15]、支持向量机[16]与深度学习[1-2,17]是有效的建模机器学习方法,心理声学客观参量[11-12,14]与听觉谱[1,15]是常用声特征。主观评价与智能客观评价是研究车辆噪声声品质评价的两个递进的层次,主观评价是客观评价的基础,客观评价升华了主观评价的研究。
全局主观评价试验常采用等级评分法、成对比较法和语义细分法等评价方法,获取评价人员对评价对象的整体声品质评价单值,可对车辆噪声声品质进行全局整体性认识。利用机器学习方法构建噪声样本的全局主观评价结果与提取声特征之间的映射关系,建立整体声品质评价模型,评价速度快、一致性好,适合于工程应用。与全局评价不同,瞬时评价主要针对非平稳噪声。在车辆噪声声品质瞬时主观评价中,评价人员根据回放的噪声样本实时给出相应的瞬时声品质评价值,获得并统计针对评价对象的时变声品质评价序列,在瞬时主观感受变化方面对非平稳车辆噪声的声品质进行微观局部性认识[3,9]。利用机器学习方法构建时变声品质主观评价序列与声特征序列间的映射关系[11],建立时变声品质评价模型,可测量与分析车辆时变声品质环境、监控车内实时声品质水平。全局评价与瞬时评价的研究成果可以相互借鉴。本文中研究汽车车内噪声整体综合烦躁度的智能客观评价。
2 汽车车内噪声的采集与听音评价试验
2.1 车内噪声样本库建立
依据国家标准GB/T 18697—2002《声学— 汽车车内噪声测量方法》[18],本文中采集汽车匀速和加速工况下车内噪声。试验车辆选择3辆不同品牌的国产轿车,分别标记为A、B与C车。工况设为30、40、50、60、70、80、90、100 km/h匀速行驶15 s及50~120 km/h全油门加速行驶,整个过程不能换挡。采集设备为B&K公司的PULSE声音采集系统和两只1/2英寸类型4189-A-21的传声器,采样频率为65 536 Hz,采集车辆前排司机位、副驾驶位与后排左乘客位(分别标记为 I、II、III位置)双耳处噪声。
每种试验条件下测量3次以上,使用B&K公司的Sound Quality软件对现场采集的车内噪声信号进行采样频率为44 100 Hz的重采样。通过听音回放,并分析噪声信号声学参量如A计权声压级、响度等随时间变化情况,选出每种条件下运行工况稳定且受其他因素影响小的最佳噪声信号。考虑到人类听觉主观感知的形成过程,从选出的噪声信号中剪辑出时间长度为5 s[19]的音频信号作为一个噪声样本,其中加速噪声信号持续时长均在10 s以上,在加速噪声信号的前半部分与后半部分各截取一段5 s的噪声样本。每辆车可获取30个噪声样本。根据采集车辆、位置与工况对样本进行编号,如AI-70表示A车驾驶员位70 km/h匀速行驶车内噪声样本,BII-a表示B车副驾驶位50~120 km/h加速行驶前半部分时长5 s的噪声样本,CIII-b表示C车后排左乘客位50~120 km/h加速行驶后半部分时长5 s的样本,建立本文中汽车车内噪声样本库,共90个样本,包括72个匀速噪声样本与18个加速噪声样本。其中AI-b、BII-70与C车后排左乘客位匀速噪声样本的声学参量测量值如图4所示。
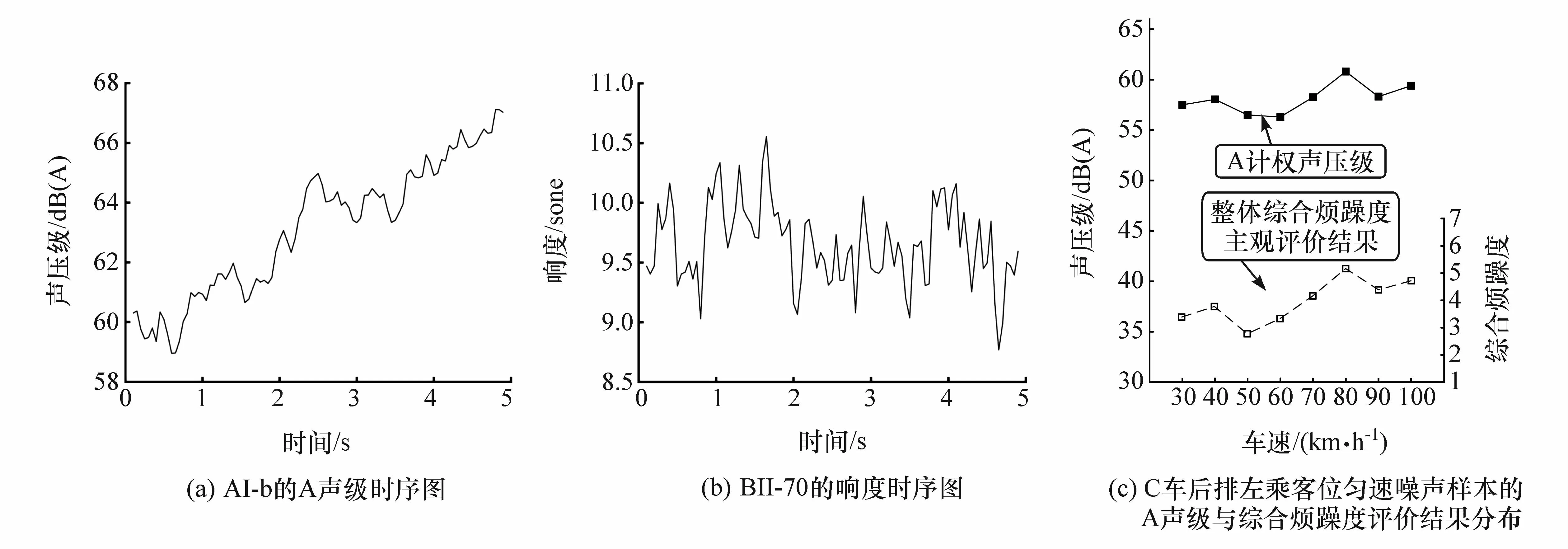
图4 噪声样本声学参量时序图与主观评价结果分布图
2.2 综合烦躁度全局主观评价试验
本文中选择综合烦躁度作为评价指标,参考语义细分法[20]为评价方法,设置描述噪声综合烦躁度主观感受程度的等级评价词,如表1所示。对比噪声样本的心理声学参量值并组织一次语义细分法综合烦躁度预评价,选定CI-60为参考样本,其综合烦躁度为“有些烦躁”。利用Adobe Audition软件将参考样本和各噪声样本分别组合,形成90个试验评价样本。组织由25位高校学生构成的评审团进行听音评价试验,评价人员先听参考样本,对噪声样本听音完毕后,结合参考样本的声品质水平对噪声样本进行评价。将评价人员选择的评价词汇根据表1进行量化,得到其对各样本的整体综合烦躁度评价值。对每个样本的各评价人员评价值取均值,作为评审团对该样本的整体综合烦躁度评价结果。C车后排左乘客位各匀速噪声样本的整体综合烦躁度主观评价结果与A声级对比见图4(c)。
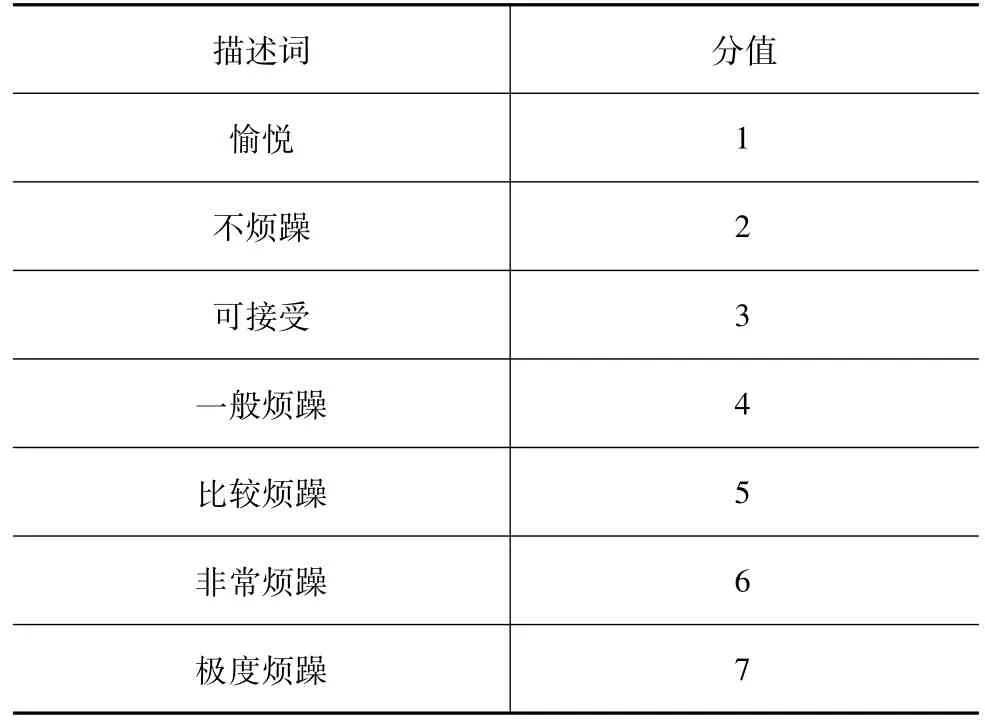
表1 参考语义细分法综合烦躁度等级评价词及分值
3 时序平滑激励级谱声特征提取
3.1 SG平滑滤波器
针对声特征时间序列的波动性,可利用平滑法提取具有时序平滑特性的序列。平滑法是进行时间序列趋势性分析的一种常用方法,利用修匀技术削弱短期随机波动对序列的影响,使序列平滑化。除了移动平均法与指数平滑法,SG滤波器[21]是常用的时间序列平滑技术。在SG滤波器的设计中,阶数与采样窗长是两个重要参数。设p为阶数,一般取 2、3或 4[22-23],2M+1为窗长,可根据待平滑时间序列的长度进行适当设置,且p≤2M。SG滤波器通过构造一个p阶多项式fi,来拟合窗内时序数组{yi|i=-M,…,0,…,M},然后在时间序列上平移,完成对整个时间序列的平滑[24]。其中 fi为
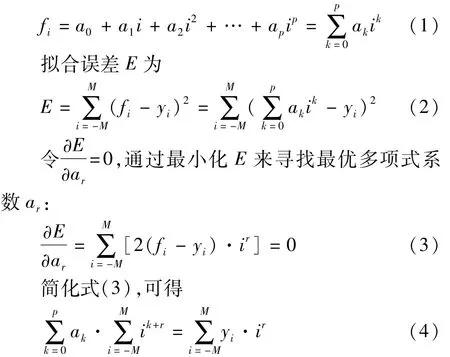
解式(4)得最优系数组合{ar|r=0,1,…,p},可确定多项式fi,完成对数组的平滑拟合。
3.2 激励级谱与时序平滑激励级谱提取
由于CNN能直接识别二维面板特征,本文中提取噪声样本的激励级时频谱,作为建立整体综合烦躁度CNN评价模型的声特征。在Matlab中编制声音信号的激励级谱提取程序:在时域上运用Hanning窗(窗宽800 ms,窗移200 ms)对信号进行分割,按照Zwicker响度模型[6-7]计算每一个子信号的听觉特征频带激励级;时域上取中间连续20个时间区块,频域上取前20个听觉频带,获得尺寸为20×20的噪声样本激励级谱。
在Matlab中设计SG滤波器,阶数设置为3,窗长为41个采样点,对激励级谱进行时域平滑,提取噪声样本的时序平滑激励级谱声特征。AI-a的激励级谱与时序平滑谱分别如图5(a)与图5(b)所示,第2与第4听觉频带的激励级时间序列及其平滑序列分别如图5(c)与图5(d)所示。

图5 噪声样本AI-a的声特征提取
4 车内噪声整体综合烦躁度CNN评价模型
4.1 卷积神经网络
受启发于Hubel-Wiesel生物视觉模型[22],卷积神经网络(CNN)通过顺序堆叠多个卷积— 池化层模拟视神经系统的局部感受野与非线性层次化处理特性[23-25]。具有局部连接、权值共享与降采样特点的CNN,其典型结构见图6,包含5种神经网络层。
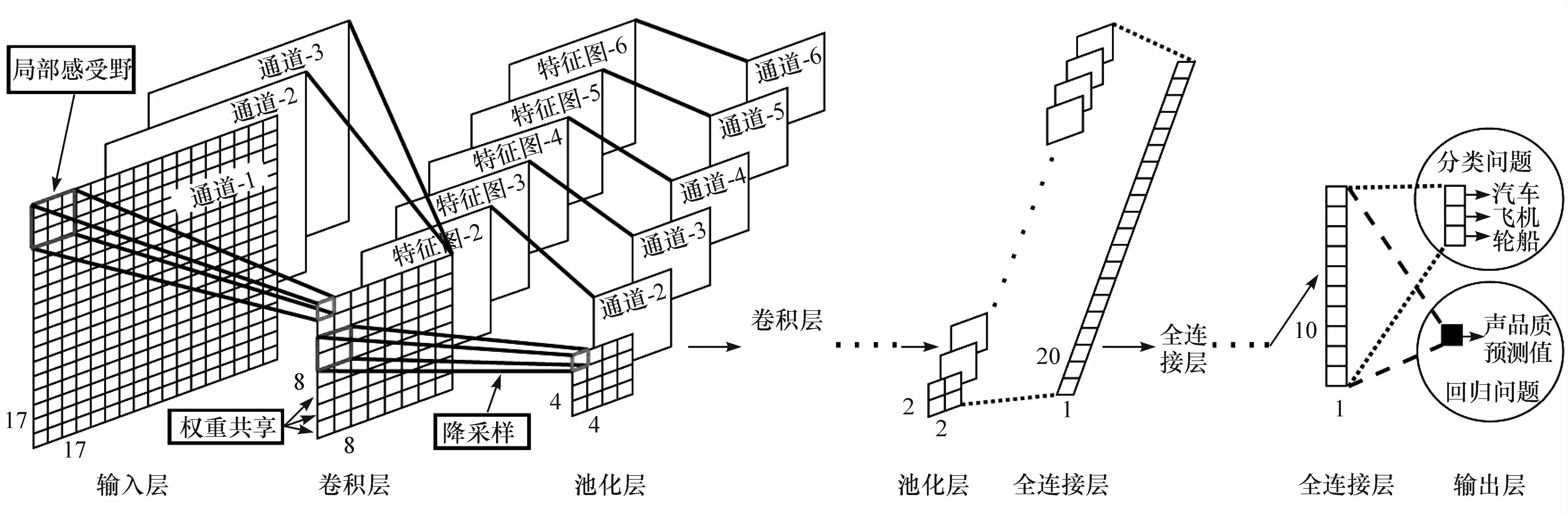
图6 CNN的结构与特点
(1)输入层:可接收单通道(如灰度图像或单通道噪声听觉时频谱)或多通道(双耳语音信号、三通道彩色图像)面板信号。图6所示输入层接收三通道信号,每通道输入信号均是尺寸为17行17列的二维矩阵,则该输入层的尺寸为3@17×17。输入层接收输入信号并传递至卷积层。
(2)卷积层:具有局部感受野特性的卷积层神经元对上一层输出信号进行局部连接加权运算,通过激活函数映射获得该层神经元输出:
y=f(x·w-θ) (5)式中:x为卷积层神经元以局部连接方式接收的输入区域信号;w为该神经元权重矩阵;θ为阈值;f(·)为激活函数;y为神经元输出。
卷积层将层内神经元局部感受野统一为相同大小并排列在有限个相同尺寸的面板上,同一面板上的神经元拥有相同的连接权重矩阵(即权值共享特性,该权重集被称为卷积核),一个面板称为一个特征图。卷积层同一面板上相邻神经元在输入信号上的局部感受野按其在面板上空间次序对应排列,相邻局部感受野在垂直与水平方向上的距离称为步长。通过在输入面板信号高度与宽度方向上的补零操作,卷积层同一面板神经元局部感受野的并集覆盖整个输入信号。图6中第一个卷积层的卷积核尺寸为6@3×3(卷积核个数@神经元感受野尺寸),通过运用尺寸为2×2的步长与0×0补零操作,该卷积层可输出6个尺寸为8×8的特征图(6@8×8)并传递至池化层。
(3)池化层:具有局部感受野特性的池化层神经元对上一层输出特征图进行局部连接加权运算(如最大值或平均值运算,即降采样特性),获得该层神经元输出。池化层将层内神经元局部感受野统一为相同大小并排列在有限个相同尺寸的面板上,面板数量与前一卷积层输出特征图个数相同,并以一一对应的方式接收输出特征图,见图6。常用的降采样运算包括最大池化(max-pooling)和平均池化(average-pooling),池化层采用同一降采样运算对输入信号提取更高阶的相对关系特征,降低特征维度与计算复杂度。图6中第一个池化层包含6个通道,分别对应前一卷积层输出的6个特征图,层内神经元感受野尺寸为2×2,则该池化层可表示为6@2×2。通过运用尺寸为2×2的步长与0×0补零操作,该池化层输出尺寸为6@4×4的特征图并传递至下一层卷积层或全连接层。
(4)全连接层:层内神经元线性排列,每个神经元均连接至前一层所有神经元,按式(5)对前一层输出信号进行接收、处理与计算。
(5)输出层:层内神经元线性排列,每个神经元均连接至最后一层全连接层的所有神经元,并按式(5)对输入信号进行激活输出。输出层神经元个数等于类别个数(分类问题)或响应变量数(回归问题)。
在CNN中,ReLU函数是常用激活函数:

基于小批量随机梯度下降的误差反向传播算法是常用的训练算法,如图7所示。迭代学习过程一直进行,直到满足终止条件(如达到最大训练轮数),输出最优网络权值阈值,CNN训练完毕。在迭代训练中,惯量因子可提高收敛速度并帮助寻优过程越过局部极小。
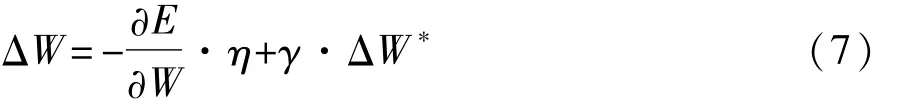
式中:η为学习率;W和ΔW分别为一次迭代过程中网络前向计算使用权值阈值和获得的权值阈值调整量;E为一次迭代中网络前向计算误差;ΔW*为前一次迭代训练中学习到的网络权值阈值调整量;γ为惯量因子。
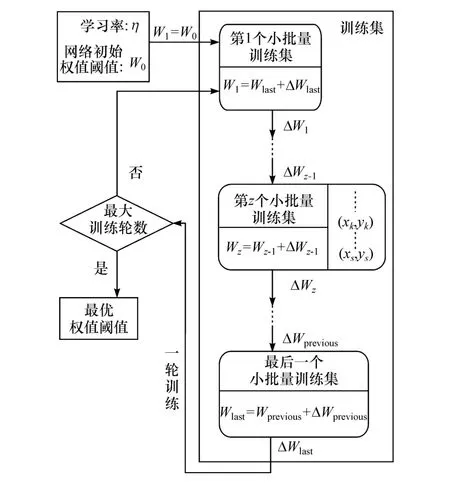
图7 基于小批量随机梯度下降的CNN误差反向传播学习过程
4.2 激励级谱与时序平滑激励级谱CNN评价模型建立
本文中在Matlab平台上构建CNN结构并设置网络学习参数对CNN进行训练,分别建立车内噪声整体综合烦躁度的激励级谱与时序平滑激励级谱CNN评价模型,其采用相同的CNN结构参数,如图8所示,包括一个输入层、两个卷积— 池化组合层(C1-P2与C3-P4)、一个全连接层(FC5)与一个回归输出层。
输入层中输入尺寸设置为1@20×20,以接收尺寸为20×20的二维面板声特征(激励级谱或平滑激励级谱);C1层利用尺寸为6@2×2的卷积核对输入二维声特征进行局部平面域感知与滤波;P2层接收C1层输出的尺寸为6@19×19的特征图,进行核为6@3×1的最大池化操作,并向 C3层输出尺寸为6@7×19的特征图;C3-P4层的卷积核分别为10@3×3与10@2×1并采用最大池化;FC5层利用30个全连接神经元对输入信息进行综合处理,提取高阶特征;包含一个全连接神经元的输出层输出CNN前向计算的综合烦躁度评价结果。卷积层、全连接层与输出层中激活函数均设置为ReLU函数,各层步长、补零及输出特征图尺寸见图8。

图8 车内噪声整体综合烦躁度客观评价模型
设置相同的CNN训练参数:采用基于小批量随机梯度下降的反向传播学习算法来训练CNN,其中小批量训练样本容量设置为12。学习率设置为0.000 7,惯量因子为0.9。在网络可训练参数的初始化方面,初始权重服从均值为0、方差为0.01的高斯分布,初始阈值均设置为0。最大训练轮数终止条件设置为4 000轮。在Matlab中根据训练参数的设置对建立的激励级谱与时序平滑激励级谱CNN评价模型进行训练。
4.3 交叉检验
利用留一法对本文中建立的汽车车内噪声整体综合烦躁度CNN评价模型的性能进行检验。首先,建立训练集与留一测试集,并归一化处理;然后,利用训练集与训练参数对CNN网络进行训练,学习过程如图7所示,分别输出最优化的激励级谱与时序平滑激励级谱CNN评价模型;最后,利用留一测试集检验模型性能,检验项目为整体综合烦躁度主观评价结果与预测结果之间的Pearson线性相关系数(度量预测一致性)、预测误差均值(度量预测精度)与方差(度量预测稳定性),其中相关系数的显著性检验水平设置为0.05。留一法检验结果见表2与图9。
表2中相关系数均高于0.85,p值均小于0.05,说明综合烦躁度主观评价结果与模型预测结果之间一致性较高。但是相比于激励级谱CNN评价模型,基于时序平滑激励级谱的CNN评价模型,其预测误差均值降低10.43%、方差降低44.26%、Pearson相关系数升高4.13%,如图9所示。说明时序平滑激励级谱CNN评价模型的预测精度、稳定性与一致性均有提高,性能高于基于激励级谱的CNN评价模型。车辆噪声声品质瞬时评价研究中的时变声品质主观评价时间序列平滑特性,提高了声品质全局评价中的整体综合烦躁度CNN评价模型的性能,提高了声特征对车内噪声整体综合烦躁度的表达能力,即时序平滑激励级谱的表达能力高于听觉激励级谱。相比于传统常用听觉谱如激励级谱,时序平滑激励级谱是较为优化的声特征,更适于汽车车内噪声整体综合烦躁度的CNN客观评价。
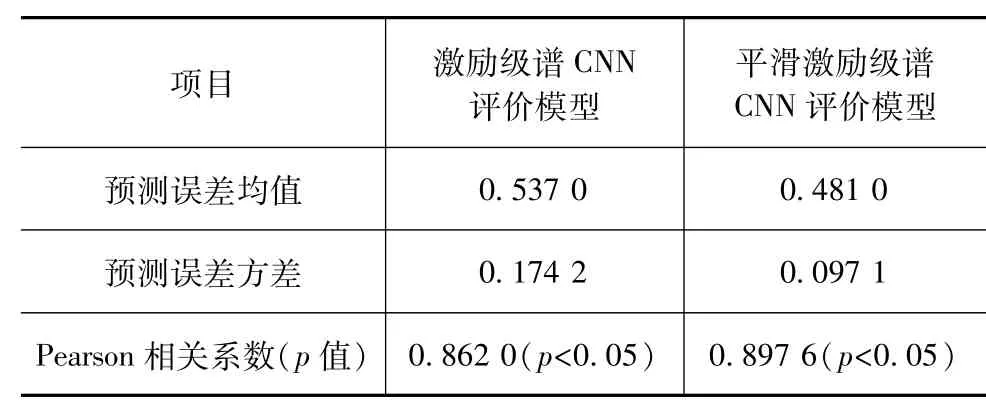
表2 CNN评价模型的留一法检验结果

图9 CNN评价模型的留一法检验结果对比
5 结论
考虑到车辆噪声时变声品质主观评价序列的时序平滑特性,时序波动激励级谱声特征的直接使用会制约汽车车内噪声整体综合烦躁度CNN评价模型的性能。本文中利用SG滤波器提取汽车车内匀速和加速噪声样本的时序平滑激励级谱,利用CNN构建二维面板声特征与整体综合烦躁度主观评价结果之间的映射关系,建立基于时序平滑激励级谱的车内噪声整体综合烦躁度CNN评价模型。留一法交叉检验结果表明,相比于基于激励级谱的CNN评价模型,时序平滑激励级谱CNN评价模型的预测精度、稳定性与一致性更高,性能更好。说明相比于激励级谱等传统常用听觉时频谱,时序平滑听觉谱,如时序平滑激励级谱,是较为优化的声特征,更适于汽车车内噪声整体综合烦躁度的CNN客观评价。
