基于深度学习的行人单目标跟踪
2020-06-28杨勇张轶
杨勇,张轶
(1.四川大学计算机学院,成都610065;2.四川大学视觉合成图形图像技术国家重点实验室,成都610065)
0 引言
行人目标跟踪在无人驾驶、智能监控、智能交通等方面都有重要意义的研究课题,在智能监控,可以通过对行人轨迹实时分析,得到行人相关事件;在智能交通中,可以通过行人轨迹对行人运行方向进行预判,有效地预防交通事故;在人流统计方面,可以通过对行人轨迹分析,实施人流监控等。总之,对任何行人相关分析都离不开对行人轨迹的分析,即要在保证跟踪效果的前提下,提高系统跟踪速度。本文在解决行人跟踪速度的同时提高了系统行人跟踪效果。
1 概述
1.1 行人目标检测概述
在传统算法中,行人检测效果主要取决于特征描述子,如何提取更优的行人特征描述子成为众多学者研究的重点。其中最为突出的当是Dalal 等提出行人HOG 特征描述子是目前广泛使用的行人检测特征描述子,其对光照变化和小量的偏移并不敏感,能有效地刻画出人体的边缘特征[1]。然后训练SVM 分类器或者使用AdaBoost 算法构建级联分类器进行行人检测[2]。在此后也提出了很多基于行人检测的特征描述子,例如Edgelet、边缘模板、LBP 等,都取得了比较好的效果。但是在2012 年ImageNet 图像识别比赛,CNN 网络AlexNet 一举夺得冠军[3],开启了深度学习目标检测的历史新篇章,不断刷新目标识别的检测率,甚至超过人类肉眼的识别水平。相比于传统方法,基于深度学习的目标检测算法能够学习到更好的目标特征,对目标具有更丰富的表达能力,随着深度学习在行人检测方面的应用,也极大地提高了行人检测效果。
1.2 目标跟踪概述
TLD 算法为长时间跟踪算法的经典代表,该算法在当保证效果的前提下基本上能够达到实时,并且是为数不多的长时间跟踪算法,提出了Tracking-By-Detect 方案,在线更新模板,使得算法能够自适应的跟踪目标[4]。陈东岳等人在Mean-shift 算法框架下提出一种基于多特征在线模板更新策略的鲁棒目标跟踪算法,其具有较强的鲁棒性和较高的准确性[5]。相关滤波器相关算法仍是目前传统跟踪算法研究热点,其中最具有代表性的为KCF 算法。KCF 使用目标周围区域的循环矩阵采集正负样本,利用脊回归训练目标检测器,并成功的利用循环矩阵在傅里叶空间可对角化的性质将矩阵的运算转化为向量元素的点乘,大大降低了运算量,使算法满足实时性要求[6]。目前传统跟踪算法中效果较好且跟踪速度能够达到实时的算法为ECO+,其跟踪效果能达到使用深度学习网络跟踪的效果[7]。
随着深度学习的在目标检测的运用,相继探索深度学习在目标跟踪中的运用,DLT 作为第一个将深度网络运用于单目标跟踪的跟踪算法,提出了离线预训练+在线微调的思路,很大程度的解决了跟踪中训练样本不足的问题[8]。FCNT 分析了CNN 不同层的特征特点,得到深度网络高层特征擅长区分不同类别的物体,对目标的形变和遮挡具有较好的鲁棒性,但是对类内物体的区分能力非常差[9]。低层特征更关注目标的局部细节,可以用来区分背景中相似的干扰项,但是对目标的剧烈形变不具备较好的鲁棒性。2016 年Luca Bertinetto 等学者提出SiamFC 网络,一个新颖的全卷积孪生网络,并使用ILSVRC15 数据集进行端到端训练。该算法达到了实时性要求,尽管它非常简单,但在多个benchmark 上达到最优的性能,将深度学习在目标跟踪领域推向一个新的里程碑。此后诸多学者在此网络进行改进,例如Siamese-RPN 将SiamFC 和RPN网络相结合[10],SiamRPN++使用了深层网络,且使用了多层网络特征进行融合[11],均达到不错的跟踪效果。但是其并没有实时更新匹配模板,由于行人不具备刚性条件,或者由于光照等原因,容易导致系统跟踪失败,从而导致算法不容易使用于实际项目中。
2 基于Faster R-CNN和SiamFC网络融合算法的提出
2.1 行人目标跟踪方案分析
目前工程中使用行人单目标跟踪方案基本上可以分为两种:方案一是使用行人识别算法对视频帧进行逐帧检测,然后将行人目标框连接,成为目标轨迹,此方案能够实现目标的长时间跟踪;方案二是使用跟踪算法,在第一帧手动框出行人目标,或者是使用识别算法检测出行人目标,利用跟踪算法对行人进行跟踪,此方案能够实现短时间跟踪目标。
在方案一中检测网络的效果和检测时间成反比,检测算法越复杂,系统能够更好地提取图像特征,则系统检测效果更好,但由于网络比较深,系统参数较多,导致系统检测时间增加,无法进行实时行人目标跟踪。反之,网络的表达能力越弱,则其相应的检测精度就随之下降,则算法容易导致系统行人跟丢。都不容易将算法运用于实际场景。所以要使此方案运用于实际场景,只能增加提高系统的运算能力,增加系统配置。此方案的优点在于能够提取行人目标的深度语义特征,识别能力比较强。但此方案缺点在于逐帧检测,并未利用视频上下文信息,所以不能提高系统检测帧率,且在实时视频目标检测时,使用Faster R-CNN 在使用NVIDIA 1080Ti 显卡平台下,该算法的速度只能达到13fps。且视频图片存在运动模糊等情况,会导致现局部跟踪失败的情况,降低系统的跟踪效率。如图1所示,前两帧图像系统能够正确检测,但是视频中行人存在运动模糊,导致后两帧系统无法检测行人,导致局部跟踪失败。

图1 检测跟踪算法检测成功和失败图
方案二选择跟踪算法实现行人目标,此方案的优点在于跟踪算法结构简单,能够达到实时,但是其缺点为在跟踪过程中,行人目标容易发生形变、被遮挡、或者光照变化等原因,容易导致目标跟丢的情况,并且跟踪失效后无法重新找回目标,从而导致算法失效。如图2 所示,跟踪算法在刚开始能够准的跟踪目标,但是由于行人走至树下,表现为系统光照变化,导致行人目标跟踪失败。且后续模板无法更新,导致系统无法找回目标,跟踪失败。

图2 跟踪算法跟踪失败序列
针对现有行人目标跟踪方案一和方案二的优缺点,利用检测算法在关键帧初始化跟踪网络,降低跟踪网络误差,避免由于视频模糊、光照等使跟踪网络模板失效,导致跟踪失败,利用跟踪网络提取行人目标浅层轮廓特征进行跟踪,提高系统跟踪效率。
2.2 行人检测算法网络介绍
行人检测算法使用Faster R-CNN 网络为twostage 目标检测网络,该网络在R-CNN、Fast R-CNN 网络上逐步改进而提出,在R-CNN 和Fast R-CNN 网络中,网络的大部分时间花销在提取预选框上[12],Faster R-CNN 提出使用网络直接提取预选框的方法。通过引入区域生成网络(RPN)算法提取预选框,减少系统提取预选框的时间,RPN 从一组预先确定的锚点通过网络的分类和回归生成预选框。然后将预选框通过ROI Pooling 得到固定的特征图,通过分类网络将候选框进行分类和回归,得到最终的目标和回归更加精准的目标框。这不仅使检测器更加准确,并且预选框通过RPN 与检测网络的联合训练,可实现端到端训练。即图像一次性即可检测出目标。Faster R-CNN 的网络结构如下,由特征提取网络VGG16[13]、RPN 网络、ROI Pooling 网络[14]和全连接层分类网络构成。

图3 Faster R-CNN网络结构图
特征提取:本文引用VGG16 作为特征提取网络,输入图像缩放到(600×800)通过13 个conv 层,13 个relu 层,和4 个pooling 层,得到系统的高维特征图为输入图像宽和高的1/16,即(38×50)。
RPN 网络:由VGG16 得到的特征层,映射到原图得到候选区域,本文特征尺寸为(38×50),原论文中在选区锚点时使用参数为ratios=[0.5,1,2],scales=[8,16,32]。每个点通过映射得到9 个锚点。在本论文中,由于检测特定行人目标,出于行人形状考虑,本文将ratios 设置为[0.5,0.8,1],使之更加符合行人形状。得到38×50×9=17100 个锚点,通过RPN 网络分类和回归得到前景目标框。其分类损失函数为:
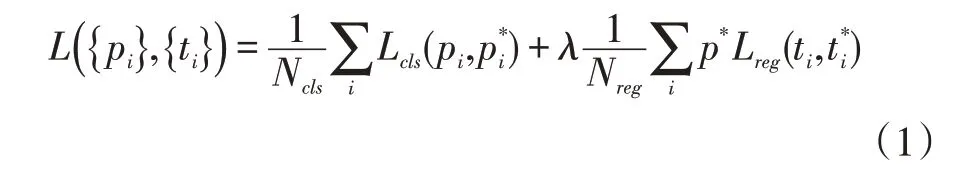
式(1)中Lreg表示的是L1损失函数,其预测的是相对于锚点的偏量:

其中xpredict, ypredict, wpredict, hpredict为网络预测目标框;xanchor,yanchor,wanchor,hanchor为锚点目标框;xtrue,ytrue,wtrue,htrue为真实行人目标框;
式(1)中Lcls为Softmax 损失函数:

其中y 为样本标签,zi为RPN 网络预测类别值;
ROI Pooling 网络:将RPN 得到的候选框在特征层上划分为7×7 的区域,每个区域提取最大值,得到7×7的特征。
全连接层分类:将候选框得到的前景框的前300个目标框进行分类和回归,得到最终的目标框。
本文由于将Faster R-CNN 用于视频目标检测,由于行人目标跟踪视频图像存在模糊情况,检测网络的效果直接决定跟踪的效果,本文在训练行人目标检测网络时,为提高行人检测效果,在训练行人检测目标模型时,使用在城市环境中正常行驶的车辆拍摄的Caltech 数据集,同时也加入了目标跟踪OTB 数据集和视频目标检测数据集VID2015 中的模糊行人数据集,提高了模型的检测能力。
2.3 跟踪网络介绍
SiamFC 网络为2016 年基于孪生网络上改进的用于目标跟踪领域的网络[16],该跟踪器在速度达到实时性要求,虽然网络比较简单,但是在多个benchmark 上达到最优的性能。SiamFC 网络就是初始离线阶段把深度卷积网络看成一个更通用的相似性学习问题,然后在跟踪时对目标进行在线的简单估计。由于网络非常简单,仅仅是学习目标之间的相似性,所以该算法能够达到实时,该网络结构如图4[17]。
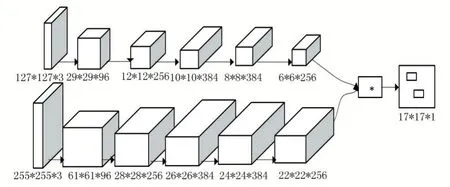
图4 SiamFC网络结构
该算法提出学习一个函数f( x,z )来比较样本图像z 和搜索图像x 的相似性,分别通过相同网络提取模板图像和搜索图像的特征图,用公式φ 表示,如果两个图像特征相似性非常高的图像,则返回较高分,否则返回低分。公式如下:

其中:函数φ 是一个特征提取函数;
函数*为特征的相关性,即为两个图像卷积;
其损失函数为:

其中:l 为逻辑回归损失函数;
D 为网络得到的得分Map,u 为得Map 中的点;
将匹配图片缩放到不同尺度,得到不同尺度下的特征匹配图片Di;

2.4 检测跟踪算法融合
本文为提高系统跟踪速度和质量,提出将目标检测网络和目标跟踪网络自适应融合,利用Faster R-CNN 检测网络在视频关键帧时提取系统深度语义特征,对行人进行检测跟踪。在非关键帧时利用视频前后帧行人目标具有高度相似性,使用SiamFC 提取目标浅层轮廓特征,在当前帧中找到与模板具有高度相似的目标,对行人进行跟踪。由于在对行人进行跟踪时,行人目标形状或者光照等变化,导致跟踪网络SiamFC 模板失效,所以在关键帧使用Faster R-CNN 检测结果对跟踪网络SiamFC 模板进行更新,提高跟踪网络质量。由于跟踪系统输出结果应具有连续性,当在系统判定为跟踪失败时,启动检测和跟踪算法对系统输出结果进行约束,并根据结果及时更新跟踪系统模板。
系统正常跟踪时在关键帧使用Faster R-CNN 检测跟踪,在跟踪失败时才同时启动检测和跟踪网络对跟踪系统进行约束跟踪,Faster R-CNN 由VGG16、PRN以及分类网络构成,SiamFC 网络由5 层简单网络构成,降低了系统的计算量,因此融合方案可将跟踪速度提高至方案一(逐帧使用Faster R-CNN 检测跟踪)的3倍左右。在关键帧或者系统判定为跟踪失败时都会利用Faster R-CNN 检测的行人目标时时更新跟踪网络模板,因此相比于方案二(跟踪网络未更新模板)提高了系统跟踪质量。
算法首先由检测网络检测出行人目标框,并初始化跟踪网络模板,然后使用跟踪网络对目标进行跟踪。以下为视频帧拆开序列算法逻辑图如图5。
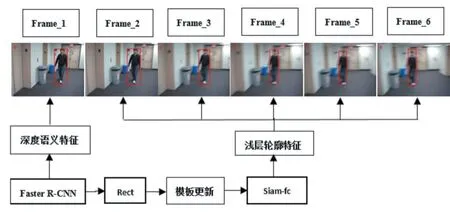
图5 行人检测和跟踪算法逻辑图
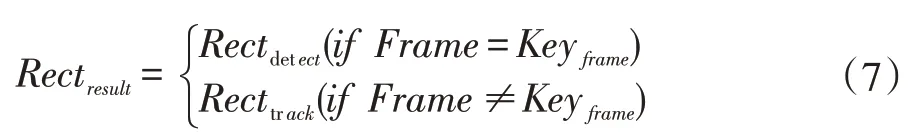
跟踪算法的结果应该具有结构性即每一帧图像内行人最多只出现在一个位置,相邻帧间行人目标运动是连续的,连续帧的位置行人的轨迹可以构成一条较平滑的轨迹。且相邻帧间行人目标框大小变化也具备连续性,不应产生突变,即当前帧中心点到上一帧中心点l2-norm距离以及当前帧和上一帧的IOU(面积重叠度)应该保持在一定范围,超过此范围则视为当前跟踪偏离了行人轨迹,需要使用检测和跟踪算法融合,本文通过目标中心点l2-norm距离以及目标框重叠度对系统检测或者跟踪结果进行约束,保证系统目标的连续性[18]。如果不满足要求则启动检测网络,并将检测和跟踪结果自适应融合。其融合算法:
行人目标框中心点自适应融合算法和公式:

其中:Dis 为前帧行人目标框中心点和当前跟踪行人目标框中心点l2-norm距离;Plast为前帧行人目矩形框中心点;Pdetect为检测行人框中心点;Ptrack为跟踪行人框中心点;DisRatiodetect为检测行人框中心点权重;文中Dis=30 为实验值。
行人目标框宽和高自适应融合算法和公式:

其中:IOU 为前后两帧人框重叠度;Wr为融合后行人框宽度,Wd为跟踪行人框宽度,Wt为检测行人框宽度;Hr为融合后行人框高度,Hd为跟踪行人框高度,Ht为检测行人框高度;IOURatiodetect检测行人框宽、高权重;注:文中参数IOU=0.3 为实验值;
检测和跟踪算法融合流程图如图6 所示。
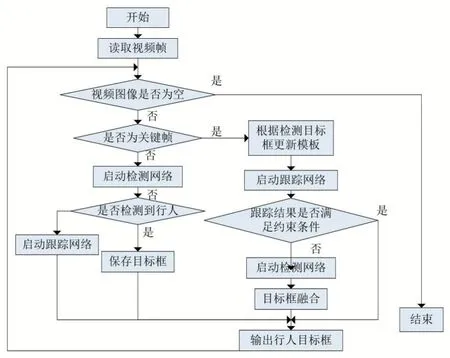
图6 检测和跟踪算法融合流程图
3 算法实验分析
3.1 检测方案和检测跟踪融合算法方案对比分析(在跟踪视频帧中选取特定序列)
如图7 所示仅使用检测算法时,由于视频序列存在模糊情况,使算法无法检测到行人目标,导致目标跟踪局部视频序列跟踪失败,视频序列中第35 帧检测出行人,但是第36 帧,第37 帧并未检测出行人,出现局部跟踪失败情况。如图8 所示使用检测与跟踪算法融合时,当检测失败,启动跟踪算法,跟踪算法利用帧间行人目标相似度,对目标进行跟踪,由于跟踪算法只是提取系统浅层轮廓特征,所以使得行人目标能够很好地进行跟踪,并且在系统判定为跟踪失败时,使用检测和跟踪算法融合,表现出良好的跟踪质量。图9 为视频跟踪结果和标定结果的中心点和重叠度曲线图,蓝色为只使用检测算法系统跟踪质量曲线,红色为使用检测与跟踪算法融合系统跟踪质量曲线,图9a 中为系统跟踪结果的行人目标框中心点与标定行人真实框中点l2-norm距离,其中大于100 以上的均为系统漏检导致,红色为检测跟踪融合算法行人目标框中心点与标定行人真实框中心点l2-norm距离。由实验所得,只使用检测算法进行跟踪时,系统平均l2-norm平均为26,而使用检测和跟踪算法融合时,系统平均l2-norm距离降低为11。图9b 为系统跟踪结果行人目标框和标定行人真实目标框重叠度曲线,其中蓝色重叠度小于0.4 的为使用检测算法时漏检导致跟踪失效,其平均重叠度为0.86,而红色曲线为检测跟踪融合算法重叠度,其平均重叠度为0.92,根据实验证明检测和跟踪算法融合跟踪质量更高,系统跟踪更加稳定。

图7 检测算法结果

图8 跟踪和检测融合算法结果
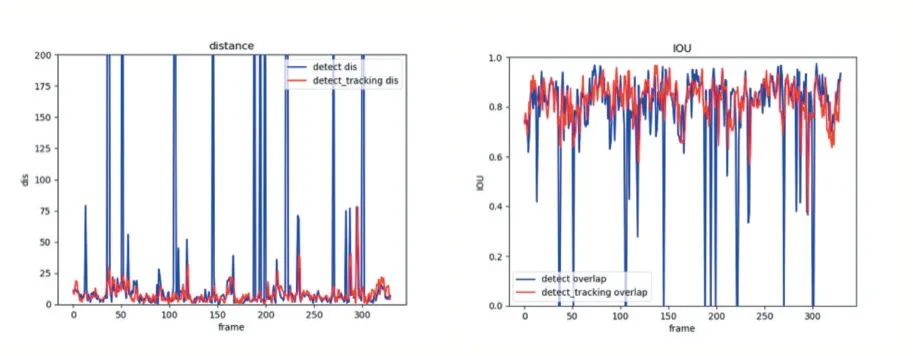
图9 检测和跟踪融合算法和检测算法l2-norm距离和重叠度结果
3.2 检测跟踪融合算法方案和跟踪方案对比分析(在跟踪视频帧中选取特定序列)
如图10 所示,在仅仅使用跟踪算法时,系统由于只使用初始帧作为模板,而由于行人不具备刚性性质,在跟踪过程中容易发生形变,所以出现跟踪丢得情况,如图所示行人目标在第134 帧以后跟丢,并且在后续过程中并未找回目标,跟踪失败。图11 所示为使用检测跟踪算法融合,系统根据跟踪算法结果自适应更新跟踪模板,在系统跟踪失败以后,使用检测网络检测重新初始化跟踪网络模板。图12 为仅使用跟踪网络和使用检测和跟踪网络融合系统跟踪l2-norm距离和重叠度结果比较图,其中蓝色为仅使用跟踪网络结果曲线,红色为检测和跟踪网络融合结果曲线。其中图12a 为算法结果行人目标框和真实行人目标框l2-norm距离,蓝色曲线为跟踪算法结果,蓝色曲线突然上升是因为仅仅使用跟踪网络,系统无法更新匹配模板,由于遮挡导致跟踪失败,其平均l2-norm距离为36,而红色曲线为检测和跟踪算法融合结果曲线,其平均l2-norm距离为3,图12b 为算法结果行人目标框和真实行人目标框重叠度曲线图,其中蓝色重叠度突然下降,为系统由于遮挡导致跟踪失败,其平均重叠度为0.35,而红色为检测和跟踪算法重叠度,其平均重叠度为0.65,根据实验证明检测跟踪算法融合跟踪质量更高,其跟踪效果更加稳定。

图10 跟踪算法结果

图11 检测和跟踪算法融合结果

图12 检测和跟踪算法融合和跟踪算法l2-norm距离和重叠度
3.3 算法结果数据表
表1 为使用相关算法对行人目标进行跟踪得到的重叠度、中心点欧氏距离以及跟踪帧率比较(16 个视频平均数)。
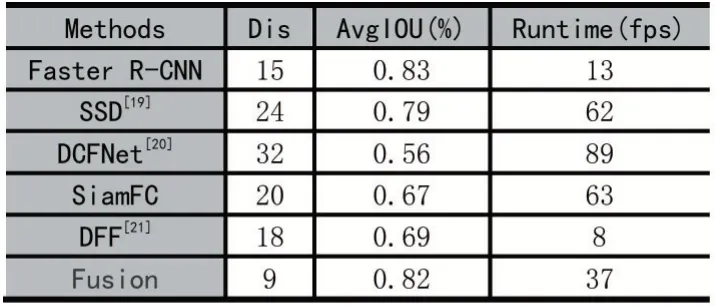
表1 算法跟踪指标
在表1 中,其中Faster R-CNN 算法为对视频逐帧进行检测跟踪,并将检测结果应用于跟踪,该方法优点为除了由于视频模糊等原因导致系统漏检,其余大部分帧能够获得很好的结果,由表中数据可知其l2-norm比较小且重叠度比较高,但是该方案由于使用深度网络提取图片语义特征,算法较为复杂导致系统帧率比较低。其中SSD 和Faster R-CNN 算法思想相同,其帧率比较高但漏检率很高,导致系统跟踪效果不理想。DCFNet 跟踪算法虽然能够时时跟踪模板,但是其模板都是与前帧跟踪结果相关,因为行人不具备刚性,所以容易导致系统跟踪失败。SiamFC 为简单的跟踪算法,其优点是跟踪速度快,但是系统并不能时时更新模板,更新导致系统不能长时间的进行跟踪。在跟踪一段时间以后容易跟丢,导致系统的l2-norm距离比较高,重叠度比较低。DFF(视频目标跟踪)在关键帧使用检测算法,在非关键帧使用光流进行辅助跟踪,由于需要计算光流图,导致系统的跟踪速度比较慢。实验证明检测和跟踪算法融合提高系统的跟踪质量且提高了系统跟踪速度,达到实时跟踪效果,其帧率平均为37fps。
如图13 所示蓝色曲线为真实的行人轨迹,红色曲线为融合算法跟踪轨迹,实验表明检测和跟踪融合算法能够准确的对行人目标进行跟踪。

图13 算法跟踪轨迹图示意图
4 结语
本文充分利用视频序列帧间信息关系,使用检测网络提取视频帧语义特征,在关键帧更新系统跟踪网络模板,由于目标不会突变,在相邻目标保持一致性,使用SiamFC 网络对行人目标进行跟踪,提高系统算法速度。本文在NVIDIA 1080TI 显卡配置下,视频能够达到37fps。同时综合跟踪和检测网络的优点,对两个网络进行融合,提高了系统跟踪质量,但是使用的为1080TI 显卡,后续可以通过改进检测网络,降低检测网络的复杂度,缩短检测时间,从而让系统在更低硬件配置下能够达到实时行人目标跟踪。同时本文并未实现端到端训练,后续可考虑将两个网络融合为一个网络,实现端到端训练。
