基于位置感知的top-k文本检索混合索引框架研究
2020-06-23李梦雪
李梦雪
摘 要:在移动Web搜索中人们希望搜索到的目标对象既满足地理位置相近性,又满足描述文档相关性。由此产生的地理位置和文档相融合的top-k查询既考虑位置邻近性又考虑文本相关性。文章介绍的基于位置感知的top-k文本检索索引,利用倒排文件进行文本检索,R-tree进行空间相近性查询。因此考虑了文本相关性和位置邻近性,并且能够获得top-k查询结果。
关键词:位置感知;top-k;IR-tree;倒排文件
中图分类号:TP391 文献标志码:A 文章编号:2095-2945(2020)19-0010-03
Abstract: In mobile Web search, the target object that people want to search not only satisfies the proximity of geographical location, but also satisfies the relevance of description documents. The resulting top-k query which combines geographic location and document considers both location proximity and text relevance. The location-aware top-k text retrieval index introduced in this paper uses inverted files for text retrieval and R-tree for spatial proximity query. Therefore, text relevance and location proximity are considered, and top-k query results can be obtained.
Keywords: location awareness; top-k; IR-tree; inverted file
前言
移动Web搜索技术的兴起在一定程度上推动传统互联网获取地理空间维度。地理位置和文档的融合使查询能够同时考虑位置邻近性和文本相关性。当今,绝大多数的商业搜索引擎提供基于位置的服务,比如地图服务、本地搜索和本地广告服务等。
本文介绍的一种新的top-k查询,考虑了与关联对象的位置邻近性和文本相关性。该查询的结果是根据排序函数排列的k个对象列表,这些对象与查询位置的距离最近且文本描述与查询短语最相关,这种类型的查询称为位置感知的top-k文本检索(简称LkT)查询。
1 内容简介
本文主要介绍了以下两方面内容:(1)一种索引框架,用于处理基于位置感知的top-k文本检索(LkT)查询。该框架集成了用于文本检索的倒排文件和用于空间相近性查询的R-tree。(2)基于框架,介绍了一种称为IR-tree的索引方法,它本质上是一个扩展了倒排文件的R-tree。
2 问题描述
设D是空间数据库。D中的每一个空间对象定义为一组数对(O.loc,O.doc),其中O.loc是多维空间的位置描述符,O.doc是对象的描述文档。文档O.doc由一个向量表示,其中每个维度对应于文档中的一个不同的项。向量中的项的值由语言模型[1]计算,如下:
其中tf(t,O.doc)表示的是t项在文档中出现的次数,tf(t,Coll)是t项在空间数据库D的文档集合Coll中的计数;tf(t,O.doc)/O.doc是t项在文档O.doc中的极大相似估计值,tf(t,Coll)/Coll是t項在集合Coll中的极大相似估计值,是Jelinek-Mercer平滑方法的一个平滑参数。为了便于理解,tf(t,O.doc)用代表本文运行的例子中t项的权重。
一个位置感知的top-k文本检索(LkT)查询为给定的查询Q在数据库D中检索k个对象,以便它们的位置与Q中指定的位置最接近,它们的文本描述与Q中的关键字最相关。
在形式上给定一个查询Q=(loc,keywords),其中Q.loc是位置描述符,Q.keywords是关键字集合,返回的对象根据排名函数f(D,P(Q.keywords|O.doc))进行排序,其中D是Q和O之间的欧几里得距离,P(Q.keywords|O.doc)是从文档的语言模型产生查询Q.keywords的概率。根据此排名函数计算出k个对象的排序列表能高效地应答LkT查询。其中如下:
本文中排名函数为查询Q中对对象O进行排序的归一化因子的线性插值[2]:
其中∈(0,1)是用来平衡空间邻近性和文本相关性的参数;Q和O之间的欧几里得距离D(Q.loc,O.loc)由maxD归一化,maxD可为D中两个对象之间的最大距离;使用maxP将概率分评分归一化到(0,1)的范围,maxP计算方法为:
使用每个单词的最大语言模型来计算概率值的上限。排名函数计算的分数越低越好。等式(3)中的允许用户在查询时设置文本相关性和位置接近性之间的权重。
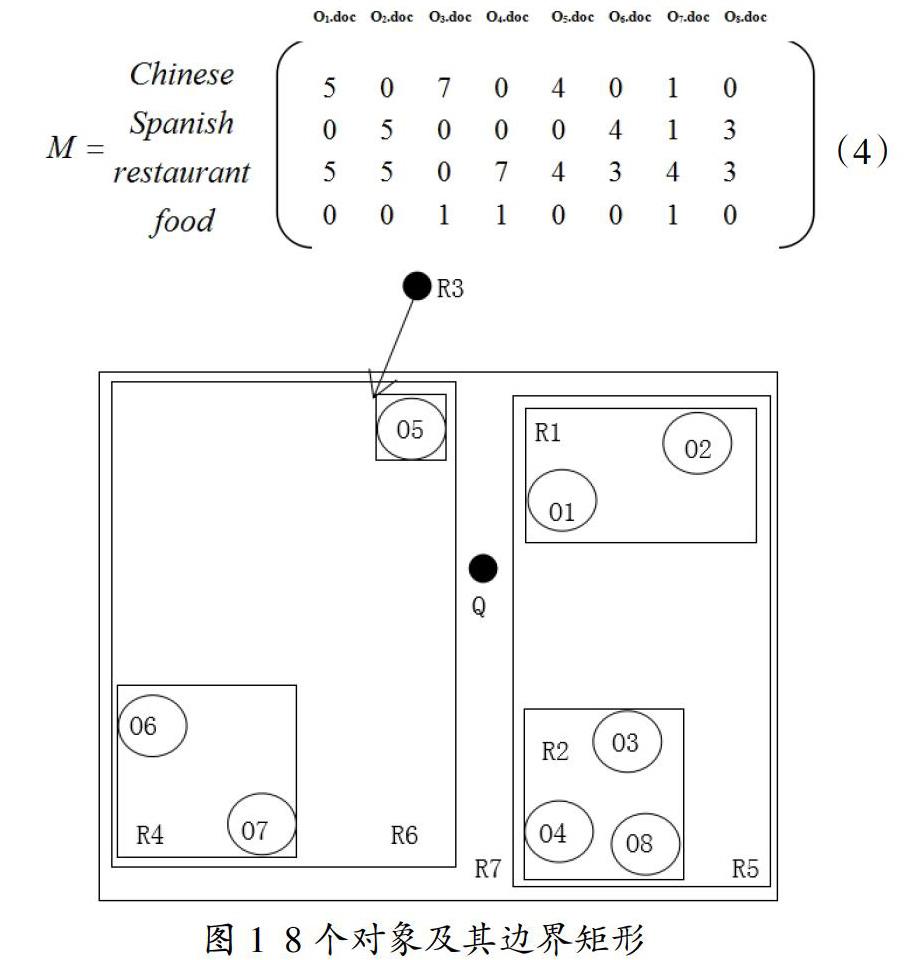
在图1中描述了8个空间对象O1...O8,等式(4)显示了八个对象的文档和词汇的关系矩阵M。在矩阵中,行和列分别表示词汇和文档。例如,矩阵显示了文档O1.doc包含了“Chineses”词汇5次和“restaurant”这个词5次。
给定一个具有位置信息Q.loc的查询Q,如图1所示,Q.keywords=(Chinese restaurant),对象O1是根据公式(4)(=0.3)得到的top-1查询的结果。
3 现有方案处理LkT查询
仅倒排文件(IFO)和R-tree+倒排文件(RIF)两种方案。
3.1 仅倒排文件(IFO)
其思想是利用倒排文件對所有对象的文本相关度得分(对应于公式(3)中运算符“+”的右操作数)进行计算,获得一个排序列表,按分数的升序排列。然后扫描列表,计算查询的空间接近程度,直到进一步扫描不会生成top-k结果。该算法只使用倒排文件。
该方案需要解决的问题是何时停止扫描。在扫描过程中,该算法保持对组合排序分数的跟踪(在公式(3)中定义,分数越低越好)。当前第k个对象的排序分数用阈值来表示,对于一个新对象T,如果它的倒排序分值大于阈值,算法将会停止,因为T之后所有对象在倒排序列中的得分将会超过阈值的分数;否则,继续检索,计算新的排序分数,并与阈值进行比较,确定阈值是否需要更新。
3.2 R-tree+倒排文件(RIF)
该算法分两个阶段使用R-tree和倒排文件。倒排文件用于计算IFO的列表不排序。然后使用R-tree递增地查找最近的邻接节点[3],并检查无序排序中对象的文本相关性分数。
在此过程中,算法对倒排序列中最小的文本相关度分数(MinTR)进行跟踪,对当前第k个对象的组合排序分数(公式(3))进行跟踪,用阈值表示。
对于空间距离为dist的新对象,如果从dist和当前 MinTR计算的组合分数超过阈值,算法停止,因为它保证所有“未见”对象的分数不会低于当前第k个对象。
4 基于位置感知的top-k文本检索混合索引框架(IR-tree)
该框架将R-tree和倒排文件集成到一个新的索引中,即倒排文件R-tree(IR-tree),其中包括一个使用IR-tree处理LkT查询的算法。
R-tree[4]是空间查询的主要索引,而倒排文件是文本信息检索[5]的最有效索引。它们是被分别开发的,用于不同类型的查询。
利用这两个技术来开发一种有效处理LkT查询的方法。要实现这个目标,一种简单的方法是使用倒排文件生成许多基于文本相关性的候选对象,然后使用其他索引计算候选对象的空间距离。但是,这种方法效率并不好,因为没有一种合理的方法来确定第一步所需的候选对象数量,以确保最后找到top-k对象。IR-tree混合索引结构,以一种组合的方式使用这两种索引结构。
IR-tree混合索引:
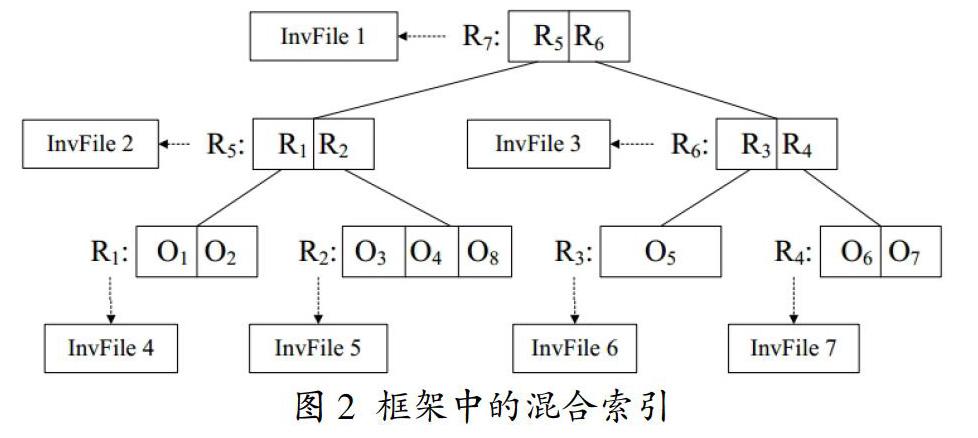
IR-tree本质上是一个R-tree,其中的每个节点都通过位于节点的子树中包含的对象的倒排文件进行充实。在IR-tree中,叶子节点N包含若干个(O,rectangle,O.di)形式的记录,其中O是指数据库D中一个对象,rectangle是对象O的边界矩形,O.di是对象O的文档标识符。叶子节点也包含一个指向被索引对象的文本文档的倒排文件的指针。
(1)倒排文件
倒排文件由两部分组成。
a.在文档集合中所有不同术语的词汇表。
b.一组发布列表,每一个都与术语t相关。每个发布列表都是一系列的数对
非叶节点R包含表单(cp, rectangle, cp.di)的若干记录,其中cp是R的子节点的地址,rectangle是子节点记录中所有矩形的最小边界矩形,cp.di是伪文档标识符。
伪文档是混合索引结构中的一个重要概念。它代表所有子节点记录中的所有文件,使我们能够评估一个根植于cp的子树所包含的所有文档的文本相关性查询的范围。被cp.di 引用的每一个伪文档中的t的权值是根植于cp的子树所包含的文档相应权值的最大值。
(2)IR-tree混合索引实例
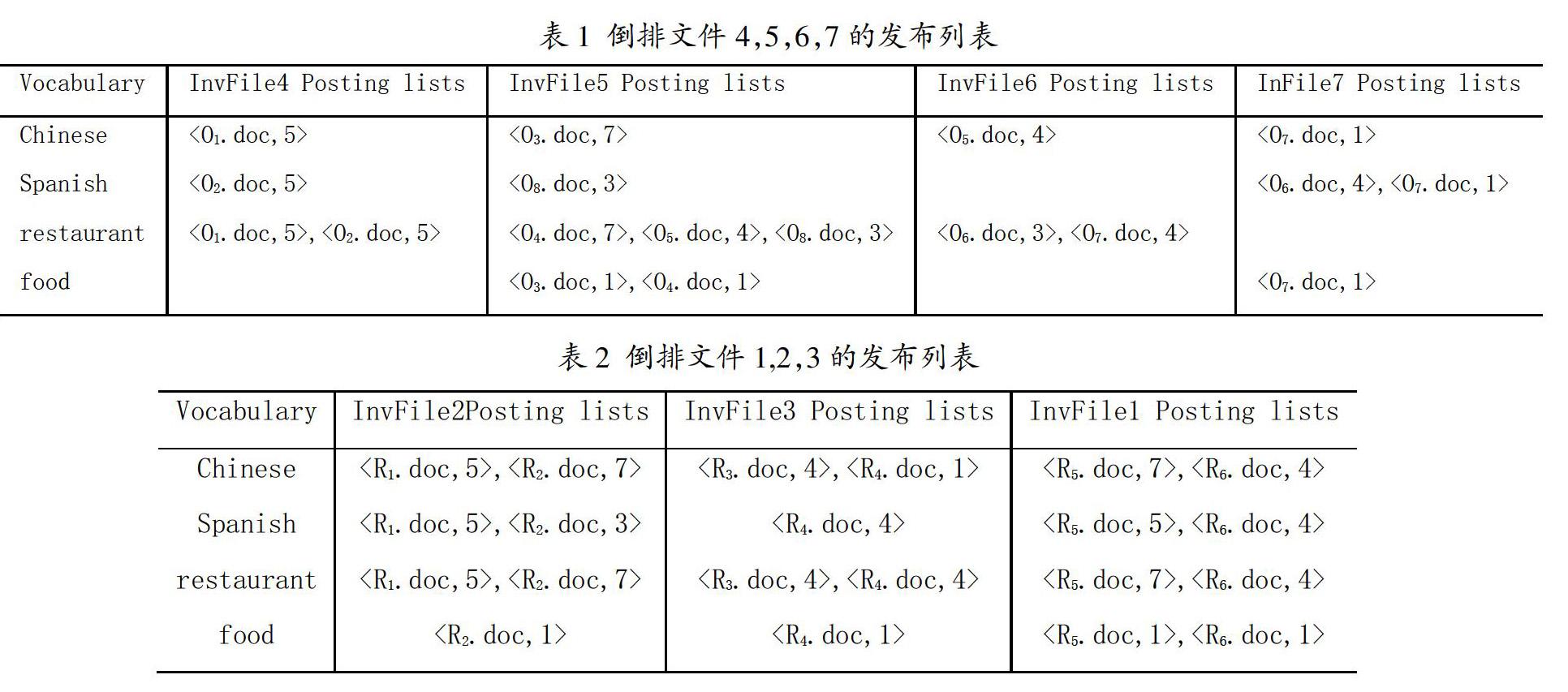
图2演示了图1中8个对象的混合索引。表1显示了叶节点的倒排文件(图2中的InvFile 4、InvFile 5、InvFile 6和InvFile 7)。表2显示的是非叶节点的倒排文件内容(如图2所示的InvFile1,InvFile2,InvFile3)。例如restaurant一词在节点R5的记录R2中的权值是7,这是这个词在节点R2三个文档(O3,O4,O8)中的最大的权值。
(3)最小空间-文本距离MINDST
最小空间-文本距离MINDST是用于查询处理的重要度量。在混合索引中给定一个查询Q和节点N,度量MINDST在查询Q和位于节点N的矩形内的对象之间给实际空间-文本距离提供了一个下限值。该边界值可用于排序和有效地修剪混合索引中的搜索空间路径。
定义1.混合索引中查询点Q与节点N的距离,表示为MINDST(Q,N),定义如下:
其中,maxD和maxP与公式(3)中的是一样的;
在公式(2)中把O.doc替换为N.doc(节点N的伪文档)可以计算出P(Q.keywords|N.doc); MIND(Q.loc,N.rectangle)是Q.loc和N.rectangle之间的最小欧几里得距离。
提出的混合索引结构的一个显著特征是,在查询处理方面继承了R-tree的良好属性。
定理3.1:给定一个查询点Q和一个节点N,其矩形包含一组对象SO={Oi,1im},则下面的式子成立:
证明:由于对象O包含在节点N的矩形中,所以Q.loc和N.rectangle之间的最小欧几里得距离不大于Q.loc和O.loc之间的欧几里得距离:
对每一项t,N.doc.t(在N.doc中的项的权值,它是节点N的伪文档)是节点N中所有文档的值中的最大值。因此:
根据等式(3)和(5)可以得到:MINDST(Q,N)DST(Q,O),因此完成了证明。
当搜索与查询Q最接近的k个对象的混合索引时,必须在混合索引的每个访问节点上决定首先搜索哪个记录。度量MINDST提供了到节点中每个记录的距离近似值,因此可以用于指导搜索。只有在查询Q中的关键字的发布列表,而不是所有的发布列表,才被加载到节点的内存中加以计算MINDST。
5 结束语
本文中用于处理LkT查询的IR-tree混合索引框架集成了传统的R-tree和倒排文件,R-tree是空间查询的主要索引,倒排文件是文本检索最有效索引。同时利用MINDST度量对空间文本距离进行剪枝,最终得到符合条件的top-k结果。以此为依托可以进一步开发剪枝算法来优化查询结果。
参考文献:
[1]J.M.Ponte and W.B.Croft. A language modeling approach to information retrieval.In SIGIR,1998:275-281.
[2]B.Martins,M.J.Silva, and L.Andrade.Indexing and ranking in geo-IR systems.In GIR,2005:31-34.
[3]G.R.Hjaltason and H.Samet.Distance browsing in spatial databases. ACM Trans.Database Syst.1999,24(2):265-318.
[4]A.Guttman.R-trees: a dynamic index structure for spatial searching.In SIGMOD,1984:47-57.
[5]J.Zobel and A.Moffat. Inverted fifiles for text search engines.ACM Comput.Surv.2006,38(2):56.
