SRGM下失效数据集效用与验证分析*
2020-06-22伊文敏徐早辉高天翼王瞰宇苏嘉尧
张 策,伊文敏,白 睿,盛 晟,徐早辉,高天翼,王瞰宇,苏嘉尧
(1.哈尔滨工业大学(威海)计算机科学与技术学院,山东 威海 264209;2.61660部队,北京 100089)
1 引言
软件可靠性增长模型SRGM(Software Reliability Growth Model)已成为度量与预测可靠性,管控成本支出,以及进行系统发布等研究的重要技术与工具[1 - 3],已有超过35年的研究和实践历史。现有SRGM研究是建立在一定假设基础之上,以最为流行的非齐次泊松(分布)过程NHPP(Non-Homogeneous Poisson Process)为例:(1)软件失效满足NHPP;(2)(t,t+Δt)内检测的故障数量与t时刻软件中剩余未被发现的故障成比例等。
自1979年Goel与Okumoto[4]提出最为经典同时影响力也最为深远广泛的G-O模型以来,SRGM研究持续得到了关注。对不同SRGMs的性能评价主要是基于公开发表的失效数据集FDS(Failure Data Set)进行验证来实现的,SRGM的性能优劣很大程度上依赖于所收集的失效数据质量[5]。显然,FDS对SRGMs的验证和发展发挥着至关重要的作用,不可替代。
整体而言,SRGM研究中较多的科学问题已被解决,但FDS却一直停留在由世界知名公司发布上,很长时间内停滞不前,这极大地制约了SRGM的深入发展。与已有的成百上千的SRGMs形成鲜明对比的是,迄今为止,对FDS本身及其在SRGM研究中的作用和影响的研究在国内外尚未见报道。在我们的前述研究中,针对不同SRGMs性能差异的根源给出了客观上FDS的不同和主观上所建立的数学模型的不同二者共同作用的结果。本文在作者前期工作基础上[6 - 8],对FDS及其对SRGM的影响进行分析与评述,期望通过本文的工作能为促进FDS与SRGM的发展做出贡献。
2 基于FDS的SRGM建模及效用分析
2.1 基于FDS的SRGM研究体系
应用SRGM进行可靠性分析是对可靠性进行建模和评测的主要手段,图1给出了科研人员基于对测试过程的认知下进行SRGM建模的基本流程以及SRGM的效用。
Ahmad等[5]认为SRGM的成功极大地取决于所收集到的FDS质量。由图1可以看出,若无公开发表的FDS,SRGMs的性能验证就无从着手。测试人员根据测试策略的安排,可以采用黑盒、白盒、回归、压力等测试方法来检测到失效的发生,确定故障的根源。科研人员通过对测试过程的建模,得到[0,t]内累积检测的故障数量m(t),并利用真实的FDS进行验证。建模中,通常自行设定软件中总故障个数a(t)的表达式,以及故障检测率b(t)等。需要指出,建模时研究人员对软件测试过程所做假设上的差异是不同SRGMs存在区别的根本原因,这种差异导致最终求解得到的m(t)表达式存在巨大差异。
2.2 不完美排错模型相关的FDS结构化描述、分类与效用分析
SRGM研究的基础是需要有FDS的支持,SRGMs性能优劣的验证也是基于FDS。通常而言,FDS由国际上著名的(软件)公司来发布。四十多年来,在这些数据集的支持下,已经有超过上百个SRGMs被相继开发出来,极大地丰富了软件可靠性工程的研究。事实上,与其名称不相一致的是,FDS不仅仅包含失效个数(即累积检测的故障数量),还包括累积修复的故障数量、测试工作量TE(Testing-Effort)消耗情况,甚至故障类型等信息。
FDS={fd1,fd2,…,fdk},k为失效数据个数,fdi(1≤i≤k)为失效数据子集,其可被抽象为下面的四元组形式:
fdi={ti,N(ti),TE(ti),C(ti)}
(1)
其中,ti表示测试时间,可以是日历时间、时钟时间、CPU时间和执行时间[9],但多以日历时间作为故障检测与修复的时间周期[10],通常以周为单位;N(ti)为截止ti时累积检测到的故障数量;TE(ti)为[0,ti]内消耗的测试工作量TE,用测试工作量函数TEF(Testing-Effort Function)来表示[11],TE消耗曲线存在多种函数形式;C(ti)为截止ti时累积修复的故障数量。需要指出,有些FDS中并不包含TE(ti)和C(ti)。典型地,在Ohba-Chou模型[12]基础上,这里将其修改为更一般性的不完美排错框架模型:
(2)

Figure 1 FDS release and SRGM performance evaluation process图1 FDS发布与SRGM性能评测过程
第1个子式考虑到了测试工作量TE的消耗,即W(t):

(3)
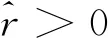
第2个子式假设(t,t+Δt)内引入的故障数量与检测的故障数量成比例,比例系数为r(t),a(t)为全部故障数量。在m(0)=0,a(t)=a的初始条件下,可求得m(t)和a(t):
(4)
(5)
其中b(t),r(t)作为参函数变量可以根据实际进行设定;w(t)作为TE的消耗率可为Logistic、Weibull等函数形式。a(t)虽难以直接验证,但却可用以指导测试中对总故障的估算,为可能的测试成本花销提供决策辅助。基于求得的m(t),可求得失效率λ(t)为:
(6)
模型的有效性需要验证得到的W(t)与m(t)同真实的FDS中TE(t)与N(t)的拟合及预测性能,即:
SRGMPerformanceonFDS=

(7)

SRGM的性能优劣很大程度上依赖于所收集的失效数据质量[5],由于不同公司在不同测试过程中的各种因素制约,这些数据集相互之间的差异较大。数据集可以有多重分类:(1)以顺序/非顺序时间为线索记录失效故障数量[13,14];(2)以顺序失效个数为线索记录失效时间[17];(3)含有TE的[13,14]与不含有TE的[17,24];(4)以标准化的失效时间和标准化的累积失效个数作为记录线索[22]。图2给出了8个FDSs的情况,横坐标是测试时间,多以周为单位,纵坐标是累积检测到的失效个数,由于通常认为一个失效是由一个故障导致的,因此也被称作累积检测到的故障数量。
(1)现有FDS多以二十几周的测试数据为主。
(2)从形状来看多以指数型增长(例如DS2,DS6,DS8~DS13)和S型增长(例如DS7)为主,尤其是指数型,这为建立SRGM提供了基准,也使得目前的SRGMs主要以此2种增长形状及其演变为主。例如,最早提出的经典G-O模型即为指数型曲线,其后各种SRGMs也均以指数型为常见。
(3)当前众多SRGMs在本质上都可以归属到上述2大类模型。
至此,可以得知FDS效用主要是指FDS的结构组成与类型、所包含的失效数据变化趋势,以及FDS对SRGM性能的影响。SRGM的建立源于对FDS蕴含测试过程的认知,其性能依赖于FDS进行验证,由于可靠性模型与FDS均存在不同类型,这使得FDS对模型的影响客观存在。
3 FDS对SRGM性能验证过程分析
3.1 参与比较的模型及FDS
不完美排错就是不断放宽传统完美排错中假设的条件,使之考虑的实际因素越来越靠近真实情况。鉴于不完美排错更加真实地描述了实际的测试过程,这里选择7个典型的不完美排错相关的SRGMs在9个数据集DS2,DS6~DS13上进行验证,结果如表2所示。这些数据集来源于多方,类型与特征也有所差异,考虑到数据集记录数据的规模量,以及模型在失效数据集上进行验证的计算复杂度,特别是实验结果便于观察分析等,这里对数据集进行了遴选,去除了5个数据集。例如,DS3的TE数值过小引发计算复杂度剧烈上升,性能结果不适宜直接对比;DS14记录时间的数值过大,使得难以直接用于验证模型有效性;DS5记录的失效故障数量过大;DS1与DS4故障数据记录缺少清晰的变化走势,使得模型拟合与预测结果不直观等。为此,我们综合选取了9个更为典型常用的数据集,这9个数据集均是由知名的计算机或软件公司发布的,已被广泛用来分析SRGMs的性能。

Table 1 FDS case selection from real computer engineering表1 源自真实计算机工程的FDS案例遴选

Figure 2 Eight FDSs图2 8个FDS
3.2 性能验证:拟合度量与预测分析
SRGM的性能度量主要从2个方面来实施:拟合过往的失效情况和预测未来失效情况。首先,基于此9个数据集,进行参数估计,图3给出了7个模型的m(t)与真实失效数据的拟合情况。
模型与真实的FDS越接近越重合表明拟合性能越好。从图3可以看出,除了图3i中7个模型与DS13拟合较好外,在其余8个FDSs上,均出现有部分模型与FDS偏差较大的情形。如前所述,当前多以指数型的FDS为主,S型的FDS则较少,因而被提出的SRGMs也多以指数型的m(t)形式为主。在FDS类型与m(t)的拟合匹配上,从图3中可以看出下面3种情况:
(1)S型的FDS与指数型的m(t)拟合偏差较大:在图3c的DS7中,FDS呈现S型的弯曲式增长,表2中的m(t)模型绝大部分是指数型的,这使得如下事实得以出现:除了图3c以外的8个图中只有1~2个模型与真实的FDS偏差较大外,其余模型均拟合较好;相反,在图3c中,则出现了多个模型在整个测试周期内均与真实的FDS偏差较大的情况。
(2)除图3c外,其余8个FDSs均呈现指数型的增长,其中又分为:①除图3h中DS13以外,其余7个FDSs呈现出“凸式”增长形状:这其中,除了M1:Y-Exp模型拟合偏差较大外,其余6个模型拟合较好。其原因在于,M1的m(t)曲线是“凹式”增长形状,与这些“凸式”增长的FDS不相符;②图3h中DS13出现“凹式”增长形状,这使得M1的m(t)拟合效果较好。

Table 2 SRGMs associated with typical imperfect debugging in comparison and FDS for validation表2 参与比较的典型不完美排错相关的SRGMs及用于验证的FDS

Figure 3 Fitting curves of 7 models on 9 data sets图3 7个模型在9个数据集上的拟合曲线
(3)开发出具有“柔韧型”能够适用指数型与S型FDS的SRGM是未来研究的重要方向。
占有多数情况的指数型FDS为指数型的SRGM验证提供了良好的数据基础,这也解释了众多SRGMs中呈现指数形式的m(t)性能表现较好的根本原因。
在对未来失效数据的预测上,模型的相对误差RE(Relative Error)曲线如图4所示,RE曲线越快趋近于0表明预测性能越好。在数学上,由于拟合的本质是尽量靠近目标曲线,因而不同模型的m(t)与真实的失效数据差别不大;但在预测上,在很多数据集上,部分模型的预测能力已经严重偏离中心水平线,表明出现了很大偏差。造成这种现象的原因包括两个方面,既有对排错过程所建立模型的不同,同时也可能是由于数据集本身失效数据间差异较大的缘故。

Figure 4 RE prediction curves of 7 models on 9 data sets图4 7个模型在9个数据集上的RE预测曲线
(1)随着测试的进行,特别是从测试时间后半程开始,9个数据集上均存在一部分模型能够较快地向0曲线进行收敛而逐渐趋向稳定,表明这些模型具有较好的预测性能。例如,在图4a的DS2上,M6,M3,M4,M5实现了较为快速地向0曲线靠近;这部分模型还包括在图4b DS6上的M3,M4,M5,M6;在图4c DS7上的M3,M7,M4,M5;在图4d DS8上的M3,M2,M5,M6;在图4e DS9上的M3,M2,M4,M7;在图4f DS10上的M3,M6,M4,M2;在图4g DS11上的M3,M4,M7,M5;在图4h DS12上的M3,M1,M6,M5;在图4i DS13上的M3,M4,M2,M7。这不仅是由于数据集中失效数据的增多带来拟合结果的准确性提升,同时也表明这些模型较好地描述了真实的测试过程,因而对未来的预测更为准确。
(2)通常,在指定数据集上拟合性能较差的模型,其预测性能也相对不足,反之亦然。例如,M1:Y-Exp在DS2、DS6~DS11上预测性能并不理想,其在这些数据集上的拟合曲线严重偏离真实的失效数据曲线,拟合性能较差;其在DS12和DS13上的拟合性能较好,相应的预测性能也很理想。
(3)Huang等[30]明确指出,不存在一个能够适应全部数据集的模型——这一点从上述对图4的分析中可以看出,7个模型在9个失效数据集上的预测性能并不稳定,即并不存在某个模型的预测性能在所有9个失效数据集上均表现为最优。例如,M1在DS2,DS6,DS7,DS8,DS9,DS10和DS11上均发生较大偏差,其预测曲线没能快速趋近于0;M2在DS2,DS6,DS7,DS11和DS12上表现欠佳;M3在DS1上,M4在DS8和DS11上,M5在DS9,DS10和DS13上,M6在DS7,DS9,DS11和DS13上,M7在DS2,DS6,DS8,DS10和DS12上均不理想。因此,模型的性能存在局部性,无法适应不同类型的FDS。
性能优异的SRGMs在本质上刻画的m(t)与真实的失效数据曲线在走势上相一致;相反,部分模型由于建立时缺乏必要的合理性以及FDS中数据收集与记录的随机化,使得模型的性能表现出现偏差。
4 当前FDS存在的不足与建议
4.1 FDS存在的不足分析
如前所述,当前FDS在SRGM的研究中主要是参数拟合、度量和预测,除此之外,对FDS的利用很难看到。当前关于FDS的不足表现在2个大的方面:
(1)FDS发布方——测试过程信息过于单一。
①首要的不足是缺少最新的FDS,现有的FDSs主要是20世纪70年代至21世纪初发布的,进入21世纪以来鲜有新的FDS发布,这使得很多SRGMs难有被充分验证的机会。
②现有的FDSs包含的失效数据数量较少,一般以周为单位,多在20周左右,这使得含有参数较多的SRGMs在拟合与预测性能上有所不足。
④缺少以构件软件CBS(Component-Based Software)为对象的失效信息,这使得构件软件可靠性增长模型CBSRGM一直发展滞后,鲜有提出。
⑤此外针对流行的软件形式,例如面向服务的软件SOS(Service-Oriented Software)、网构软件等至今也没有公开的FDS被发布。
(2)研究人员——对FDS的利用不充分。
①目前FDS只用来进行参数拟合和性能的评测(包括拟合与预测),失效信息利用得并不充分。
②SRGMs验证结果并未对FDS的收集、记录与发布以及测试过程提出指导意见。例如,当前研究认为故障修复时间服从指数分布,但实际的故障修复时间是否如此,各大公司并未进行确认。
③软件发布后的操作运行阶段中的失效信息不足,导致对运行阶段的可靠性建模、评测与提高缺乏必要的数据集支撑,留下了研究的“真空”。
可见,若公开发表的FDS中包含更多更全面的信息,则会促使研究人员在建模中所建立的数学模型更为“细腻”,也便于在验证环节中将求解得到的数值与真实的信息进行比较,更能刻画比较出SRGMs与真实测试过程的逼近情况。
4.2 FDS发布建议
文献[31]中指出,对可靠性信心的增强与软件测试的次数紧密相关。FDS在当前的SRGM研究中主要承担基础性的性能验证作用,我们建议,在不泄露项目与公司机密的情况下,鼓励软件公司发布更多的测试信息。
(1)应丰富FDS的信息种类,FDS中应明确包含反映测试环境、测试策略、测试人员技能、软件自身的结构特征、多种故障类型等信息。
①要充分挖掘FDS中隐藏的关于测试策略以及涉及到各类故障数量与可靠性的深层次关系。
②要增大FDS中失效数据的数量,使得SRGMs能有更为长远的性能表示趋势,也使含有较多参数的SRGMs性能能够充分地体现出来。
③当前所发布的众多FDSs中均没有任何关于CP的信息:当前研究中,Huang等[31,32]采用c图来确定CP位置,利用拉普拉斯趋势曲线分析SRGM的增长情况;Shyur[33]则认为,测试过程中测试环境的改变是人为主动引发的,因而CP的位置是已知的,或采用目估法来确定CP的位置。但是,在公布的FDSs中却没有直接告知CP的存在(可能由测试人员技能的提高,新测试技术与工具的引入,甚至软件中总故障个数等引发CP的出现)。显然,若FDS中告知CP信息,则会促使SRGM的建模能直接体现出CP的存在,使得所建立的数学模型(微分方程(组))更为准确。
(2)对于大型复杂的软件系统,其测试过程是一个时间跨度较长且较为随机与复杂的过程,采取有效的测试信息记录机制,则会形成规模庞大的数据信息,这些近似于“大数据”的信息更能反映测试过程中潜在的内在机制与机理。
①若FDS中包含除累积检测的失效数量以外的更多信息,例如,修复(改正/排除)、引入等信息,则研究人员所建立的模型在验证中就会有更多参照比较的对象,使得SRGM研究能够突破现有相对较为单一的建模思维,可支持更多个描述不同测试要点的方程(组)。
②大规模的数据中隐藏着各种测试机理信息,这为大数据理论与技术的运用提供了条件。当前IT(Information Technology)已进入到以数据为中心的DT(Data Technology)时代,因此应加大FDSs的收集力度,提倡有大量数据支撑的相对复杂的模型。
③实际的测试过程中具有较强的随机性,需要多参数来描述以求准确与全面。多参数虽使模型变得复杂,但现有的优秀数值处理软件能够解决由此带来的复杂求解问题。
5 结束语
当前用以验证SRGM的FDS主要是于20世纪发布的,进入21世纪,软件自身的形态以及软件工程都发生了很大的变化,反映这种变化的FDS也极为少见,例如网构软件、面向服务的软件等,这已成为制约了SRGM发展的主要客观事实。此外,至今为止,也仅有一份CBS的FDS,且并不完整,尚不足以支撑构件软件可靠性增长模型CBSRGM的研究。虽然采用离散事件仿真的方法可以模拟(构件)软件的测试过程,进而获得FDS,但由于仿真之初做了较为苛刻的假设,使得所获得的数据集与实际软件系统测试过程中的真实情况差距较大。我们建议更新更多包含更多测试信息的FDSs能够发布,这样才能确保SRGM得到充分验证。
