基于区域卷积神经网络模型的广西柑橘病虫害识别方法研究
2020-06-22温国泉王筱东
苏 鸿,温国泉,谢 玮,韦 幂,王筱东
(1.数字广西集团有限公司,广西 南宁 530028;2.广西农业科学院农业科技信息研究所,广西 南宁 530007;3.广西财经学院,广西 南宁 530003;4.广西慧云信息技术有限公司,广西 南宁 530007)
【研究意义】广西作为柑橘(Citrus)的原产地之一,具有天然的生产地域优势,柑、橘、橙和柚等柑橘品种种植面积均较大,其中2018年种植面积超过40万hm2,产量近700万t,在全国省(区)中排名第一[1],形成了产前产中产后的全产业链。广西柑橘种植主要分布于桂北、桂中、桂南及桂西南的石灰岩旱坡地区,季节性干旱及病虫害制约着其产业规模的发展,尤其是黄龙病、红蜘蛛和溃疡病等的为害,导致柑橘生产成本居高不下,果品质量下降,严重影响柑橘种植的经济效益[2]。虽然植物提取物作为一种新型植物源杀菌剂可为柑橘病虫害的高效、绿色、环保防治提供无公害新选择[3],但柑橘病虫害种类繁多,技术人员匮乏,难以全部准确诊断,无法满足防治需求。而采用摄像设备对柑橘枝叶和果实进行监控,通过机器学习算法和神经网络对图像进行识别,实现病症自动分类和预警,改变传统病虫害防治方式,可更好地满足广大果农对柑橘病虫害诊断与防治的需求。因此,研究基于区域卷积神经网络(R-CNN)模型的广西柑橘病虫害识别方法,对提高柑橘重要病症分类和病理检测效率具有重要意义。【前人研究进展】基于调制荧光检测、高光谱成像技术的柑橘黄龙病传统诊断方法过程复杂,需要仪器对生物样本进行检测才能得出结果[4-5],耗费大量人力和时间,且对不同分类树叶的识别准确率浮动较大。卞云超等[6]基于MapReduce的新聚类算法对柑橘红蜘蛛图像进行了单一目标病害识别;而后虽开始兴起用机器学习方法如支持向量机算法(SVM)和神经网络等开展识别研究,但仅以较初级的卷积神经网络(最高为8层)对溃疡病进行比较分析,识别效果有限[7]。国内外图像处理和机器学习算法在农作物识别方面已有不少研究报道[4,8],但多数是基于通过图像物体特征向量抽取,采用反向传播(BP)网络、SVM分类和k均值聚类(k-mean)算法开展研究[9-11]。BP和k-mean算法的应用效果一般,而SVM属于二分类算法,是对多维度特征向量数据从高维度映射到低维度空间进行分类,通过对超平面线性方程的参数进行样本训练而求得最优分割超平面[12]。随着近年来神经网络的兴起,通过R-CNN来识别和分类物体获得了更高的准确率和精度[13]。【本研究切入点】目前,针对基于R-CNN模型的柑橘病虫害识别方法提高广西柑橘重要病症分类和病理检测效率的研究鲜见报道。【拟解决的关键问题】采用多层神经网络对广西不同种类柑橘病虫害特征进行识别,分析其准确率和空间复杂度,为提高广西柑橘重要病症分类和病理检测效率提供参考依据。
1 材料与方法
1.1 图片预处理
对目标进行分类和识别的传统做法是对图片进行预处理,例如转化成灰度值图片及进行滤波等。本研究为了更好地识别图片中植物的病症,未对图片进行过多预处理,仍然保留图片原来的像素颜色3通道,统一将图片缩放至1000像素×1000像素,采样图像缩小后树叶和柑橘果实的像素值一般在300×300~800×800,病症的像素值(长×宽的像素矩阵)也尽量保持在合理范围内。
1.2 神经网络结构设计
由于果园里监控摄像机拍摄的照片会不同程度受到背景噪音影响,因此本研究在对病虫害进行分辨分类时,首先对照片中的物体进行有效识别,以验证可视的病理特征是否在相应的物体上。如果不是目标物体(果实和叶片),则将鉴别结果摒弃,以减少错误识别率。而采用SVM方法每次只能对单个物体进行识别和分类,无法将待识别目标与背景有效区分开,其他的卷积网络模型或分类神经网络模型如VGG(视觉几何组网络)模型[14]在分类识别上的平均准确率也不高,因此参考Ross等[15]的方法选择R-CNN模型进行柑橘病虫害特征分类和识别。
1.2.1 R-CNN模型结构 神经网络选用R-CNN模型结构,其中主干网络采用残差神经网络(ResNet),在主干网络输出特征图后经过区域预测网络(RPN),再经过全链接层网络(FCN)得到输出的预测、物体框选及分类结果[16-17]。本研究侧重于检测照片中果实和枝叶的病理特征,已将背景和其他物体过滤掉,不需要太多的神经网络深度层级,以减少空间复杂度,因此主干网选用了33层ResNet网络结构。
在ResNet主干网络里,选用特征金字塔网络(FPN)方法,将所有卷积层按先后顺序分割成5块向金字塔层级上面输出的特征图,然后与升维采样(Upsample)中向下的金字塔链接,输出每个层级不同尺度上特征值以预测物体。ResNet有2种卷积层(Block块),一种是恒等映射块(Identity block),输入和输出数据的维度一致,主要用来保证数据不会因为梯度爆炸而失真,以增强梯度的反向传播;另一种是基本的卷积块(Conv block),主要用来调整特征图的大小并增加深度。一个ResNet的Identity block包含3个卷积层,每个卷积层均使用3×3卷积核(Filter conv)扫描(图1),输出向量维度和输入向量维度一致,每个卷积层跟随批量归一化(BN)和激活函数(Relu)处理及一个跳跃连接(Shortcut),通过残差函数加上跳跃连接(Shortcut)路径上的值来保证F(x)残差函数能根据输入输出相同向量,以不断调整Identity block里的权值学习和偏移量参数。

图1 卷积层恒等映射块的层级网络Fig.1 Convolution layer identity mapping block

图2 柑橘病虫害识别的神经网络结构Fig.2 Neural network structure for citrus disease and pest identification
本研究的R-CNN模型主干网共有33层ResNet结构卷积层(图2)。其中,普通卷积层(Conv)采用3层,Identity block采用10个块(每个Identity block 有3个相同输出维度的卷积层)。在Identity block里的第1个Conv用来调整主干网初始输入向量维度,其他Conv插在Identity block中的层级之间用于控制输出向量维度。R-CNN模型网络结构与普通的Fast R-CNN模型网络结构一致,从主干输出再以FCN全卷积网络代替全链接层,以减少输出的通道和参数,比一般的ResNet101和ResNet50网络结构少了很多层级,极大减少了计算复杂度。然后采用通用的9种比例锚选择框(Anchor boxes)对主干网输出的特征图进行RPN[18]。假设有k种(k为自定义数量,对应不同长宽的锚选择框,一般选择k值为9,即9种锚选择框,数值越大可检测的精度越高)锚选择框对应每个输出特征图的像素,最后在主干网络后面FCN对应RPN里输出的每个像素点,则有需要回归的边框包围盒(使用边框包围盒的目的是进行回归预测分类计算)4k和2k个。
1.2.2 网络训练损失函数计算 通过对目标物体位置检测,在RPN层后的FCN层使用归一化指数函数(Softmax)(Pi)分类器筛选后,用交叉熵来表示分类的损失函数。物体位置检测的损失函数可用L2算法来回归并计算RPN的物体检测候选框回归损失函数。为防止梯度爆炸,同时设置较小的学习率(Learning rate)或使用Adam算法来控制学习率[19],采用log函数来防止过快的梯度爆炸。
以网络输出预测值和物体真实值(Ground truth)进行以上损失函数计算,通过大量样本对网络进行训练,最后得到能精确预测目标分类的网络模型。
1.3 柑橘病虫害特征识别率比较
1.3.1 主干网模型复杂度分析和预测平均准确率比较 主干网选用33层ResNet网络结构,通过计算处理,分别与ResNet101、VGG-19及非主干网模型SVM等其他机器学习方法作比较,分析各模型的复杂度;进一步计算分析各模型对柑橘黄龙病、红蜘蛛感染和溃疡病识别的预测准确率。
1.3.2 柑橘病虫害的R-CNN模型识别率比较 取分辨率在1280像素以上的柑橘果实和叶片样本数据500张,分别采用R-CNN模型与线性SVM和VGG-19模型进行训练和标签,进行柑橘黄龙病、红蜘蛛感染和溃疡病的识别率比较,找出对广西柑橘黄龙病、红蜘蛛感染和溃疡病行之有效的鉴别方法。
2 结果与分析
2.1 主干网模型的复杂度和预测平均准确率
在以往的神经网络分类中,较大的样本分布差异会影响类别分类,因此本研究主要对柑橘黄龙病、红蜘蛛感染和溃疡病进行识别。本研究采用的ResNet类型网络只有33层卷积,相比ResNet101少了2/3的卷积层计算量,预测的平均准确率仅比其低3.10 %(绝对值,下同),而比VGG-19模型的准确度高8.60 %(表1)。ResNet101的神经网络层级虽然较多,但其耗费的计算量也随之增大,在相同计算处理能力下耗时更长,对长期监控野外的设备是个不小的负担;而33层的ResNet作为主干网络,虽然识别准确率降低3.10 %,但卷积层级计算量减少2/3;VGG-19模型对很多小型网络有效,但是针对移动低功耗端设备的应用,33层ResNet的卷积层结构在柑橘病症识别方面的准确率更高。

表1 主干网和非主干网模型的复杂度和预测平均准确率对比
2.2 柑橘黄龙病、红蜘蛛感染和溃疡病的R-CNN模型与线性SVM识别率比较
训练样本数据有500张分辨率在1280像素以上的柑橘果实和叶片背景图,每张图片均能标签10个以上需预测和分类的物体(图3)。其中80 %用于神经网络模型训练,20 %用于神经网络模型评估。本研究设计的模型在循环训练时对样本随机抽取训练样本,尽量做到样本分布能覆盖所有情况(包括背景、光线和角度等),以避免同一阶段重复取样导致模型输出过拟合。为了验证神经网络模型的性能,本研究选取其中500个样本对柑橘黄龙病、红蜘蛛感染和溃疡病进行SVM分析,进行100次样本循环训练可得到93.10 %的平均准确率(表1),而使用R-CNN模型分析对黄龙病的识别平均准确率达95.20 %(表1)。
用线性SVM分别对柑橘黄龙病、红蜘蛛感染和溃疡病进行训练和识别,损失函数用平方铰链损失(Square hinge loss)测试识别结果与R-CNN模型识别结果进行比较,其正样本率受试特征者(ROC)分别如图4~图6所示。从ROC图可看出,R-CNN模型对黄龙病的识别真正率(识别准确率)为95.30 %,高于对红蜘蛛感染的识别准确率(90.30 %),低于对溃疡病的识别准确率(99.10 %),但均相应优于SVM对黄龙病、红蜘蛛感染和溃疡病的识别准确率(分别为93.20 %、88.20 %和95.20 %)。可见,在样本一致和数量下同的条件下,33层ResNet的R-CNN模型对柑橘样本病症的识别准确率优于SVM。
2.3 柑橘黄龙病、红蜘蛛感染和溃疡病的R-CNN模型与VGG-19模型识别率比较
在分类测试方面,以柑橘黄龙病、红蜘蛛感染和溃疡病病症特征和背景的500个样本图片使用VGG-19模型和R-CNN模型的ResNet骨干网进行训练和标签,结果(表2)表明,R-CNN模型对各类别病症的识别率均高于VGG-19模型相应病症的识别率。

图3 柑橘黄龙病、红蜘蛛感染和溃疡病的检测Fig.3 Detection effect of citrus Huanglongbing,red spider mite infection and canker
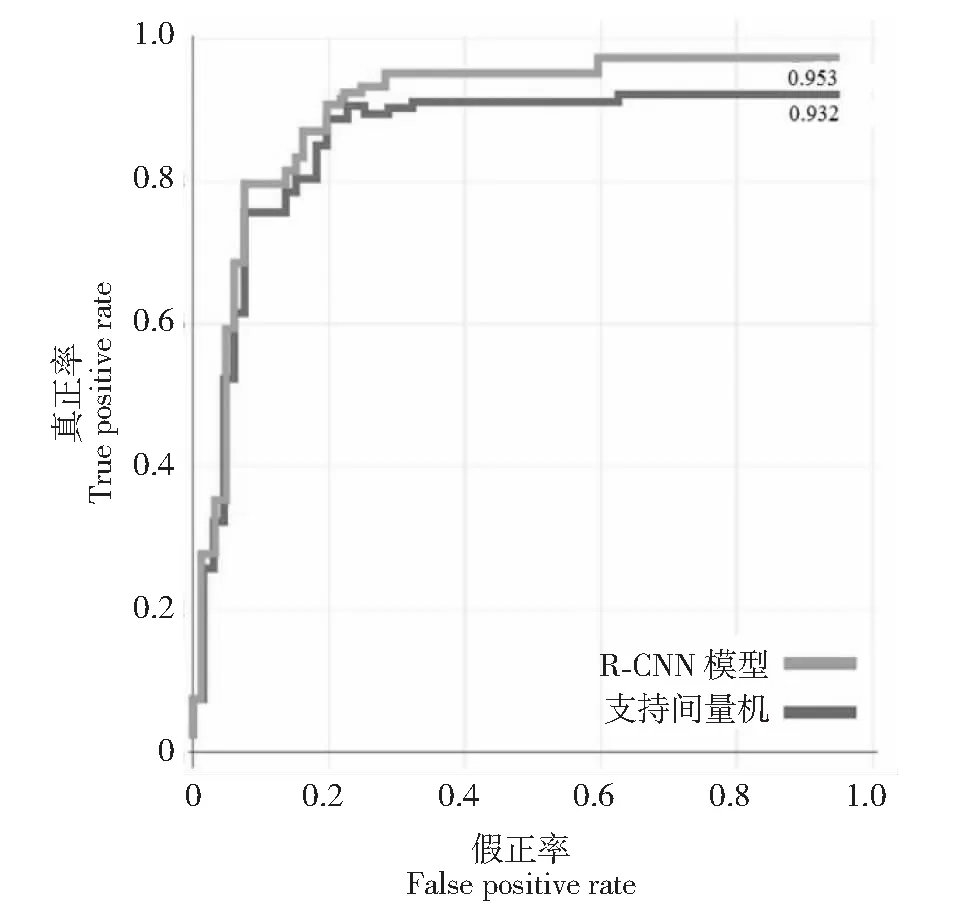
图4 R-CNN模型与线性SVM对柑橘黄龙病的识别检测结果对比Fig.4 Comparison of R-CNN model and linear SVM for citrus Huanglongbing recognition and detection
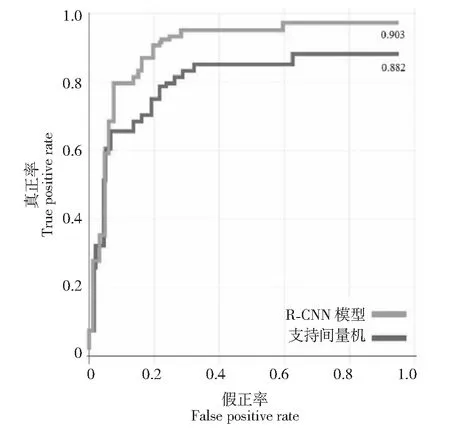
图5 R-CNN模型与线性SVM对柑橘红蜘蛛感染的识别检测结果对比Fig.5 Comparison of R-CNN model and linear SVM for citrus red spider mite infection recognition and detection
由表2可知,对R-CNN模型进行训练后,对柑橘溃疡病的平均识别准确率达99.12 %,比VGG-19模型提高4.25 %;柑橘黄龙病的病理特征比较明显,因而比较好区分,R-CNN模型对黄龙病的平均识别准确率达95.31 %,比VGG-19模型提高2.55 %;对红蜘蛛感染的预测,由于其叶片正面病理特征不明显,在取样时较难与正常的叶片区分,但其平均识别准确率仍达90.23 %,且比VGG-19模型提高4.62 %。说明本研究的R-CNN模型在较少神经元参数的情况下,可减少空间复杂度,对设备的利用成本较低,但能获得较理想的柑橘叶片黄龙病、红蜘蛛感染和溃疡病识别效果,可实现在广西柑橘果园大量部署和识别应用。

图6 R-CNN模型与线性SVM对柑橘溃疡病的识别检测结果对比Fig.6 Comparison of R-CNN model and linear SVM for citrus canker recognition and detection
表2 主干网分类预测柑橘黄龙病、红蜘蛛感染和溃疡病的平均准确率和Top-1错误率对比(n=500)
Table 2 Comparisons of backbone network predicted average accuracy for citrus Huanglongbing,red spider mite infection and canker and top-1 error

模型Model分类Classification平均准确率(%)Average accuracy rateTop-1错误率(%)Top-1 error rateVGG-19黄龙病92.769.12红蜘蛛感染85.61溃疡病 94.87R-CNN黄龙病 95.316.85红蜘蛛感染90.23溃疡病 99.12
3 讨 论
本研究使用R-CNN模型、设计主干33层卷积网络对柑橘病虫害进行识别分析,适宜南方柑橘果园环境和当地设备条件应用。比起其他研究中使用简单卷积和使用传统的图像处理(滤波和图像预处理),R-CNN模型能区分更多的柑橘叶片病理特征,且测试仪成本较低。与线性SVM相比,R-CNN模型对柑橘溃疡病的平均识别准确率达99.10 %,对柑橘黄龙病的平均识别准确率达95.30 %,对柑橘红蜘蛛感染的平均识别准确率达90.30 %;在分类测试方面,分类效果也优于VGG-19模型,对柑橘黄龙病的平均识别准确率达95.31 %,对柑橘红蜘蛛感染的平均识别准确率达90.23 %,对柑橘溃疡病的平均识别准确率达99.12 %,分别提高4.25 %、4.62 %和2.55 %。因此,本研究使用基于33层ResNet为主干网络的R-CNN模型虽然选用的卷积层网络较少,但获得较高的平均识别准确率,是一种对柑橘黄龙病、红蜘蛛感染和溃疡病行之有效的鉴别方法,可在广西柑橘果园大量部署应用。
近年来,CNN模型在作物病害防治领域的应用已逐渐兴起。本研究中基于33层ResNet主干网的专用R-CNN模型对柑橘黄龙病、红蜘蛛感染及溃疡病的平均识别准确率分别达95.31 %、90.23 %和99.12 %,而徐冬[20]采用CNN的特征学习方法对大豆病害特征进行自动提取学习,并通过模型改进,使识别准确率迅速收敛至94.6 %,孙俊等[21]对传统CNN模型进行改进得到8种模型,通过对14种不同植物的26类病害进行识别训练筛选出最优模型,其测试平均识别准确率达99.56 %,表明基于CNN改进模型的病害识别准确率较理想,具有良好的应用潜力。
本研究发现,受红蜘蛛感染的叶片由于病理特征不明显,因此识别准确率相对较低,表明叶片病理特征是影响识别准确率的重要因素,与邱靖等[22]对水稻病害纹理特征的研究结果相似。值得注意的是,影响识别准确率的原因除图像及网络本身外还有样本噪声,因为在图像监督式学习中,设置的图像样本实际标签值与理论值相比不可能做到完全准确,致使训练出现一定误差。林中琦[23]研究认为,高质量、大数量、多类别的标签数据集对于CNN性能提升意义重大,因此,在进一步的研究中还可将对抗性网络模型或记忆类网络模型融入进行半监督式训练,以提升对柑橘病理特征的平均识别准确率,并扩展到对柑橘其他病症如锌和锰等微量元素缺失特征的共同识别,以极大减少训练计算成本,提高柑橘生产的经济效益。
4 结 论
R-CNN模型识别是一种对柑橘黄龙病、红蜘蛛感染和溃疡病行之有效的鉴别方法,可在广西柑橘果园大量部署和应用。
