海量数据广义线性模型变量选择算法研究
2020-06-22陈少东李志强
陈少东 李志强
(北京化工大学 数理学院, 北京 100029)
引 言
广义线性模型由Nelder等[1]在研究指数族分布时引入,该模型不仅能刻画连续型数据,还可刻画计数数据、属性数据等离散型数据,因此在医学、经济学以及社会科学等领域得到广泛应用。
随着数据时代的到来,数据呈现海量化趋势。数据海量化主要体现在两个方面:一是能获取的变量维度越来越高;二是可获取的观测样本越来越多。在数据量不是很大时,面对高维的变量如何进行变量选择的问题已得到了广泛的研究。在以往文献中,有许多研究人员利用惩罚函数进行变量选取,例如Tibshirani[2]提出的least absolute shrinkage and selection operator (Lasso)惩罚、Fan等[3]提出的smoothly clipped absolute deviation (SCAD)惩罚以及Zhang[4]提出的minimax concave penalty (MCP)惩罚等。
为了解决基于惩罚函数的广义线性模型变量选择问题,Breheny和Huang[5]给出一种基于坐标下降法的计算方法,该算法能有效求出模型局部最优解;然而,在海量数据环境下,由于该方法使用了全部海量数据进行迭代计算,导致出现计算效率较低甚至计算机存储空间不足等问题。为了克服这些瓶颈,需要探究新的估计算法来解决海量数据下广义线性模型的变量选择问题。
分治算法是在海量数据下估计统计模型参数的一类主流方法。目前已有部分文献利用分治算法研究海量数据下的统计模型。其中,Lin等[6]提出了一种解决海量数据非线性估计方程的估计方法;在变量选取方面,方方等[7]研究了海量数据下Logistic模型的平均算法;Chen等[8]给出了一种非凸惩罚下具有典则连接的广义线性模型的变量选择估计方法。基于分治算法处理海量数据的详细介绍可参考文献[9]。
然而,以上研究的相关工作还有待进一步深入,例如采用文献[7]中的模型平均估计方法难以进行高效的运算;文献[6]、文献[8]只研究了海量数据下具有典则连接的广义线性模型。但在实际建模应用中,大部分连接函数都是非典则连接,因此研究一般广义线性模型的惩罚估计具有更重要的现实意义。
本文基于文献[5]在Logistic模型下的估计方法,推导出一般广义线性模型在SCAD惩罚和MCP惩罚下的迭代公式,并将该方法推广到了海量数据下一般广义线性模型中。该方法避免了在迭代过程中一次性加载全部数据,从而有效地克服了基于原始海量数据的估计方法带来的计算机存储空间不足等问题。与此同时,考虑到当前在解决海量数据问题时,大部分处理工具采用分布式并行框架,本文结合分治算法与分布式计算的共同特征,给出了算法在Spark集群环境的计算步骤。模拟结果表明,估计算法在克服内存瓶颈的同时提高了计算效率,其估计精度要优于随机抽样得到的估计,而且能有效应用于集群环境。
1 广义线性模型及惩罚方法
1.1 广义线性模型
一般广义线性模型满足
(1)
式中,f(·)为概率密度函数,yi∈为响应变量,xi∈p为观测变量,β∈p为未知参数,θ为典则参数,a(·)、b(·)、c(·)为已知函数,μi为均值函数,V(μi)为方差函数,g为连接函数,为常数,i=1,…,N。
为了估计模型的未知参数β,通常采用极大似然估计方法,其似然函数可表示为
(2)
1.2 基于惩罚的变量选择
惩罚函数方法是一种常用的变量选择方法,在进行变量选择时,通过在式(2)上添加惩罚项,即可得到惩罚目标函数,现将其转化为极小化问题
(3)
式中,βj为β的第j维分量。
SCAD惩罚和MCP惩罚是两种常用的非凸惩罚函数,与Lasso方法相比,这两种惩罚能保证Oracle性质,因此本文将围绕这两种惩罚方法进行研究。
1.2.1SCAD惩罚函数
SCAD惩罚函数在βj∈[0,∞)上定义为
(4)
式中,λ≥0,γ>2。
当βj较小时,SCAD和Lasso具有一样的惩罚力度;随着βj增大至λ,SCAD惩罚力度开始逐渐下降;当βj>γλ时,惩罚力度降为0。SCAD惩罚保留了Lasso惩罚的稀疏性等优点,并修正了Lasso惩罚过度压缩系数的问题。
1.2.2MCP惩罚函数
MCP惩罚函数在βj∈[0,∞)上定义为
(5)
式中,λ≥0,γ>1。
MCP惩罚起初与Lasso惩罚有相等的惩罚力度,然后随着βj的增大,惩罚力度逐渐减小,当βj>γλ时,惩罚力度降到0。在高维线性回归中,MCP惩罚方法是一种几乎无偏且准确的变量选择方法。
1.2.3Logistic模型惩罚估计方法
为了解决Logistic模型在上述两种惩罚下的估计问题,Breheny和Huang[5]结合了文献[10]给出的用于求解广义线性模型的迭代加权最小二乘法,将优化问题转化为线性模型下加权最小二乘的优化问题,然后采用以下方法进行估计。
设对数似然函数的第m次迭代的估计值为m,Logistic模型在β=m处的近似惩罚似然函数为
(6)
记Xj为第j个自变量所对应的整体观测值,mj为m的第j维分量,为了求解式(6)的极小值,文献[5]给出具体估计步骤如下:
(4)基于坐标下降法重复步骤(1)~(3)直到收敛。
当惩罚函数为SCAD时,f(zj,λ,γ)满足
当惩罚函数为MCP时,f(zj,λ,γ)满足
这里,
2 海量数据下一般广义线性模型的惩罚估计方法
2.1 一般广义线性模型下的惩罚估计
Logistic模型仅仅是广义线性模型中的一个特例,在实际问题中,因变量除了服从两点分布外,还可能服从多项分布、泊松分布等,且在建模时,大部分连接函数都是非典则连接。因此有必要进一步研究一般情形下的广义线性模型的估计方法。
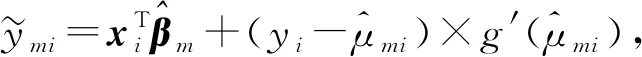
(7)
因此结合式(6)的惩罚函数和式(7),可以利用与式(6)类似的计算步骤得到一般广义线性模型的惩罚估计。
上述方法在求解过程中需要把所有的观测数据一次性加载到计算机内存当中,当观测数据量N很大时,可能会带来计算机内存不足等问题。因此,需要对该算法进行改进,以适应海量数据情形。
2.2 海量数据下一般广义线性模型的惩罚估计
为了解决海量数据下具有典则连接的广义线性模型的变量选择问题,Chen等[8]采用分治思想,给出了一种具有典则连接的广义线性模型的变量选择方法,其基本思想是:首先将全部数据划分为K个互不相交的子数据集;接着分别求解每块子数据集下的变量选择及参数估计结果;然后通过投票的方式解决不同子数据集下选取的变量可能不同的问题,确定最终选取的变量;最后通过加权方式对K个估计结果进行聚合,将其作为最终估计结果。本文延续上述思路,给出了具有一般连接函数的广义线性模型变量选择的估计方法。
为了求解第k块数据集Dk下的压缩统计量k,记Xkj为Dk下第j个自变量所对应的观测值,mk为第m次迭代的估计值,mkj为mk的第j维分量,通过1.2.3节方法进行估计:
(4)基于坐标下降法重复步骤(1)~(3)直到收敛。这里,k、mki、kj均为β=mk时代入相应公式计算得到的值。
因为不同的子数据集选取的变量可能不同,所以可先采用投票方式确定选取的变量
(8)
当vj=1表明第j个变量被选中,否则剔除该变量,I(·)为示性函数,w∈(0,K]为阈值。设A={j|vj=1,j=1,…,p}为被选中变量集。令Ak表示由k的第j维分量组成的子向量,其中j∈A。
为了对K个数据集上的估计结果Ak进行聚合,将似然函数的二阶近似导数作为权重矩阵进行加权,得到最终的聚合估计结果
(9)
式中SAk=ATSkA。令v=diag(v1,…,vp),则A为由v的第{j|j∈A}列元素组成的子矩阵。
由式(9)可知,在变量选择及参数估计的实现过程中,仅需保留每个子数据集Dk上的压缩变量Ak、SAk即可得到整块数据集的近似估计。因为每个小数据集上的估计是独立的,所以对计算机性能的依赖大大降低,只需要能保证每个小数据集的估计能正常进行即可。
2.3 基于Spark集群的并行实现
当前处理海量数据的主流工具是基于分布式搭建的。分布式计算通过将一个大型计算任务拆分为多个子任务,然后将这些子计算任务分发给集群中的多个计算机节点进行计算,以此来完成并行化计算。
在本文所提算法的估计过程中,数据压缩是耗时最久、占用计算资源最多的步骤,然而基于分治算法,每个子数据集在进行数据压缩过程中是独立的,该特性使其适合以分布式方式实现。
Spark和Hadoop是目前处理海量数据的主流工具,借助Hadoop的存储框架HDFS对数据按块进行分布式存储,并采用适合处理迭代式计算的Spark计算框架,便能将该算法以并行的方式实现,从而提高计算效率。
并行计算流程如图1所示,每个计算节点从HDFS中读取不同的数据块,然后以并行的方式对每一个子数据块上数据进行压缩,接着将所有数据块上的结果广播给主节点,让主节点完成聚合步骤,最后输出结果。
3 数值模拟
本节对算法进行数值模拟,以验证算法的有效性。有效性通过估计精度和时间消耗两个角度来衡量,模拟通过普通单机和Spark集群两种方式完成。选择常用的两点分布,即yi|xi~B(1,μi),其中μi通过以下两种方式来建模。
(1)在典则连接下,即为常用的Logistic模型
(2)在非典则连接下,选择Probit模型
式中,Φ(·)为标准正态分布的累积函数。
模拟时选取的数据量N=106,β0的维数为200,其中非零个数为24,自变量独立同分布,服从标准正态分布。
3.1 单机计算
本次实验在Ubuntu 16.0.4操作系统下,使用Python 3.7.0完成,计算机配置为CPU 3.40 GHz、内存8 G。所有实验重复50次取平均值作为最终结果。
为了检验估计效果,重新随机生成了100万个样本点,并将这些样本下的模型分类准确率作为估计效果的评价指标,结果如表1所示。在所有的实验中,变量选取结果均是正确的非零变量。由表1可以看出,Logistic模型的分类准确率可达0.928以上,Probit模型的分类准确率可达0.958以上,并且经过分块后,两个模型的分类准确率下降基本控制在0.1%内,这说明该估计的精确度较高且稳定。
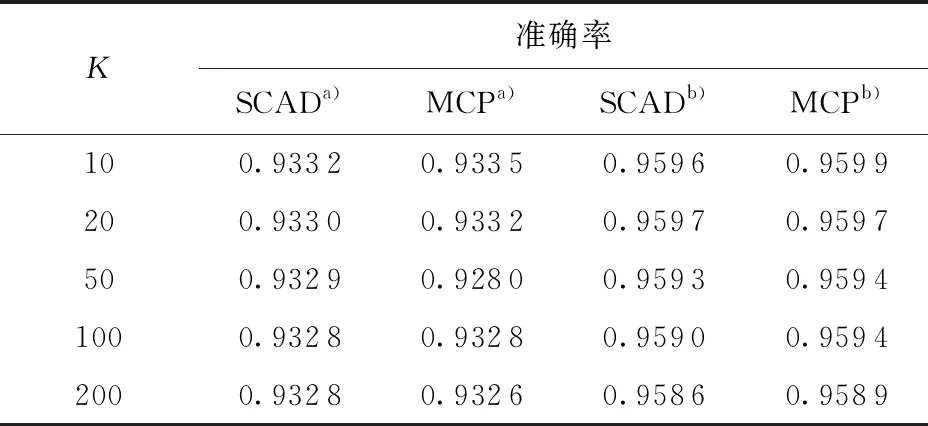
表1 分类准确率与分块数的关系
a—Logistic;b—Probit。
表2给出了单机环境下参数估计消耗的时间与分块数的关系。由表2可知,随着分块数的增加,两个模型的参数估计过程所消耗的时间逐渐减少,这说明了分块方法在一定程度上可以提高模型参数的估计效率。
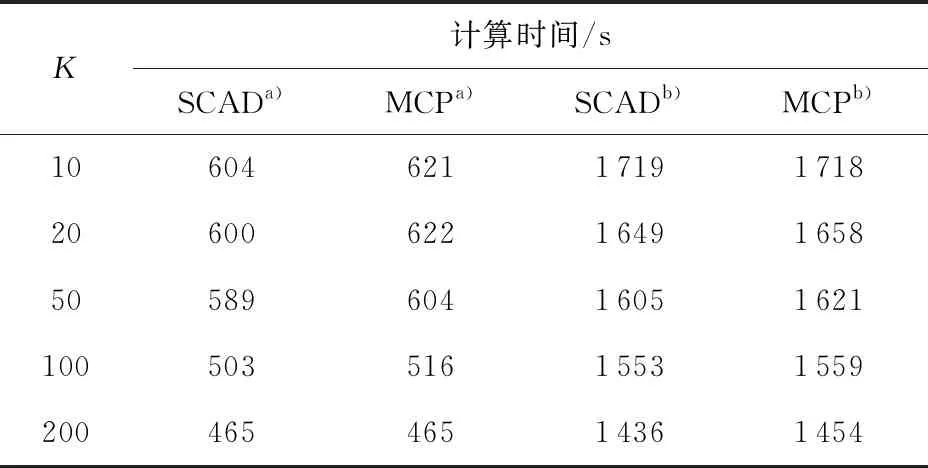
表2 单机环境下计算时间与分块数关系
a—Logistic;b—Probit。
结合表1和表2的实验结果,分块方法能够在保证分类准确率微小下降的情况下提升模型的参数估计效率。
表3和表4给出了本文的聚合估计方法与随机抽样方法的估计结果对比。选取的评价指标为估计偏差,其计算公式为:设为估计结果,β0为真实值,则估计偏差定义为这里‖·‖1为一范数。因模拟所用数据是随机产生的,所以可将分块后的每一块数据集下的估计结果视为一次以的比例进行随机抽样得到的估计结果。由表中结果可知,两个模型的结果是一致的:固定分块数K的情况下,因为聚合方法使用了全部数据进行估计,所以其估计偏差要比基于随机抽样得到的估计偏差小。该结论表明:在计算机内存有限的情况下,采用聚合的估计方法总要优于随机抽样方法。
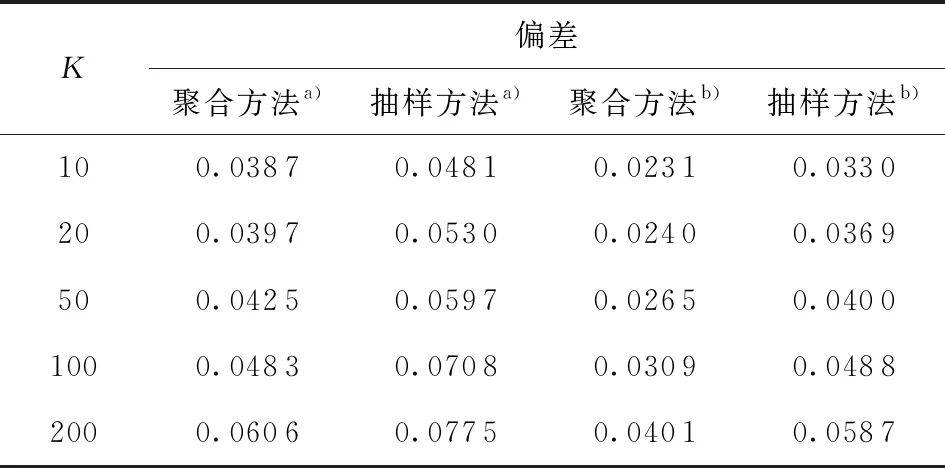
表3 Logisitc下聚合方法与抽样方法偏差比较
a—SCAD;b—MCP。
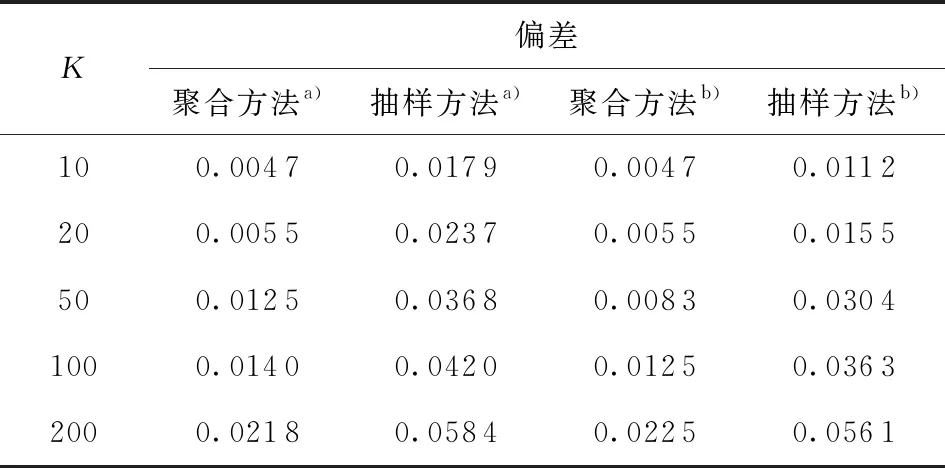
表4 Probit下聚合方法与抽样方法偏差比较
a—SCAD;b—MCP。
3.2 Spark集群计算
在海量数据环境下,实际上数据多数是以分布式的方式存储在多台计算机上。Spark是目前用于海量数据计算的主流分布式计算框架之一,本文通过Spark计算框架来完成模拟。实验在Ubuntu 16.0.4系统下,通过4台普通计算机组成的Spark集群来完成,计算环境为Python 3.7.0及Spark 2.3.2。其中,计算节点的配置为CPU 3.40 GHz、内存4 G。
表5给出的是Spark集群下,模型参数估计消耗的时间与分块数的关系。由表5可知,相比于单机环境,采用集群方法可以提高模型参数估计的效率,这也说明了分块方法在集群环境中的可行性。
4 实证分析
选取搜狗实验室(https:∥www.sogou.com/labs)公开的2012年6月—7月科技板块和股票板块的新闻数据集建立Probit模型,以此来检验本文算法在实际应用中的可行性。其中随机抽取40 138条科技新闻和39 971条股票新闻用于估计模型参数,将剩余的9 844条科技新闻和4 437条股票新闻用于测试,将其分类准确度作为模型分类效果评价指标。
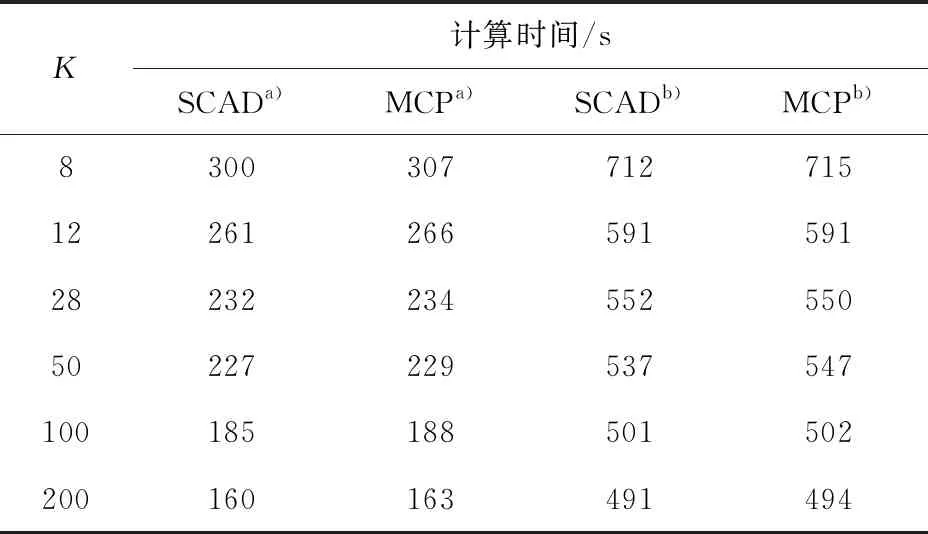
表5 Spark集群下计算时间与分块数的关系
a—Logistic;b—Probit。
整个建模流程为:首先对新闻文本进行分词并过滤掉无用的停用词,然后通过term frequency- inverse document frequency (TF- IDF)方法将每个新闻文本转化为1 000维的词向量,最后通过本文算法完成Probit模型的变量选择。结果表明,采用MCP惩罚在测试集上得到的准确率为0.955 8,采用SCAD惩罚在测试集上得到的准确率为0.951 4。由以上结果可知,两种惩罚方法在实证数据集上都有较好的表现,对测试集的新闻分类准确度可达0.95以上,这也进一步证明了本文给出的方法对于解决实际问题是可行的。
5 结束语
本文研究了海量数据下一般广义线性模型的变量选择估计问题,结合分治思想与坐标下降法,给出了基于MCP惩罚和SCAD惩罚的估计方法,该方法有效降低了估计时对计算机内存的依赖,克服了计算时内存不足的瓶颈。数值模拟表明该方法能进一步提高计算效率,并通过实证分析证明了本文估计方法在解决实际问题时的可行性。
