可视化支持下CNN在个性化推荐算法中的应用①
2020-06-20宗春梅张月琴赵青杉郝耀军郭玥鑫
宗春梅,张月琴,赵青杉,郝耀军,郭玥鑫
1(忻州师范学院 计算机系,忻州 034000)
2(太原理工大学 计算机科学与技术学院,太原 030024)
3(西安工业大学 西北兵器工业研究院,西安 710021)
推荐算法是一种信息过滤技术,通过总结用户在过去的一段时间内留存在网络中的信息找到其中的规律,利用这些规律从需要推荐的项目集合中确定用户可能感兴趣的某些项目或者产品,进而主动向用户提供推荐信息[1].传统方法是使用各种协同过滤算法实现推荐,但用户评分数据却很稀疏,导致推荐质量及速度下降,针对协同过滤中存在的稀疏矩阵的问题有学者引入了降维技术对用户进行聚类,降低了用户特征维数的同时实现了推荐的信息的实时性,同时为该推荐系统添加了对数据的隐私保护[2-4],但推荐的时间及精准性仍然与目标相距较大.
近年来深度学习被成功的应用于推荐领域并取得了巨大的成功,尤其是神经网络,能从数据列中获取最有信息量的部分,卷积神经网络在文本特征的提取中得到了很好的应用[5,6].基于此,本文对神经网络的个性化推荐算法进行研究,依据神经网络、卷积神经网络和推荐算法的各种理论构建实现算法的网络模型,以此预测用户对电影的评分,实现基于神经网络的个性化推荐.在使推荐结果更优化的同时有效减少数据稀疏性对推荐结果的影响,提高电影推荐速度及质量.
1 背景知识及相关工作
传统的推荐方法在学者们不断改进下取得了很好效果.文献[7]提出基于一种算法改进评分填充矩阵,在一定程度上缓解了协同过滤推荐中的数据稀疏性问题,并弥补了空值填补法填补值过于单一的问题.文献[8]提出协同过滤利用相似度计算邻居用户,从而以邻居用户的偏好对目标用户的偏好进行推荐预测,提高了电影推荐质量.文献[9]引入社区划分的思想,构建了一种融合电影类别、用户评分和用户标签的电影推荐模型,有效解决了数据稀疏性问题.文献[10]提出一种改进的时间加权协同过滤算法,利用时间加权的聚类结果优化算法使预测评分准确性大幅度提升.但数据稀疏、冷启动、手工提取特征过多等问题仍然是传统推荐方法性能提升的瓶颈问题.
随着卷积神经网络应用的日渐成熟与推广,学者们提出了各种基于此算法进行用户和项目隐藏特征之间的关联分析从而实现基于关联的推荐,并通过大量实验证明该方法在大规模数据环境下从各方面显著提高了推荐性能,证明深度学习方法对许多关联分析任务是有效的[11,12].文献[13]以电影推荐为研究对象,提出了融合动态协同过滤和深度学习的推荐算法,以解决在电影评分推荐场景中的数据稀疏性、冷启动和信息过期问题,实验结果表明电影评分预测的准确性提高了.但是算法也存在算法复杂且可解释性差、算法中的参数选取费时且影响着算法性能等缺点.
文献[14]提出尝试基于深度学习来加强个性化推荐,提出将层叠降噪自动编码器与隐含因子模型相结合的混合推荐方法,综合考虑评论文本与评分,以提升推荐模型对潜在评分预测的准确性.实验结果表明:与传统推荐模型相比,该文提出的方法可有效提高评分预测的准确性,性能提升最高可达64.43%.文献[15]提出一种融合径向基函数的二值化卷积神经网络的推荐模型,通过对推荐系统中的用户属性和项目属性建立了RBF 网络,使用径向基函数计算用户与用户之间的相似度矩阵,再结合卷积神经网络进行推荐预测,极大节省数据存储空间并提高推荐效率.文献[16]提出了一种基于注意的卷积神经网络和因子分解机的推荐算法,利用所建立的因子分解机分析用户和项目隐藏特征之间的关联,并实现基于关联的推荐.实验证明推荐性能得到了显著提高,另外在数据稀疏和冷启动的极端环境下该推荐精度也优于其他推荐方法.文献[17]提出了一种基于生物机制驱动的特征构建的答案推荐方法用于社区问答中推荐相应给定问题的最佳答案,通过引入回答者的用户信誉信息来模拟记忆处理特性,然后构造出用于答案排序的特征向量,通过特征向量得到最佳答案,并在StackExchange 数据集上的实验,结果表明该算法具有很好的性能.
综上所述,神经网络的批量处理及大幅度循环训练的特性可以克服传统的基于协同过滤推荐方法推荐过程时间长的问题,且卷积神经网络的卷积与池化流程可以适度解决评分矩阵稀疏性问题.因此,本文提出一种神经网络算法,通过对特征向量和卷积核大小等参数的调整实现推荐速度和推荐准确性的提升,进而在实验过程中通过误差均值等参数来验证神经网络推荐方法在许多性能上优于传统协同过滤推荐方法,从而说明算法的有效性.
2 本文提出的推荐模型
2.1 相关模型
本文选取构建神经网络的方法进行推荐算法的实现即神经网络推荐算法(Neural Network Recommendation Algorithms),所设初期计模型将其称为NNRAM_1.NNRAM_1 中,x_y_embed_layer 是将x对象的y数据引入嵌入层后转成的向量矩阵,其中向量的值是-1 到1 之间的随机数,本质就是数据降维;x_fc_layer 是x对象的隐含层;concatenate 是做“层”拼接;dense 作为输出层用以产生x对象的特征矩阵x_combine_layer_flat;inference 是进行预测评分.算法模型NNRAM_1 具体步骤如下:
(1)构建神经网络模型实现用户特征的提取.模型包含4 层:输入层、嵌入层、隐含层、输出层,具体如图1所示.预处理后的用户数据由输入层接收后,首先经过嵌入层,目的是将用户的id、年龄、性别和职业等属性矩阵分别转成向量矩阵,实现数字化;其次将嵌入层产生的4 个向量矩阵分别送入隐含层;最后,经过在隐含层对用户年龄及职业做相应加权处理后,将4 个隐含层矩阵合并送入输出层,生成聚合的用户属性特征.
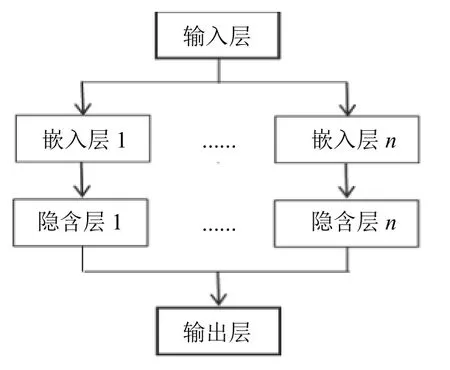
图1 获取用户特征的模型
(2)与用户特征的提取同理,将处理后电影数据中电影id 和电影类型以同样的方式处理产生电影基本信息特征.对电影名称做文本卷积处理,如图2所示,虚线内部分可以循环多次.首先初始化卷积核的参数和偏置的参数,指定需要做卷积的文本、卷积核的大小以及卷积的步长.对于卷积核数的选择可以尝试随机选取数值,亦可从3 起步,进而选择使用Tensorboard可视化进行监控的方式来观察损失率的变化情况,从Loss 的信号曲线防止过拟合,反复观测即可尽快确定卷积核数量最佳范围.当然,卷积核越小则网络中所需参数数量和计算量就越小.激活选用ReLU 方法,池化选用max_pool 方法,处理过后生成电影名全连接矩阵;最后将电影信息所产生的3 个局部全连接合并在一起做全连接并输出,生成电影特征.
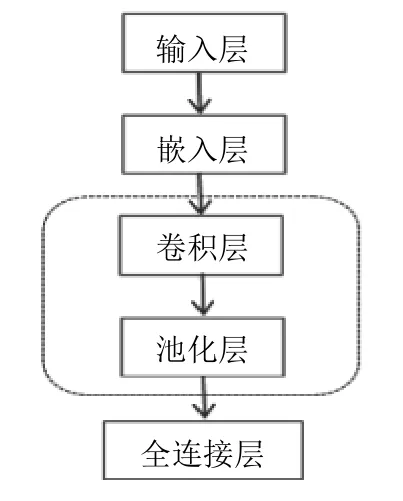
图2 获取电影title 特征模型
(3)将第(1)步和第(2)步中所获得的特征值进行运算,产生最终的预测评分,如式(1)所示.inference 表示预测评分,A为用户特征,B为电影特征,考虑到预测评分中用户特征与电影特征所占比例可能存在不平衡性,为A、B设置权重w0、w1.实际评分均为整数,预测评分为实数,所以设置偏差b以缩小两者之间的差距.实验中,各模型未明确说明时,w0、w1、b的值分别为1、1、0.
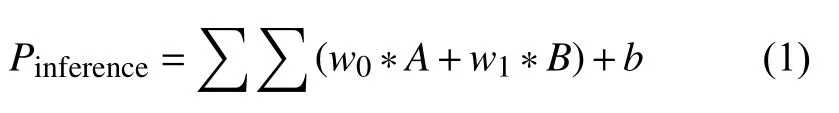
2.2 模型评价标准
推荐算法评价是验证推荐算法是否合格的重要环节之一,常用指标包括准确度与决策支持精度,本文主要使用统计精度度量中的平均绝对误差(Mean Absolute Error,MAE),来进行模型评价.MAE 的评价方式为计算预测评分与实际评分二者的绝对平均误差,MAE 越小代表预测结果更趋近于真实值,即推荐结果较优.MAE 评价公式如式(2)所示,式中n为测试集合元素数,xi表示实际评分,yi表示预测评分.

3 实验与结果分析
实验中,将MovieLens-1M 数据集分成训练集和测试集,训练数据与测试数据比为9:1,先将训练数据投入网络模型进行训练,训练的最终目的是得到预测评分.训练结束后,算法模型得到保存.训练好的网络模型用测试数据进行测试,以验证模型的性能,最后使用模型进行推荐.
3.1 数据集及数据预处理
论文所用数据集是MovieLens-1M,是将近6000个用户在将近4000 部电影上所有评论,有一亿多条评分数据.MovieLens-1M 有3 个数据表:用户数据表、电影数据表、评分数据表.其中用户数据分别有用户id、性别、年龄、职业id 和邮编等字段;电影数据分别有电影id、电影名和电影风格等字段;评分数据分别有用户id、电影id、评分和时间戳等字段.
在使用之前需要对现有数据进行预处理.将用户数据中的年龄和性别字段分别转化为数字.其中性别中代表男性的M 和代表女性的F 转化为1 和0;对于年龄数据将其分为7 段,依次用0 到6 表示.电影名称和电影类型通过数据字典将其转化为数字.电影名称数据信息分裂为两个字段信息,电影文字标题及电影年份,进而将电影文字标题转成数字字典,首先将电影名称分成字符串列表,然后将每一个单词字符串变换成一个数字字符串;在电影类型数据中,电影类型的处理同电影名称转成数字字典,也是一个单词对应一个数字.
3.2 参数设置
模型NNRAM-1 中,filter_num 数量为8,batch_size 数量为256,dropout_keep 数量为0.5,learning_rate 数量为0.0001.经训练后,train time(s)为329.6 s,损失率为0.833 526,MAE 为0.717 517.
在NNRAM-1 中参数值filter_num、batch_size、dropout_keep、learning_rate 不变的情况下,将网络模型中全连接层的维数由200 更改为50 产生模型NNRAM-2,发现其训练时间缩短将近一半,而Loss 及MAE 均有所下降.在进行数据挖掘时发现,电影的年份数据未得到使用,而根据观影者的日常选择,影视作品的年份在很大程度上影响着观影者对其的选取,所以在读取评分数据集后,将电影标题中的年份取出并与现在年份做差运算获得的信息参与到电影信息特征提取中,产生模型NNRAM-3(全连接层维数为200)与NNRAM-4(全连接层维数为50),实验结果表明在更改模型设置后,训练时间、损失函数及平均绝对误差均有所下降.训练结果对比如表1所示.
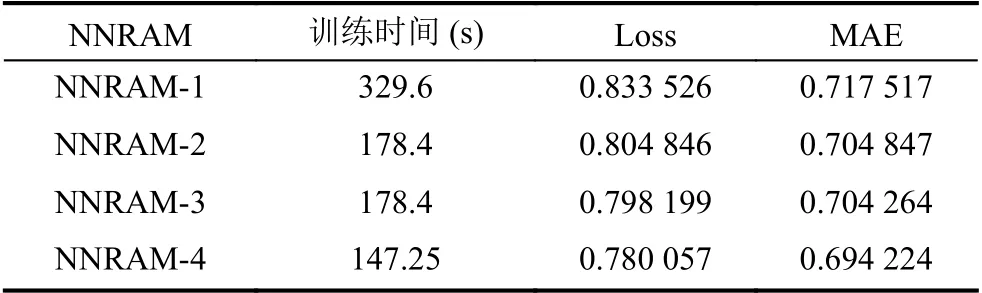
表1 相关模型训练结果参数对比
继续对模型NNRAM-4 进行改进,卷积核的数量决定着计算时间的长短及特征提取的准确度,批处理量的大小影响着权重更新的质量,学习率的适度设置可以加快学习的速度,因此对更改模型的卷积核个数filter_num,对批处理参数batch_size、学习率learning_rate 值进行调整以达到运行结果相对最优,具体如表2所示;再将数据经过嵌入层、连接层及全连接层时的维度进行缩减;考虑到电影标题相当于一句话,一般词组的词素量为2~3 个,由此改变文本卷积时滑动窗口的单词数量,使其适量减小.通过以上参数的调整产生了模型NNRAM-5、NNRAM-6、NNRAM-7,模型部分参数值如表3所示.模型NNRAM-7 中,求inference时w0、w1、b的值分别为0.4、0.6、0.28.

表2 相关模型部分参数对比

表3 相关模型数据维数对比
3.3 实验结果分析
依次运行所设计的3 种模型,实验结果如表4所示.
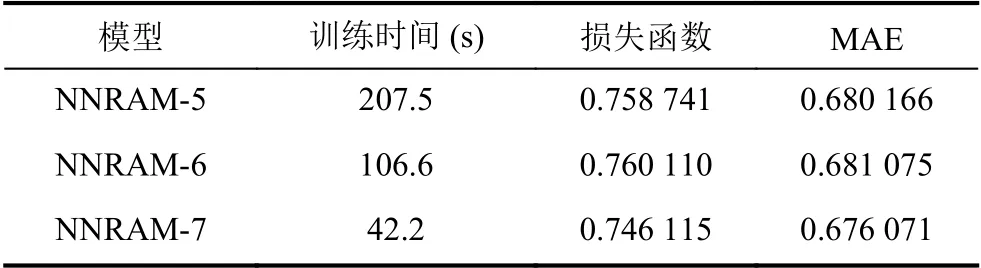
表4 改进后相关模型参数对比
当模型中各层的维数适量减小时,训练时间会大幅减少,如图3所示.而卷积核数量的适量减少及卷积时滑动窗口的数量的合理设置会使损失函数及平均绝对误差(MAE)有所下降,如图4所示,这意味着推荐的准确性随之增加.
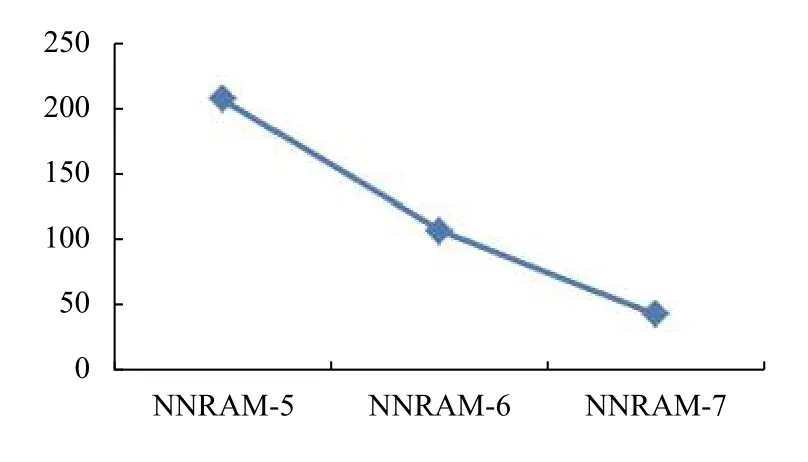
图3 改进模型间训练时间对比

图4 改进模型间性能对比
当对NNRAM_1 与NNRAM_7 的3 次推荐结果进行对比时发现,加入与时间相关的字段后的模型NNRAM_7 所推荐的电影日期上都比较新颖,而未改进的模型NNRAM_1 所推荐的电影中部分时间比较久远,如表5所示.电影年份早或过早,意味着效果不佳,被推荐对象与观影者猎新习性相违背,观影需求可能性较小.改进后的模型NNRAM_7 所推荐电影的时间均为与现在时间相近的,符合观影者需求,所以推荐结果更容易被观影者接纳.

表5 相关模型推荐结果对比
文献[18]中所提及的3 种算法改进的SlopeOne 算法、组合协同过滤算法、SVD 和CURE 协同过滤算法的MAE 分别为:1.5、1.38、1.57;文献[19]中所提及的两种算法UIPPSCF 和UCF 的MAE 分别为:0.791、0.824;将SlopeOne 算法、组合协同过滤算法、SVD和CURE 协同过滤算法、UIPPSCF 算法、UCF 算依次定位M1~M5,联合NNRAM_7 算法其MAE 对比如图5所示.将NNRAM_7 的MAE 值与前5 种模型的MAE 值作对比发现,NNRAM_7 的MAE值比前5 种的平均降低了将近44%.
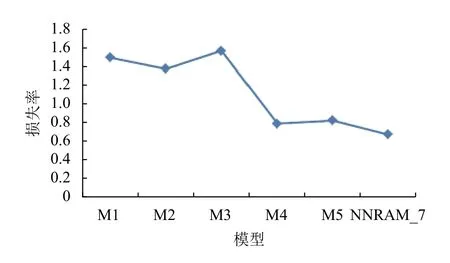
图5 传统及改进模型间MAE 对比
3.4 Tensorboard 实现可视化
在神经网络的训练过程中,可以通过Tensorboard来记录、监测每个epoch 的梯度值并以做出梯度消失、梯度爆炸等问题研究,可以实时检测每次循环后损失率的变化及走势,可以分析出权值的更新方向并判断其是否符合规律,继而对神经网络学习率等参数做出相应的设置和调整以解决现有问题.
(1)损失率(Loss)可视化
Loss 图像如图6所示,损失率随着迭代次数的增加在不断下降,下降过程虽然存在震荡,但整体持续下降趋势非常明显,损失率在不断降低.通过观测下降趋势,可以考虑继续加大训练次数以降低损失率,并且这一过程时间损耗并不明显.

图6 损失率与迭代次数的关系
(2)梯度更新
卷积层中权重曲线纵坐标表示训练次数,横坐标表示权重值,曲线说明权重值随着网络的训练也在波动做调整变化.良好训练的网络其偏置及权值反映在曲线上是美观、光滑的,曲线缺乏结构性则表明训练不够理想.电影标题先后两次池化过程中偏置bias 和权重weight 的直方图如图7所示,对比图像可知训练效果良好.
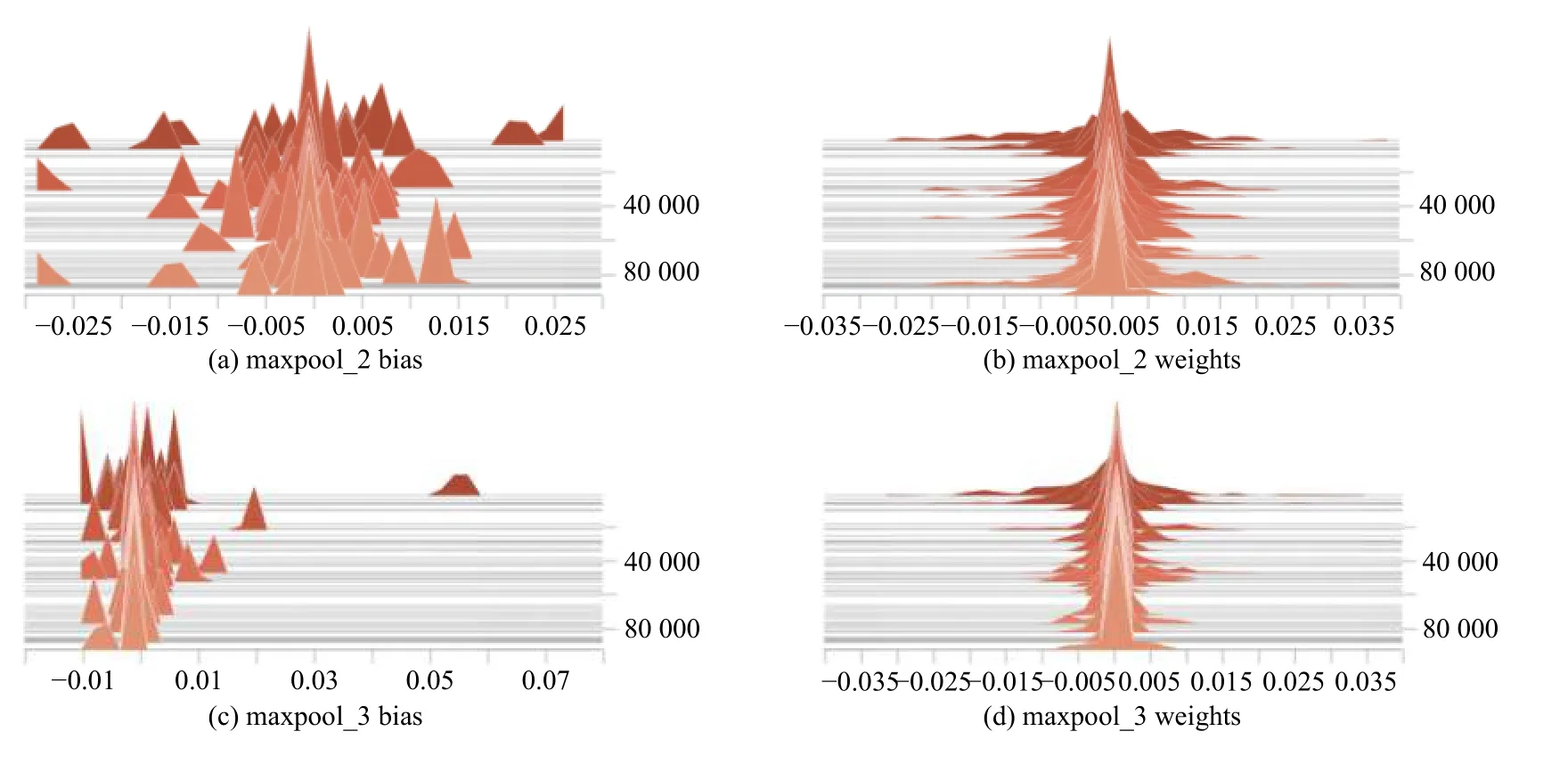
图7 电影标题池化过程中偏置bias 和权重weight 的直方图
4 结束语
本文尝试了将普通神经网络与卷积神经网络相结合应用于推荐过程中的方法,将特征提取的过程用卷积神经网络来实现,所形成的模型通过预测评分实现了准确率较高的电影推荐,且在推荐速度和推荐准确性等性能方面相对协同过滤推荐方法有大幅度提升,说明神经网络可以较理想的实现精准性更高的推荐结果,虽然在适度的有限循环内模型的损失函数及平均绝对误差呈现着明显的下降趋势,但还有待通过改进模型结构及调整参数取值进一步降低损失,使误差趋近于最低值.另外,可以考虑将时间戳字段中日期时间的所有信息取出参与数据挖掘,因为影评的及时性也体现出观影者对电影的情感深度,同时观影的日期时间等信息也暗含了观影者的其它诸多个人特征如职业及生活习性等,极具研究价值.
