基于FCN的图像中文字目标语义分割①
2020-06-20刘信良王静秋
刘信良,王静秋
(南京航空航天大学 机电学院,南京 210016)
数字图像是由有限像素值组成的二维矩阵,包含丰富的语义信息,自动识别图像中的目标,例如文字是当前研究的热点问题.图像文字识别技术是指利用计算机视觉等技术分离图像中文字与背景区域,并且准确识别文字内容的过程.该技术可将图像中的文字转化为可供计算机识别和处理的文本信息,减少人为参与,提高自动化程度.
图像文字识别技术一般先分割图像中的目标文字再识别其内容,目标文字分割的效果影响文字内容识别的准确度.林孜阳等[1]提出了一种结余连通域的目标文字分割算法,通过连通域阈值分析,将文本块联通,从而实现对难提取的文字分割.易小波[2]提出了一种图像二值化分割处理的方法,通过对图像特征的研究,选取适当的阈值对图像进行二值化,从而达到分割的效果.郑泽鸿等[3]提出将AP 聚类算法用于字符分割,根据类中心对特征点进行归类得到分割结果.上述算法运行速度快、对特定场景分割准确度高,但需要人为设定大量参数,且通用性较差、鲁棒性不足,在实际应用中仍然存在较多的局限性.
近些年,深度学习中的卷积神经网络被应用到众多领域,如图像分类[4,5]、目标检测[6,7]、目标追踪[8]、图像分割[9]等,取得了令人瞩目的成绩,逐渐成为研究的热点.Zhang 等[10]提出一种串联全卷积神经网络(Fully Convolutional Networks,FCN)[11]的方法,先用FCN 模型粗分割出文字区域,再用另一FCN 分类器预测出每个文字区域的中心位置,以去除粗分割时错误区域.此方法在稀疏文本下表现较好,但无法解决复杂文本重叠情况.
本文针对图像中文字逐点标注复杂费时的问题,设计一种简单的数据标注与增广方式,并且改进FCN 模型,结合大津法[12]及全连接条件随机场[13],实现对较复杂图像中目标文字的语义分割,为后续文字识别做准备.
1 图像文字语义分割算法
语义分割是指自动分割并识别图像中具有特定语义的目标物体的过程.如图1所示,将人和自行车作为两种语义类别,在图像中自动分割出属于这两类的所有物体,并标定其类别,其余部分当作背景.图像中目标文字分割也可以当作语义分割问题求解,将文字当作唯一的语义类别,其余当作背景,从而将文字从图像中分割出来.
1.1 图像文字语义分割算法流程
本文提出了一种基于全卷积神经网络的图像文字语义分割的算法,并采用大津法和全连接条件随机场进行修正处理.如图2所示,首先利用FCN 模型对输入图像进行初步分割,再用大津法对其二值化处理,最后使用全连接条件随机场修正,得到精细的语义分割结果.
1.2 基于FCN 的图像初步分割
FCN 模型是用于任意尺寸图像输入的语义分割模型,此模型包括图像特征提取编码和标记图像解码生成两个部分.图像特征提取编码是对图像高级语义特征抽象的过程,通过多层卷积和池化操作,删除冗余信息,提取出图像的本质信息.标记图像解码生成是对语义特征重建的过程,通过上采样操作恢复图像的原始尺寸,并得到每个像素所属的类别.
如图3(a)所示,本算法中的FCN 特征提取基础网络为VGG16 网络[14],利用13 个3×3 的卷积层和5 个最大池化层提取图像中抽象的语义特征,通常这些特征是整张图像的全局特征.同时,FCN 将VGG16 网络的全连接层用1×1 卷积层替换,以解决全连接层神经元个数必须固定的缺点,从而实现任意尺寸图像输入.由于图像特征提取过程经过了5 个最大池化,原始图像被缩小了32 倍,故需要用反卷积进行上采样,恢复成原始图像的大小.如图3(b)所示,第5 个池化层输出的特征图经过反卷积扩大2 倍后与第4 个池化层输出的特征图结合,将其结果反卷积扩大2 倍后与第3 个池化层输出的特征图结合,最后反卷积扩大8 倍生成预测标签图像.通常特征提取中间步骤的特征图包含着丰富的浅层特征,如边缘、纹理等,将此浅层特征与最终提取的深层抽象特征结合可以更加准确地分割物体.

图1 语义分割示例

图2 算法流程图
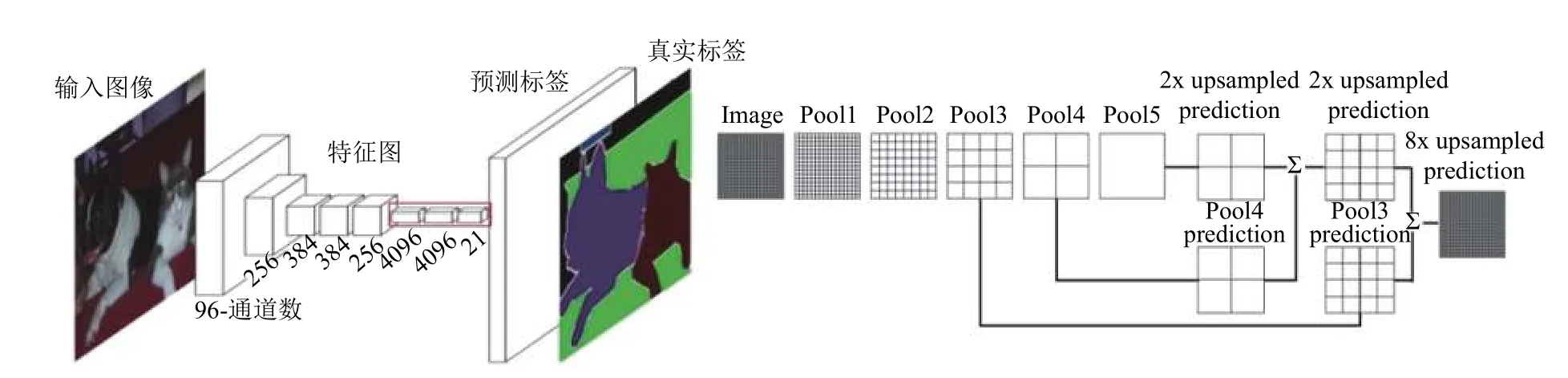
图3 FCN 整体结构
本文改进原有的FCN 模型,采用均方差损失函数,定义为式(1),其中yi为预测的标签值,yˆi为真实的标签值.采用此损失函数目的是利用回归的方式,使得最终特征图的目标值接近255,背景值接近0,通过前景背景较大的差异值准确分割出文字区域大体位置.
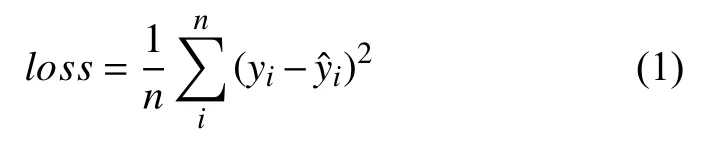
1.3 大津法二值化
大津法能够根据阈值将图像分为目标和背景两部分,通过计算目标和背景的类间方差,遍历所有灰度值寻找最佳阈值使得类间方差最大.对于带有文字的图像,假设属于文字的像素点数占整幅图像的比例为ωo,平均灰度为μo;背景像素点数占整幅图像的比例为ωb,平均灰度为μb.类间方差g如式(2)计算:

遍历0~255 各灰度值,计算并寻找类间方差的极大值即为文字目标与背景分割的最佳阈值.
1.4 全连接条件随机场修正
在本文中,对于一幅带有文字的图像,每个像素点i具有像素值Ii,对应的类别标签为xi,以每个像素作为节点,像素之间的关系作为边,构成了一个全连接条件随机场.其吉布提能量可以表示为:
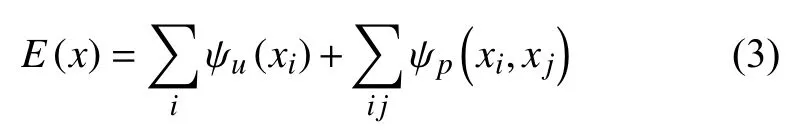
式中,ψu(xi)为一元势能,来自大津法二值化的输出,只与像素i自身相关,表述了像素i与其所属类别的差异度:
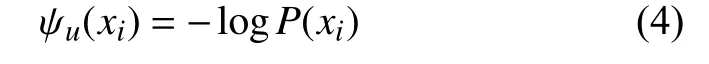
二元势能ψp(xi,xj)表达式为:

式中,∇1为外观核,p表示位置信息,I表示颜色信息,σα为用于控制位置信息的尺度,σβ为用于控制颜色相似度的尺度,通常在边界位置颜色有较明显的变化,因此位于边界两侧的像素不同类别的可能性较大;∇2为平滑度核,σγ为控制位置信息的尺度,此项只与位置信息有关,用于平滑去除一些孤立的小区域,通常这些区域不是文字区域.
本文提出的图像文字语义分割算法融合了改进的FCN 模型、大津法和全连接条件随机场,相比传统数字图像处理算法,此算法需要设定的参数少且能够适用复杂场景的文字分割.
2 实验
2.1 数据集准备
数据集图像中的目标文字主要有两种类型:光学字符(文字是由摄像设备输入)和合成字符(通过软件将字符合成到图像上).原版FCN 模型的数据集需要逐点标注目标的轮廓并给出目标的类别,对于图像集制作起来复杂、耗时,因此本文提出一种新的数据集制作方法:对原始数据集图像用最小四边形标记文字区域,即四边形包围区域设为目标,像素值为255,其余区域设为背景,像素值为0,如图4(a)、图4(b)所示;为扩充数据集,让分割结果更加准确,制作模拟合成字符图像,即准备一批无文字的背景图像,将文字集随机生成并合成到图像中,文字的类型包含中文、英文和数字,颜色随机生成,如图4(c)、图4(d)所示.数据集包含训练集,验证集和测试集,其中训练集有10 000 张图片,验证集和测试集各有1000 张图片.

图4 数据集示例
2.2 FCN 模型训练
本次实验的FCN 模型是用Tensorflow[15]框架搭建,实验平台为个人电脑,硬件为:i7-8700k CPU,16 GB 内存,RTX 2070 GPU.
训练时,所有图像和标签都被放缩为224×224,以32 张为一批送入模型中训练.应用指数衰减的学习率,初始学习率设置为0.001,衰减系数设置为0.9.优化策略采用随机梯度下降,共训练了50 000 次,耗时约11 个小时,其损失函数值的趋势如图5所示,从图中可以看出损失函数值随着训练的进行不断下降,最终稳定在一定数值.
2.3 实验结果及分析
如图6(a)、图6(b)所示,将FCN 初步分割结果转化为RGB 格式,亮色代表此区域为文字的概率值大,暗色代表此区域为背景的概率值大.从图中可以看出,亮色区域与图像中文字区域基本对应,越亮的部分代表着此区域是文字的概率越大;相反,暗色区域与图像中的背景相对应.接着,用大津法对FCN 初步分割结果进行二值化处理,计算得到使得目标/背景的类间方差最大的阈值分别为107、91、93.如图6(c),可以看出大津法大致将文字区域划分出来,但是划分结果较粗糙,存在错误标记区域.最后,使用全连接条件随机场进行结果修正,如图6(d)所示,可以看出经过全连接条件随机场后处理的图像能够提升分割的结果,将大津法处理后的粗糙结果细化,更正了误识别区域,为后续文字内容识别做好准备.然而,此算法仍存在一定漏检和误检的问题,分别如图6中第2 行与第3 行矩形框所示.

图5 训练时损失函数曲线

图6 实验结果
图7为本文提出的算法与“FCN+全连接条件随机场”算法对比结果.“FCN+全连接条件随机场”算法的结果记为对照组,即采用FCN 模型进行初步分割(采用交叉熵损失函数),再用全连接条件随机场进行后处理.图7(a)、图7(b)分别为两种算法的初步分割图,相较本文算法,对照组初步分割的结果较粗糙,有较多孤立的小片区域,且文字区域不够明显.最终分割结果如图7(c)、图7(d),对照组能够分割出文字,但是出现一些漏分割现象,如图中矩形框所示,且精细程度不如本文提出的算法.

图7 对比结果
由于验证集和测试集的标签类型如图4(b)所示,无法使用传统的图像分割的评判标准,如像素准确度、分割交占比(IOU)等,本文提出一种新的评判标准,评判步骤如下:
(1)先用OpenCV 对文字分割结果用最小矩形框集合,如图8(a)所示,矩形框内部即为目标文字区域.
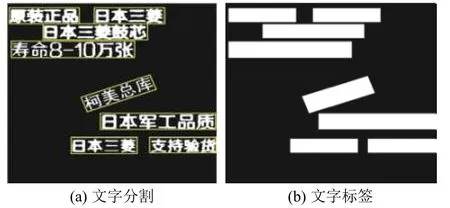
图8 评价结果图
(2)对真实标签的每个文字区域(如图8(b)),按照式(8)计算其对预测结果中每个文字区域的Ci,选取最大Cmax,并将取最大值时两个文字区域的索引值记录到集合I中.若Cmax≥60% 表示预测正确;若10%≤Cmax<60%预测错误;若Cmax<10%则表示漏检;若预测结果中文字区域的索引值未出现在I中,则此区域为误检.

其中,Sp表示预测的文字区域,St表示真实文字区域.
(3)错误总数(Nerr)为预测错误个数(Ne)与漏检个数(Nm)之和,准确率计算如下:

其中,Nc表示预测正确的总个数,Na为验证集/测试集文字区域的总个数
根据此项判断标准,实验结果如表1所示,可以看出整体的实验效果较好,没有出现过拟合的情况;同时,可以发现结果中误检数量较漏检数量多,可知本次实验提出的算法容易将类似文字的图案(背景)识别为文字(目标).本文算法的速度为0.181 s/幅,即5.5 fps,运行速度较快.

表1 图像目标文字分割准确率分析
3 结论
本文提出了一种基于改进全卷积神经网络的图像目标分割算法,此算法使用FCN 模型进行初步分割,再利用大津法进行二值化,最后使用全连接条件随机场进行修正.此算法在准确度和速度上都取得了较好的效果,在测试集上可以达到85.7% 的准确度以及0.181 s/幅的速度.
