基于残差和密度网格的簇心自确认聚类算法
2020-06-18陈胜发贾瑞玉
陈胜发,贾瑞玉
安徽大学 计算机科学与技术学院,合肥230601
1 引言
聚类算法是数据挖掘中最经典的算法之一,已经得到了许多学者的研究。聚类技术在许多领域得到了广泛的应用。在商业领域,它可以用来分析顾客的行为,为商业营销策略的制定提供重要的依据[1-2]。此外,在互联网电子商务领域,它可以用来分析符合用户浏览日志的相似客户的特征,从而帮助互联网商家提供更好的客户服务[3]。
聚类是将样本元素分为不同的簇,在同一簇中的元素都是具有较高的相似度,不同簇中的元素相似度低[4]。数十年来国内外专家学者对聚类算法进行了深入研究,已获得了相当好的成果。如基于划分的聚类算法[5]有K-means[6]、K-medoids[7]等;基于密度的聚类算法有DBSCAN[8]等;基于层次的聚类算法有CURE[9]等;基于网格的聚类算法有STING[10]等。
文献[11]结合密度峰值,提出了一种基于密度的Canopy算法,将改进的Canopy算法作为K-means算法的预处理过程,从而提高了K-means的聚类质量。文献[12]利用网格对数据空间划分并使用KL散度进行相似性度量,解决了不确定数据聚类问题(存在于障碍空间),并很好提升了算法的聚类效果。CCDDG算法[13]以网格化数据集空间,用网格对象代替数据对象,大大地降低了计算复杂度,但是最终的初始聚类中心和聚类数目还需要人工来选取。SNIC_K-means算法[14]利用样本点在数据集空间中的分布信息来确定数据集的聚类数目和初始聚类中心,但算法需要计算每个数据对象的密度值、距离值和残差,计算复杂度非常大。
2014年6月,Laio等人在Science发表了快速搜索和发现密度峰值的聚类算法(Clustering by fast search and find of Density Peaks,DPC)[15],该算法的思路是将具有局部较大密度且与其他密度更高的有较远距离的数据点视为聚类中心,通过快速搜索聚类中心,将每一个非聚类中心的数据点沿着密度递增的最近邻方向划分到对应的聚类中心中,实现数据划分。该算法与传统的聚类算法相比,具有较好的聚类效果,但存在以下的几个问题:(1)样本的密度取值依托于截断间隔dc;(2)需要计算所有样本间的距离,计算复杂度大;(3)需要通过人工监督的方式从决策图中选取出簇心对象。
为了解决文献[15]的三个问题,本文结合文献[13]和文献[14]的优点,提出了基于残差和密度网格的簇心自确认聚类算法(Self-confirming Clustering algorithm based on Residual Error and Density Grid,REDGSC)。该算法首先将数据集空间网格化,删除没有任何信息的网格对象;然后计算每个网格对象的密度值ρ和距离值δ;接着通过残差分析从计算得到的ρ和δ中决策出簇心网格对象;最后,根据一种密度距离的划分方式来对划分网格对象,再用与非边缘点的距离和自变动的阈值来处理网格边缘点和噪声点,完成数据集的聚类。
2 REDGSC算法介绍
2.1 密度网格思想介绍
将数据的每一维进行等距离划分,均匀划分成相同的段数,记为fG;将数据集空间分割成若干个超矩形网格对象,删除不含任何信息的网格对象,剩余的网格对象就是所需要的,记为G;网格对象的个数记为NG。经过多次实验表明,当网格对象数量NG大于或等于数据集中的数据对象个数n的1/8时,算法的聚类效果最佳。图1为二维数据集的网格化结果。网格化具体步骤如下:
步骤1将含有n个数据对象的数据集空间中每一维划分成相同段数,记为f(初值为2),形成网格。
步骤2删除不含任何信息的网格对象,剩余的记为N。
步骤3如果N<n/8,则让f=f+1,然后返回步骤1。
步骤4最后确定网格对象集G,划分段数为fG,网格对象数NG。
图1 二维数据集的网格化
确定网格对象集后,接下来就是如何计算网格对象的密度值ρ和距离值δ,相关定义如下:
定义1(密度值)将网格对象i中的数据元素个数作为密度值,记为ρi。
定义2(网格对象距离)网格对象i和网格对象j之间距离为:

其中,xi和xj为网格对象i和网格对象j中的数据对象的平均值;xip(i=1,2,…,n;p=1,2,…,d)代表网格对象i的第p维属性;d为数据的维数。
定义3(距离值)δi表示网格对象i到具有更高密度值的网格对象j的最近距离。如果网格对象i的密度值为最大值,δi定义为max(dij);如果网格对象i的密度值不是最大值,δi被定义为min(dij),具体定义如下:
2.2 决策图介绍
在Rodriguez和Laio在Science期刊上提出的聚类中心在与具有更高密度值的数据对象之间具有较大的距离δ且具有较高的密度值ρ的假设下,REDGSC算法网格化数据集空间后,含有簇心的网格对象也是具有较高的密度值ρ和较大的距离值δ。通过定义1和定义3,计算出每个网格对象的密度值和距离值,构造出网格对象的δ和ρ的决策图,如图2所示。
通过图2,人工很容易认为最偏离的两个点就是含有簇心的网格对象。但是这样人工选取的方式非常不智能化而且还比较繁琐,所以本文引入了残差分析的方法来自动决策出含有簇心的网格对象。
2.3 残差分析确认簇心
图2 ρ和δ的决策图
从2.2节的决策图中可以很容易地看出簇心所在的网格对象,但是这属于人工选取,并且这也是文献[15]的思想中的一个缺陷。为了能自动从网格对象集中获取较大的ρi和δi的网格对象,进而引用统计学中的残差分析和线性回归,利用规范化残差来自动获取含有簇心的网格对象。相关概念如下:
概念1研究变量间函数关系是回归分析中的一种方法。设响应变量为Y,以X1,X2,…,Xp表示预测变量,其中p是预测变量的个数,Y与X1,X2,…,Xp的关系可以用以下回归模型来描述:

其中,ε为随机误差,是模型不能高精度拟合数据的缘由。函数f(X1,X2,…,Xp)描述了Y与X1,X2,…,Xp之间的关系。
概念2响应变量Y的拟合值Y*是使用拟合函数获得的值,其表述如下:

例如,假设用以下线性模型:

来拟合某二维数据集中变量xi和yi的关系,则响应变量yi的拟合值如下所示:

概念3残差是拟合值减去观测值的相反数,残差ei的定义如下:

其中,yi和分别是xi对应的观测值和拟合值。
在回归分析中,测定值减去由回归方程预测出来的值所得到的值,以δ0表示。残差δ0遵从正态分布N(0,σ2);(δ0)/标准化残差,称为规范化残差,以δ*表示;δ*服从标准正态分布N(0,1)。若某一网格对象的规范化残差的值在(-1,1)区间之外,则该网格对象一定是异常的,这个定论在统计学的书籍[16]中有介绍过。
从决策图中获取具有较大的ρi和δi的网格对象,就是在决策图中找到异常点,因此找到合适的回归模型是非常重要的,从而求出决策图中每个网格对象的残差,并将残差进行规范化,则规范化残差的绝对值大于1的网格对象就是含有簇心的网格对象。
图3是图2中数据的走势图,从图2中可以看出,几乎所有网格对象对应的点都靠近ρ轴和δ轴,并且这些点分布在一条反比例曲线周围,因此本文使用函数δ=a0+a1×(1/ρ)来拟合ρ和δ的关系。通过图3可以看出除了可以被确认为含有簇心的网格对象外,大部分数据点都集中在反比例曲线上。运用残差分析从决策图中得到具有较大的ρi和δi的数据对象的步骤流程如下:
步骤1用函数δ=a0+a1×(1/ρ)来拟合决策图中δ和ρ的函数关系。
步骤2令ρ*=1/ρ,可将步骤1中的拟合函数线性化为δ=a0+a1×ρ*。
步骤3根据步骤2中的拟合函数来拟合数据点,然后计算每个网格对象对应的数据点的残差ei。
步骤4将步骤3获得的残差进行规范化。
步骤5通过比较计算得到规范化残差的绝对值大于1的网格对象对应的数据点,这些网格对象对应的数据点就是含有簇心的网格对象。

图3 决策图的数据走势图
图4 是图2中数据点的规范化残差图,以ρ*为横轴,标准残差δ*为纵轴。在图4中,在两条虚线外有两个数据点,也就是说这两个网格对象就是含有簇心的网格对象。

图4 决策图的规范化残差图
至此,已经较好地解决了自动选取网格对象集中含有簇心的网格对象的问题。
2.4 聚类过程
在自动选好簇心网格对象后,首先为每个簇心网格对象标上不同编号,然后根据已经计算出来的每个网格对象的密度值ρ,将剩余的网格对象的标号跟随距离最近且密度值更高的已经标号的网格对象,这样就可以很快地完成网格对象集的聚类,网格对象集的聚类完成也就是整个数据集的聚类完成。
2.5 边缘点和噪声
2.5.1 边缘点处理
对于边缘点的处理,首先就是选取出边缘处的网格对象;然后计算所有非边缘数据对象到选取出来的边缘网格对象中每个数据对象之间的距离;接着就是将这些边缘网格对象中的数据对象标上和它们距离最近的非边缘数据对象一样的编号,这样就完成了边缘点的处理。
2.5.2 噪声处理
由于噪声点一般都是离群点,网格化数据集后,噪声点都是处于边界网格对象内,所以对于噪声点的处理,这里是用自动变换的阈值来代替人工设定的噪声点阈值。首先就是找到簇与簇之间的边界网格对象,然后将边界网格对象中密度最大值作为阈值,记为ρb,只要是密度值低于ρb的网格对象,就视为噪声点,将其删除。将边界网格对象中密度最大值作为阈值,这样就能很好地去除大部分噪声点,并省去人工设定阈值的麻烦,虽然这样的设定有可能将一些有用的信息删除,但是通过实验证明,聚类准确度得到了很大的提高,这是因为噪声点会对聚类精度产生很大的影响,在牺牲一些有用的信息的同时可以删除大量的噪声点,所以聚类准确度得到很大的提高。
3 算法流程和仿真实验
3.1 算法流程
本文提出了一种基于残差和密度网格的簇心自确认聚类算法。首先网格化数据集空间,删除没有任何信息的网格对象;然后就是通过残差分析自动获取含有簇心的网格对象;最后通过密度距离的划分方式进行聚类操作。
REDGSC算法的处理流程如下:
步骤1输入数据集D={x1,x2,…,xn}。
步骤2根据2.1节中的网格化步骤来网格化数据集空间,得到网格对象集G={X1,X2,…,Xn}。
步骤3根据定义1和定义3求出G中每个网格对象的ρi和δi。
步骤4运用线性函数δ=a0+a1×ρ*(其中ρ*=1/ρ去拟合ρi和δi的关系。
步骤5计算每个网格对象的残差,并规范化所有残差。
步骤6从规范化残差中,通过计算选出残差绝对值大于1的网格对象,这些被选出来的网格对象就是含有簇心的网格对象。
步骤7根据2.4节和2.5节,并以步骤6中获得含有簇心的网格对象,对G中的网格对象进行聚类。
步骤8输出聚类结果。
详细算法流程图如图5所示。
3.2 仿真实验与分析
3.2.1 性能对比
为了测试本文算法的聚类性能,实验采用7个不同分布的人工数据集AD1、AD2、AD3、AD4、AD5、AD6和一个UCI数据集Iris,7个数据集的参数描述如表1所示。本文算法使用的聚类准确率R为正确分类的数据对象个数占总数据对象个数的百分比。实验中每个算法在每个数据集上都运行10次,在这10次运算中,获取平均算法执行时间Ta、平均聚类准确度Ra、最高聚类准确度Rmax和最低聚类准确度Rmin,在这里对于算法执行时间的计算,并没有考虑CCDDG和DPC两个算法的人工决策出聚类簇心的时间。
表1 7个数据集的具体描述

图5 算法流程图
AD1~AD6数据集的二维分布如图6所示。AD1~AD6数据集网格化后网格对象对应的规范化残差的ρ*和δ*分布如图7所示,Iris对应的ρ*和δ*分布如图8所示。
本文以CCDDG算法、DPC算法、SNIC_K-means算法和REDGSC算法,在给出的7个数据集上进行对比实验,以测试本文算法的聚类性能,实验结果如表2所示。
3.2.2 算法执行时间分析
由表2的实验结果可知,使用网格化数据集空间的REDGSC算法和CCDDG算法在7个数据集上的平均执行时间都小于DPC算法和SNIC_K-means算法,其中当数据量相对较大(达到2 000以上)的时候,执行时间下降了30倍以上。对于REDGSC算法在执行时间上大于CCDDG算法,这是因为本文算法添加了残差分析来自动确认簇心和对于边缘点和噪声的处理,这两个操作增加了本文算法的执行时间。
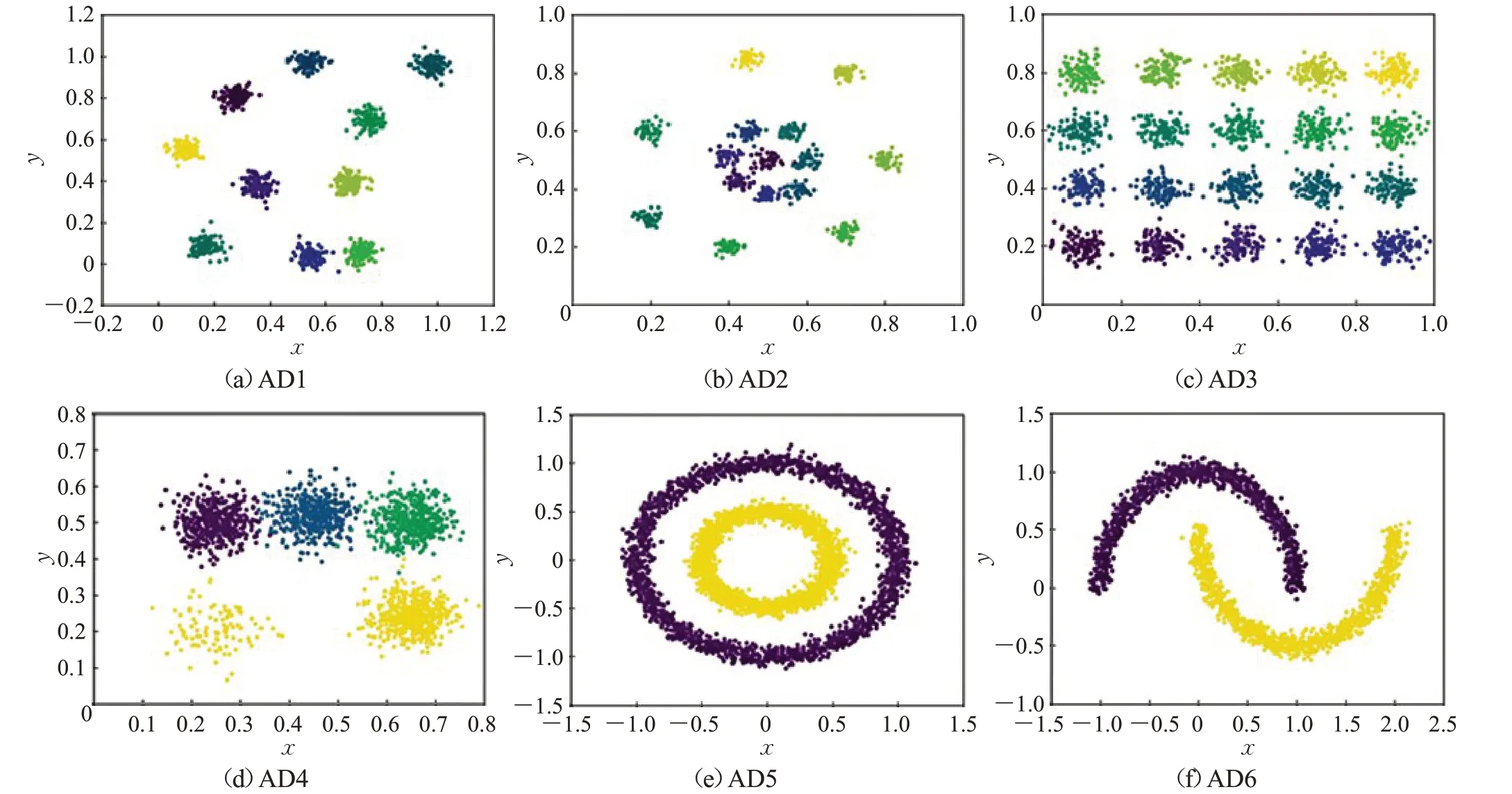
图6 6个数据集的二维分布图

图7 6个数据集的网格对象对应的规范化残差ρ*和δ*分布图

图8 Iris对应的ρ*和δ*分布图
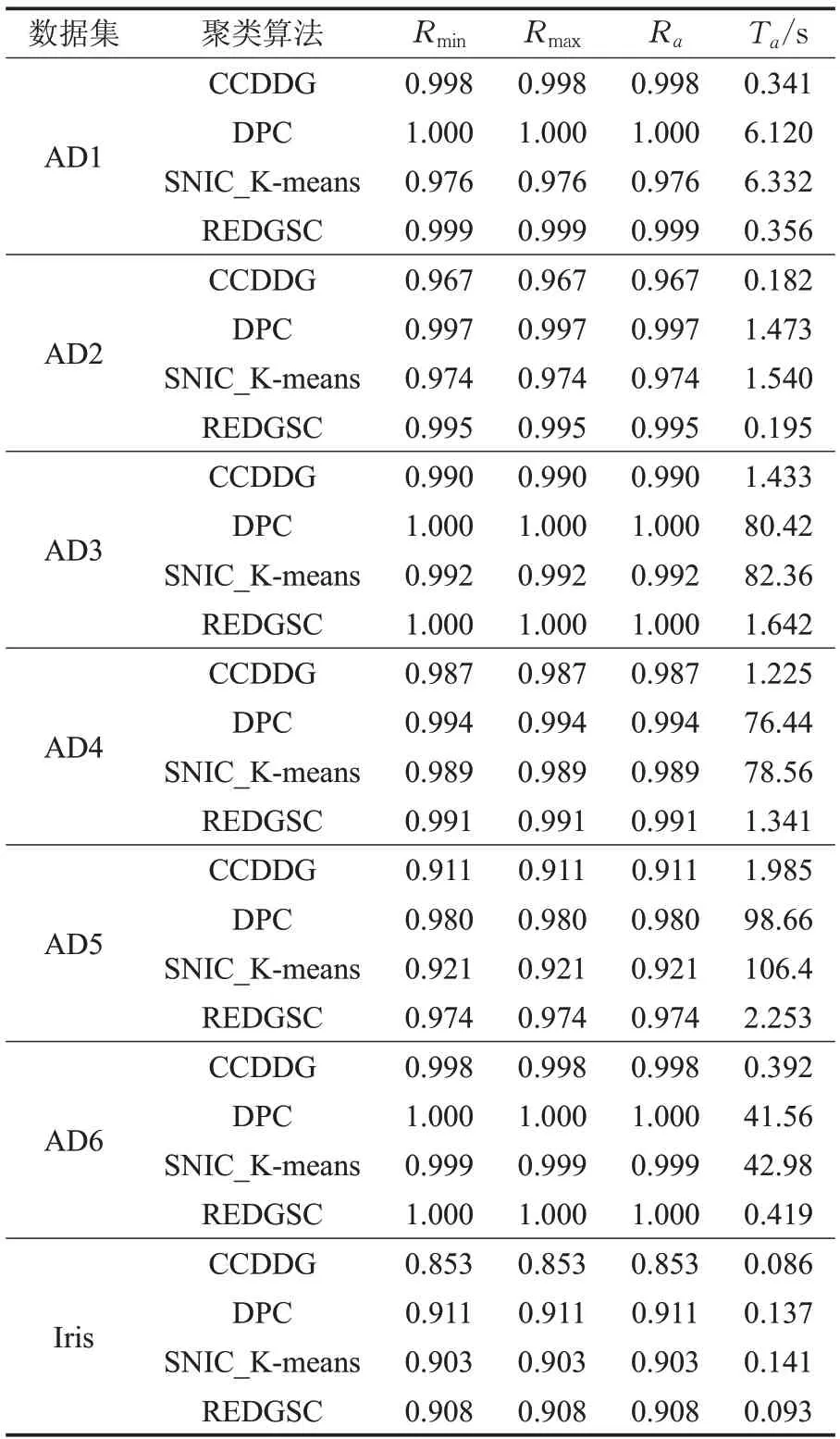
表2 4种算法在7个数据集的实验结果
3.2.3 算法复杂度分析
设聚类数据集是一个含有n个m维的数据集,首先算法对数据集进行网格化并得到网格对象的密度值,这个过程的计算复杂度为O();然后计算每个网格对象的距离需要的计算代价为O((N2-N)/2),算法进行一次距离密度的划分完成聚类,其计算代价为O(N lg N+N/2);接着就是边缘点和噪声处理的过程的计算代价为O(bn+aN),其中b表示边缘点的个数,a表示簇与簇之间的边界网格对象个数;最后就是线性回归和残差分析的计算代价O(N2+N)。因此REDGSC算法的算法时间复杂度为O(+N lg N+3N2/2+N+bn)。
由表3可以分析得到:相比SNIC_K-means和DPC,REDGSC算法有着较低的时间复杂度,所以在执行速度方面,REDGSC算法相比前两个算法,有着较快的表现;而相比CCDDG算法,REDGSC算法有着较高的时间复杂度,这是因为线性回归和残差分析的过程中消耗了部分时间。但REDGSC算法的优势:(1)能够自动确定簇心而不是人工选取;(2)确定含有簇心的网格对象后,利用一种密度距离的划分方式进行类簇的划分,这就使得REDGSC算法对于任意形状分布的数据集都有着较好的聚类效果。

表3 算法时间复杂度对比表
3.2.4 实验结果分析
综上7个数据集的实验结果,可以看出REDGSC算法在聚类准确度和时间复杂度上都优于SNIC_K-means算法,这是因为REDGSC算法网格化数据集,将网格对象作为聚类对象,大大地降低计算复杂度,而且还进行了边缘点和噪声的处理,从而提高了聚类准确度。相比于CCDDG算法,REDGSC算法解决了CCDDG算法需要人工选取聚类中心的弊端,并在聚类准确度上高于CCDDG算法,这是因为REDGSC算法在网格化数据集后,在聚类的过程中进行了边缘点和噪声的处理。
对于REDGSC算法在聚类准确度上稍微低于DPC算法,是因为网格化数据集空间时,会有可能将不同簇的数据对象分到一个网格对象中,虽然REDGSC算法在后续操作中进行了边缘点和噪声的处理,但是这样的处理并不能处理所有的情况,所以在聚类准确度上会有所降低,但是REDGSC算法很好地解决了DPC算法的三个缺陷(依赖截断距离dc、计算复杂度高和需要人工选取聚类中心)。
4 结语
本文提出了一种基于残差和密度网格的簇心自确认聚类算法。该算法将数据对象映射到网格上,用网格对象替换数据对象进行聚类计算,这样大大减少了聚类过程中的计算量,加快了算法的执行速度。在算法聚类的过程中,采用一种密度距离的方式来划分网格对象,这样使得本文算法对于任意形状分布的数据集都有着较好的聚类效果。而且在网格化数据集空间后的聚类过程中,对边缘点和噪声进行了处理,很好地提高了聚类准确性。通过实验表明本文算法在保持着聚类准确度的前提下,很好地解决了DPC算法的三个缺陷。
由于本文算法在聚类准确性上低于DPC算法,因此,未来的研究就是提高算法的聚类准确性。
