双网络模型下的智能医疗票据识别方法
2020-06-18郑祖兵盛冠群唐新功李长晟
郑祖兵,盛冠群,,谢 凯,唐新功,文 畅,李长晟
1.长江大学 电工电子国家级实验教学示范中心,湖北 荆州434000
2.长江大学 电子信息学院,湖北 荆州434023
3.油气资源与勘探技术教育部重点实验室(长江大学),武汉430100
4.长江大学 计算机科学学院,湖北 荆州434023
1 引言
随着现代社会医疗水平的提高,每天有大量医疗票据需要录入计算机存储与处理。传统方式为人工将票据中数据录入计算机,其成本高、效率低,票据录入工作任务重、强度大,极易导致录入人员疲劳致使工作出错。医疗行业迫切需要一种自动票据识别录入方法。
在票据识别领域:Wei等[1]提出了通过集成稀疏编码和矢量量化(VQ)技术开发的紧凑型MQDF分类器,在没有精度损失的情况下实现了低存储空间的手写汉字分类;Song等[2]提出了应用图像滤波的银行票据单号识别方法,对彩色纸币图像进行图像增强处理,应用模式匹配方法对单号信息进行准确地提取;谢文彬等[3]通过建立一种基于结构特征的分类器,根据票据中每个单号的结构特征值,能对发票单号进行分类识别;薛峰[4]提出了一种针对银行票据的自动识别系统,用以提取票据中部分信息。目前国内外学者对于票据识别的研究较少,上述票据识别方法只能识别票据中部分信息(如票据单号),无法完成对全部信息的提取识别,且现阶段票据识别方法均是针对标准的打印字体,其字体规范、无断点、易于辨认,而医用针式打印机打印出字符笔画含有断点、分辨率低,如图1所示,现有的方法难以准确识别此类不规范的字体。

图1 针式打印字体效果图
在深度学习领域:Yang等[5]从实例感知分割角度提出了一种端到端场景文本检测器IncepText,并引入了可变形的PSROI池化层来处理面向多向的文本检测,解决了场景文本中的宽高比、比例和方向不确定造成的识别精度低的问题;Zhu等[6]提出了滑动线点回归(SLPR)方法,以检测自然场景中的任意形状的文本;Dai等[7]提出了面向多向场景的神经网络文本检测方法,在特征提取过程中结合了多级网络的特征,使得模型具有更精细的特征表达;Zhang等[8]提出了一种新的基于轨迹的激进分析网络(TRAN),利用字符的固有结构特点,首先识别自由基并同时分析基团之间的二维结构,然后通过基于内部自由基的分析来识别汉字;李伟山等[9]以Faster-RCNN算法为基础,对候选区域网络(RPN)结构进行了改进,提出了一种“金字塔RPN”结构来解决井下行人检测存在的多尺度问题,同时算法中加入了特征融合技术,将不同卷积层输出的特征图进行融合,增强煤矿井下模糊、遮挡和小目标行人检测的性能;史凯静等[10]提出一种基于FasterRCNN的前方车辆检测方法,能准确定位与识别出不同交通环境场景下的前方车辆。上述方法应用神经网络于字符、图像识别领域,能实现快速准确的识别,虽然识别目标受环境的影响较大,但神经网络模型具有较强的鲁棒性,模型均能维持稳定较好的识别效果。
目前国内外尚无成熟的医疗票据处理系统,且传统票据识别大多采用模板匹配方法,灵活性差;深度学习的应用广泛,基于深度学习的目标检测研究较为深入,传统的神经网络目标检测方法基于单网络进行物体的定位与识别,对于简单且类别数较少的分类任务,单网络方法能减小网络的参数量和复杂度,但对于复杂背景下的多目标检测任务,如字符识别任务,其需要进行大规模的定位与识别,单网络的同一参数值既难以描述位置信息又难以描述类别信息,且普通的浅层网络难以实现此类复杂需求,随着网络层数的加深,网络的参数量呈几何倍数增加,当参数量过大、层数过深时导致网络庞大、难以训练。
基于以上分析,本方法将深度学习与票据识别相结合,提出了基于FasterRCNN与深度卷积神经网络的双网络模型针式打印字体医疗票据识别方法,分步实现定位与识别,避免了因网络层数过深导致的梯度消失或梯度爆炸的问题,针对票据中的全部信息进行准确识别。此外,本文还提出了自适应学习策略与新型票据矫正方法以提高双网络模型的性能。
2 双网络模型票据识别方法
本文采用FasterRCNN与深度卷积神经网络相结合的双网络模型进行票据中字符的定位识别。层数较深的神经网络模型在训练的时候容易出现梯度消失(gradient vanishing problem)或梯度爆炸(gradient exploding problem)的问题,且随着网络层数的增加变得越来越明显,这是因为深度神经网络在反向传播的过程中,根据链式求导法则[11],梯度会随着反向传播层数的增加而呈指数衰减或增长趋势,从而导致梯度消失或梯度爆炸。在复杂特征多分类任务上,本文方法通过使用双模型来降低网络深度。

图2 使用双网络模型进行票据识别算法原理图
本方法只需标记不同区域的类别与位置就能生成文本定位训练集,字符识别训练集由程序基于字体文件自动生成,数据集制作难度低、工作量小。
利用双网络模型进行票据识别的算法流程如图2所示,主要分为:(1)构建文本定位网络模型;(2)构建字符识别网络模型;(3)票据图像处理与基于双网络模型的票据识别。
2.1 文本定位网络模型
2.1.1 票据数据集制作
医疗票据中的信息分为出厂印刷内容和后期打印内容。在构建票据识别系统时,固定格式的出厂印刷内容预先导入数据库,识别阶段只需处理后期打印的医疗信息。本方法预先采集了3 000张具有完整信息的医疗票据图像用以制作数据集,根据票据的版面信息标定文本位置并标注所属类别,如图3,以生成用于文本定位网络训练的票据训练集。

图3 文本位置标定示意图
2.1.2 构建文本定位网络
文本定位模块采用基于VGG16[12]的FasterRCNN,其包含13个卷积层,如图4,适中深度的卷积层既能保证网络有足够的参数拟合字符的深层次特征,又避免了网络过深引起的网络难收敛的现象。

图4 基于VGG16的FasterRCNN中的卷积层
FasterRCNN使用候选区域网络(Region Proposal Network,RPN)来生成检测目标的建议框,较传统的选择性搜索(Selective Search)建议框生成算法性能更优。RPN能学习预测建议框A与真实标记框G之间的差异,通过对建议框微调得到输出框G′,如图5,从而准确预测文本的位置。

图5 建议框位置回归示意图
针对票据中字符位置、大小不固定的特点,本方法对FasterRCNN网络结构做出了改进,使用多个1×1,3×3的卷积核来代替传统的3×3固定大小的卷积核,如图6,多尺度卷积核可有效融合图像不同尺寸的相邻区域的特征,大卷积核提取图像的全局性特征,小卷积核提取图像的局部特征,使网络捕获图像特征的能力更强,模型的文本检测能力大幅提升。

图6 多尺度卷积核示意图
2.1.3 网络训练与测试
在网络训练过程中,将票据训练集作为网络的输入,记网络的输入为∅(Ai),平移量为(tx,ty),尺度因子为(tw,th),学习率为λ,网络需要学习的参数为w,则损失函数[13]表示为(*表示x,y,w,h):

网络的优化目标为:

则网络通过反复迭代,利用误差的反向传播来更新网络参数w*。
本文提出了基于inv学习策略[14]改进的自适应学习策略(adaptive learning rate),其规定了网络在第iter次迭代时的学习率lriter可表示为:

其中,baselrgamma power均为人工设定值,baselr为网络初始学习率,gamma为控制曲线下降的速率,power为控制曲线在饱和状态下学习率可达的最低值,iter表示网络当前迭代次数。
自适应学习策略的优势在于学习率在每次迭代时都会有细微变化,当loss下降时学习率会减小,而当loss上升时学习率会增大,由于随机梯度下降法[15](Stochastic Gradient Descent)在更新参数时不一定会按照正确的方向进行,自适应学习率能在loss上升时增大学习率,较大的学习率有利于跳出局部最小值,到达全局最低点,从而使网络能更快地找到梯度下降最快的方向。选取的参数:gamma=0.01,power=0.75。
当网络进行了15000次反复迭代时,误差小于1×10-3,此时认为网络已经拟合,停止网络训练。利用测试集测试网络性能,模型能对字符所在位置进行精准的标注。
2.2 字符识别网络模型
2.2.1 字库数据集制作
本方法采用国标一级字库和医疗术语字库共4 200类字符,通过程序自动生成字库图像,并联合高斯模糊、腐蚀等多种图像处理方法处理字库图像,模拟针式打印字体,使得用于训练的字库数据集最大程度地接近真实票据中的字体,再对字符图像进行类别标注,生成用于字符识别网络训练的字库训练集(图7为算法实现流程图),贴近真实票据字体的训练集训练得到的网络模型的识别率高。

图7 字库数据集的制作流程图
2.2.2 构建字符识别网络
字符识别网络通过增加网络的层数来增强网络的学习能力,从而获得更好的特性表征。网络采用自适应矩估计(Adaptive Moment Estimation,Adam)优化算法[16],Adam算法综合考虑梯度的一阶矩估计[16](First Moment Estimation)和二阶矩估计[16](Second Moment Estimation)来动态调整网络中每个参数的学习率,设mt与vt分别为梯度一阶矩估计与二阶矩估计,学习率为η,为防止分母为零设置ε为平滑项,则对于t+1时刻,其参数更新规则可表示为:

Adam优化算法下网络通常仅需微调其超参数就能拟合,选取的参数为:学习率α=0.001、一阶矩估计的指数衰减率β1=0.9、二阶矩估计的指数衰减率β2=0.999和参数ε=1×10-8。
字符识别网络采用“标签平滑归一化”(Label Smoothing Regularization)方法[17]对真实标签进行改造,使其不再是one-hot形式。在one-hot形式下,4 200分类任务中某类标签的表示形式为:

网络输出的预测概率为:

其中,zi为未被归一化的对数概率,q为样本的真实类别标签概率,则交叉熵损失表示为:

训练目标是最小化损失函数,网络需要用预测概率去拟合真实概率,因为one-hot中全概率和零概率使得本类别与其他类别的差距达到最大值,当训练充分时,网络容易过拟合,最终会造成模型过于相信预测的类别。为防止模型把预测结果偏向于概率较大类别上,“标签平滑归一化”方法将零概率替换为一个较小的数ε,将全概率替换为较接近的数1-ε,而使得网络不会完全贴近训练数据,从而降低了网络过拟合的风险。
2.2.3 网络训练与测试
在网络训练阶段,将票据训练集作为网络的输入,采用“Xavier”方法[18]初始化网络权重,使得网络参数能获得一个合适的初值以利于网络中传递信息的流通。设定权重初始化的范围为[-a,a],“Xavier”方法需使得网络每一层输出的方差尽量相等,则方差为:

设第k层网络有n个参数,则采用“Xavier”方法会将参数初始化为内的均匀分布。
当网络进行了10 000次反复迭代时,误差小于1×10-4,此时认为网络已经拟合,停止网络训练。利用测试集测试网络性能,模型能对字符进行准确的分类。
2.3 票据识别
票据识别的流程如图8所示。
2.3.1 票据校正
本文设计了的新型票据校正方法,其算法流程如图9所示。

图8 票据识别流程图

图9 票据校正方法流程图
Roberts算子定位边缘精度高,但其抗噪声能力弱,而在票据的边缘检测过程中,票据中字符、折痕、污渍、拍摄时产生的噪点等都可能成为噪音而干扰票据边缘的检测。在进行边缘检测之前先采用高斯滤波对图像进行平滑处理,滤除噪音。记σ为正态分布的标准差,参数σ决定了平滑程度,则对于图像中任意一点(x,y),二维高斯滤波的如公式(8)所示:

对于降噪后的图像,采用Roberts算子检测图像中票据的边缘。最后对图像中票据边缘所在的直线进行霍夫变换(Hough Transform),将原始票据图像的边缘直线映射为参数空间的一个点。于是笛卡尔坐标系中的直线检测问题转换为在极坐标下寻找对应数量的曲线的交点的问题,如图10,由交点在极坐标系中的位置可求得票据的倾斜角度。
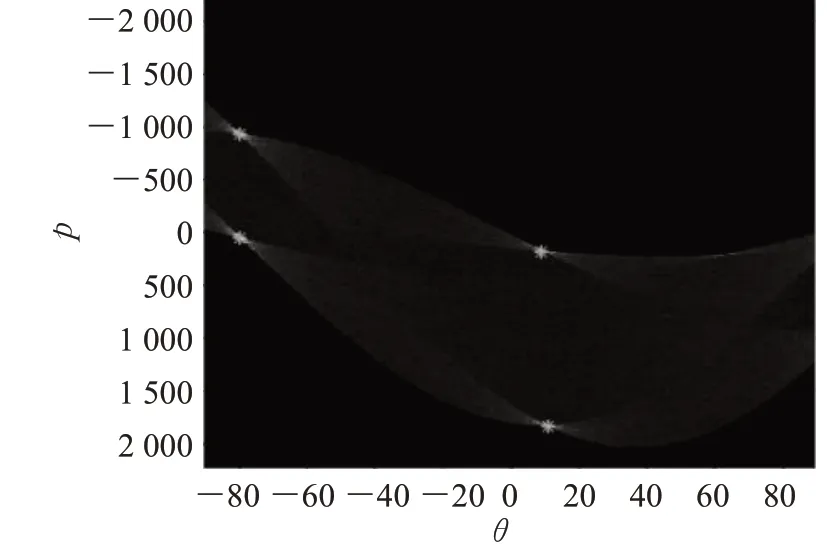
图10 霍夫变换检测边缘结果图
2.3.2 检测定位
本方法使用FasterRCNN模型进行文本定位,将预处理后的票据图像输入网络,模型将定位出不同类别字块的位置信息,根据文本定位结果对票据图像进行切分,实现了票据图像中的待识别的文本与无关背景的分离。由于文本的定位功能由FasterRCNN模型单独实现,因此对于不同类型的票据的识别,无需重构整个系统,只需采集少量票据训练网络进行微调,就能迁移至不同类型的票据的识别,模块化的设计增强了系统的灵活性。
2.3.3 文本分割与处理
对字块图像进行颜色分割[19],只保留后期打印内容,进行平均法灰度化与阈值法二值化处理,获得清晰的字符轮廓。
进行基于垂直投影直方图的字符分割,按照投影的间隔切分字块为单字符图像,如图11所示。

图11 垂直投影切割示意图
2.3.4 字符识别
利用字符识别网络模型对单字符图像进行识别,该网络学习了针式打印字体的深层特征,网络的参数量足够庞大,因此即使字符类别数较多,在不同参数学习到不同目标的特征的情况下,网络仍然能准确地进行数千类字符的分类。因为在文本定位阶段保留了票据原始的版面信息,所以识别结果仍可按照票据版面中的个人信息、金额等进行结构化分类存储于数据库之中。
3 实验与结果分析
双网络模型的具体应用方法如图12所示,分为离线部分与在线部分,离线部分通过GPU运算服务器进行模型的训练,在线部分通过医院端采集发票信息,上传至服务器后进行识别,识别结果传回医院端显示。
3.1 实验运行平台
本实验采用的硬件平台及软件平台见表1所示。
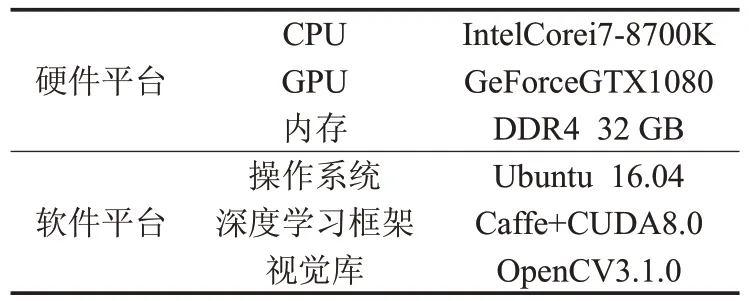
表1 实验运行平台配置
本实验的流程如图13所示。
3.2 网络参数设定
3.2.1 不同学习率对测试准确率的影响
本实验利用现场采集的票据图片,测试了不同学习率下模型的识别准确率,见图14,学习率太大会导致梯度爆炸或者震荡剧烈,学习率太小会导致参数更新缓慢且难以找到梯度下降最快的方向,依据实验结果,网络采用的学习率为0.001,使模型的识别准确率最高。

图12 具体应用方法图

图13 实验流程图

图14 不同学习率下的模型测试正确率
3.2.2 不同激活函数对网络收敛速度的影响
ReLU函数[20](公式(9))在输入x为正数的时候,不存在梯度饱和问题,且只存在线性关系,而Sigmoid函数[21](公式(10))和Tanh函数[22](公式(11))都存在指数关系,在前向传播与反向传播过程中,ReLU函数速度也是最快的。实验测试了不同激活函数对网络收敛速率的影响,见图15,根据实验结果,本方法采用了使网络收敛最快的ReLU激活函数。

图15 不同激活函数对网络收敛速度的影响
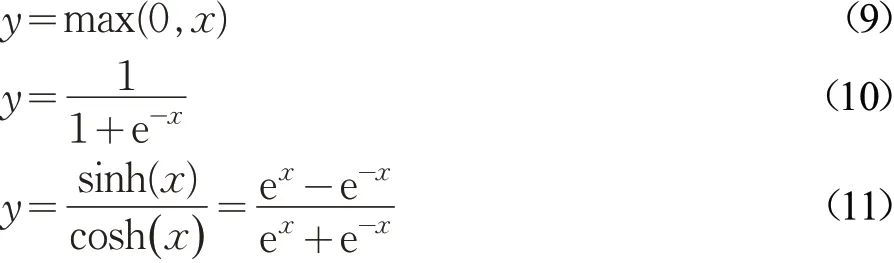
3.3 不同校正方法效果对比
图16所示为几种不同算子的票据边缘检测效果对比结果。可以看出Roberts算子在边缘检测方面的效果更好,边缘轮廓更明显,结合本文对票据边缘精确检测的需要,选用Roberts算子来检测图像中票据的边缘。

图16 不同边缘检测算子的检测效果对比图
实验将本文图像校正方法、旋转投影法[23]和Radon变换法[24-25]进行对比分析,结果见表2,其中,以水平方向为标准位置,数值为正表示校正后的顺时针角度误差,反之为逆时针误差。

表2 在不同票据图像状态下的校正结果
本文设计的校正方法选取Roberts算子检测边缘,为霍夫变换提供了清晰的边缘直线,使得变换结果中峰值明显。由表2可知,本文校正方法的校正效果比传统方法更精准。
3.4 模型性能分析
利用现场采集的50张票据测试本方法性能,测试结果如表3所示。
文本定位网络使用了多尺度的卷积核,其能学习目标不同粗细粒度的特征,使得定位时不会遗漏目标;网络中PRN层利用卷积神经网络提取特征并生成目标建议框,经过充分训练后其参数学习了目标的深层特征,更能贴合实际数据,能在复杂环境下精确定位目标,由表3可知,定位精度达98.6%;文本定位网络采用的自适应学习率策略,能够根据loss的变化动态地调整学习率的大小,合适的学习率使得网络迅速找到梯度下降最快的方向,并且一定程度上避免了网络陷入梯度的局部最小值情况的出现,因此,网络训练所需的时间大幅降低。

表3 待识别文本定位正确率
字符识别网络采用了深度卷积神经网络,其参数量大,大量参数能够准确拟合到字符的深层次特征,网络采用“Xavier”方法初始化权重,使得网络在初始状态就具有较合适的初始权重,节省了通过反复迭代调整权重所需的时间,网络训练时的速度有明显提升;“标签平滑归一化”方法使得网络在充分贴合训练数据的同时避免了过拟合,因此网络可以充分训练以学习到每个字符的特征,使得识别精度维持在较高水平;上述传统的方法只利用了图像的浅层特征,由表4可知,本方法的字符识别精度较传统方法提升了约3%~8%;由于神经网络只需通过对输入图像进行数学计算可直接得到最终结果,由表5可知,本方法识别速度优于其他方法。由于文本定位网络几乎能定位出所有字符,且字符识别的精度较高,由表7可知,在正常情况下本方法的字符识别召回率达92.7%。

表4 与传统字符识别方法的精度对比

表5 与传统字符识别方法的速度对比
训练数据集中不可能包含各种干扰下拍摄的票据图片,而在实际应用过程中,部分票据表面存在折痕与污渍,票据图像曝光不均衡,票据中字符打印内容相对于规定位置有不同程度的偏离,可见在实际过程中输入网络的数据摄动较大,如表6、表7所示,在不同的干扰环境下,票据识别的准确率浮动不超过2.4个百分点,召回率稳定维持在90%以上,当输入的信息发生有限范围的变化时,神经网络仍能维持稳定的输入、输出关系,这是由于双网络模型联合了两个网络模型分别实现定位与识别,而定位与识别模型均利用了图像的深层特征,数据的摄动被分散到两个模型上,因此输入数据的摄动对于结果的影响被限定在一定量的较小的程度上,使得网络具备较强的泛化能力与鲁棒性,并且由于数据摄动的影响被分散,使得单个网络模型的性能不会受到太大的影响,最终使得叠加的双模型识别精度高。

表6 在不同环境下的识别准确率

表7 在不同环境下的识别召回率
4 结束语
本文详细地描述了双网络模型下的票据识别方法,并通过实验验证了该方法的有效性。实验结果表明,本方法识别准确率可达95.4%,召回率达92.7%,识别速度达0.76 s/张,且模型具有较强的泛化能力。医疗票据识别系统搭建在高性能的GPU云端服务器上,任何具备图像录入功能的可联网设备均可作为客户端,实现了成本控制下的医疗票据识别。下一步的工作方向主要将为研究通用票据检测系统,以实现不同行业不同种类的票据的识别。
