基于改进型YOLO v3的蔬菜识别算法
2020-06-18魏宏彬张端金杜广明肖文福
魏宏彬, 张端金, 杜广明, 肖文福
(郑州大学 信息工程学院, 河南 郑州 450001)
0 引言
目前,目标检测主要包括传统目标检测技术和深度学习目标检测技术。传统的识别技术主要利用滑动窗口实现图片内目标的搜索,然后通过HOG(histogram of oriented gradient)或者SIFT(scale-invariant feature transform)手工设计特征输入到SVM[1]内进行识别。多尺度形变部件模型(DPM)[2]的提出实现了目标检测。但传统的检测方法不仅检测精度较低,而且鲁棒性较差。
Girshick等[3]采用候选区域和卷积神经网络结合的目标检测方法取代了传统方法。目前,基于深度卷积神经网络经典的目标检测算法主要有两大类。一类是两阶段目标检测方法,例如Faster RCNN[4]、R-FCN[5]和FPN[6]。该类算法第一阶段对前景和背景进行分类以及边界框回归,第二阶段利用第一阶段的输出再进一步地分类和边界框回归。另一类是一阶段目标检测算法,例如YOLO系列算法[7-9]和SSD算法[10]。与两阶段算法相比,该类算法利用深度卷积神经网络提取的特征直接对目标进行识别和定位,满足了实时性的要求,但识别精度较低。在实际应用中,目标检测既要保证精度又要满足实时性的要求,所以一阶段目标检测算法使用范围较广。其中YOLOv3算法[9]在一阶段目标算法中检测效果最佳,在COCO数据集上 51 ms内mAP为57.9%。
为提高超市的运行效率,使称重设备能够自动检测蔬菜的种类,从而快速地为散装蔬菜称重打码,笔者采用高清摄像机和网络爬虫技术收集蔬菜数据,并对数据进行筛选和标注,制作成用于检测的蔬菜数据集。为保证能实时地检测蔬菜目标,笔者以YOLOv3算法为基础模型。由于YOLOv3算法是针对COCO数据集的优化,为适应新的数据集,笔者提出了改进型YOLOv3算法。首先,通过K-means算法[11]分析获得适应于蔬菜数据的15组先验框;其次,采用一种新的边界框回归损失函数DIoU来提高检测性能;最后,因蔬菜数据集中的大目标较多,因此通过增强特征提取网络,获取5组不同尺度的特征构成特征金字塔,从而实现蔬菜检测任务。经实验验证,改进型YOLOv3算法对蔬菜数据具有较好的检测性能。
1 YOLOv3原理
1.1 Darknet-53网络
YOLOv3算法性能得到提升的主要原因为特征提取网络的增强。与YOLOv2[8]的DarkNet-19网络相比,YOLOv3借鉴了ResNet[12]的残差结构,构造出更深的DarkNet-53网络。DarkNet-53特征提取网络由3×3和1×1卷积层构成,采用5个步长为2的3×3卷积层替换最大池化层(max pooling)实现下采样。该网络在ImageNet数据集测试,网络性能比ResNet网络更加有效,结果如表1[9]。表中,pTop-1和pTop-5分别是模型进行图片识别时得到前1个结果和前5个结果中有1个是正确的概率;计算量表示浮点运算的次数;运算速度是每秒多少次浮点运算;帧速率为每秒刷新图片的帧数。

表1 特征提取网络Table 1 Feature extraction network
由表1可知,DarkNet-53网络的速度约是ResNet-101网络的1.5倍,并且与ResNet-152网络性能几乎一样;同时,帧速率提高至78 f·s-1。因此DarkNet-53在满足检测实时性的同时比DarkNet-19具有更高的准确率。
1.2 YOLOv3设计思想
FPN算法通过高低层特征融合的方式增强低层特征的语义信息,从而提高小目标的检测准确率[6]。YOLOv3采用了类似的方法,利用特征金字塔预测不同尺度的目标;同时,YOLOv3将Softmax[13]替换为多个独立逻辑分类器,使用二元交叉熵损失函数进行类别预测。因此,YOLOv3与其他主流检测网络相比,无论在速度还是检测准确率上,均表现出优异的检测性能。
2 改进型YOLOv3
相比于其他检测网络,YOLOv3具有速度快、精确度高等优点。对于蔬菜数据集,因数据之间的差异需重新设计特征提取网络。笔者受DenseNet[14]启发,将DenseBlock结构[14]添加到DarkNet-53网络中,提高了检测大目标的性能。此外,笔者还提出一种新的边界框回归损失函数DIoU,DIoU与YOLOv3的边界框回归损失函数MSE相比,定位精度更高。
2.1 特征提取网络
若在YOLOv3算法中输入的图片尺寸为512×512,经过下采样32倍后输出特征图的尺寸是16×16。根据FPN可知,原图片被下采样了64倍,这对于提高大目标的检测精度起到一定的作用。针对YOLOv3算法存在的特征图尺寸偏大、感受野偏小、预测不准确等问题,笔者在DarkNet-53的基础上加入2个DenseBlock来构造深度卷积神经网络以提高检测精度。单个DenseBlock结构如图1所示。
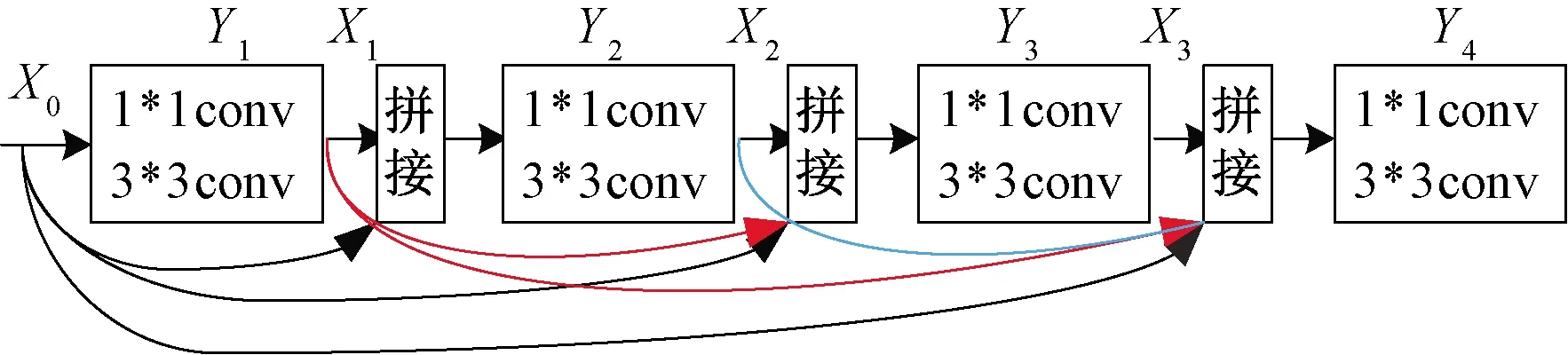
图1 DenseBlock 结构Figure 1 DenseBlock structure
图1中X0是输入特征,第n层的输入不但与第n-1层的输出特征有关,而且也与之前所有卷积层的输出有关,其定义的公式如下:
Xn=Yn([X0,X1,…Xn-1]),
(1)
式中: []表示将第0层的输出X0到第n-1层输出Xn-1进行通道拼接后作为第n层的输入;非线性变换Yn表示将第n层输入经过批量归一化、ReLU激活函数和卷积层之后得到输出特征Xn。DenseBlock内每个卷积层由1×1和3×3卷积构成。1×1卷积主要是为了减少特征通道的数量、降低计算量以及融合特征各通道之间的信息。此外,1×1卷积核的数量是4×k,k表示3×3卷积核的数量,称为增长率,在文中设置k=48。
在DarkNet-53网络的后面添加2个Dense-Block结构达到加深网络的目的。而不使用残差单元的主要原因为:残差单元相比于DenseBlock而言参数量较高。例如,若输入的特征通道数是2 048个,残差单元1×1和3×3的卷积核的数量分别是1 024个和2 048个;而DenseBlock结构中1×1和3×3的卷积核的数量分别是192个和48个。此外,根据DSOD[15]网络结构可知,在没有预训练的前提下DenseBlock结构更易于训练,这主要源于该结构密集连接的方式。 改进型YOLOv3特征提取网络详细结构如图2所示。

图2 改进的特征提取网络结构Figure 2 Improved feature extraction network structure
图2中每个DenseBlock采用4组1×1和3×3卷积构成,每组的输入均由前面所有组的输出经过通道拼接获得。若输入图片是512×512像素,则由残差单元和DenseBlock输出的且用于检测的特征图尺寸分别是64×64、32×32、16×16、8×8和4×4。为增强每个特征图的上下文语义信息,提高特征的表达能力,改进型YOLOv3利用以上5组特征通过最近邻插值法上采样来构造特征金字塔,从而共享高低层特征信息,进行目标检测。
2.2 DIoU边界框回归损失函数
目标检测、目标跟踪以及图像分割都需要依靠精确的边界框回归,现有的网络大多采用L1和L2范数作为边界框回归损失函数,却忽略了真实框和预测框之间的交并比IoU在边界框回归中的重要性,IoU定义如下。
(2)
式中:P是目标的预测框;G是目标的真实框;IoU是真实框和预测框面积之间的交并比。
在目标检测中IoU是比较预测框与真实框之间最常用的度量标准,是评价网络性能的重要指标。通过证明可知,采用L1和L2范数作为边界框回归损失函数与改善IoU值没有较强的关联,如图3所示。图3中L2范数均相等,但IoU值却不同,可以直观地感受到第3个预测框最好,因此采用L1、L2范数作为边界框回归损失函数并不能较好地优化网络。
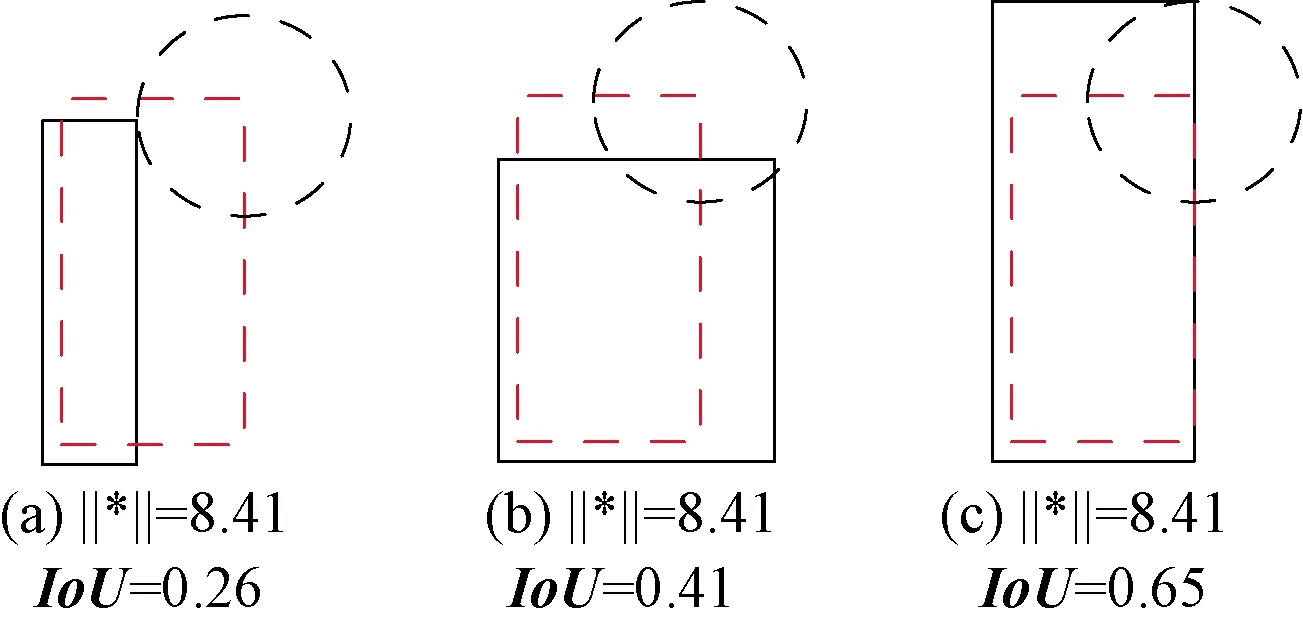
图3 L2范数相同IoU不同Figure 3 L2 norm is the same and IoU is diff erent

图4 真实框与预测框之间关系Figure 4 The relation between ground truth box and predicted box
针对以上问题,可以很自然地想到将IoU作为边界框回归损失函数对优化网络的性能十分重要。但将IoU直接作为边界框损失函数会存在一些问题。如图4所示,黑色框是预测框,红色虚线框是真实框。当预测框与真实框不重合时,则IoU的值为0,导致无法优化网络,使得网络性能较差。
为了在边界框回归损失函数中利用IoU,如公式(3)所示,将FIoU作为边界框回归损失函数,它表示预测框和真实框之间的偏差。
FIoU=1-IoU,
(3)
式中:FIoU的取值范围(0,1]。当IoU=0时,FIoU一直为1,则无法反映预测框与真实框之间的距离关系,如图4中的(b)和(c)两种情况。
为了体现不相交两个框之间距离关系,受YOLOv1[7]损失函数启发,笔者利用真实框和预测框之间中心点距离D解决此问题,如式(4)所示:
D=(x-x′)2+(y-y′)2,
(4)
式中:(x,y) 是真实框的中心坐标;(x′,y′)是预测框的中心坐标;其值均是相对整张图片的坐标位置,取值范围(0,1)。笔者提出最终的边界框回归损失函数DIoU,如式(5)所示:
DIoU=λD+FIoU,
(5)
DIoU是由式(3)和式(4)的结合,式中λ是为了平衡两个损失函数值之间的差距,取λ=10。
3 实验结果与分析
3.1 蔬菜数据集
由于目前没有公开的蔬菜数据集,因此需要自己采集数据。蔬菜数据的来源主要是采用高清摄像机拍摄和爬虫技术获取。拍摄的数据占主要部分,爬虫技术获取的数据为次要部分。蔬菜数据集目前有20类,均为超市常见的蔬菜种类,总共7 632张图片,图片内的蔬菜类别为随机拍摄,如图5所示。

图5 蔬菜数据集Figure 5 Vegetable dataset
数据集的类别分别是上海青、白菜、萝卜、黄瓜、西红柿、茄子、土豆、香菇、杏鲍菇、西葫芦、山药、洋葱、辣椒、西兰花、胡萝卜、莴笋、红薯、包菜、苦瓜和豆角等。笔者对蔬菜数据集内的目标进行统计分析得到总目标数是22 493个,表2是VOC2007数据集和蔬菜数据集分别在某个像素范围内的目标占总目标的比重。

表2 目标像素大小分布Table 2 Object pixel size distribution
通过表2可知,蔬菜数据集的小目标相对较少,而大目标占据了较大的比重。因YOLOv3是针对VOC数据集和COCO数据集进行优化,对于蔬菜数据集无法获得较好的性能,因此笔者提出了改进型YOLOv3目标检测算法,使其适应于蔬菜数据集。
3.2 实验环境及参数
实验的蔬菜数据集共有7 632张图片,其中1 232张是测试集,6 400张是训练集,在显卡NVIDIA TITAN V上运行。改进型YOLOv3算法输入图片像素尺寸设置为512×512,对5组不同尺度的特征上采样构成特征金字塔,预测蔬菜目标的位置和种类。YOLOv3的9组先验框是基于COCO数据集产生的,蔬菜数据集的目标尺度普遍偏大,因此原始的9组先验框已不适应蔬菜数据集。
为获得合适的先验框,笔者采用了K-means算法对蔬菜数据进行聚类分析,获取的15组先验框依次是(88,88)、(115,121)、(150,142)、(128,200)、(310,100)、(107,297)、(194,170)、(99,432)、(176,262)、(235,220)、(380,152)、(152,390)、(314,260)、(235,354)和(396,394)。再分别将15组先验框均分到5组不同尺度的特征金字塔上。小尺寸的先验框在高分辨率特征图上用于检测小目标;大尺寸的先验框在低分辨率特征图上用于检测大目标。
训练时,改进型YOLOv3算法进行50 000次迭代,其中momentum与weight decay分别配置为0.9与0.000 5,批 (batch size)设置为8,初始学习率为0.000 1,迭代次数为30 000和40 000时,学习率分别降至0.000 1、0.000 001。利用改进型YOLOv3算法对蔬菜数据进行目标检测的结果如图6所示。

图6 检测结果Figure 6 Detection results
3.3 DIoU性能分析
在目标检测算法中,边界框回归损失函数作为衡量预测框与真实框之间的误差,其对目标定位效果起到重要作用。为验证FIoU和DIoU对YOLOv3算法的影响,笔者将YOLOv3的边界框回归损失函数MSE分别替换为式(3)和式(5)的FIoU和DIoU。 3种损失函数对YOLOv3算法影响如表3所示。

表3 边界框回归损失函数Table 3 Bounding box regression loss function
由表3可知,采用边界框回归损失函数FIoU训练YOLOv3,与MSE相比mAP提升1.1%,从而可知将IoU考虑进边界框回归损失函数对网络性能的提升具有重要作用。此外,YOLOv3采用DIoU边界框回归损失函数与FIoU相比,mAP提升0.4%,因此在考虑IoU的同时,引入预测框与真实框之间的中心点距离可以更好地优化YOLOv3算法。
图7是YOLOv3采用不同边界框回归损失函数训练时每轮的网络对测试集的检测结果。由此可知,与另外两种损失函数相比,DIoU可以更快地提升网络的性能。 不同边界框回归损失函数对蔬菜的检测效果如图8所示,其中红色框是目标真实框。由图8可知,以IoU为基础的FIoU和DIoU方法对目标的定位精度基本相同,而MSE方法的定位精度稍差。

图7 不同边界框回归损失函数对网络的影响Figure 7 Effect of regression loss functions of different bounding box on network

图8 不同损失函数检测结果Figure 8 Detection results of different loss functions
3.4 多尺度预测性能分析
原YOLOv3算法对蔬菜数据集的检测结果如图9所示。 由图9可知,YOLOv3在检测蔬菜时存在一些问题,如 图9(a)和(c)中山药和黄瓜出现漏检,图9(b)中将香菇错误检测为土豆,以及图9(d)中同一个目标被多个框标记。
改进型YOLOv3算法输入图片的像素尺寸设置为512×512,从而获得5组特征图,其像素尺寸分别是64×64、32×32、16×16、8×8和4×4,再将5组特征图上采样构成特征金字塔进行目标检测。改进型YOLOv3算法采用多尺度特征金字塔之后在蔬菜数集上的检测性能如表4所示。 由4组、5组特征构成特征金字塔的YOLOv3-1、YOLOv3-2的mAP依次是92.6%、93.2%,与YOLOv3算法相比分别提升1.3%和1.9%。 而YOLOv3-2算法提升较大的原因是新的先验框、图片尺寸的增大以及更深的网络。
虽然YOLOv3-2检测速度与YOLOv3相比有一定的下降,但是YOLOv3-2算法利用5组不同尺度特征构成的特征金字塔进行目标检测时仍能满足实时性要求,并且检测精度更高。改进型YOLOv3算法在蔬菜数据集上的检测结果如图10所示。从图10可以直观地看到,增强特征提取网络可以较好地解决漏检、错检和重复检测等问题。

表4 改进型YOLOv3对蔬菜数据集的检测结果Table 4 Detection results of improved YOLOv3 on vegetable dataset

图10 改进型YOLOv3检测结果Figure 10 Improved YOLOv3 detection results
笔者使用蔬菜测试集分别在Faster RCNN、SSD、YOLOv3和改进型YOLOv3进行测试。由表5可知,改进型YOLOv3比原YOLOv3的mAP提高了3.4%,虽然检测速度有所降低,但仍能满足实时性要求。同时,改进型YOLOv3算法的mAP比SSD和Faster RCNN分别高出6.8%和5.4%,说明改进型YOLOv3算法对蔬菜数据更有效。
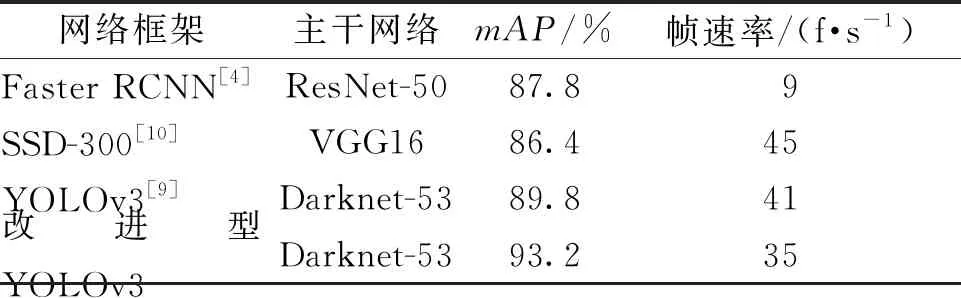
表5 不同方法在蔬菜数据集上的性能对比Table 5 Performance comparison of different methods on vegetable dataset
4 结论
笔者针对蔬菜数据集设计了改进型YOLOv3的特征提取网络,并且采用一种新的边界框回归损失函数DIoU来提高精度。首先,改进型YOLOv3算法将DenseBlock和DarkNet-53相结合,获取具有更高语义信息的5组特征,进而构成特征金字塔,这在一定程度上解决了漏检、错检以及重复检测等问题。其次,通过K-means聚类分析得到适应于蔬菜数据集的先验框;同时,DIoU边界框回归损失函数增强了目标定位精度。改进型YOLOv3算法在蔬菜数据集上的mAP达到93.2%,并获得35 f·s-1的检测速度。在后续的工作中,将收集更多种类的蔬菜数据,并且利用改进型YOLOv3算法和硬件结合实现电子秤智能化,解决散装蔬菜称重问题,提高超市的运行效率。
