基于虚拟机的数据中心能耗测量
2020-06-13陈俊,李娅,张芥
陈 俊, 李 娅, 张 芥
贵州师范大学教育学院,贵阳550025
数据中心廉价资源池的日益扩容带来了能源的急剧消耗.统计数据显示,2006 年美国6 000 个数据中心消耗电能的价值约为45 亿美元[1],已超过美国当时电视机的能耗总和.Facebook 基础设施每半年增长1 倍,电费消耗则每半年增长数百万美元[2].
数据中心利用虚拟机在线迁移技术实现负载均衡,进行物理资源与虚拟资源的重映射[3].虚拟机技术的应用使数据中心拥有集中计算属性,这一属性可将空置物理机设为等待状态而实现节能[4].虚拟机能耗优化的前提是数据中心可以实现虚拟机层次的能耗测量,而利用传统操作系统监测物理机运行状态获取物理机能耗的方法不能测量虚拟机层次的能耗.原因在于,数据中心存在较多的虚拟机在线迁移行为,导致虚拟资源与物理资源映射不一致,从而造成能耗测试数据精度丢失,使得能耗数据结果失去意义.
针对虚拟机层次的能耗测量,文献[5]提出使用虚拟机功率与运算时间乘积计算虚拟机能耗的方法.该方法未考虑到虚拟机运行功率是实时变化、并非持续以额定功率运行的.文献[6]尝试建立虚拟机在线迁移能耗模型,但其未考虑资源映射的非一致性问题,因而计算误差较大.本文采用Hypervisor(虚拟机监视器)监控虚拟机运行状态参数[7],提出了一种度量虚拟机层次能耗的方法,该方法是基于计算密集型与I/O 密集型并结合典型设备运行状态参数来建立数学模型.模型在计算密集型时引入了针对虚拟机的CPU 使用率与CPU 频率,在I/O 密集型时引入了针对虚拟机的硬盘读写与内存读写总字节数计算虚拟机功耗,并将其进行积分得出数据中心能耗[8].
1 相关技术
虚拟机技术可以支持单个虚拟机拥有独立的虚拟资源,这会使虚拟资源与物理资源具有非一致性.因此,直接通过测量物理机的运行能耗去获得虚拟机的运行能耗显然是不够准确的.Hypervisor 可以监测虚拟机运行状态的参数,故可用于虚拟机运行能耗的测量.本文利用Hypervisor 对虚拟机运行状态参数进行跟踪,例如对虚拟机最后一层cache(last level cache, LLC)跟踪时,结合性能计数器来跟踪虚拟机因上下文切换造成的LLC 缺失数,从而避免物理资源与虚拟资源的非一致性.实验方案将虚拟机运行划分为计算密集型与I/O 密集型.实验测量中则使用电量仪获取通过电缆的实时功率来建立能耗模型.
2 虚拟机能耗模型
能耗定义为一段时间内能量的总开销,故可采用对功耗进行时间积分的办法来获取实时能耗.实验中的数据中心被设计为多台同构节点(同构定义为硬件设备型号相同),又设定第节点机上运行多个虚拟机,第i节点上第个虚拟机在t时刻的功耗记为Pij(t),则可推知数据中心能耗E(T)为[9]
式中,Pij(t)dt为第i节点上第j个虚拟机的实时功耗,在实验中可令运行的物理机节点仅运行1 个虚拟机,从而通过电量仪直接测量获得实时功耗值.
由上文分析可知,式(1)中E(T)数值确定的关键点在于Pij(t)值的确定.实验中每台物理机上皆可运行多个虚拟机,而电量仪只能测量物理机粒度的实时功耗,故虚拟机粒度的实时功耗无法通过电量仪直接测量.在此,实验通过Hypervisor 对虚拟机运行状态参数进行采样,用以建立虚拟机实时功耗模型,从而计算虚拟机实时功耗值.
2.1 CPU 使用率、CPU 频率与功率关系
计算机系统运行状态为计算密集型时,计算机系统功耗模型可看为CPU 运行状态的线性回归模型[10],而除CPU 外其他设备功耗可看作常数.项目组在研究CPU 使用率、CPU 频率与虚拟机功率之间关系的实验中,将ω设定为0、0.25、0.50、0.75、1.00,并在Userspace 模式设定CPU 工作频率为1.6 GHz、1.8 GHz、2.0 GHz、2.2 GHz、2.4 GHz、2.6 GHz、2.8 GHz,实验数据见图1.
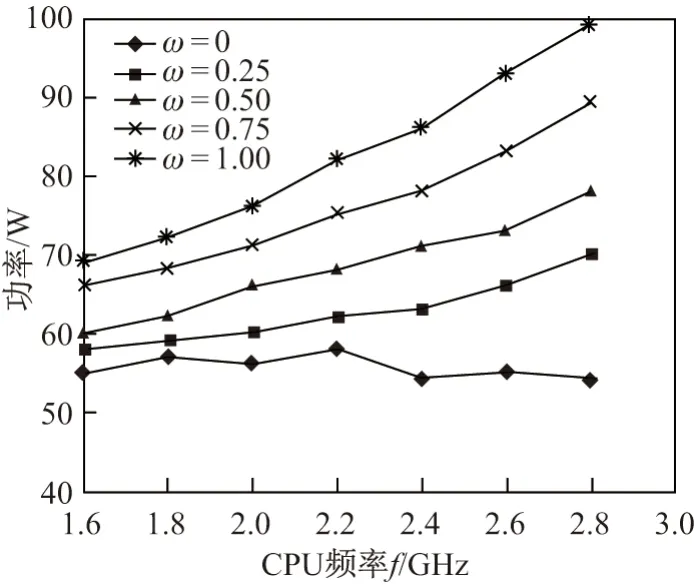
图1 CPU 使用率、CPU 频率与虚拟机功率关系Figure 1 Relationship among CPU utilization, CPU frequency and virtual machine power
由图1 可知,当CPU 使用率为0 时,功率基本保持常数值,而当CPU 使用率为非0 时,频率越大则功率越大.故可得

式中,f为CPU 频率,ω为CPU 使用率.
2.2 硬盘读写总字节数、内存读写总字节数与功率关系
实验发现,CPU 使用率与CPU 频率处于低值时,仅使用式(2)计算虚拟机功率会造成较大误差,故在实验中增选硬盘读写总字节数(drw)与内存读写总字节数(mdr)建立数学模型[11].
为求取硬盘读写总字节数与内存读写总字节数相对计算机实时功率的数学关系,实验方案以间隔∆t时间(∆t取值为0.1 s)对计算机硬盘读写总字节数与内存读写总字节数进行断点采样.为保证结果精确,以上采样都在Sort 任务运行环境下进行.Sort 任务运行环境为I/O 密集型运算环境,可最大限度避免CPU 运行所带来的计算功率波动.实验方案引入下式用以求取若干配对数据之间的相关系数r
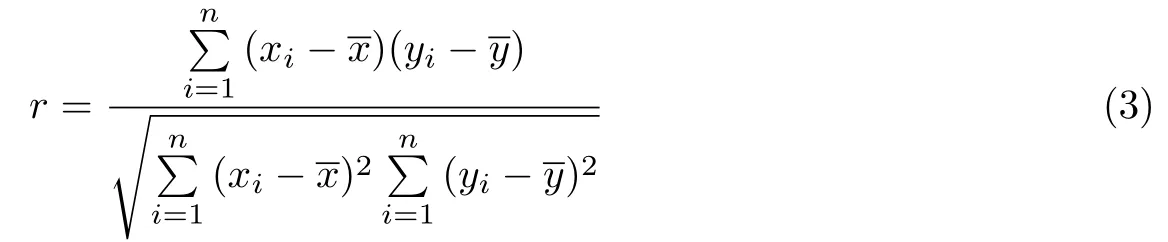
式中,xi为计算节点硬盘读写总字节数与内存读写总字节数,yi为计算节点功率为计算节点硬盘读写总字节数与内存读写总字节数的平均数为计算节点平均功率.
我们分别将Sort 运算置为主硬盘读写方式与主内存读写方式,获取采样数据.针对P,drw配对取样的(P,drw)数据有:(60, 2 317)、(83, 3 257)、(92, 4 531)、(78, 3 115)、(81, 3 212)等;针对P,mdr配对取样的(P,mdr)数据有:(75, 6 512)、(82, 7 122)、(72,5 561)、(93, 8 671)、(65, 6 321)等.
利用式(3),分别求取drw、mdr与计算机实时功率P的相关系数,见表1.

表1 变量线性关系参数分析Table 1 Parameter analysis of variable linear relation
表1 中第1 行为P与drw配对数据计算得出的变量线性关系参数,第2 行为P与mdr配对数据计算得出的变量线性关系参数.其中,P与drw的相关系数= 0.856,P与mdr的相关系数= 0.784,相关系数值均大于0.75,可证明硬盘读写总字节数与内存读写总字节数相对于计算机实时功率P具备线性相关性.故有
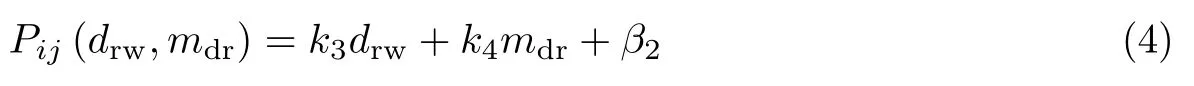
又由式(2)和式(4)可得
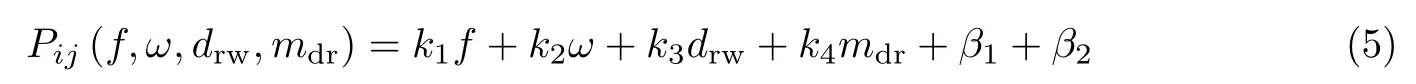
令式(5)中β1+β2=β0,可得
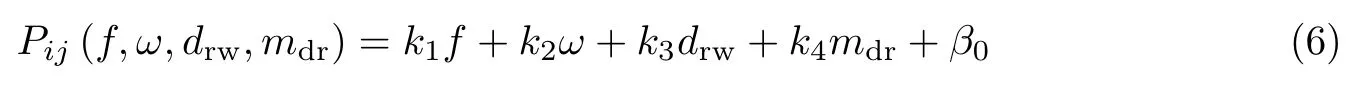
3 实验与计算
实验在数据中心实验室内进行,引入了WordCount(计算密集型)、Sort(I/O 密集型)进行测试计算.在待测虚拟机上运行测试程序,每∆t(∆t取为2 s)进行1 次Hypervisor 资源计数与电量仪功率的数据采样.实验需保证采样数据的独立性,故此处尽量增长采样间隔时长,以便减少采样点之间的数据关联性.实验以∆t的间隔对2 000 个采样点数据进行分组,得到两个规模为1 000 个采样点的采样数据分组,故分组相邻两个采样数据样本之间间隔时长实际为2∆t.实验采样的数据质量直接影响模型精度,本文采样数据应满足以下质量要求[12]:
1)正态分布性:采样数据应尽可能呈现正态分布.
2)方差齐性:计算同类采样数据的平均值与方差,尽可能减少各类采样数据组方差差值.
3)样本独立性:样本独立性检验等同于均值差异性检验,实验通过增长采样数据间隔时长来保证样本独立性.
WordCount 运算与Sort 运算压力测试数据见图2、图3.
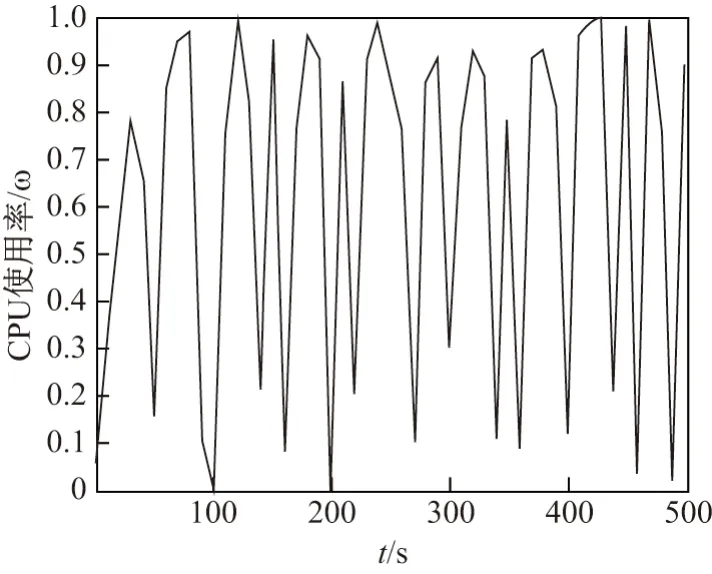
图2 500MB 数据WordCount 运算压力测试Figure 2 WordCount operational stress test for 500MB data
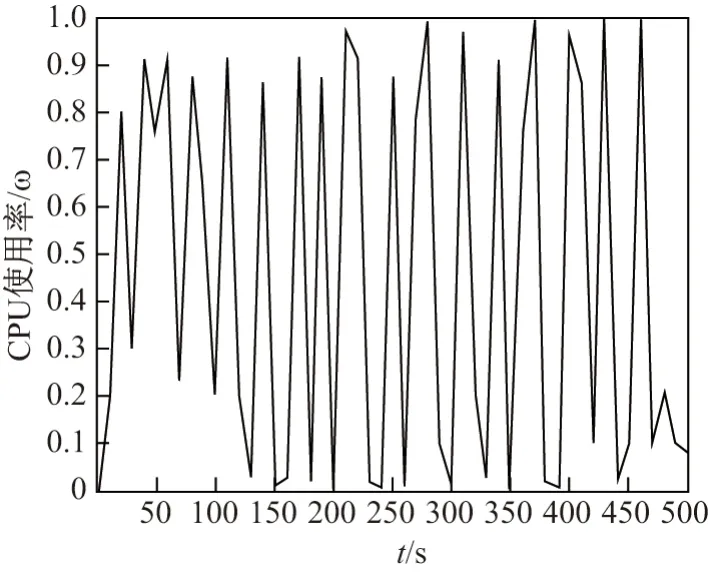
图3 500MB 数据Sort 运算压力测试Figure 3 500MB data Sort operational stress test
由图2、图3 数据可知,较多WordCount 运算节点处于高CPU 使用率状态,属于CPU 密集型.而Sort 运算节点则呈现CPU 使用率时高时低的运行状态,且Map 阶段CPU 使用率高于Reduce 阶段,属于I/O 密集型.
考虑到虚拟机的运行状态参数可能存在共线性问题[13],在此,针对式(6)用实验数据进行共线性诊断,诊断结果见表2.其中,共线性诊断计算的常量值为57.61.
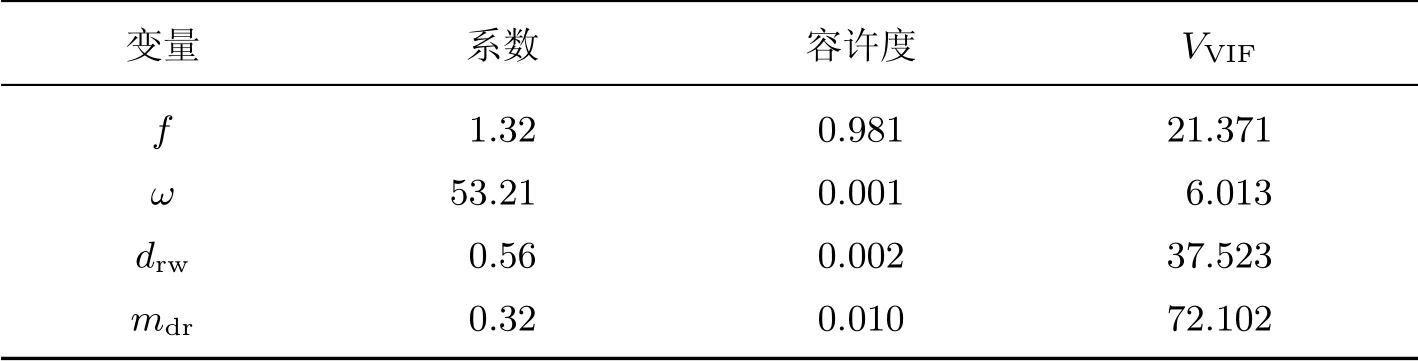
表2 共线性诊断Table 2 Collinearity diagnosis
在表2 中,VVIF为表征变量共线性的膨胀因子,其计算公式为

式中,Rj为第j个自变量与其余变量进行回归时的判定系数.表中对应有3 个VVIF值大于20(VVIF10 即存在共线性),故应加入岭参数进行岭回归分析[14],得到:K1= 0.911,K2=32.752,K3=0.321,K4=0.225,β0=25.351.
4 实验分析
本节针对实验测量能耗与计算能耗进行误差分析[15],定义

式中,We为采样点功耗误差,Wm为测量功耗,Wc为计算功耗.
图4 是WordCount 运算计算值与测量值比较,图5 是Sort 运算计算值与测量值比较.
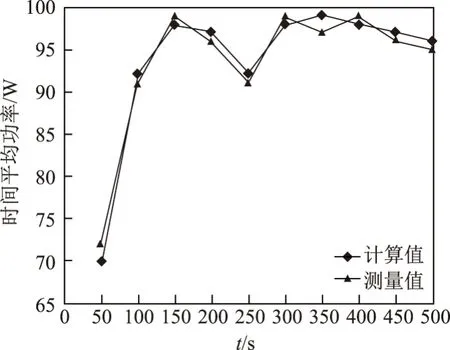
图4 WordCount 运算计算值与测量值比较Figure 4 Comparisons of WordCount operational calculated value and measured value
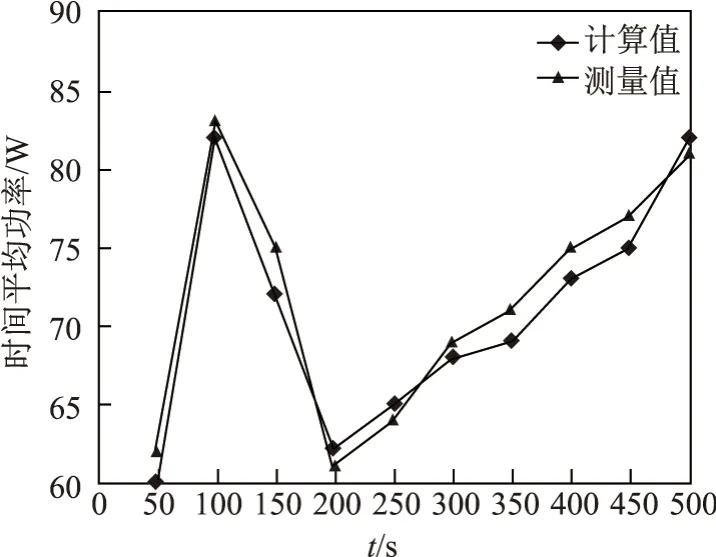
图5 Sort 运算计算值与测量值比较Figure 5 Comparisons of Sort operation calculated value and measured value
采样点功耗平均误差为各采样点功耗误差之和除以总采样点数量.对采样数据进行误差分析可知:平均误差为0.062 5,最大绝对误差为0.115 2,误差整体呈正态分布.
分析采样数据的误差计算结果可知,误差分布呈现正态分布.对实验物理节点能耗组成分析可知,第1 部分能耗为无负载运行的物理机操作系统基础功耗;第2 部分能耗为去除多个虚拟机运行的增量功耗与Hypervisor 所需功耗后,物理机的剩余功耗;第3 部分能耗为运行物理机上的虚拟机功耗.
5 结 语
数据中心的海量运算资源带来了巨大的能耗开销,本文通过Hypervisor 采样虚拟机运行状态参数以建立一个较好精度的虚拟机能耗模型.实验将采样数据虚拟机运行状态划分为计算密集型与I/O 密集型,能耗模型的测量功耗与计算功耗平均误差为0.062 5.
实验方案为进一步实现粒度细化,采用虚拟机Hypervisor 进行虚拟机运行状态参数采样,但该方法会造成测量精度下降,由上节所述物理节点能耗划分可知本文虚拟机粒度能耗构建未考虑第1 部分和第2 部分能耗,故造成一定精度误差.
