基于深度学习的电子物流票据信息分割与识别
2020-06-12沈明军汪山虎王朝晖杨佳龙陈杉杉
沈明军,汪山虎,王朝晖,杨佳龙,陈杉杉
(江苏大学,江苏 镇江 212013)
0 引言
随着我国电商和物流领域的迅猛发展,涌现了大量的电子物流票据,对于这些电子票据信息的识别和利用有着巨大的社会效益和经济效益。实现电子物流票据的快速识别录入,迅速获取物流信息,不仅缩短信息采集时间,更有利于物流和电商企业及时响应市场需求,做出合理资源分配。
在电子物流票据的识别过程中,具体包含两大应用技术,即字符分割和字符识别。字符分割的完整性很大程度决定了识别的正确性,所以字符分割技术至关重要。在字符分割领域,早期有提出基于投影的分割算法[1],利用文本区域行列之间的间隔,对字符进行切割,此算法对英文和数字等连通体文本的分割准确率较高,但在含有大量左右偏旁的中文字符集较难准确分割;有学者在投影分割的基础上提出了统计分割算法[2],该算法通过聚类算法分析出正常字符宽度范围,再结合高度、宽度和高宽比三种特征信息进行字符分割,但此算法识别非正常中文字符集所利用的特征信息过于简单,容易错误识别导致分割失败;有学者提出了基于连通域的字符分割算法[3],但并不适用具有文字密集性特点的电子物流票据,容易导致多行多字被分割。
基于以上的分析,面对电子物流票据中单字符分割时所利用特征单一的问题,我们在统计分割算法的基础上,将聚类算法与深度学习相结合实现基于复杂特征的电子物流票据分割。利用深度模型学习到的文字特征替代了高度、宽度和高宽比三种简单特征,例如文字的形态、结构等隐性特征;为了充分考虑偏旁的左右字符信息,通过左顺序优先和右预判相结合的方法,提高了偏旁的组合准确率,进而有效提高了整体上单字符分割的准确度。在字符分割结束后,将中文字符送入VGG16深度网络模中进行识别[4],识别准确率达到了99.9%。
1 相关理论
1.1 基于投影的字符分割算法
二值化文字图像后,对字符像素分别在x,y轴上投影,即对每一行或每一列像素进行累加,形成高低起伏的统计分布图,根据峰谷依次进行水平分割、垂直分割,如图1所示。投影法对行文本的切割准确而高效,而对行文本中每个中文字符的列分割,却容易失败,因为有中文字符含有左右偏旁,垂直投影后,很容易把偏旁单独分割出来。如果在文本中再混合英文、标点和数字,由于英文、标点和数字存在与分割出的偏旁同一宽度的情况,对于分割错误的偏旁就很难进行正确的组合,所以投影分割算法适用于英文、数字和标点这种连通体字符的分割,而在中文字符分割上的表现效果不佳。

图1 文字进行投影分割
1.2 基于统计学习的字符分割算法
基于统计学习的字符分割算法是在投影分割算法的基础上进行改进的,在基础投影分割后,收集分割字符的宽度数据,进行聚类分析,再结合长度、宽度和长宽比三种特征进行字符分割。
虽然统计分割在实际中的部分应用表现突出,甚至可以商用,比如在牌照、商品字符等方面[5],但是只有在结合具体的场景中才有效果。这主要原因是统计分割对投影分割的完善是有限的,一方面表现在对非整体字符中英文、标点和数字的识别具有很大的限制,因为在统计分割中采集到字符的数据特征只包含长、宽和长宽比三种特征,而非正常字符中的偏旁、数字、标点和英文在这三种特征上重合的可能性很大;另一方面是对偏旁组合考虑的情况考虑不够全面,容易导致组合失败。
1.3 卷积神经网络
随着深度学习的崛起,卷积神经网络(CNN)[6]在计算机视觉领域得到广泛的应用,原因在于卷积对图片特征的提取力得到了毋庸置疑的肯定。CNN是一类包含卷积计算且具有深度结构的神经网络,常用于目标分类、目标检测等研究领域,其主要由输入层、卷积层、池化层、全连接层组成。
卷积层可以提取图片的特征,随着层数的加深,提取的特征信息会更加丰富;池化层是取卷积核区域的最大值或平均值来代替该区域从而达到增强鲁棒性和减少计算量;全连接层连接所有的特征,将输出值送给分类器(如softmax分类器)实现概率输出。
2 改进的字符分割、识别算法
本论述的工作是对电子物流票据字符进行精准分割与识别。为避免异常宽度字符(包括中文偏旁、英文字符、数字和标点)无法识别,在原始投影算法上结合异常宽度字符聚类算法,并运用基础CNN网络实现异常宽度字符的分类,再通过组合机制将多个偏旁拼接成整字。最后,将整字依次输入到VGG16深度模型中识别。
2.1 K-Means聚类算法
K-Means聚类算法是一种迭代求解的聚类分析算法。在输入数据中,随机设置k个中心点,计算数据集中每一个点到中心点的距离(如欧式距离),根据距离迭代调整中心寻找最优解[7]。
本论述在投影分割后,通过K-Means算法对分割字符的宽度进行正常和异常聚类分析。设置中心簇k=2,目的是分出正常宽度字符和异常宽度字符。在正常字符的宽度数据集中找出正常字符的宽度范围,用于以后中文偏旁的组合。正常宽度字符集包括完整的中文汉字,异常宽度字符集里包括中文偏旁、英文字符、数字和标点。
选用欧式距离作为目标函数,见式(1):

其中,xn表示数据对象,μk表示中心点,rnk在数据点n分配到类别k的时候为1,没有分配到类别k的时候为0。
迭代优化过程中,先固定 μk,更新rnk,将每个数据对象放到与其最近的聚类中心的类别中;然后固定rnk,更新 μk,根据J对 μk的偏导等于零求得中心 μk的更新公式,见式(2):

这样交替更新,直至目标函数收敛,分离出正常与异常字符。
2.2 CNN异常宽度字符分类
采用CNN网络模型对异常宽度字符集里的字符进行识别,此深度模型主要由2层卷积层,2层池化层和2层全连接层组成,具体结构如图2所示。

图2 异常宽度字符分类CNN
输入数据为原始训练图像(图像大小:28×28×3),因为数字、常用标点、英文共有有78种类别,所有模型输出的神经元个数为78。模型的测试集效果达99.9995%,训练集为100%。
2.3 偏旁组合机制
根据卷积神经网络识别出来的偏旁进行重新组合,采用左顺序优先的策略,即从每一行文本的最左侧开始检测,检测到第一个偏旁,开始分析其左右字符,具体情况见表1所列。

表1 偏旁组合情况
面对第一和第二种情况,我们从检测到的偏旁和右邻近的偏旁进行组合,对组合后的宽度进行计算,如果满足在正常字符的宽度范围之内就进行组合,如果低于正常字符的最小宽度值,则会继续组合右边的偏旁。
面对第三种情况,我们将所检测到的偏旁和左右整字的宽度分别相加,如果只有一个组合宽度在正常字符范围之内,就将偏旁和整字进行组合;如果两个组合宽度都在正常字符宽度范围之内,我们选择宽度靠近K-Means聚类算法算出的聚簇中心的组合。如果两个组合都超出正常字符范围,则对偏旁宽度进行缩减之后再次进行组合分析。
面对第三种情况,我们对所检测偏旁不做任何操作。
2.4 VGG16字符识别模型
在单字符分割后,采用VGG16网络模型实现字符识别。模型训练的数据集借助强大的图形库自动生成,含有3755个常用中文字符,并对每一个字符进行了六种增强,分别为:文字扭曲、背景噪声、文字位置、笔画粘连、笔画断裂和文字倾斜。
VGG16深度模型具有结构简单,提取特征能力强的优势。虽然之后出现了更加优秀的网络,如ResNet[8]和 DenseNet[9]等,但考虑到 VGG16 模型分类能力已经足够满足我们的分类需求,而其他更优秀网络一般具有训练难度大和线上部署时的预测速度慢等问题,所以我们最终还是采用了VGG16网络作为文字图片的识别网络。网络主要结构如图3所示。
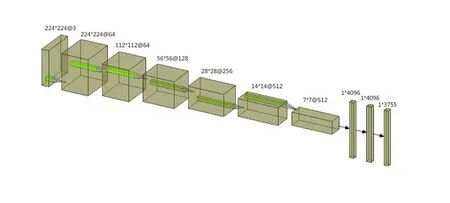
图3 VGG16识别网络结构图
卷积层用来理解图片的重要的空间信息,比如空间上邻近的像素为相似的值、RGB的各个通道之间的关联性、相距较远的像素之间的关联等。池化层主要是用来增强对微小位置变化的鲁棒性和保留主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力。
全连接层起到将学到的“分布式特征表示”映射到样本标记空间的作用。同时在三个全连接层中增加了两次dropout层,来防止过拟合。3个全连接层在整个卷积神经网络中起到的是对文字图片进行分类的作用。
在全连接层最后一层有3755个神经元,是因为我们要对3755个常用中文字符进行的分类。而英文、标点和数字的识别在分割时就已经被识别出来,所以不参加这里的分类。
3 实验与分析
3.1 实验运行平台
本实验采用运行平台CPU为Intel Core i7-8700k,显卡为GeForce GTX1080,系统为64位Ubuntu 16.04,在Tensorflow+GUDA9.2下进行实验。
3.2 单字符分割实验
3.2.1 数据集
本论述聚类算法和深度识别模型分析的数据集来自电子物流票据中分割出来的文本图片,我们在对文本图像二值化后进行了投影分割,分割效果如图4所示。

图4 投影分割流程图
分割结束后由垂直投影计算得到分割字符的宽度数据集,而深度识别模型的数据集我们自制的数据集,将电子物流票据中的各类英文、数字和标点和偏旁用投影法分割出来,共有78种。将78种图片二值化,字符为白,背景为黑,对图像进行各种类型的膨胀,多样化数据。图片的size设置为(3,28,28),三通道上的值同为二值化后的图像值,即将二值化的图像复制三份,之后再对图片进行缩放、旋转(仿射变换),然后增加随机噪声。将数据保存为npy格式,共10 000组,每个数字满足“粗细、旋转角度、缩放比例、噪声分布”的多样化。
3.2.2 参数设计及实验结果
对分割字符宽度数据集进行聚类分析,在K-Means算法中,我们设聚簇中心k=2,将分割出的字符集分为两类,一为整字宽度集,二为非整字宽度集,具体效果如图5所示。

图5 聚类分析结果图
由上图显示,在我们所做的数据中,整字宽度集和非整字宽度集的分类比较明显,他们聚簇中心点分别为24.3和8.6,计算方差为162.676,所以对整字和非整字的区分比较容易,对整字集的宽度也很容易从聚类图中得到。
之后使用深度网络模型对非整字集进行识别,我们使用了由两层卷积和两次全连接层构成的网络进行了训练。网络的初始权值设计为标准差为0.1的正态分布,损失函数选择了softmax_cross_entropy,优化器选择了Adam,学习率设为0.001,表2展示了从200次迭代到450次迭代的测试集精度和训练集精度,在450次迭代以后准确率分别达到了99.95%和100%。

表2 CNN训练、测试准确度分析
在将非整字集识别完后,就是对非整字集的偏旁进行组合,部分组合效果如图6所示。

图6 偏旁组合效果图
3.3 深度模型识别实验
3.3.1 数据集
电子物流票据的文字属于印刷体,我们可以借助强大的图形库自动生成数据集。本论述的中文数据集含有3 755个常用中文字符,对每一个字符进行了六种增强,分别为:文字扭曲、背景噪声、文字位置、笔画粘连、笔画断裂和文字倾斜。具体效果如图7所示。

图7 中文字符数据集
3.3.2 参数设计及实验结果
在制作完数据集以后,我们将数据送进了VGG16网络,网络的损失函数选择交叉熵损失函数,优化器选择了Adam,学习率设为0.1,最大迭代步数为16 000,每100步进行一次验证,每500步存储一次模型。
在训练过程中训练集和测试集的Accuracy变化如图8所示。

图8 VGG16准确率与损失值变化情况
实际字符识别效果如图9所示。

图9 字符识别效果图
数据定位结构化识别结果如图10所示。

图10 结构化识别结果
4 结束语
本论述提出了一种将传统机器学习算法中的KMeans聚类算法和深度学习分类算法相结合的方法,解决了传统方法对含有中文字符的电子物流票据图像难分割的问题。首先,我们使用了聚类算法分析出正常字符的宽度大小,进而使用深度网络识别出英文字符、数字、标点和偏旁,再通过左顺序优先、右预判和正常字符宽度范围等信息对偏旁进行了较为准确的组合,有效提高了整体字符分割的准确率。在这之后,我们将分割好的图片送进VGG16网络模型进行了识别,训练集和验证集的accuracy都达到了99.9%,且在实际测试中,针对左右偏旁结合的中文字符识别的效果较好。
本论述只针对电子物流票据这一特定场景进行深入研究,字符识别在其他复杂场景中的应用同样值得更进一步的探索。如果将本论述的直接分割策略和已经商用的置信度反馈机制相结合,可能会适用于更多场景的字符识别。[10]
