基于句结构的主题分类模型改进算法
2020-06-10韩奕农乐红兵
韩奕农 乐红兵
(江南大学物联网工程学院 江苏省无锡市 214122)
1 引言
统计主题模型是描述大型文本集合生成主题信息概率分布的无监督模型。目前,基于吉布斯采样的潜在狄利克雷分布(latent Dirichlet allocation,LDA)是当下普遍使用的文本聚类挖掘技术。该主题模型使用词袋算法,忽略词的位置信息,提取出的主题为分割词的无序组合,然而单词在连贯的文本段(句子或短语)中的意义丢失,并且分配这些主题的标签通常留给人工解释,降低了识别的准确率、增加了工作量。在主题模型上增加多标签识别为多个词从属于一个标签主题以及对主题进行预测所属类别提供了便利。例如,单词如铅笔、笔记本电脑、尺子、橡皮和书本可以映射到标签“学校用品”上,判断铅笔类别可归属到“学校用品”上。
为了提升主题模型的泛化性,一些研究者在Blei等[1]提出的LDA模型基础上进行了研究改进:Liu Y[2]提出主题词嵌入(TWE),给定一个单词序列D={w1,…wM},在LDA迭代收敛后,每个单词被分配给一个特定的主题,形成word-topic映射对,用来学习主题词嵌入,该方法的计算复杂度高,耗时较长。Georgios Balikas[3]提出copLDA模型,充分利用句子的结构信息,以名词短语为基本采样单位,并且用连接函数模拟词之间的依赖关系,提取出名词短语,然而名词短语是共现词的一种特殊情况。Justin Wood[4]提出sourceLDA模型,先采取有监督的方法学习带有标记的主题,再将这些先验知识纳入建模过程,以提高主题分配的质量,更有效地标记主题,这种方法整合了先验知识,但没有考虑单词分布,需要手动输入预先存在的概念和每个主题的词袋。Harsh Shrivastava[5]提出CoNN-sLDA改进分类准确率,使用一组经过训练的神经网络来捕获先前给定结构的潜在表示,与传统的深层网络相比,它需要更多特定领域的先验结构或变分自动编码器。
本文提出senLDA模型,修改LDA的吉布斯采样过程,假设文本窗口内词只由一个主题产生,短文本潜在主题与各个单元上的主题保持一致。以句内共现率较高词作为采样单位,收敛出高频共现词。传统LDA假设单个词的长度为最大窗口,因此senLDA是LDA的一个特殊情况。senLDA通过整合句子来扩展LDA,保持词汇与主题的关联并且没有依据先验知识增加额外超参数的推导,保留了传统LDA的简单性。
2 senLDA模型
传统LDA是3层贝叶斯概率模型,它主要采用两层Dirichlet分布表述了文档、主题、词汇间的数学关系,可以用来挖掘数据规模较大的文档集或语料库中隐藏的主题词信息,并广泛应用于文本分类聚类、文章概要挖掘、信息优先级检索等多重领域。SenLDA与传统LDA结构类似,采用两层Dircichlet分布表述了文档、主题、共现词间的数学模型,假设同一句子窗口内的词由同一主题产生,对句子内的词进行进一步建模,能捕捉到更加细粒度词语共现关系。

图2:senLDA-CNNs处理文档过程
模型概念如图1所示。
图1中,α为K维向量,表示对应的主题在文档中的概率比值,β为v维向量,表示每个主题内部词的平滑程度。θ是一个M*K的矩阵,矩阵的行代表了一篇文章的主题分布,列表示贡献词在各个主题下的概率值,w是N个词组组成的向量,各个符号的含义见表1。
在文本切分好的词中增加词序列表示词的相关性。通过分析句结构联合语法,只保留名词属性词,其它属性词被去除,再进行以共现词为单位的吉布斯采样,可以获得更精确的主题粒度。senLDA使用文档采集过程如算法1所示:

?

For document do Sample mixture of topics Sample sentence number For sentence do Sample number of words Sample topic For co-words in sentence s do Sample term for End End End
由算法1可以看出,senLDA通过使用句子作为连贯片段来扩展LDA,分析句子的结构并将共现词替代单个词进行主题提取,可以实现更精细的粒度级别。采用吉布斯采样估计隐藏的主题变量,文本结构通常包含词序信息,可以更好地进行分类的有监督学习。因为句子或短语是文本窗口大小内的完整部分,它们本身可以传达一个简洁的意思。如“这部电影是由 Victor Mature, Brian Donlevy 和Richard Widmark在1947年根据电影《黑色经典》翻拍的”。在句子层面上,我们可以认为句子是由“电影”主题产生的,因为它讨论的是一部电影及其作者。然而,LDA给句子中的《黑色经典》分配了“电影”、给三个人名分配了“选举”这2个主题,可以看出,“电影”和“选举”是无关的。进一步,在更精细的文本粒度中,LDA也无法在名词短语(如“无厘头电影”)和实体(如“周星驰”)中指定一致的主题,而senLDA通过共现词的概率计算,把短语和实体捆绑在一起分类到电影主题。因此,一个句子或短语主题之间的约束机制考虑到简单的文本结构,可以更好表达主题意义。senLDA的联合分布如式(1):

对公式(1)进行分解可以得到公式(2):


公式(3)中的第一项具体解释如下所示:
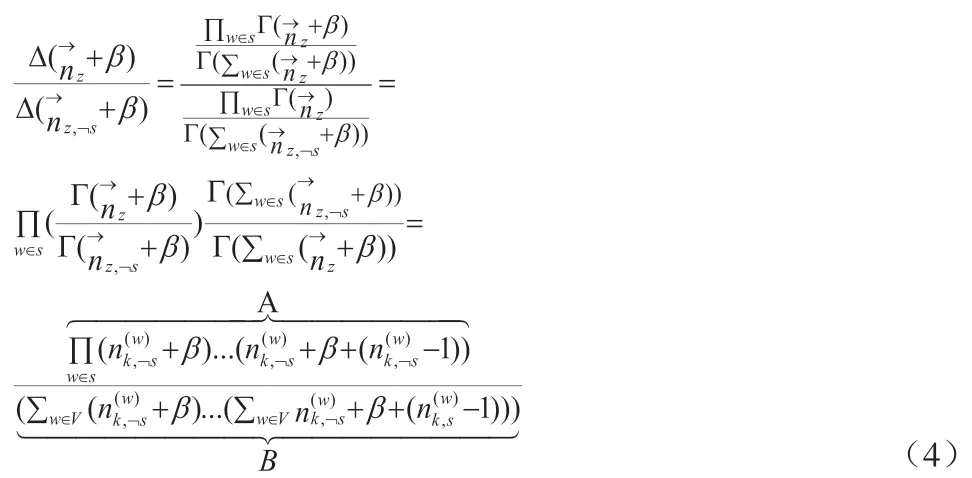

表1:senLDA符号含义对照表
公式(3)的主题计算方法在大体上与传统LDA计算方法相似,不同之处在于考虑到每个文档的主题数由句子表示的主题数决定,而不是词表达的主题数决定,公式(3)由此得出:

3 卷积神经网络
神经网络为学习复杂的自然语言提供了一种低偏差的解决方法,卷积神经网络(CNNs)近来在句子分类任务上广泛使用,该模型要求一个精细的模型体系结构并设置伴随的超参数,包括过滤区域大小、正则化参数等等。单层CNNs分类功能类似于向量机和逻辑回归,不仅能提高分类精度值,而且减少了多层网络的训练时间。
进行文本多分类的模型训练过程中,对同一主题中的文档使用senLDA进行高频共现词提取,然后提取结果使用卷积操作处理词向量序列,生成多通道特征图,再对特征图采用的最大池化操作得到与此卷积核对应的整句话特征,最后将所有卷积核得到的特征拼接起来为文本的定长向量表示,映射为分类类别。CNNs经过多次迭代学习神经网络参数,构建模型,用于预测测试集语句。
图2中最上面是同一主题的多个文档,经过senLDA进行窗口内提取的高频词作为输入层,通过word2vec生成有顺序的多个短语对应矩阵。使用K维的分布式词向量表示长度为n的句子,则构成一个n×k的矩阵,句子可以表示为:



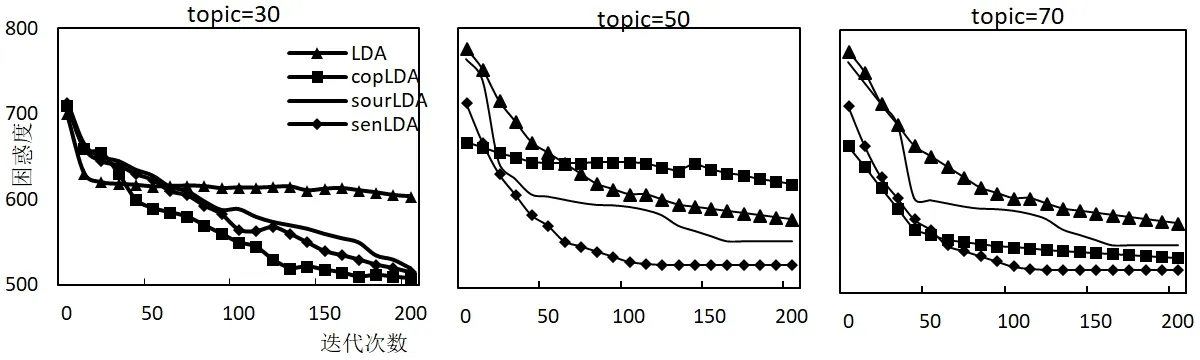
图3:20NewsGroup困惑度变化曲线

图4:wiki困惑度变化曲线
(1)通过卷积神经网络对提取出关键词的文本进行标签分类。经过输入层后,得到大小为的三维文本输入。对三维文本进行卷积过滤操作,卷积尺寸为其中m代表卷积长度,即每次处理文本中单词的数量;k代表词向量的维度;depth代表过滤的深度,可以使用不同的m分别进行卷积来提取更多的特征,逐行进行卷积操作。当m=1表示一元分词特征,m=2表示二元分词特征。在卷积层选择m={2,3,4}进行卷积得到3个特征映射,每个特征映射的长度与原文本长度相关,宽度为depth,经过卷积层可以提取到原文本的n元特征。
(2)在池化层采用了max-pooling的方法,池化层的过滤器表示为其中convLength代表对文本卷积后特征映射的长度。经过池化层后特征映射的维度降为1,因此池化结束后,得到向量的维度为这样就得到整个文本的特征表示。
(3)经过卷积池化后得到了表示文本的特征向量,再经过一个全连接+softmax层就获得不同标签的概率联合向量,完成了CNNs对文本分类建模的任务。
4 实验结果与分析
实验评估senLDA的性能,过程分为两个步骤:
(1)训练阶段:迭代主题模型去学习主题参数。
(2)预测阶段:使用吉布斯抽样推理方法估计主题分布。
4.1 主题正确性评估
困惑度(Perplexity)最早由Blei D M[1]提出,是目前常用的一种评价主题模型性能的手段,可以表示主题模型的泛化能力。困惑度指的是训练出来的模型对文档d属于某个主题的不确定性。困惑度与模型聚类效果和泛化能力成反比。困惑度的计算公式如式(9)所示:

p(w)是指单词出现的频率,计算方法如式(10)所示:

p(z|d)表示一个文档中每个主题出现的概率, p(w|z)表示的是每一个单词在某个主题下出现的概率。
文献[3]提取的copLDA模型,文献[4]提及的LDA模型sourceLDA模型,和本文提出的senLDA三种主题模型的困惑度都依赖词频计算,选择主题数K={30,50,70}随着迭代次数的增加,3个数据集的困惑度值在不同数据集上的变化曲线如图3,图4所示。
图3和图4描述了四种主题模型在两种数据集上随着迭代次数增加困惑度的变化曲线。当迭代次数增大,四种模型的困惑度随之下降。在头条新闻数据集中,senLDA曲线变化幅度最大,尽管刚开始copLDA表现优于senLDA,随着主题模型更长时间的迭代,senLDA的困惑度差距逐渐缩小并且低于copLDA。与其它三种模型相比,senLDA模型的困惑度低于其它以词为提取单位的主题模型,模型的泛化能力最强。当topic=50时,senLDA的下降速度最快,收敛效果最明显;当K增加时,senLDA的困惑度变化曲线基本与之前一致,其它算法曲线相应下降,但还是高于senLDA算法。在wiki数据集中,四种算法的变化曲线都比较大,随着主题模型更长时间的迭代,四种模型的困惑度在迭代次数小于50时迅速下降,最后趋于平缓。当K=30时,senLDA的下降速度最快,收敛效果最明显;当topic=50时,困惑度的值一开始区分明显,而后senLDA曲线与sourLDA 基本重叠;当K=70时,senLDA的困惑度变化曲线基本与之前一致,其它算法曲线相应下降,但还是高于本章提出算法。

表2:实验数据集

表3:模型在数据集上的F值

表4:模型在数据集上的准确率
从两个数据集的实验结果可以看出,由Georgios Balikas[13]提出copLDA模型,充分利用句子的结构信息,以名词短语为基本采样单位,并且用连接函数模拟词之间的依赖关系,提取出名词短语,然而名词短语是共现词的一种特殊情况。Justin Wood[14]提出的sourceLDA模型采取有监督的方法学习带有标记的主题,并将这些先验知识纳入建模过程,不仅提高主题分配的质量,还有效地标记主题,这种方法确实整合了先验知识,但没有考虑单词分布,需要手动输入预先存在的概念和每个主题的词袋。传统LDA假设单个词的长度为最大窗口,因此senLDA是LDA的一个特殊情况。senLDA通过整合句子来扩展LDA,保持词汇与主题的关联并且没有依据先验知识增加额外超参数的推导,保留了传统LDA的简单性。
总体而言,senLDA模型虽然有更低的困惑度,但是需要更长的迭代时间。由于senLDA采样单位为共现词,代替传统LDA以单词为采样单位,所以senLDA计算复杂度的灵活性降低,概率计算时间较长。尽管如此,当训练实例是短语,基于单词度量进行困惑度评估时,虽然senLDA的灵活性受到限制,收敛时间更长,但是模型泛化能力好,并且采集的短语更能表达主题的含义。
4.2 分类F值评估
提取文本的主题词等同于文本预处理,根据多个核心短语进行网络学习并且多分类,不仅降低了文本训练维度,而且实验准确率得到提高。实验采用准确率(Precision,P)和综合F值作为评价指标。为了验证本文提出文本分类方法的有效性,
(1)第一组实验是在4个通用数据集上将senLDA-CNN与当前的一些经典主题模型算法做比较。文献[2]中提及的模型,如BOW、Skip-Gram、LDA和文献[6]涉及的模型如copLDA、senLDA+SVM,计算分类的F值如表3所示,评估本文算法的有效性和可靠性。
通过表3可得,在数据集20NewsGroup,wikitrain和头条新闻中,本文提出算法相较于经典算法有较大提升。本文算法senLDA+CNN分类的F值在四个不同数据集上最高。与其他模型相比,senLDA可以能够把文章特征降低到82%。在20NewsGruop数据集中,本文提出算法的F值提升显著,如较senLDA+SVM提高了大约3.75%,较copLDA提高了2.4%,较BOW模型提升了29.9%。在头条新闻数据集中,本文提出算法提升不大,相较于其他主题分类模型,最多提升7%左右。总体可以看出,保持词序建神经网络,不仅可以最大限度降低文章特征,而且比其他主题模型的分类的F值更高。
(2)第二组实验为LDA融合于神经网络或机器学习的扩展模型与本文提出模型的比较。
senLDA结合单层卷积神经网络进行文本分类,根据主题困惑度评估,20NewsGruop数据集中的k=50,模型的主题聚类达到最好。在卷积层选择m={2,3,4},当m=1表示一元分词特征,m=2表示二元分词特征,进行分类实验。比较senLDA+CNN和现有的文档分类算法;
(1)VI-sLDA[7,8]包括图模型中包含文档标签,可以最大限度地实现最低边界;
(2)DiscLDA[9]的有监督主题模型通过引入与类相关的线性变换来降低分类主题向量 θ的维数;
(3)OverRep-S[9]是为建模文档而开发的分类方法;
(4)BP-sLDA[10]是在深层结构上的反向传播进行lda的点到点学习;
(5)senLDA算法[3]和本章提出算法senLDA+CNN在20 Newsgroups数据集上进行正确率比较。
表4显示了20NG数据集的准确性结果以及平均值的标准误差,将数据集分为训练集和验证集,并优化所有参数。
由表4可得,当卷积层的分词特征m=3时,senLDA+CNN在损失函数中平衡了不同类别的误分类成本,表现稍好。其他深层模型如BP-sLDA所需的层数通常比较高,并且随着层数的减少,它们的性能大大降低。senLDA+CNN的单层神经网络分类的准确率上高于其它模型,因为与其他模型相比,senLDA能够把文章特征降低到82%,过滤掉对分类用处不大的信息。在20NewsGruop数据集中,本文提出算法的准确率比senLDA+SVM提高了大约3.75%,较BP-sLDA提高了2.4%,并且网络结构达到了最简化。本文算法的准确度略低于BP-sLDA,网络设计层数是它的1/5,因此模型的复杂度低于其它算法。总体而言,本文提出算法准确率并没有完全高于所有算法,但对于其它网络模型结构,单层神经网络达到最简化,分类性能略低于或大于其它模型。
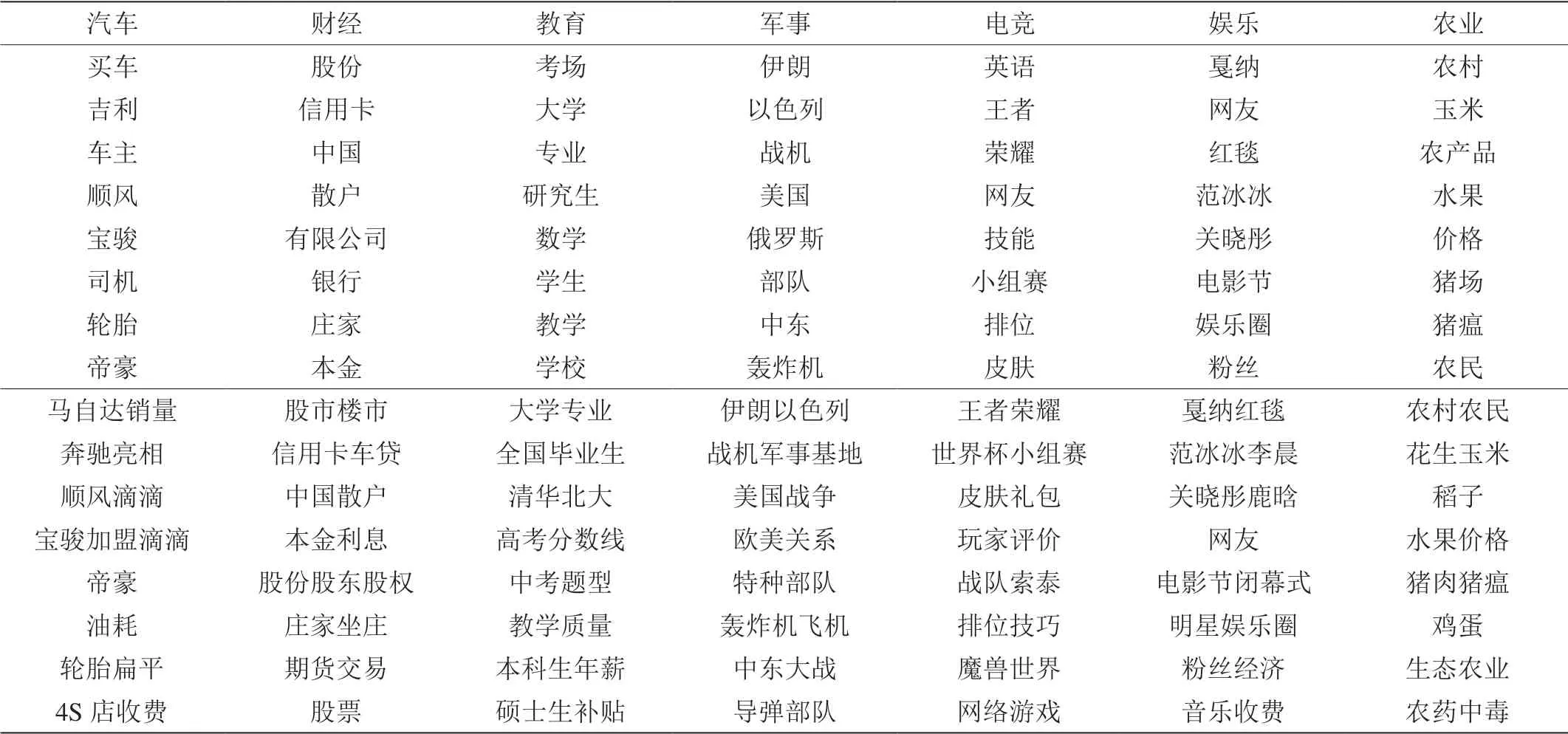
表5:LDA和senLDA主题提取结果
4.3 LDA和senLDA关键词对比
使用今日头条数据集训练LDA模型和senLDA模型, 窗口长度最大为20的共现名词作为采样基本单位,LDA和senLDA提取的主题为汽车、财经、教育、军事、电竞、娱乐、农业前8个关键描述词和高频共现词如表5所示:第一行为新闻所属主题,上部分词是LDA模型提取结果,下部分共现词是senLDA模型提取结果。
由表5可得,两个模型都能识别直观主题,LDA是词袋模型,所以提取的主题是无序单词,词与词之间的联系被忽略,表达的含义比较有限,并且各个主题之间的关键词容易混淆。而senLDA提取出的多是高频共现词,表示组成该字符串的词共同出现的频率较高,短语表达不仅在含义上更清晰,还可以帮助提取每个类别下新闻的热点话题。如在“汽车”类别的话题下,通过senLDA提取,新闻发布量最多的话题可能是“马自达销量”、“奔驰亮相”、“顺风滴滴”等代表网名最关心或者提及最多的话题。在“娱乐”类别的话题下,热点话题为“戛纳红毯”、“范冰冰李晨”、“关晓彤鹿晗”等娱乐圈新鲜事和营销号推广最多的话题。senLDA使用的文本结构信息有助于获得一致的主题以生成像“大学专业”和“全国毕业生”这样的教育类别的名词短语,表示“大学”和“专业”在文本中共同出现的频率最高,使词语表达含义更准确和更易理解。由于senLDA在窗口内采用的是连接函数,以句内高共现词取代了单个词作为采样单位,所以提取出来的词有连贯性,在词意表达和理解上优于传统LDA模型。
5 结束语
本文提出senLDA-CNNs模型,主题按照以句为最大窗口进行共现词采样,再结合单层卷积神经网络模型进行文本分类,在困惑度计算、分类准确率和F值中评估了本文算法,实验结果表明改进模型主题提取泛化性和文本分类准确度都得到提高。
未来的工作中,可以从以下几个方面进行改进:
(1)进行词语相似度计算使得出的主题相关词集中。
(2)建立多种混合模型进行标签判定,进一步提高分类的准确率。
(3)从数据本身出发,对文本质量进行打分,筛除低质量文本,增加高质量文本重要性,提高分类和主题提取的准确度。
